Primers • Tulu 3
- Introduction
- What is Tülu 3?
- What Makes Tülu 3 Novel?
- Deep Dive into the Tülu 3 Training Pipeline
- How Does Tülu 3 Compare to Other Models?
- Conclusion
- References
Introduction
-
Open-source large language models have made significant progress in recent years, but one area where they have consistently lagged behind proprietary models is in post-training—the fine-tuning processes that refine model behavior, improve alignment, and enhance instruction-following capabilities. Enter Tülu 3, an open post-trained model that not only pushes the boundaries of fine-tuning methodologies but also openly shares its training data, optimization recipes, and evaluation frameworks. Tülu 3 is based on Llama 3.1 and outperforms existing open models while competing with closed-source alternatives like GPT-4o-mini and Claude 3.5-Haiku.
-
This article provides a deep dive into Tülu 3’s architecture, training methodologies, and how it advances post-training for open-source models.
-
The figure below from the original paper shows the overall structure of Tulu 3.
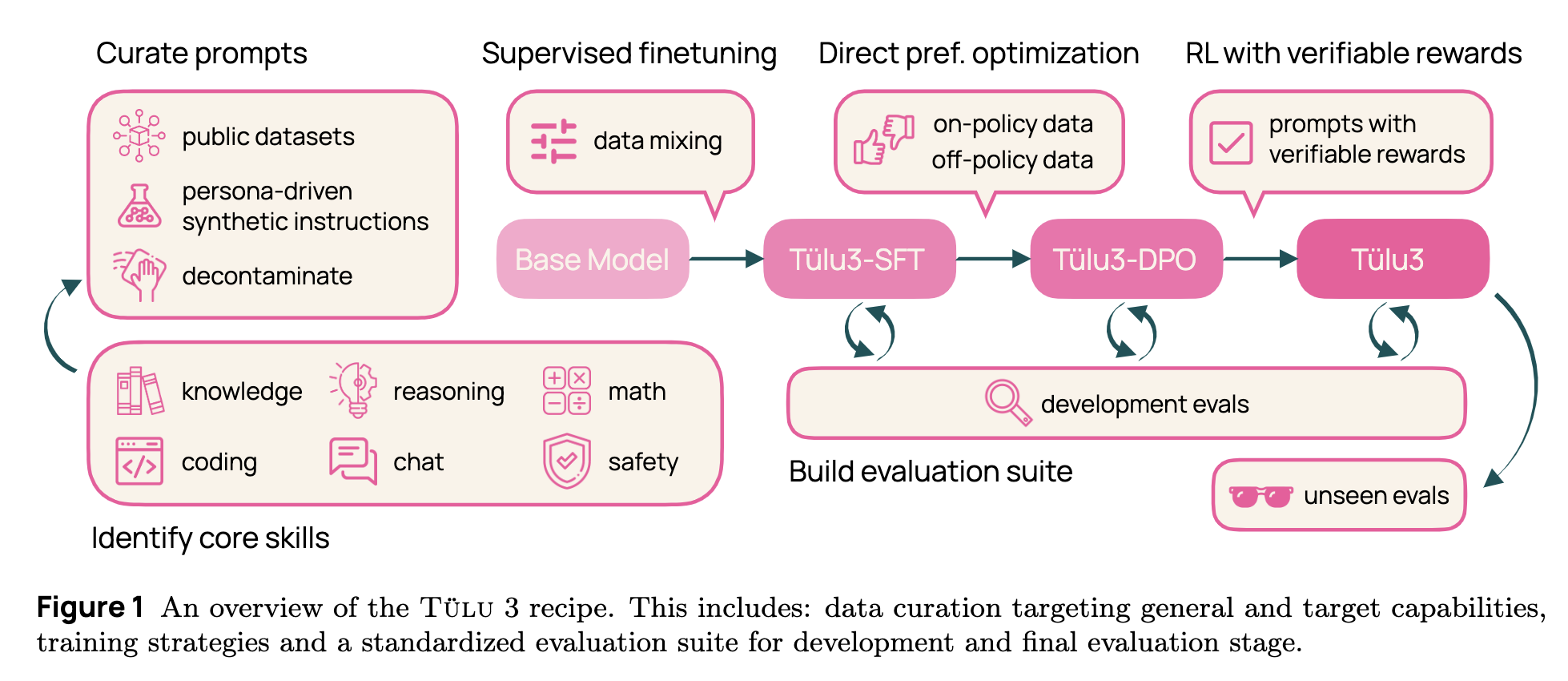
What is Tülu 3?
-
Tülu 3 is a family of post-trained language models that leverage cutting-edge fine-tuning and reinforcement learning techniques. The models are derived from Llama 3.1, a powerful open-weight base model, and trained using a sophisticated multi-stage pipeline that includes:
-
Supervised Finetuning (SFT)
-
Supervised Finetuning (SFT) is the first stage of Tülu 3’s training pipeline, where the model learns from structured, high-quality datasets curated to enhance various core skills. This process involves:
- Dataset Curation and Selection: Training prompts are sourced from open datasets, synthetic data generation, and manually curated task-specific inputs. These prompts cover a range of competencies, including reasoning, coding, mathematics, and safety.
- Skill-Specific Data Mixing: The datasets are blended with specific weightings to ensure a balanced enhancement across skills. For instance, a higher proportion of mathematical reasoning tasks ensures improvements in numerical problem-solving.
-
Iterative Model Refinements: Multiple training passes refine data distributions and eliminate suboptimal performance patterns. The model undergoes evaluation at each iteration to optimize generalization and robustness before proceeding to preference optimization.
- SFT serves as the foundational layer upon which preference optimization and reinforcement learning are applied, ensuring that Tülu 3 achieves a strong baseline of general competencies.
- Direct Preference Optimization (DPO)
-
Reinforcement Learning with Verifiable Rewards (RLVR)
- Unlike proprietary models, Tülu 3 is fully open-source, including its training data, fine-tuning recipes, model weights, evaluation framework, and training infrastructure.
Model Variants
Tülu 3 comes in multiple sizes:
- Tülu 3 8B (Llama-3.1-Tulu-3-8B)
- Tülu 3 70B (Llama-3.1-Tulu-3-70B)
-
Tülu 3 405B (Llama-3.1-Tulu-3-405B)
- Each variant follows the same training pipeline but scales across different parameter sizes.
What Makes Tülu 3 Novel?
1. Reinforcement Learning with Verifiable Rewards (RLVR)
- Traditional reinforcement learning for language models, such as RLHF (Reinforcement Learning from Human Feedback), depends on a learned reward model, which introduces biases and inconsistencies. Tülu 3 pioneers Reinforcement Learning with Verifiable Rewards (RLVR)—a new approach where models are trained on tasks with deterministic, verifiable rewards as shown below from the original paper. This technique ensures that reward signals are accurate and non-biased.
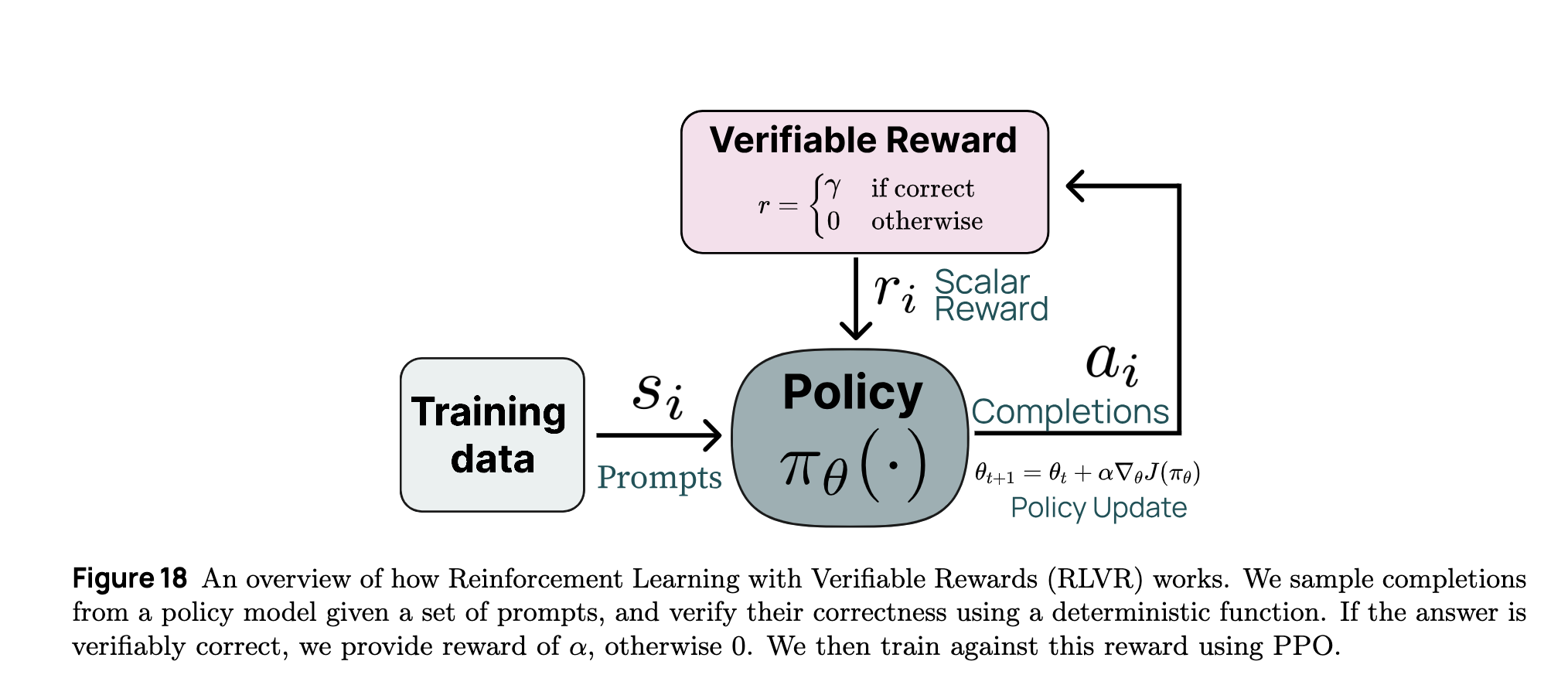
-
What makes RLVR different from Direct Preference Optimization (DPO) is its reliance on objective, verifiable reward signals rather than preference-based feedback. While DPO improves alignment using comparative preference data, RLVR directly reinforces correct behaviors by leveraging tasks where ground-truth correctness can be established. This means that RLVR is particularly effective for domains that require strict correctness verification, such as:
- Mathematical problem-solving (where correctness is unambiguous and verifiable through equations and proofs).
- Precise instruction-following (ensuring adherence to well-defined constraints and output formats).
-
Coding and logical reasoning (where program outputs can be systematically evaluated for correctness).
-
The novel aspect of RLVR lies in its reward structure. Unlike conventional RL methods, where a reward model must be trained and fine-tuned, RLVR uses a deterministic reward mechanism where model outputs are automatically verified against known solutions. This eliminates human biases in scoring and ensures greater consistency in reinforcement learning.
- Tülu 3’s RLVR implementation includes:
- Asynchronous RL training using vLLM for inference, enabling efficient learning cycles where reward verification and parameter updates run concurrently.
- Scalable RL infrastructure capable of training models up to 405B parameters, leveraging distributed computing for efficient scaling.
-
Task-specific verifiable reward functions, ensuring that only objectively correct outputs receive positive reinforcement, improving task performance without overfitting to subjective preferences.
- By introducing RLVR, Tülu 3 achieves higher reliability in structured tasks compared to preference-based optimization alone, making it one of the most advanced post-training pipelines for open-weight language models.
- Traditional reinforcement learning for language models, such as RLHF (Reinforcement Learning from Human Feedback), depends on a learned reward model, which introduces biases and inconsistencies. Tülu 3 pioneers Reinforcement Learning with Verifiable Rewards (RLVR)—a new approach where models are trained on tasks with deterministic, verifiable rewards. This technique ensures that reward signals are accurate and non-biased. RLVR is particularly effective for domains like:
- Mathematical problem-solving (where correctness is objective)
- Precise instruction-following (ensuring response constraints are met)
2. Advanced Preference Tuning (DPO)
- Tülu 3 utilizes Direct Preference Optimization (DPO), a powerful preference learning technique that optimizes models using high-quality preference data. Unlike RLHF, DPO does not require training an explicit reward model, reducing bias and improving stability.
3. Rigorous Data Curation & Decontamination
- Many open-source models suffer from data contamination, where test benchmarks inadvertently leak into training data. Tülu 3 aggressively decontaminates its datasets using:
- n-gram matching (to detect overlapping text sequences)
- embedding-based similarity (for paraphrased content detection)
-
manual dataset filtering (removing suspect samples)
- The training dataset includes over 23 million carefully curated prompts, balancing general knowledge, reasoning, coding, math, safety, and instruction following.
4. Robust Evaluation Framework (Tülu 3 Eval)
Tülu 3 introduces OLMES (Open Language Model Evaluation System), a standardized framework for evaluating post-training improvements. Key benchmarks include:
- MMLU (knowledge recall)
- GSM8K (math)
- BigBenchHard (reasoning)
- HumanEval (coding)
- AlpacaEval (instruction following)
Deep Dive into the Tülu 3 Training Pipeline
Stage 1: Supervised Finetuning (SFT)
The first stage of training focuses on supervised fine-tuning (SFT) using high-quality, curated datasets. Key considerations:
- Data selection: Prompts are sourced from public datasets and synthesized where needed.
- Skill balancing: Training data is weighted to balance core skills like reasoning, coding, and math.
- Iterative refinements: Early SFT experiments help refine data distributions before preference tuning.
Stage 2: Direct Preference Optimization (DPO)
- Preference tuning helps align the model’s responses with human-like preferences. Instead of reinforcement learning with a separate reward model (as in RLHF), Tülu 3 uses DPO, which:
- Directly optimizes the model on pairwise preference data.
- Uses length-normalized loss functions for improved stability.
- Requires no explicit reward model, reducing bias and computational cost.
Stage 3: Reinforcement Learning with Verifiable Rewards (RLVR)
- This is where Tülu 3 truly differentiates itself. RLVR uses a task-specific, verifiable reward signal instead of a learned reward model. This is particularly impactful for:
- Math problems (rewarding only correct solutions)
-
Precise instruction-following (ensuring structured constraints are met)
- Tülu 3’s RLVR pipeline includes:
- Asynchronous RL training using vLLM for inference while learners update parameters.
- Scalable RL infrastructure for 70B+ models.
- Reward functions derived from deterministic task evaluations.
How Does Tülu 3 Compare to Other Models?
- Tülu 3 not only outperforms other open models but also competes with leading proprietary LLMs. Some key performance metrics:
- Tülu 3 surpasses Claude 3.5 Haiku and GPT-3.5 Turbo in instruction following, reasoning, and safety, while performing competitively in knowledge retrieval and general chat capabilities.
Conclusion
Tülu 3 represents a significant advancement in open post-training for large language models. By combining supervised finetuning, preference optimization, and reinforcement learning with verifiable rewards, it not only closes the gap between open and proprietary models but also sets a new standard for transparency in model training.
With its fully open-source release, researchers and developers now have access to the most advanced techniques for instruction tuning and reinforcement learning, enabling further innovation in the field.
For those looking to integrate or experiment with Tülu 3, check out the model releases on Hugging Face and the training code on GitHub. The future of open AI is here, and Tülu 3 is leading the charge.