Reinforcement Finetuning
- Reinforcement Finetuning
- Reinforcement Learning with Verifiable Rewards (RLVR)
Reinforcement Finetuning
- Reinforcement Finetuning (RFT) was introduced by OpenAI as part of their innovation roadmap to enable precise, task-specific improvements in language models.
- Key Feature: RFT empowers users to customize models for domain-specific tasks using their own datasets, achieving advanced reasoning capabilities beyond simple replication of inputs.
- While Supervised Finetuning (SFT) specializes in replicating desired patterns such as tone or style, RFT enables the model to develop reasoning strategies tailored to custom domains.
- RFT does not merely mimic patterns but encourages the model to explore problem-solving pathways, with its outputs graded for correctness or alignment.
- Rewards incentivize “right thinking” and penalize incorrect reasoning, enabling significant task improvements with as few as 12 curated examples.
Deep dive into RFT
- The RFT process is grounded in ranking-based reasoning:
- The model generates outputs ranked from most likely to least likely, allowing for iterative improvement as we can see below. (source)
- The model generates outputs ranked from most likely to least likely, allowing for iterative improvement as we can see below. (source)
- Outputs are graded using automated systems or human feedback.
- A grader model evaluates the alignment of model outputs with desired results on a scale from 0 to 1, enabling partial credit and nuanced feedback.
- Custom graders tailored to specific tasks are integral to RFT’s flexibility and domain alignment.
Reinforcement Learning with Verifiable Rewards (RLVR)
- Reinforcement Learning with Verifiable Rewards (RLVR) is a reinforcement learning framework tailored for training large language models (LLMs) to excel in tasks with deterministic correctness criteria. It builds on the foundational supervised finetuning (SFT) of LLMs and introduces a reinforcement learning mechanism that leverages binary or scaled rewards derived from explicit task validations. Unlike conventional reinforcement learning techniques such as PPO (Proximal Policy Optimization) or standard RLHF (Reinforcement Learning with Human Feedback), RLVR optimizes for precision by using tasks with verifiable ground truths, ensuring that the model’s performance on critical domains like mathematics, coding, and instruction following is measurably improved.
- Per Nathan Lambert’s tweet, “OpenAI announced a new RL finetuning API. You can do this on your own models with Open Instruct – the repo we used to train Tulu 3. Expanding reinforcement learning with verifiable rewards (RLVR) to more domains and with better answer extraction (what OpenAI calls a grader, a small LM) and to more domains in our near roadmap.”
- Since we do not have too much information on RFT yet, let’s dive deeper into RLVR.
Core RLVR Framework and Technical Details
1. Objective-Centric Reward Signal
RLVR focuses on tasks with deterministic evaluation mechanisms, avoiding reliance on human preference models or heuristic approximations:
- Binary Rewards: The model receives a reward of
1for outputs that are validated as correct and0otherwise.- Example: Solving a math problem where the answer must match the pre-determined solution exactly.
- Continuous or Scaled Rewards: For tasks with partially correct outputs (e.g., coding challenges with test cases), rewards are proportional to the percentage of successful validations.
2. Task Suitability
RLVR applies to domains with clear correctness measures:
- Mathematics:
- Tasks are curated from datasets like GSM8K and MATH, where solutions can be verified against symbolic or numeric solvers.
- Coding:
- Outputs are validated using unit tests or execution environments that determine code correctness and efficiency.
- Precise Instruction Following:
- Tasks include constraints such as producing outputs with a specific number of words or paragraphs, validated through automated heuristics.
3. Data Preparation
Data is carefully curated and preprocessed to align with RLVR’s requirements:
- Prompts and Ground Truths:
- Each training instance includes a prompt and a verifiable output.
- Decontamination:
- Overlap with evaluation datasets is minimized using n-gram-based contamination checks. Instances with >50% token overlap between training and evaluation sets are excluded.
RLVR Training Architecture
- As shown below from TULU 3’s paper, RLVR has a very similar grader model to what OpenAI is proposing that helps the model score the outputs from the model.
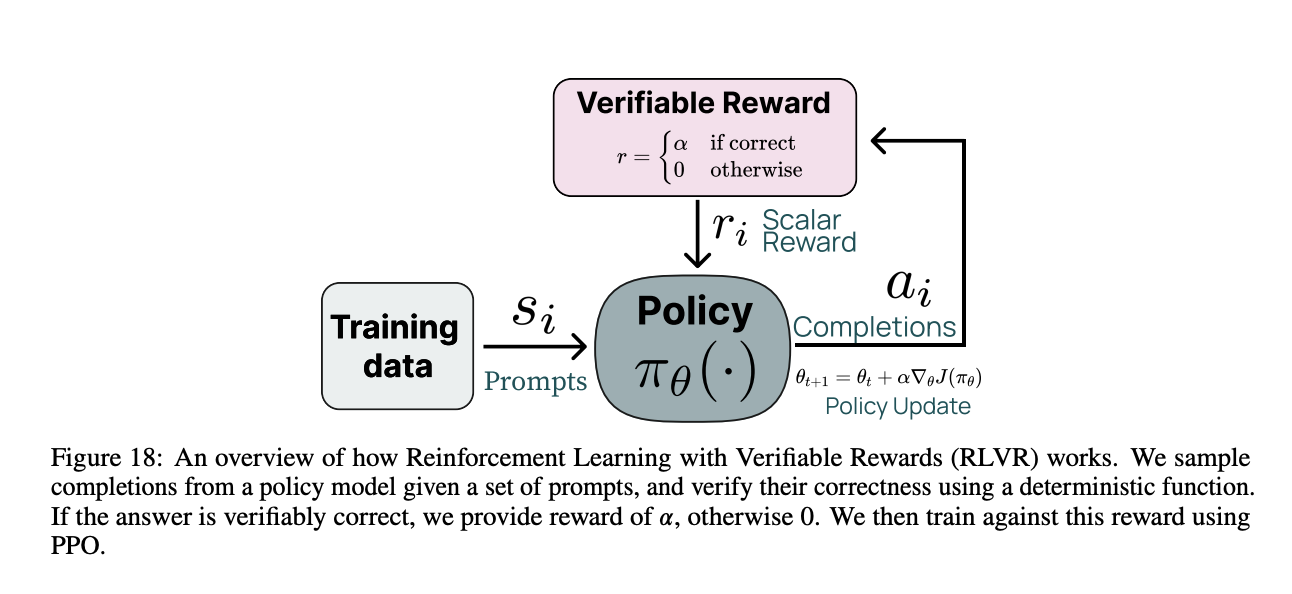
1. Reinforcement Learning Process
RLVR integrates a policy-gradient reinforcement learning mechanism to optimize the model’s ability to produce verifiably correct outputs. The key components are:
- Policy Model:
- A decoder-only transformer initialized from the SFT-trained model checkpoint.
- Environment:
- Tasks are treated as environments where the model generates responses, and external validators evaluate these responses for correctness.
- Reward Function:
- Binary or scaled rewards are computed based on task-specific validation results.
- Loss Function:
- Combines the standard policy gradient loss with entropy regularization to encourage exploration without deviating from valid solution paths.
2. Infrastructure
RLVR employs an asynchronous training infrastructure to handle large-scale models effectively:
- Asynchronous Learners:
- Model inference (output generation) runs parallel to gradient updates, ensuring continuous training.
- Efficient Inference Engine:
- The vLLM framework is utilized to accelerate output generation for policy evaluation.
- Gradient Updates:
- Policy gradients are updated concurrently as rewards are computed.
3. Multi-Stage Pipeline
RLVR is deployed as the final stage in a multi-step post-training pipeline:
- Stage 1: Supervised Finetuning (SFT):
- The model is trained on curated datasets to achieve broad generalization and baseline task competency.
- Stage 2: Preference Tuning (e.g., DPO):
- Model responses are compared against baseline and reference outputs, and preference-based feedback is incorporated.
- Stage 3: RLVR:
- The model is fine-tuned further using verifiable reward signals, specifically targeting tasks requiring precision.
Performance Results
- RLVR consistently outperforms traditional post-training approaches across key benchmarks:
- Mathematics:
- Achieves 93.5% accuracy on GSM8K (8-shot) and 63% on MATH (4-shot), a significant improvement over SFT-only models.
- Coding:
- Pass@10 accuracy on HumanEval reaches 92.4%, with similarly high results on HumanEval+.
- Precise Instruction Following:
- IFEval benchmark accuracy rises to 83.2%, showcasing the model’s ability to follow complex, verifiable instructions.
- Mathematics:
Key Insights and Applications
- Focused Optimization:
RLVR improves task-specific precision by prioritizing verifiability over broad generalization. It excels in domains where correctness is non-negotiable, such as:
- Mathematical reasoning.
- Software development tasks.
- Constrained or regulated text generation.
-
Scalability: RLVR’s asynchronous infrastructure enables training on models with billions of parameters, such as Llama 3.1 70B, while maintaining training efficiency.
- Generalization Maintenance: RLVR is carefully balanced with supervised finetuning objectives to prevent over-optimization on narrow tasks, preserving the model’s general-purpose capabilities.
Challenges and Future Directions
- Applicability:
- RLVR relies on deterministic correctness criteria, limiting its applicability to tasks without clear evaluation metrics.
- Infrastructure Demands:
- Training RLVR on large-scale models requires extensive computational resources, posing accessibility challenges for smaller research teams.
- Skill Integration:
- Balancing RLVR with broader skill sets remains a challenge to ensure the model performs well on open-ended tasks alongside deterministic ones.
- Reinforcement Learning with Verifiable Rewards (RLVR) is a groundbreaking training methodology that refines language model performance by leveraging verifiable outcomes. Its integration into the TÜLU 3 training pipeline has demonstrated substantial improvements in task-specific benchmarks, providing a replicable and scalable framework for future LLM development. By addressing high-precision tasks with rigorously defined correctness criteria, RLVR sets a new standard in post-training methodologies for open and transparent language model development.