- Watermarking, a technique often employed to assert ownership or establish the origin of content, has widespread application across various mediums, including text documents. The watermark — a unique pattern or set of information — is subtly embedded within the document, serving as a tool to verify authenticity or identify the content’s source.
- In the realm of AI-generated text, watermarking presents its own unique set of challenges and opportunities. It allows for the insertion of specific phrases or patterns in the generated text, subtly indicating that a particular AI model or system was responsible for the creation of the text.
- With the evolution and growing ubiquity of AI technologies, distinguishing between human-generated and AI-generated content has become increasingly complex. Therefore, the importance of effective watermarking techniques has never been more pronounced.
- However, watermarking text data is inherently more challenging than its counterparts in the image or audio domain. This is due to the critical need to preserve the readability and context of the text. Here, we outline several methods used for watermarking text:
- Zero-Watermarking: This technique doesn’t directly insert a unique watermark into the text. Instead, it extracts text features such as word frequency and punctuation use to create a reference database, used later to verify the text’s ownership.
- Linguistic Watermarking: Leveraging the capabilities of natural language processing, this method subtly alters the text while preserving its original meaning. Changes could include the use of synonyms, paraphrasing, or embedding subtle redundancies. These watermarks can be detected by a similarly trained AI model.
- Steganography-based Watermarking: Here, the watermark is hidden within the text, ensuring it isn’t easily detected. Modifications can include altering word order or sentence structure without significant changes to the overall meaning.
- Structural Watermarking: This method embeds the watermark through alterations to the text’s structure, such as changing the number of words per sentence, the number of paragraphs, or specific punctuation usage.
- Statistical Watermarking: This technique creates a watermark by altering statistical properties of the text, such as word frequencies or the usage of specific types of words.
- The effectiveness of these watermarking techniques relies on various factors, including the complexity of the text, the watermarking method utilized, and the sophistication of the AI used to embed and detect the watermarks. Furthermore, it is critical to assess the potential impact of watermarking on the text’s readability and usability. By striking a balance between robust watermarking and text integrity, we can ensure a secure and authentic communication landscape in the era of advanced AI.”
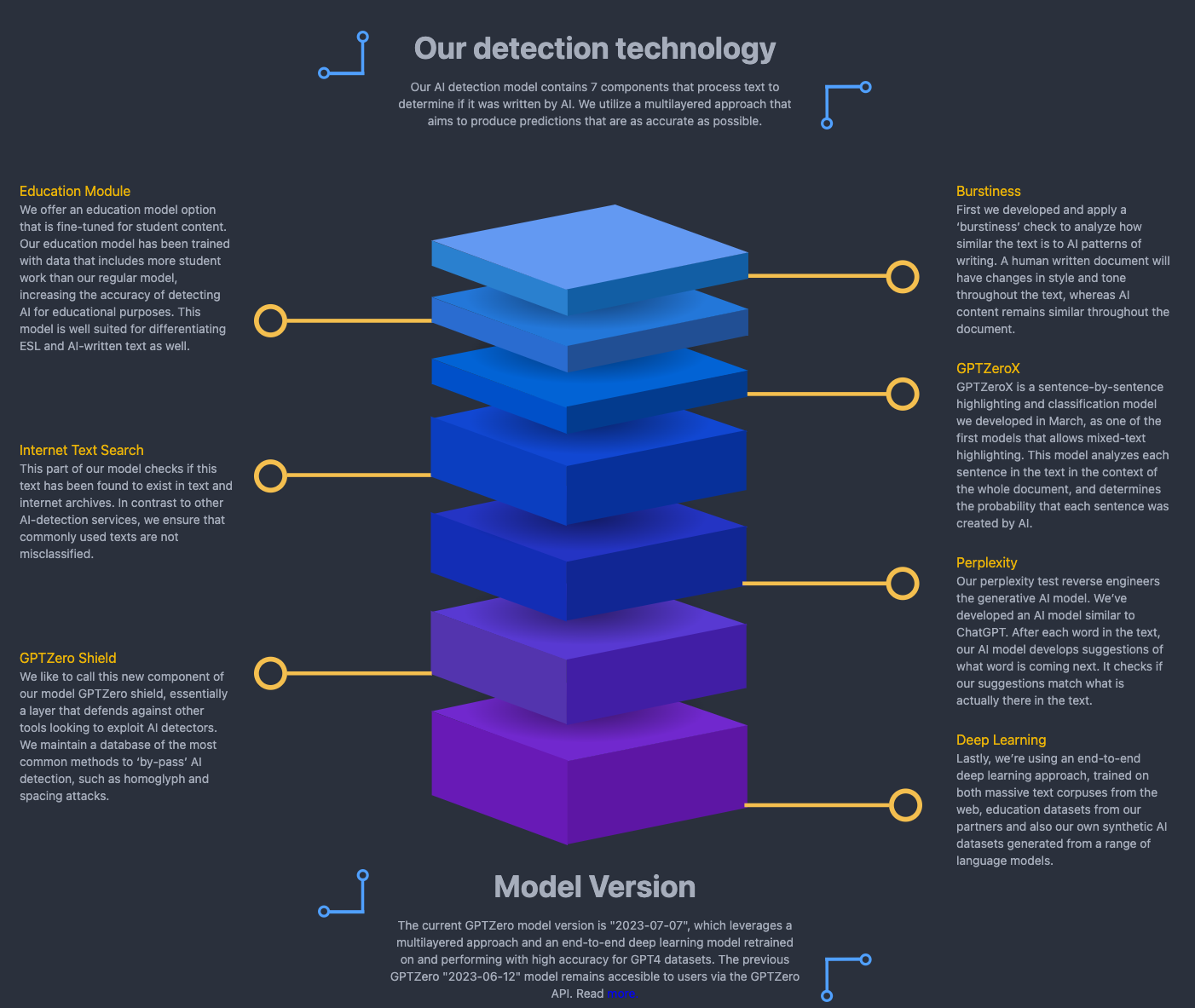
- As shown in the image below, (source), we see that when the language model generates text, it picks words based on probabilities. The “green” tokens, or watermark, are subtly promoted during this process. This means that the model is slightly more likely to choose these words or phrases, making them more frequent in the text. However, this promotion is done in a way that does not significantly impact the quality or coherence of the text.

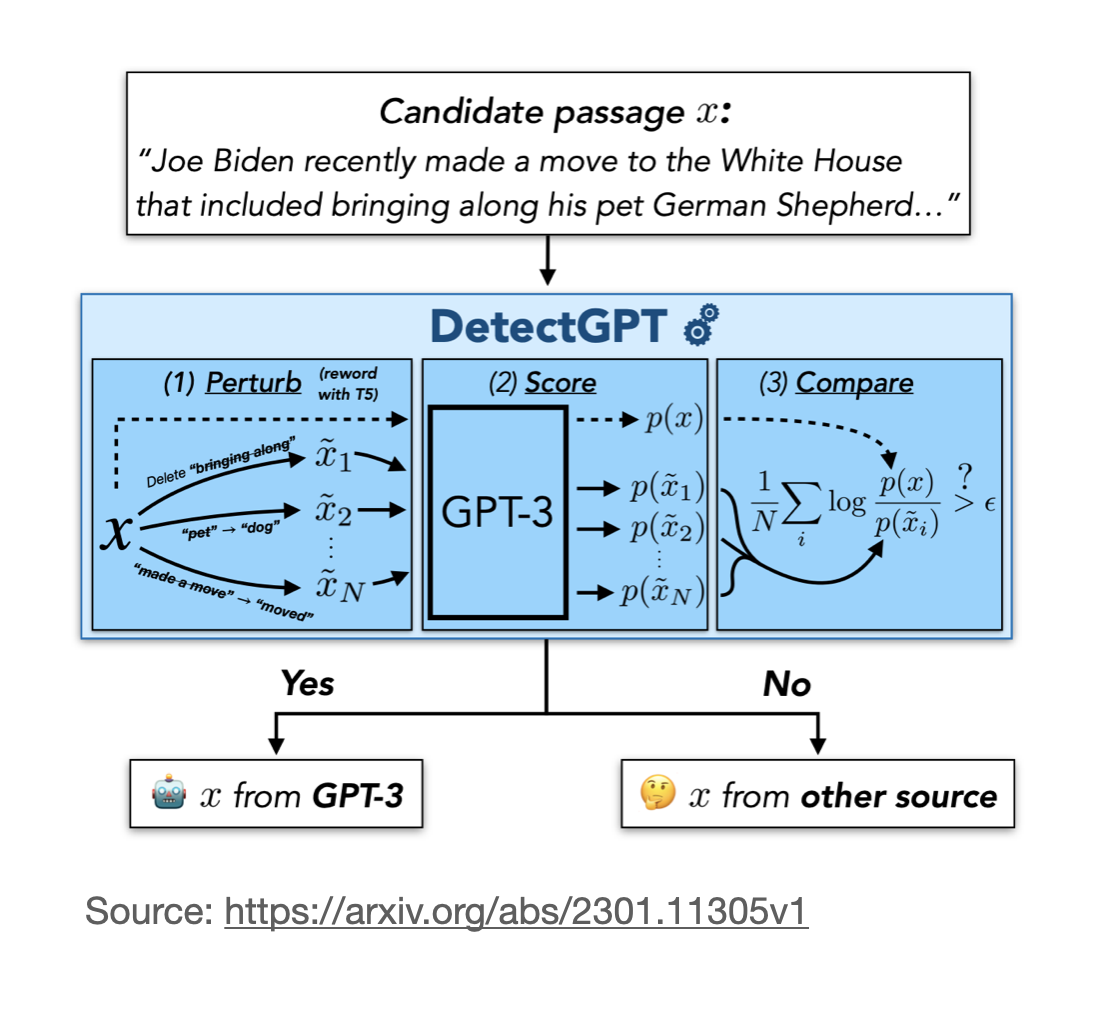
- DetectGPT’s method leverages log-probabilities of the text. “If an LLM produces text, each token has a conditional probability of appearing based on the previous tokens. Multiply all these conditional probabilities to obtain the (joint) probability for the text.”(source)
- What DetectGPT does is it perturbs the text and then compares the log probabilities of both, pre-perturbed and perturbed text. If the new log-probability is significantly lower, its AI generated, otherwise it is human generated.
- The image below, (source), displays the perturbation, scoring and comparison process.
Stylometry
- Stylometry is the study of linguistic style, and it’s often used to attribute authorship to anonymous or disputed documents.
- In AI detection, stylometry can be used to identify the distinct ‘style’ of a particular AI model, based on certain features like word usage, sentence structure, and other linguistic patterns.
- Stylometry is a field of study within computational linguistics and digital humanities that involves the quantification and analysis of literary style through various statistical and machine learning methods. The core premise of stylometry is that authors have a distinct and quantifiable literary “fingerprint” that can be analyzed and compared.
- Stylometric analysis is performed using features such as word length, sentence length, vocabulary richness, frequency of function words, and usage of certain phrases or structures. These features are then subjected to various statistical analyses to identify patterns.
- Here are a few applications and techniques used in stylometry:
- Authorship Attribution: Stylometry can help identify or confirm the author of a text based on stylistic features. This can be useful in literary studies, forensics, and even in cases of disputed authorship or anonymous texts.
- Author Profiling: By analyzing the stylistic features of a text, it’s possible to make predictions about the author’s demographics, including age, gender, native language, or even psychological traits.
- Text Categorization: Stylometry can also be used to classify texts into different genres, types (fiction vs non-fiction), or time periods based on stylistic features.
- Machine Learning Techniques in Stylometry: In recent years, machine learning techniques have been increasingly applied to stylometry. Methods such as Support Vector Machines (SVM), Random Forests, and Neural Networks are used to classify texts based on stylistic features.
- N-gram Analysis: This is a common technique in stylometry that involves counting sequences of ‘n’ words or characters. N-gram analysis can help capture patterns of language use that are distinctive to a particular author.
- Function Words Analysis: Function words are words that have little meaning on their own but play a crucial role in grammar (like ‘and’, ‘the’, ‘is’). Authors tend to use function words unconsciously and consistently, making them a valuable tool for stylometric analysis.
- It should be noted that while stylometry can be powerful, it also has its limitations. The results can be influenced by factors such as the genre of the text, the author’s conscious changes in style, and the influence of co-authors or editors. Furthermore, while stylometry can suggest patterns and correlations, it can’t definitively prove authorship or intent.
- “GPTZero computes perplexity values. The perplexity is related to the log-probability of the text mentioned for DetectGPT above. The perplexity is the exponent of the negative log-probability. So, the lower the perplexity, the less random the text. Large language models learn to maximize the text probability, which means minimizing the negative log-probability, which in turn means minimizing the perplexity.
- GPTZero then assumes the lower perplexity are more likely generated by an AI.
- Limitations: see DetectGPT above. Furthermore, GPTZero only approximates the perplexity values by using a linear model.” Sebastian Raschka
- In addition, as we an see in the image below, (source), it now takes into consideration burstiness to check how similar the text is to AI patterns of writing.
- Human written text as changes in style and tone whereas AI content remains more-so consistent throughout.