Primers • How To's
- Overview
- How to deal with limited training data in supervised learning
- How to augment your data with PyTorch
- How to select a batch size
- How to test your model in production
Overview
- The below sections will cover a few, ‘how to’s’ and techniques of machine learning.
How to deal with limited training data in supervised learning
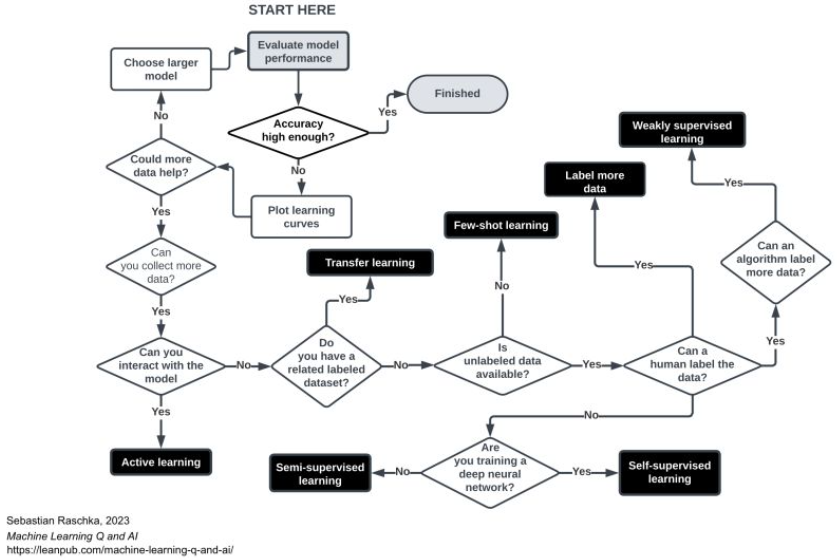
- Transfer learning:
- The model is trained on a particular/general task and is fine-tuned on a second, related task.
- The idea here is to leverage the knowledge gained from the first task and extend it to apply to the second task.
- Benefit is that the model learns more quickly and performs better than if it was trained from scratch.
- Beneficial in a scenario where the second task has limited data because the model can use its pretrained weights as a starting point.
- Self-supervised learning:
- The model is pretrained on unlabeled data and then finetuned on the task’s dataset.
- Eg: in NLP, this may look like the model predicting the masked words in a sentence or the next word in the sequence.
- Few-shot learning:
- The model learns from a very small number of examples or classes via meta-learning, transfer learning etc.
- Meta-learning:
- Train models to learn new tasks faster and with less data by leveraging the knowledge gained from previous tasks.
- Active-learning:
- a machine learning technique where a model is able to interact with the environment and select the most informative examples to learn from, rather than relying solely on a fixed dataset.
- In active learning, the model can actively query the user or the environment to obtain the labels of the most uncertain or valuable examples, and then incorporate this information into its training process to improve its accuracy.
- Semi-supervised:
- train on a dataset that has both labelled and unlabelled data.
- Weakly-supervised:
- Model is trained on a dataset that has limited or weak annotations.
- Self-learning:
- The model will use an existing classifier to create pseudo-labels for unlabeled data to train a new model.
- Multi-task learning:
- Train with multiple losses such that the model performs well on multiple tasks.
How to augment your data with PyTorch
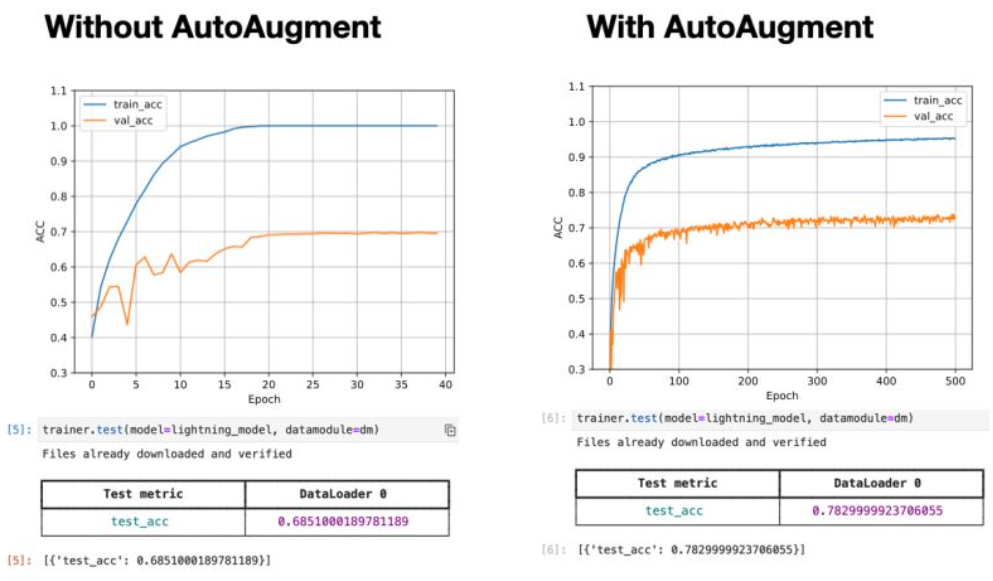
- AutoAugment is a data augmentation technique for improving the performance of deep learning models.
- It was introduced by Cubuk et al. in 2018 in the paper “AutoAugment: Learning Augmentation Strategies from Data.”
- AutoAugment uses reinforcement learning to search for the best data augmentation policies for a given task and dataset.
- The goal is to find a set of augmentation policies that result in the highest accuracy on a validation set.
- The augmentation policies can be applied to the training set to improve the generalization performance of the model.
- In PyTorch, you can use the AutoAugment implementation from the torchvision library to apply this technique to your models.
- The implementation provides a wrapper around the popular data augmentation techniques, such as random crop, flip, color jitter, and others, and allows you to search for the best combination of these techniques for a given task.
- You can specify the search space, the number of trials, and the learning rate for the reinforcement learning algorithm.
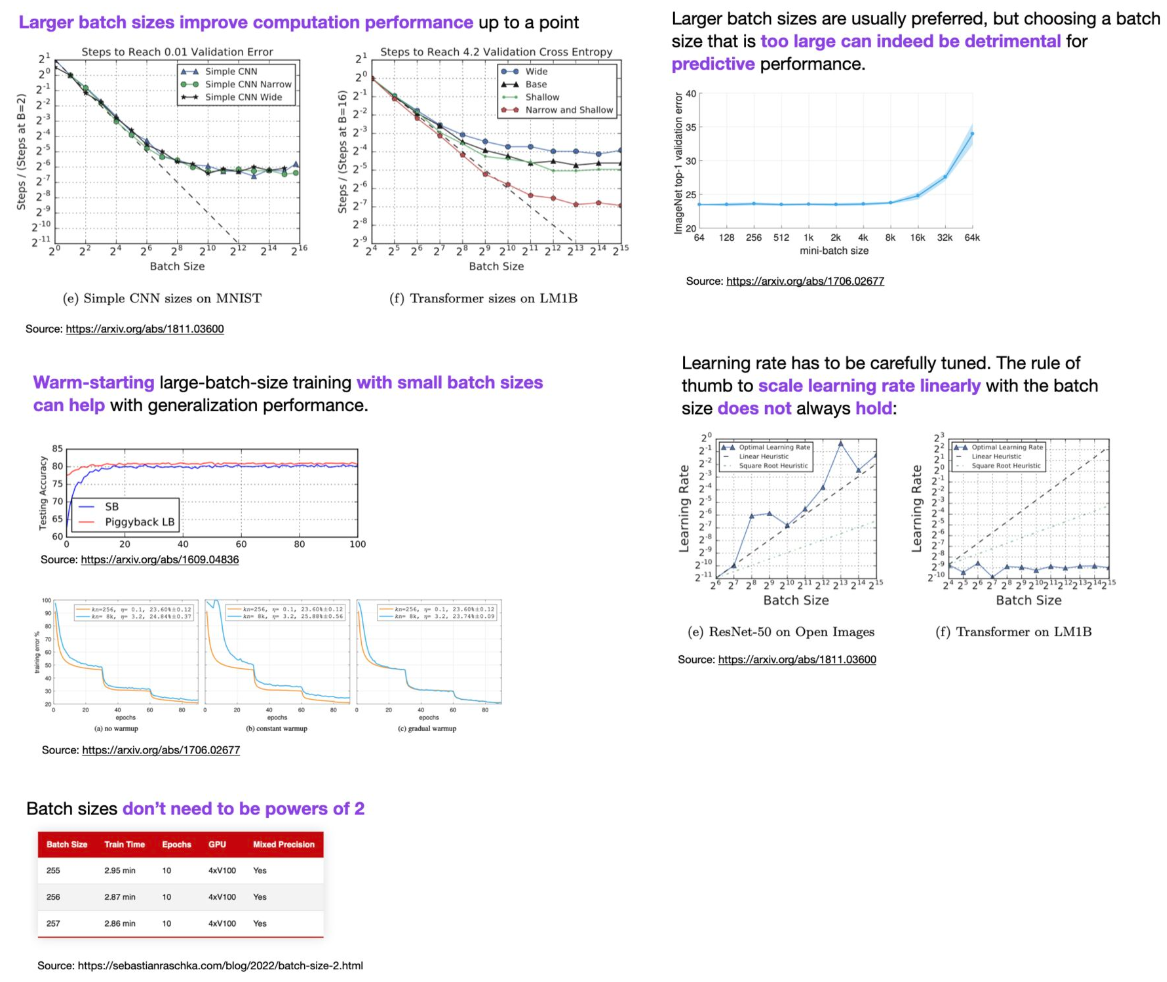
How to select a batch size
How to test your model in production
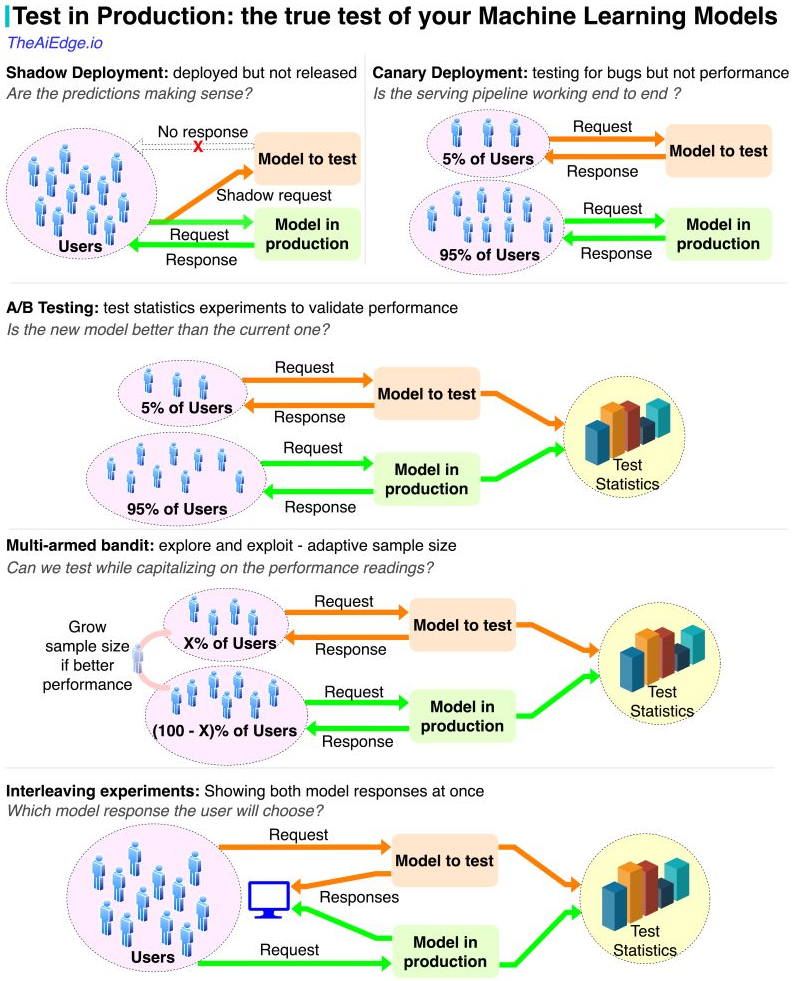
- Shadow deployment:
- is a technique used in software development to test new versions of a system in parallel with the production version, without affecting the normal operation of the production system.
- It involves running a duplicate instance of the system in parallel with the live system, using real data and traffic, but without affecting the actual users.
- This allows developers to test new features, configurations, and updates in a real-world environment, and assess their impact on the system before rolling them out to the production system.
- Canary deployment:
- the new version of the system is deployed to a small group of users or a “canary” group, while the majority of users continue to use the old version.
- The behavior and performance of the system are monitored closely, and if any issues are detected, the deployment can be stopped or rolled back before it affects a larger number of users
- A/B Testing:
- A/B testing is used to determine which ML model performs best on a given dataset, by splitting the dataset into two groups and training each model on a different group.
- The performance of each model is then evaluated and compared to determine which one provides the best results.
- Multi-armed bandit:
- a classical problem in the field of reinforcement learning, and it refers to a decision-making scenario where an agent must repeatedly choose between multiple actions (or “arms”), in order to maximize a reward signal over time.
- Interleaving experiments:
- Allow the user to be shown results from both models and see what they choose.