Gradient Accumulation and Checkpointing
Overview
- With models getting larger, running out of GPU memory and getting a
CUDA: out of memory (OOM) errorhas become more ubiquitous. - In this article, we will talk about a few ways to make the training process more efficient by some gradient hacks and use GPU memory optimally.
Gradient Accumulation
- Gradient accumulation is a technique used to overcome memory limitations when training large models or processing large batches of data. Normally, during backpropagation, the gradients of the model parameters are calculated and updated after each batch of data. However, in gradient accumulation, instead of updating the parameters after each batch, the gradients are accumulated over multiple batches before performing a parameter update. This allows for a more memory-efficient training process by reducing the memory requirements for storing gradients.
- For example, if gradient accumulation is set to accumulate gradients over four batches, the gradients of the model parameters are summed over these batches, and the parameter update is applied once after the accumulation. This reduces the memory footprint by performing fewer updates and enables training with larger batch sizes or more complex models.
- Gradient accumulation is a technique used in deep learning to increase the effective batch size during training. Normally, the weights of a neural network are updated based on the gradients computed from a single batch of training data. However, for larger models or datasets, the batch size may be limited by the memory capacity of the GPU, leading to a significantly longer time to convergence due to vectorization.
- As shown in the image below (source), gradient accumulation splits the batch of samples (that are used to train a neural network) into several mini-batches that are run sequentially. Put simply, the idea behind gradient accumulation is to accumulate the gradients iteratively over several mini-batches.
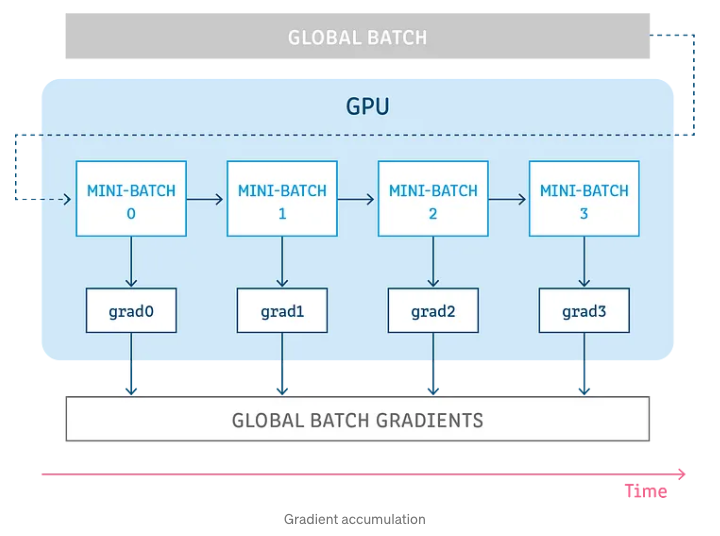
- Once we have enough gradients accumulated via the above process, we run the model’s optimization step (via the usual
optimizer.step()) to increase the overall batch size. - The code sample below (source] shows how the model gets impacted positively by gradient accumulation.
training_args = TrainingArguments(per_device_train_batch_size=1, gradient_accumulation_steps=4, **default_args)
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
result = trainer.train()
print_summary(result)
> BEFORE
Time: 57.82
Samples/second: 8.86
GPU memory: 14949 MB
> AFTER
Time: 66.03
Samples/second: 7.75
GPU memory: 8681 MB
- Gradient accumulation can lead to slower convergence and longer training times, as the gradients are accumulated over several mini-batches before an update is made. However, it can be a useful technique in situations where memory is limited and a larger effective batch size is desired (especially with contrastive learning where larger batch sizes lead to better learning due to added diversity within large training batches).
- The code below helps illustrate the basic idea behind gradient accumulation. In it, we train a loop of
num_iterationsiterations and within each iteration,accumulation_stepmini-batches are processed before updating the weights. - During each iteration, the gradients for each mini-batch are computed separately using
compute_gradients(). The gradients for each mini-batch are then accumulated in accumulated_gradients variable. After processing accumulation_steps mini-batches, the accumulated gradients are then used to update the weights usingupdate_weights().
# Training loop
for i in range(num_iterations):
accumulated_gradients = 0
for j in range(accumulation_steps):
batch = next(training_batch)
gradients = compute_gradients(batch)
accumulated_gradients += gradients
update_weights(accumulated_gradients)
Gradient Checkpointing
- Gradient checkpointing is a technique used to trade off memory usage for computation time during backpropagation. In deep neural networks, backpropagation requires storing intermediate activations for computing gradients during the backward pass. However, for models with a large number of layers or limited memory, storing all the intermediate activations can be memory-intensive.
- Gradient checkpointing addresses this issue by selectively recomputing a subset of intermediate activations during backpropagation. Instead of storing all activations, only a subset of them, typically those necessary for computing gradients, are cached. The remaining intermediate activations are recomputed on-the-fly during the backward pass. By recomputing rather than storing all intermediate activations, memory usage is reduced at the cost of increased computation time.
- The specific choice of which intermediate activations to checkpoint depends on the memory requirements and computational trade-offs of the model. By strategically checkpointing activations, gradient checkpointing allows for more memory-efficient training, enabling the use of larger models or reducing memory bottlenecks in deep learning tasks.
- Gradient checkpointing helps to reduce the memory requirements during the backpropagation phase of training, especially in models with a large number of layers or parameters.
- In order to compute the gradients during the backward pass all activations from the forward pass are normally saved. This can create a big memory overhead.
- Instead of storing all the intermediate activations during the forward pass, gradient checkpointing stores only a subset of them. During the backward pass, the missing intermediate activations are recomputed on-the-fly, reducing the amount of memory required during training.
- Alternatively, one could forget all activations during the forward pass and recompute them on demand during the backward pass. This would however add a significant computational overhead and slow down training.
- This trade-off allows the use of larger models or batch sizes that would be otherwise infeasible due to memory constraints.
- There are two ways you can think of doing gradient checkpointing:
- In summary, gradient accumulation addresses memory constraints by accumulating gradients over multiple batches before updating model parameters, while gradient checkpointing selectively recomputes a subset of intermediate activations to reduce memory usage during backpropagation. Both techniques offer ways to optimize memory and computational resources in deep learning training.
- The code below (source), with addition of gradient checkpointing along with gradient accumulation, we can see that some memory is saved but the training time has become slower. As HuggingFace mentions, a good rule of thumb is that gradient checkpointing slows down training by 20%.
training_args = TrainingArguments(
per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
)
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
result = trainer.train()
print_summary(result)
> BEFORE
Time: 66.03
Samples/second: 7.75
GPU memory: 8681 MB
> AFTER
Time: 85.47
Samples/second: 5.99
GPU memory occupied: 6775 MB.