Overview
- With the release of several conversational LLM’s, we see a greater need to be able to detect whether a given text is generated from a human or an AI.
- The need for detection of text generated by AI will become pivotal for institutions such as academia where they need to ensure students assignments are not written by LLMs.
- Additionally, in terms of publication of research, it may also be needed to ensure that the authors submitting to conferences have in fact written their own research papers.
- Furthermore, industries that regularly rely on text publication, such as newspapers and magazines, will also require detection of human vs AI generated text to maintain their factual credibility.
- If LLM’s are used in such ways, they deter student’s abilities to learn and be assessed fairly. In addition, news generated via LLMs tend to lean towards generation of inaccurate facts, spreading information that is not credible.
- Humans do not perform well at detection of AI vs human generated text, thus, this is why there is a need for different methods of doing just that.
- There are several solutions already proposed, such as watermarking the generated text.
- Below, we will look at that and several other proposed solutions!
- DetectGPT alters from other methods because it takes the text generation detection problem as a binary classification problem.
- Their objective is to classify whether a candidate passage was generated by a particular source model.
- “To test if a passage came from a source model \(pθ\), DetectGPT compares the log probability of a candidate passage under \(pθ\) with the average log probability of several perturbations of the passage under \(pθ\) (generated with, e.g., T5; Raffel et al. (2020)).” (source)
- The idea behind DetectGPT is it first generates minor perturbations on a passage using pre-trained models such as T5 and then compare their log probability to determine if the text is generated from a human or a LLM.
- The hypothesis the authors of this paper make is that model-generated text in the log probability tends to lie where the log probability function has negative curvature. This could be where it’s at the local maxima of the log probability. They have found this to hold true for other LLMs as well even with minor rewrites which they refer to as perturbations occur from alternative models.
- In addition, DetectGPT uses zero-shot machine-generated text detection by detecting whether a piece of text comes from a particular source model without access to any human-written or machine-generated samples. It assumes a white-box setting where the detector can evaluate the log probability of a sample, without access to the model architecture or parameters. DetectGPT does this via the use of pre-trained mask-filling models to generate passages that are similar to the candidate passage.
- As such, it does not require having text be explicitly watermarked, and it does require training a seperate classifier with generated and not generated text.
Architecture

- The image above (source) describes the basic architecture of DetectGPT in 3 steps.
- Perturb: DetectGPT takes the generated text and adds minor perturbations to it via a pre-trained model such as T5.
- Score: DetectGPT determines the log probability of each sample and perturbed sample.
- Compare: DetectGPT compares the log probability of a candidate passage under a source model with the average log probability of several perturbations of the passage under the same model. If the perturbed passages tend to have lower average log probability than the original by some margin, the candidate passage is likely to have come from the source model and the algorithm below (source) displays that.
- “We can approximate directional second derivatives by perturbing the text a bit with T5 & comparing the logprob under the LM before and after. Add Hutchinson’s trace estimator & we get approximate trace of the Hessian.” (source)

- The image below (source) displays the fact that machine-generated passages \((x ∼ pθ(·))(left)\) have a tendency to exist in regions with negative curvature of \(log p(x)\), while it’s neighboring samples tend to have lower model log probability on average. On the other hand, human-written text \((x ∼ p_real(·))(right)\) tends to avoid areas with clear negative curvature of log probability.
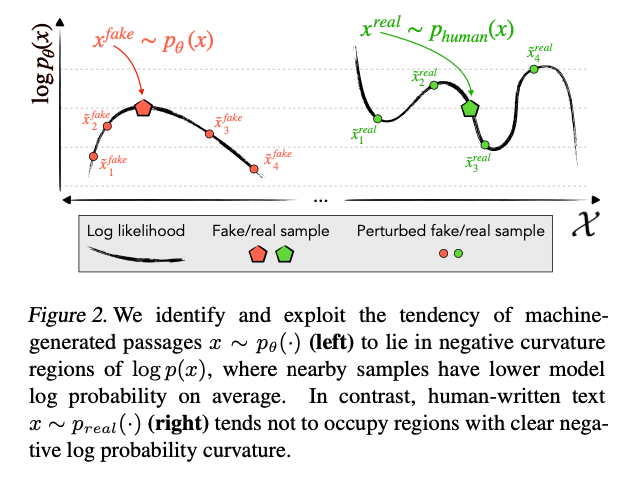
- The image below (source) shows how DetectGPT takes the approximate Hessian trace and thresholds it to get a detector. If the trace is very negative, it’s likely a sample generated from a model.
- The algorithm below (source) summarizes the normalized DetectGPT.
Results
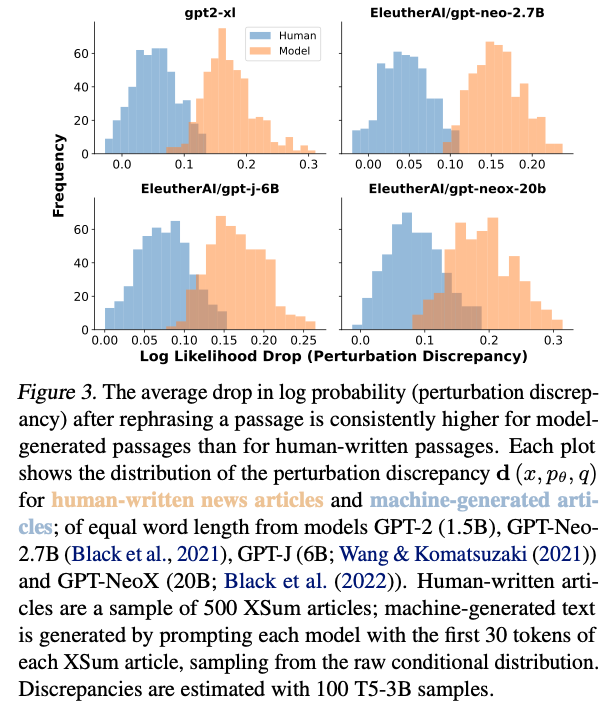
- DetectGPT is found to be more accurate than existing zero-shot methods for detecting machine-generated text, improving over the strongest zero-shot baseline by over 0.1 AUROC for multiple source models when detecting machine-generated news articles.
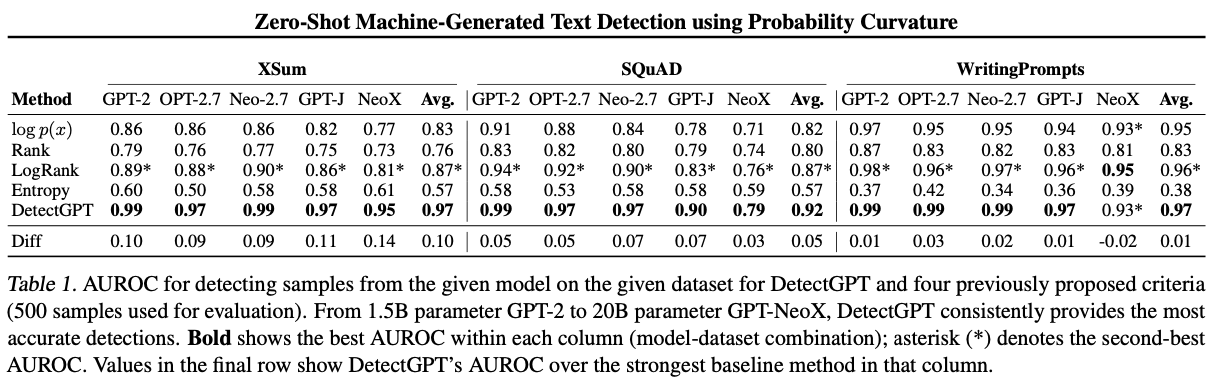
- As we can see from the table above (source), DetectGPT consistently outperforms it’s competitors and provides the most accurate detection.
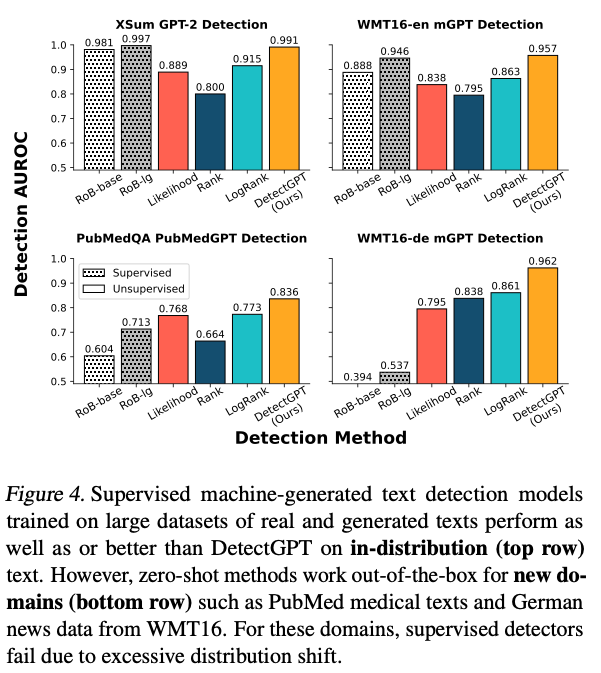
- Lastly, from the graph above (source), we see that supervised models for detecting machine-generated text perform well on familiar texts, while DetectGPT’s zero-shot method works better for new types of text, where supervised models struggle due to big differences from what they were trained on.
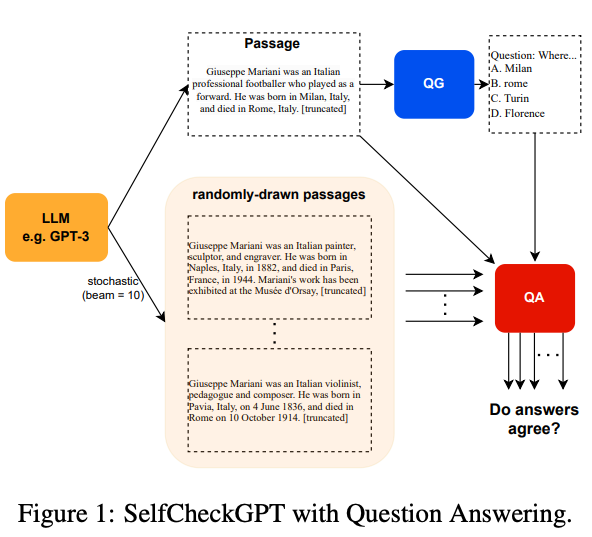
- SelfCheckGPT is a sampling-based approach for fact-checking blackbox language models, and it leverages the idea that a language model’s responses are likely to be consistent and similar if it has knowledge of a given concept.
- SelfCheckGPT can detect factual and non-factual sentences and rank passages in terms of factuality.
- The approach performs well compared to existing baselines in sentence hallucination detection and is best at assessing passage factuality.
- Per the author’s analysis, factual sentences tend to have tokens with higher liklihood and lower entropy and in contrast, hallucinations tend to have high uncertainty and flat probability distributions.
Architecture
References