NLP • Personalizing Large Language Models
- Overview
- Prompt Engineering
- Retrieval Augmented Generation (RAG)
- Parameter-Efficient Finetuning (PEFT)
- Finetuning
- References
- Citation
Overview
- Given the plethora of Large Language Models (LLMs) at our disposal, ranging from publicly available versions like ChatGPT and LLama to specialized ones such as BloombergGPT for specific sectors, the challenge emerges: How can we harness their capabilities beyond their primary training objectives?
- In this article, we will delve into different methods of leveraging LLMs for new tasks, their respective benefits, and when to use which method.
Prompt Engineering
- As we saw in the earlier prompt-engineering article, prompting is a method for steering an LLM’s behavior towards a particular outcome without updating the model’s weights/parameters.
- It’s the process of effectively communicating with AI about desired results.
- Prompting with context involves manually selecting relevant contexts to include in the prompt to condition the LLM. The contexts are static and pre-selected and do not involve any gradient updates.
- The image below (source) displays how the end to end process of prompt engineering providing context to the LLM.
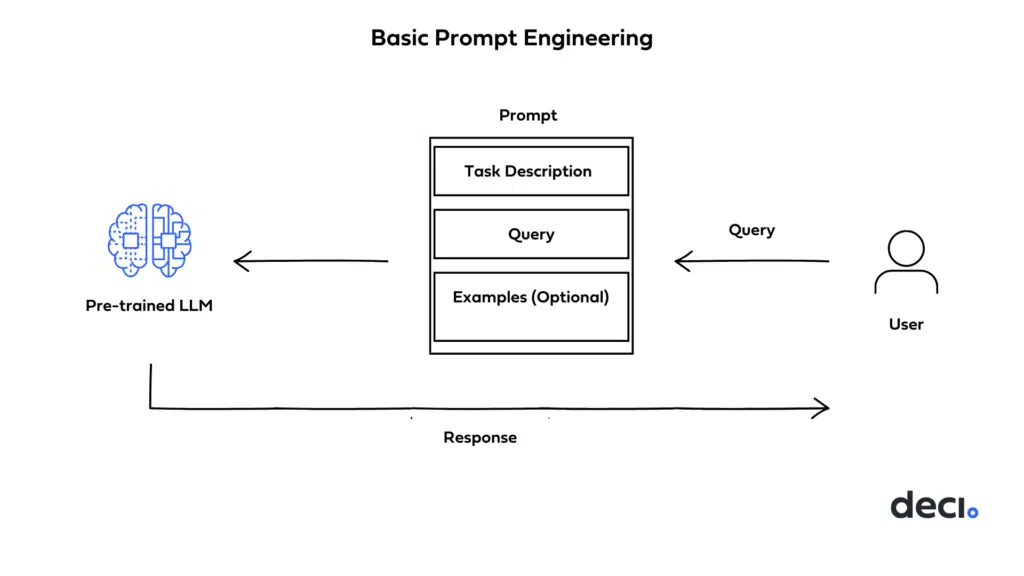
- There are many flavors of prompting such as:
- Zero-shot prompting: which involves feeding the task to the model without any examples that indicate the desired output
- Few-shot prompting: which involves providing the model with a small number of high-quality examples that include both input and desired output for the target task
- Chain-of-thought prompting: generates a sequence of short sentences known as reasoning chains
- Chain-of-verification prompting: designs a plan of verification and executes it
- Examples:
- If you prompt your LLM about movies, and it hallucinates, provide the movie plot, actors, and other relevant details to ground the conversation.
- Pros:
- Computationally very cheap and quite fast as the prompt can be passed to a backend software system to help add extra context.
- Quick to test on new tasks
- Cons:
- May involve a lot of trial and error to understand what context to provide the prompt to get desired outputs
- When to use:
- Use prompt engineering to rapidly prototype new capabilities and to ground open-ended conversations
Retrieval Augmented Generation (RAG)
- With RAG, the LLM is able to leverage knowledge and information that is not necessarily in its weights by providing it access to external knowledge sources such as databases.
- It leverages a retriever to find relevant contexts to condition the LLM, in this way, RAG is able to augment the knowledge-base of an LLM with relevant documents.
- The retriever here could be any of the following depending on the need for semantic retrieval or not:
- Vector database: Query can be embedded using BERT for dense embeddings or TF-IDF for sparse embeddings and search with term frequency
- Graph database
- Regular SQL database
- The image below from Damien Benveniste, PhD talks a bit about the difference between using Graph vs Vector database for RAG.
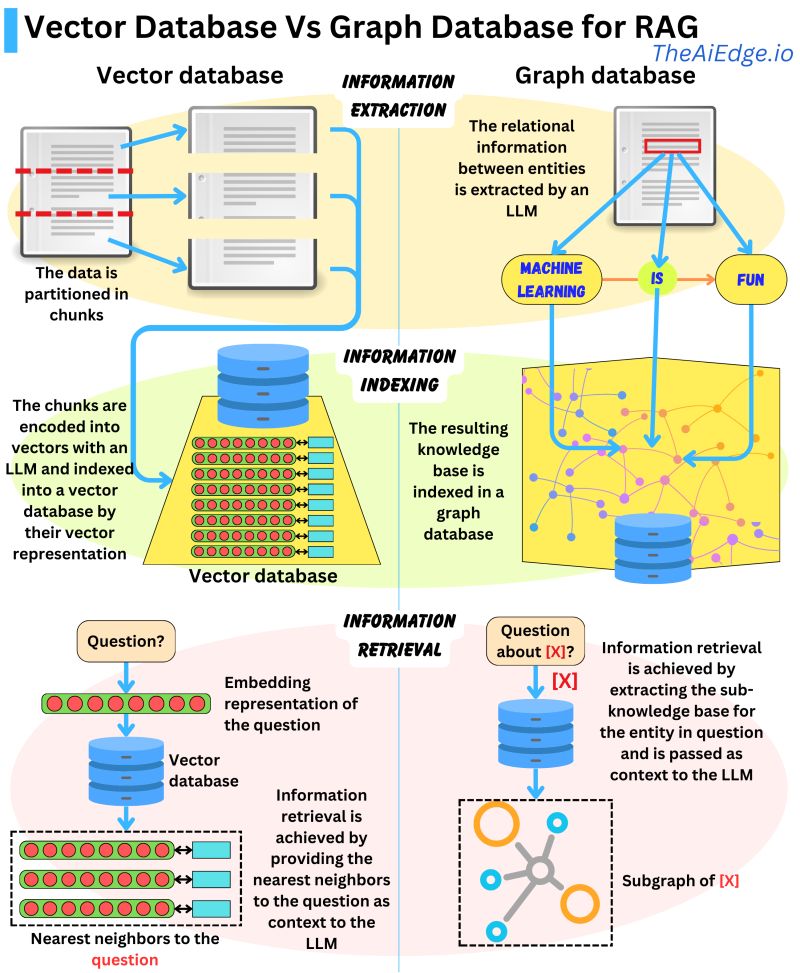
- In his post linked above, Damien states that Graph Databases are favored for Retrieval Augmented Generation (RAG) when compared to Vector Databases. While Vector Databases partition and index data using LLM-encoded vectors, allowing for semantically similar vector retrieval, they may fetch irrelevant data.
- Graph Databases, on the other hand, build a knowledge base from extracted entity relationships in the text, making retrievals concise. However, it requires exact query matching which can be limiting.
-
A potential solution could be to combine the strengths of both databases: indexing parsed entity relationships with vector representations in a graph database for more flexible information retrieval. It remains to be seen if such a hybrid model exists.
- After retrieving, you may want to look into filtering the candidates further by adding ranking and/or fine ranking layers that allow you to filter down candidates that do not match your business rules, are not personalized for the user, current context, or response limit.
- Let’s succinctly summarize the process of RAG and then delve into its pros and cons:
- Vector Database Creation: RAG starts by converting an internal dataset into vectors and storing them in a vector database (or a database of your choosing).
- User Input: A user provides a query in natural language, seeking an answer or completion.
- Information Retrieval: The retrieval mechanism scans the vector database to identify segments that are semantically similar to the user’s query (which is also embedded)RA. These segments are then given to the LLM to enrich its context for generating responses.
- Combining Data: The chosen data segments from the database are combined with the user’s initial query, creating an expanded prompt.
- Generating Text: The enlarged prompt, filled with added context, is then given to the LLM, which crafts the final, context-aware response.
-
The image below (source) displays the high-level working of RAG.
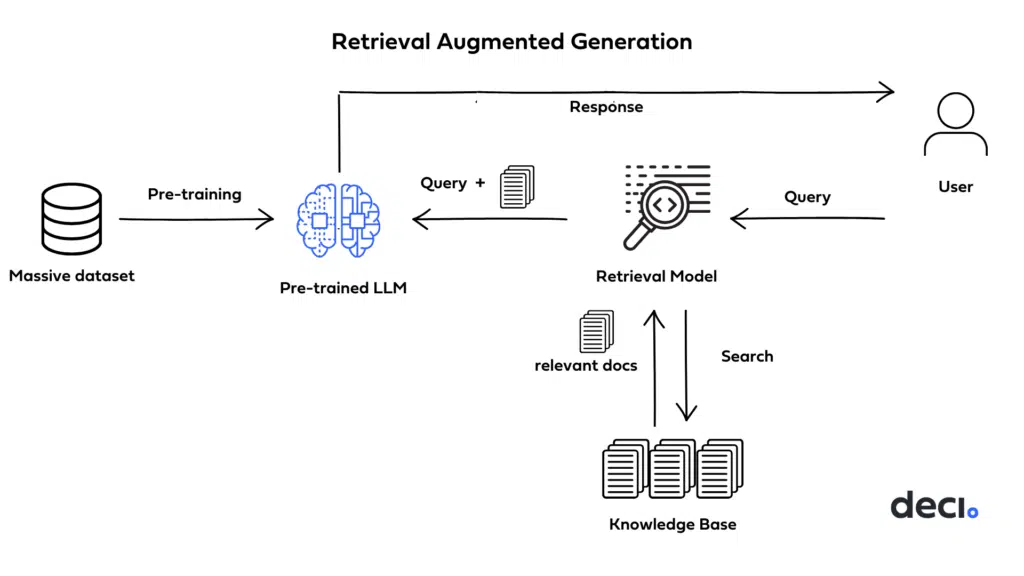
- One question that may arise is, how is RAG different from Prompting that we mentioned earlier. There are a few subtle differences:
- Retrieval augmented generation retrieves relevant contexts from a large indexed corpus to condition the LLM. The contexts are retrieved dynamically during inference.
- Prompting with context involves manually selecting relevant contexts to include in the prompt to condition the LLM. The contexts are static and pre-selected.
- Summary:
- Retrieval augmentation automatically retrieves contexts at inference time.
- Prompting uses pre-selected static contexts provided in the prompt.
- Pros:
- Does not update the model’s parameters, so no training time/compute required
- Works well with limited unlabeled data
- Cons:
- Limited by the retrievers knowledge base, must constantly be kept up to date.
- **When to use: **
- Use retrieval augmentation when you have unlabeled data but limited labeled data.
- You want an assistant to answer user questions about products such as retrieve relevant product manuals and concatenate to the input to condition the LLM.
Parameter-Efficient Finetuning (PEFT)
- PEFT enables us to adapt a pre-trained model to downstream tasks more efficiently – in a way that trains lesser parameters and hence saves cost and training time, while also yielding performance similar to full finetuning.
- There are many flavors of PEFT such as:
- LoRA - Uses a small set of new task-specific parameters
- QLoRa - Quantizes model weights for efficiency
- Soft Prompting - New task prompts used to steer model behavior
- Hard Prompting - Task prompts inserted as extra tokens
- Prefix Tuning - Only the first layers are finetuned
- The image below (source) displays the high-level working of PEFT.
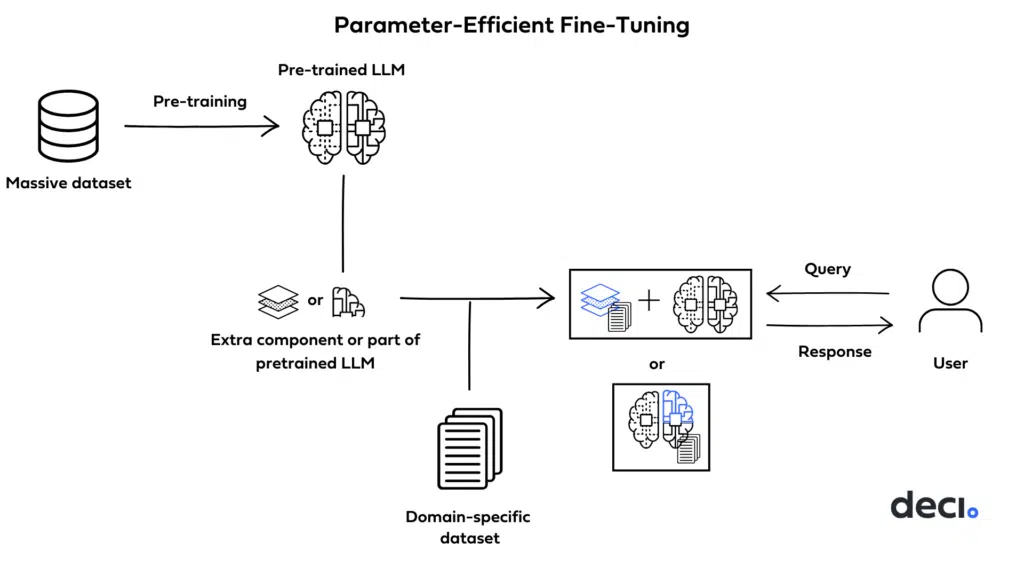
- Pros:
- Unlike full finetuning, catastrophic forgetting is not a concern since the original parameters of the model are frozen and untouched
- Allows continuous learning on new tasks with limited data
- Works well when want to adapt to new tasks with limited compute
- Cons:
- Performance may not be as good as full finetuning since the model is more constrained
- When to use:
- You have a model trained on many tasks. Finetune just the classifier head to adapt it to a new niche categorization task with limited data.
- For more details, please refer to the PEFT article.
Finetuning
- In full finetuning, we take the pre-trained LLM and look to train it on a new task with labeled dataset. In this process, we update the models parameters to be optimized for our new task.
- Per Surgical Fine-Tuning by Lee et al., we learn how to know which layer of the model to finetune as defined below:
- A quick note here before we start, the Surgical fine-tuning paper, whose contents are mentioned below, focuses on computer vision and does not directly deal with large language models (LLMs). The techniques are applied to convolutional neural networks and vision transformers for image classification tasks. 1) For input-level shifts like image corruptions, finetuning earlier layers (first conv block) tends to work best. This allows the model to adapt to changes in the input while preserving higher-level features. 2) For feature-level shifts where the feature representations differ between source and target, finetuning middle layers (middle conv blocks) tends to work well. This tunes the mid-level features without distorting low-level or high-level representations. 3) For output-level shifts like label distribution changes, finetuning later layers (fully connected classifier) tends to be most effective. This keeps the feature hierarchy intact and only adapts the output mapping.
- Try finetuning only a single contiguous block of layers while freezing others. Systematically test first, middle, and last blocks to find the best one.
- Use criteria like relative gradient norms to automatically identify layers that change the most for the target data. Finetuning those with higher relative gradients can work better than full finetuning.
- When in doubt, finetuning only the classifier head is a solid default that outperforms no finetuning. But for shifts related to inputs or features, surgical finetuning of earlier layers can improve over this default.
- If possible, do some quick validation experiments to directly compare different surgical finetuning choices on a small held-out set of target data.
-
The key insight is that different parts of the network are best suited for adapting to different types of distribution shifts between the source and target data.
- The image below (source) displays the high-level working of full finetuning.
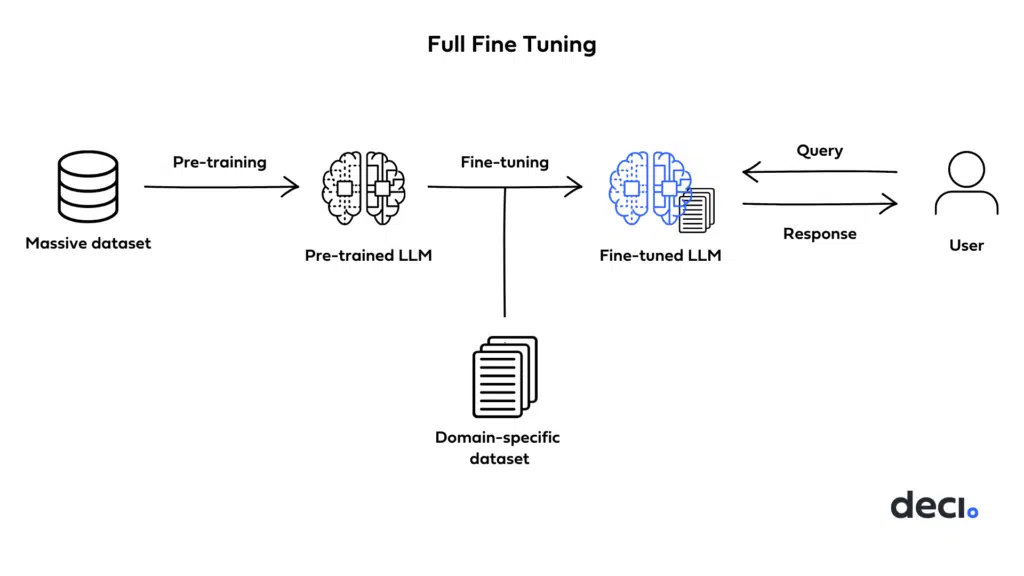
- Pros:
- Works well with a large set of data
- Less data than fully retraining
- Enhanced accuracy as it will grasp nuances of the particular task
- Cons:
- Catastrophic forgetting of the original task the LLM was trained on
- Requires a large dataset and compute for training, else will overfit to the training data if its small
- When to use:
- Use finetuning when you have sufficient labeled data, compute, and don’t require frequent updates for new tasks/data.
References
Citation
@article{Chadha2020DistilledPersonalizingLLMs,
title = {Personalizing Large Language Models},
author = {Chadha, Aman and Jain, Vinija},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}