Internal • Netflix
- Evan Cox/ Faisal Siddique - MetaFlow
- Tools
- Metaflow specs
- comparision
- Ville tutorial
- Compute types
- Infrastructure
- Below are the areas of focus:
- Q’s
- Increase experimentation velocity via configurable, modular flows. Amazon Music personalization, North - South Carousels
- The motivation
- Competitors
- Problems
- What is Metaflow?
- Metaflow observability
- Metaflow achieves its functionality through a combination of a well-designed Python library, a set of conventions and best practices for workflow design, and integration with underlying infrastructure, particularly cloud services. Here’s a closer look at how Metaflow accomplishes its objectives:
- Sample Metaflow Workflow
- Running the Flow
- Explanation
- Integration with AWS
- Metaflow
- Outerbounds
- Metaflow job descrip
- Fairness among New Items in Cold Start Recommender Systems
- Data drift
- Causal Ranker
- Question bank
- your projects
- ooooo
- Syllabus
- Week 1-2: Introduction to Econometrics
- Week 3-4: Time-Series Analysis & Forecasting
- Week 5-6: Causal Inference - Basics
- Week 7-8: Experimental Design & A/B Testing
- Week 9-10: Advanced Causal Inference & Machine Learning Integration
- Week 11-12: Reinforcement Learning
- Week 13-14: Application to Real-World Problems
- Ongoing: Networking & Keeping Up-to-Date
Evan Cox/ Faisal Siddique - MetaFlow
- His 100 days
- 30 min call 3-3:30 1) Metaflow 2) Amazon Music , Oracle 3) FNR, culture, book stories, Reed Hastings 4) Faisal specifics
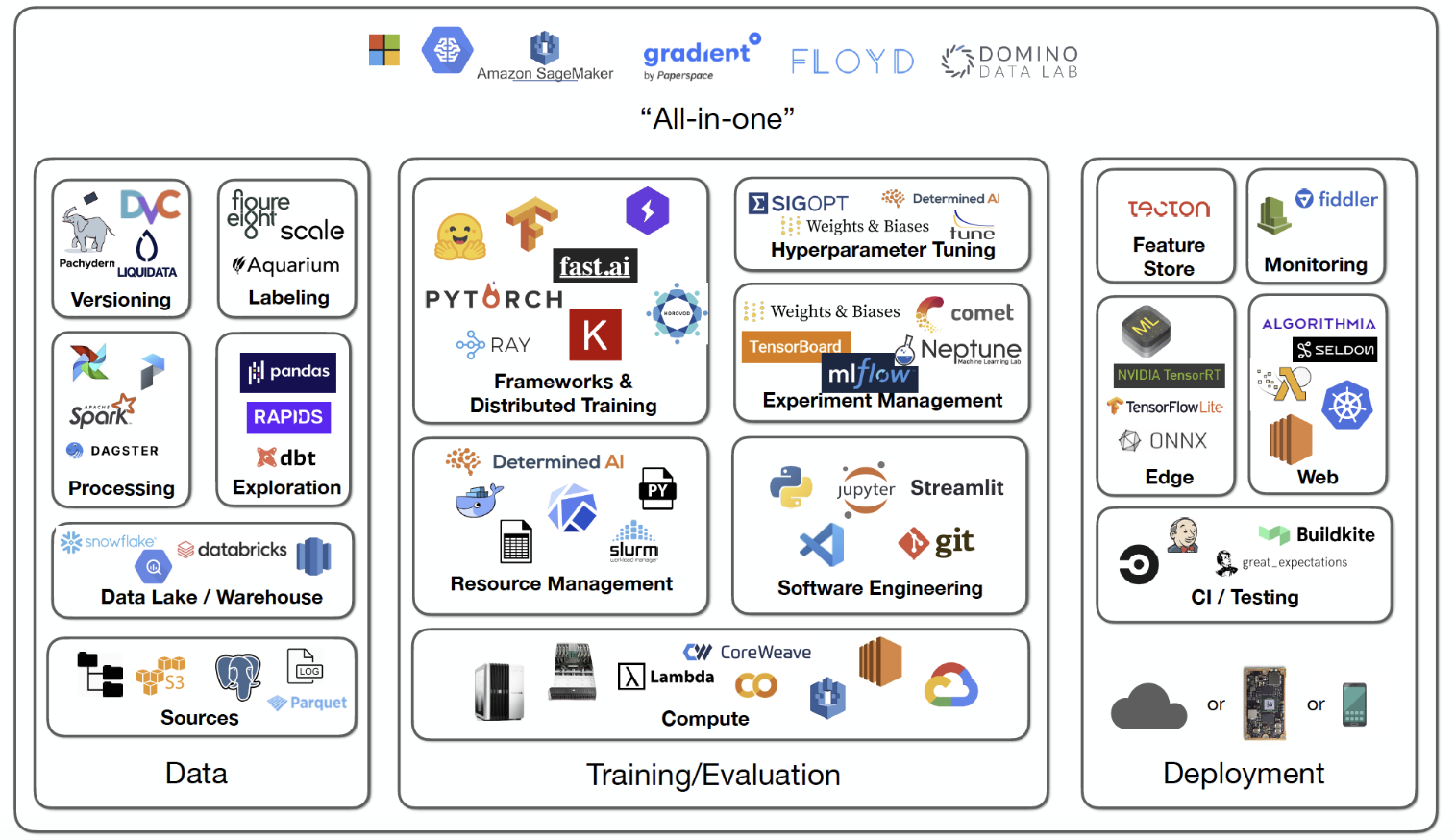
- Here’s a quick overview of the covered frameworks:
- Apache Airflow is a popular open source workflow management system that was released by Airbnb in 2015. It is implemented in Python and uses Python to define workflows. Multiple commercial vendors, including AWS and GCP, provide managed Airflow as a service.
- Luigi is another well-known Python-based framework that was open sourced by Spotify in 2012. It is based on the idea of dynamic DAGs, defined through data dependencies.
- Kubeflow Pipelines is a workflow system embedded in the open source Kubeflow framework for data science applications running on Kubernetes. The framework was published by Google in 2018. Under the hood, the workflows are scheduled by an open source scheduler called Argo that is popular in the Kubernetes ecosystem.
- AWS Step Functions is a managed, not open source, service that AWS released in 2016. DAGs are defined in the JSON format using Amazon States Language. A unique feature of Step Functions is that workflows can run for a very long time, up to a year, relying on the guarantees of high availability provided by AWS.
- Metaflow is a full-stack framework for data science applications, originally started by the author of this book and open sourced by Netflix in 2019. Metaflow focuses on boosting the productivity of data scientists holistically, treating workflows as a first-class construct. To achieve scalability and high availability, Metaflow integrates with schedulers like AWS Step Functions.

Tools
- Michaelangelo - Uber
Python ML Infrastructure
Ray.io
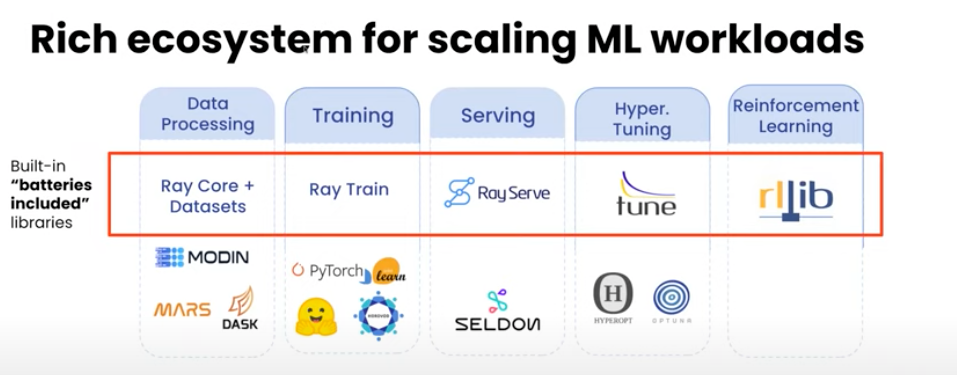
- Scale a single component of an existing ML pipeline
- Build an end to end ML application
-
Build an ML platform
- Each of Ray’s five native libraries distributes a specific ML task:
- Data: Scalable, framework-agnostic data loading and transformation across training, tuning, and prediction.
- Train: Distributed multi-node and multi-core model training with fault tolerance that integrates with popular training libraries.
- Tune: Scalable hyperparameter tuning to optimize model performance.
- Serve: Scalable and programmable serving to deploy models for online inference, with optional microbatching to improve performance.
- RLlib: Scalable distributed reinforcement learning workloads.
Horovod
- Distribute model training: servers, networking, containers, hardware
- Horovod is a distributed deep learning framework developed by Uber Technologies. It’s designed to efficiently scale out the training of deep neural networks across multiple GPUs or multiple machines.
-
Distributed Training: Horovod enables distributed training of deep learning models by leveraging techniques like distributed gradient averaging and message passing interface (MPI). This allows the workload to be spread across multiple GPUs or multiple machines, significantly reducing the training time for large models.
-
Single-Ring Allreduce: One of the key components of Horovod is its use of the single-ring allreduce algorithm. Allreduce is a collective communication operation commonly used in distributed computing to synchronize data across multiple processes. In the context of deep learning, allreduce is used to aggregate gradients computed on different workers during training. The single-ring allreduce algorithm used by Horovod is highly optimized for performance and efficiency.
-
Integration with Deep Learning Frameworks: Horovod seamlessly integrates with popular deep learning frameworks like TensorFlow, PyTorch, and MXNet. This integration allows users to leverage the distributed training capabilities of Horovod without having to make significant changes to their existing codebase.
-
Ease of Use: Horovod is designed to be easy to use, with a simple API that abstracts away much of the complexity of distributed training. Users can typically convert their single-GPU training scripts to distributed training scripts with just a few lines of additional code.
-
Scalability: Horovod is highly scalable and can efficiently distribute training workloads across hundreds or even thousands of GPUs. This makes it well-suited for training large-scale deep learning models on massive datasets.
In summary, Horovod is a powerful distributed deep learning framework that enables efficient scaling of training workloads across multiple GPUs or machines. It’s widely used in both industry and academia for training state-of-the-art deep learning models.
Kubernetes
- Kubernetes can facilitate the deployment and management of infrastructure
- Kubeflow for making deployment of ML workflows on K8 simple
XGBoost
- Robust ML algorithm that can help you understand your data and is based off of gradient boosting decision trees
- Also helps with classification and regression models training
Other
- ETL:
- Mage
- Prefect
- Dagster
- Fivetran
- Airbyte
- Astronomer
- Streaming pipelines:
- Voltron Data
- Confluent
- Analytics:
- Starburst
- Preset
- Data Quality:
- Gable
- dbt Labs
- Great Expectations
- Streamdal
- Data Lake and Data Warehouse
- Tabular
- Firebolt
Google AutoML
- Model Development: Google AutoML shines in automating the model development process. It provides a user-friendly interface and process for selecting the best ML model and tuning its hyperparameters without requiring deep ML expertise. It’s particularly effective for users who need quick results in domains like vision, language, and structured data without delving into the complexities of model architecture and optimization.
- Training and Evaluation: AutoML handles the training and evaluation process, automatically managing resources and scaling as needed. It also provides easy access to performance metrics to assess the model’s quality.
- Deployment: It simplifies the deployment of models for predictions, offering seamless integration with other Google Cloud services for hosting and serving the model.
Amazon SageMaker Autopilot
- Data Preprocessing and Feature Engineering: Autopilot automatically preprocesses tabular data and performs feature engineering, making it easier to prepare data for model training.
- Model Development: Similar to Google AutoML, SageMaker Autopilot automates model selection and hyperparameter tuning. It goes a step further by providing an explainable AI feature, offering insights into the automated decisions made during the model creation process.
- Training and Evaluation: Autopilot manages the training and evaluation, automatically optimizing compute resources. It also allows users to dive into the automatically generated Jupyter notebooks to understand and modify the training process.
- Deployment: SageMaker Autopilot facilitates the deployment of models into production environments within AWS, including setting up endpoints for real-time predictions or batch processing.
Metaflow
# pip install metaflow
- Workflow Management: Metaflow is designed to manage the entire ML workflow, from data ingestion and preprocessing to model training and deployment. It provides tools for building, orchestrating, and monitoring ML workflows, with a focus on making the process reproducible and scalable.
- Experiment Tracking: Metaflow automatically versions your experiments and data, making it easy to track, reproduce, and rollback changes across the ML workflow.
- Resource Management: It abstracts away the complexities of infrastructure management, allowing data scientists to easily run their workflows on various compute backends (local, cloud, or hybrid) without worrying about the underlying resources.
- Deployment: While Metaflow doesn’t directly handle model deployment in the same way as AutoML services, it integrates with AWS services to facilitate deploying models to production. It provides a robust foundation for building custom deployment pipelines.
- In the engineering point of view, Metaflow acts as a substrate for integrations rather than as an attempt to reinvent individual layers of the stack. Companies have built or bought great solutions for data warehousing, data engineering, compute platforms, and job scheduling, not to mention the vibrant ecosystem of open source machine learning libraries. It would be unnecessary and unproductive to try to replace the existing established systems to accommodate the needs of data scientists. We should want to integrate data science applications into the surrounding business systems, not isolate them on an island.
- Metaflow is based on a plugin architecture that allows different backends to be used for different layers of the stack, as long as the layers can support a set of basic operations. In particular, Metaflow is designed to be a cloud-native framework, relying on basic compute and storage abstractions provided by all major cloud providers.
- Metaflow has a gentle adoption curve. You can get started with the “single-player mode” on a laptop and gradually scale the infrastructure out to the cloud as your needs grow. In the remaining sections of this chapter, we will introduce the basics of Metaflow. In the chapters to follow, we will expand its footprint and show how to address increasingly complex data science applications, spanning all the layers of the stack, and enhance collaboration among multiple data scientists.
- If you want to build your infrastructure using other frameworks instead of Metaflow, you can read the next sections for inspiration—the concepts are applicable to many other frameworks, too—or you can jump straight in to chapter 4, which focuses on a foundational layer of the stack: compute resources.
Summary
- Google AutoML and Amazon SageMaker Autopilot primarily assist in the model development phase, including data preprocessing, model selection, training, evaluation, and deployment, with a strong emphasis on automating these processes to minimize the need for ML expertise.
- Metaflow provides comprehensive support across the entire ML workflow, focusing on workflow management, experiment tracking, and resource management. It’s more about enabling data scientists to structure and scale their ML processes rather than automating the model development process.
The choice between these tools depends on whether the priority is on automating model development (AutoML and Autopilot) or managing and scaling ML workflows (Metaflow).

- To define a workflow in Metaflow, you must follow these six simple rules:
-
A flow is defined as a Python class that is derived from the FlowSpec class. You can name your flows freely. In this book, by convention the flow class names end with a Flow suffix, as in HelloWorldFlow. You can include any methods (functions) in this class, but methods annotated with @step are treated specially.
-
A step (node) of the flow is a method of the class, annotated with the @step decorator. You can write arbitrary Python in the method body, but the last line is special, as described next. You can include an optional docstring in the method, explaining the purpose of the step. After the first example, we will omit docstrings to keep listings concise in the book, but it is advisable to use them in real-life code.
-
Metaflow executes the method bodies as an atomic unit of computation called a task. In a simple flow like this, there is a one-to-one correspondence between a step and a task, but that’s not always the case, as we will see later in section 3.2.3.
-
The first step must be called start, so the flow has an unambiguous starting point.
-
The edges (arrows) between steps are defined by calling self.next (step_name) on the last line of the method, where step_name is the name of the next step to be executed.
-
The last step must be called end. Because the end step finishes the flow, it doesn’t need a self.next transition on the last line.
-
One Python file (module) must contain only a single flow. You should instantiate the flow class at the bottom of the file inside an if name == ‘main’ conditional, which causes the class to be evaluated only if the file is called as a script.
- Timestamp denotes when the line was output. You can take a look at consecutive timestamps to get a rough idea of how long different segments of the code take to execute. A short delay may occur between a line being output and the minting of a timestamp, so don’t rely on the timestamps for anything that requires accurate timekeeping.
- The following information inside the square brackets identifies a task:
- Every Metaflow run gets a unique ID, a run ID.
- A run executes the steps in order. The step that is currently being executed is denoted by step name.
- A step may spawn multiple tasks using the foreach construct (see section 3.2.3), which are identified by a task ID.
- The combination of a flow name, run ID, step name, and a task ID uniquely identifies a task in your Metaflow environment, among all runs of any flow. Here, the flow name is omitted because it is the same for all lines. We call this globally unique identifier a pathspec.
- Each task is executed by a separate process in your operating system, identified by a process ID, aka pid. You can use any operating system-level monitoring tools, such as top, to monitor resource consumption of a task based on its process ID.
- After the square bracket comes a log message, which may be a message output by Metaflow itself, like “Task is starting” in this example, or a line output by your code.
-
What’s the big deal about the IDs? Running a countless number of quick experiments is a core activity in data science—remember the prototyping loop we discussed earlier. Imagine hacking many different variations of the code, running them, and seeing slightly different results every time. After a while, it is easy to lose track of results: was it the third version that produced promising results or the sixth one?
-
In the old days, a diligent scientist might have recorded all their experiments and their results in a lab notebook. A decade ago, a spreadsheet might have served the same role, but keeping track of experiments was still a manual, error-prone process. Today, a modern data science infrastructure keeps track of experiments automatically through an experiment tracking system.
-
An effective experiment tracking system allows a data science team to inspect what has been run, identify each run or experiment unambiguously, access any past results, visualize them, and compare experiments against each other. Moreover, it is desirable to be able to rerun a past experiment and reproduce their results. Doing this accurately is much harder than it sounds, so we have dedicated many pages for the topic of reproducibility in chapter 6.
-
Standalone experiment tracking products can work with any piece of code, as long as the code is instrumented appropriately to send metadata to the tracking system. If you use Metaflow to build data science applications, you get experiment tracking for free—Metaflow tracks all executions automatically. The IDs shown earlier are a part of this system. They allow you to identify and access results immediately after a task has completed.
- We will talk more about accessing past results in section 3.3.2, but you can get a taste by using the logs command, which allows you to inspect the output of any past run. Use the logs command with a pathspec corresponding to the task you want to inspect. For instance, you can copy and paste a pathspec from the output your run produces and execute the next command:
Metaflow specs
- Metaflow automatically persists all instance variables, that is, anything assigned to self in the step code. We call these persisted instance variables artifacts. Artifacts can be any data: scalar variables, models, data frames, or any other Python object that can be serialized using Python’s pickle library. Artifacts are stored in a common data repository called a datastore, which is a layer of persisted state managed by Metaflow. You can learn more about the datastore later in this chapter in the sidebar box, “How Metaflow’s datastore works.”
- Each task is executed as a separate process, possibly on a separate physical computer. We must concretely move state across processes and instances.
- Runs may fail. We want to understand why they failed, which requires understanding of the state of the flow prior to the failure. Also, we may want to restart failed steps without having to restart the whole flow from the beginning. All these features require us to persist state.
- Volume—We want to support a large number of data science applications.
- Velocity—We want to make it easy and quick to prototype and productionize data science applications.
- Validity—We want to make sure that the results are valid and consistent.
-
Variety—We want to support many different kinds of data science models and applications.
- Batch processing vs. stream processing
- An alternative to batch processing, which deals with discrete units of computation, is stream processing, which deals with a continuous stream of data. Historically, the vast majority of ML systems and applications requiring high-performance computing have been based on batch processing: data goes in, some processing is done, and results come out.
- During the past decade, increased sophistication of applications has driven demand for stream processing, because it allows results to update with a much lower delay, say, in a matter of seconds or minutes, in contrast to batch jobs, which are typically run at most once an hour. Today, popular frameworks for stream processing include Kafka, Apache Flink, or Apache Beam. In addition, all major public cloud providers offer stream-processing-as-a-service, such as Amazon Kinesis or Google Dataflow.
- Fortunately, the choice is not either/or. You can have an application use the two paradigms side by side. Many large-scale ML systems today, such as the recommendation system at Netflix, are mostly based on batch processing with some stream processing included for components that need to update frequently.
- PRODUCTIVITY TIP Containers boost productivity by granting users the freedom to experiment without having to fear that they can break something by accident or interfere with their colleagues’ work. Without containers, a rogue process can hog an arbitrary amount of CPU or memory or fill the disk, which can cause failures in neighboring but unrelated processes on the same instance. Compute- and data-intense machine learning processes are particularly prone to these issues.
helloworld.py logs 1609557277904772/start/1
-
You should see a line of output that corresponds to the print statement in the step you inspected. The logs subcommand has a few options, which you can see by executing logs –help.
-
Finally, notice how Metaflow turns a single Python file into a command-line application without any boilerplate code. You don’t have to worry about parsing command-line arguments or capturing logs manually. Every step is executed as a separate operating system-level subprocess, so they can be monitored independently. This is also a key feature enabling fault tolerance and scalability, as we will learn in chapter 4.
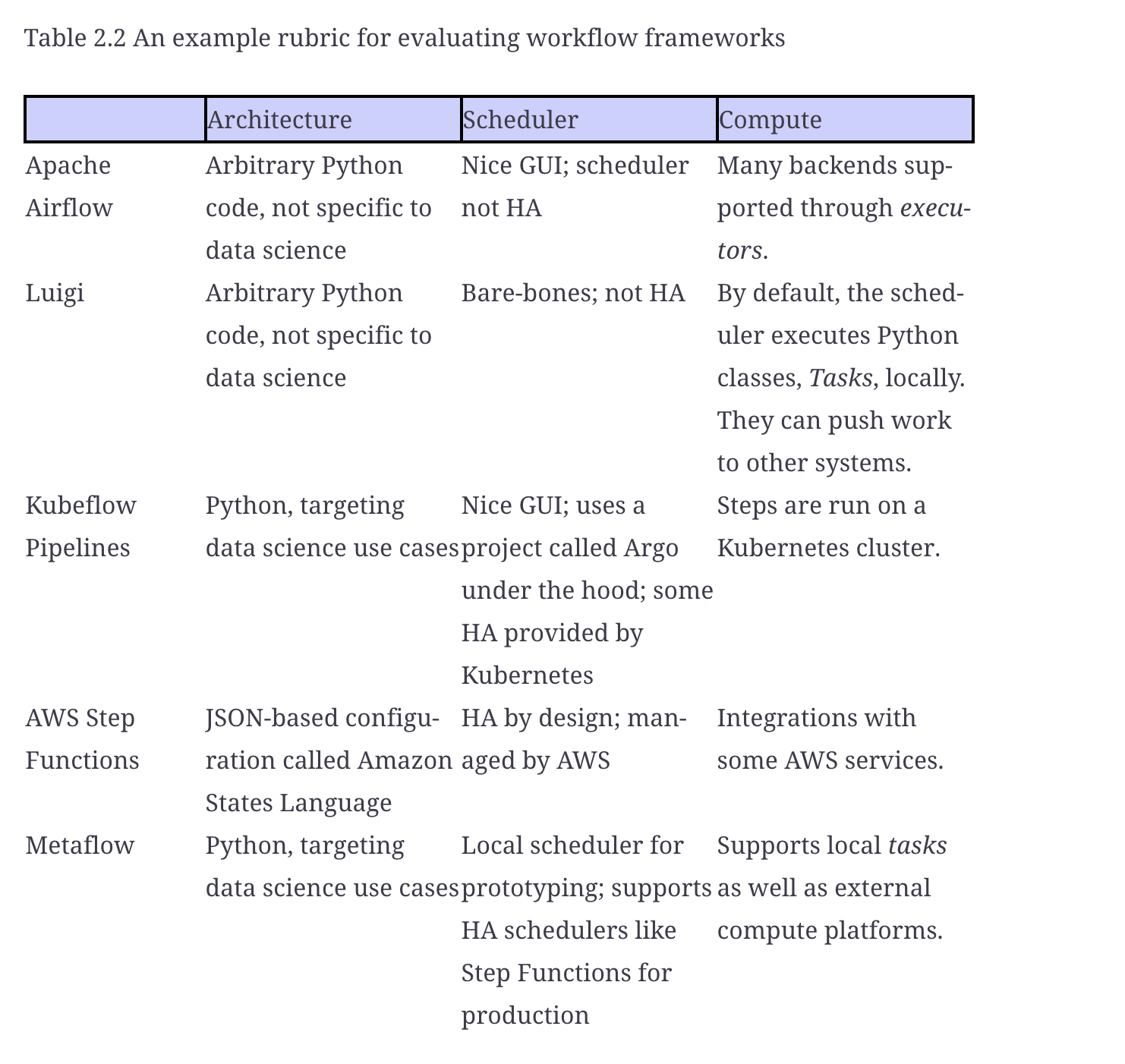
comparision
Creating a highly detailed and technical table comparing the systems you’ve mentioned would exceed the text limitations here. Instead, I can provide a concise comparison touching on the creators, best use cases, and key technical details for each system.
- Metaflow:
- Creator: Netflix
- Best Used For: Simplifying the building and managing of data science projects from prototype to production.
- Key Details: Provides easy scaling, integrates with AWS, version control for data science experiments, Python and R API support.
- Apache Airflow:
- Creator: Airbnb
- Best Used For: Scheduling and orchestrating complex, multi-step data pipelines.
- Key Details: Supports DAGs for workflow orchestration, has a rich UI for monitoring, extensible with custom operators, supports numerous integrations.
- Luigi:
- Creator: Spotify
- Best Used For: Batch job orchestration with dependency resolution.
- Key Details: Python-based, handles dependency resolution, task visualization, failure recovery, and command line integration.
- MLflow:
- Creator: Databricks
- Best Used For: Managing the machine learning lifecycle, including experimentation, reproducibility, and deployment.
- Key Details: Offers tracking of experiments, packaging code into reproducible runs, and model sharing and collaboration.
- Kubeflow:
- Creator: Google
- Best Used For: Deploying and orchestrating machine learning workflows in Kubernetes.
- Key Details: Kubernetes-native, supports a variety of ML tools, serves models at scale, and facilitates end-to-end ML workflows.
- AWS Step Functions:
- Creator: Amazon Web Services
- Best Used For: Serverless orchestration for AWS services to automate processes and workflows.
- Key Details: Manages state transitions at scale, integrates with AWS ecosystem, visually manage workflows, supports error handling and retries.
- Ray.io:
- Creator: UC Berkeley’s RISELab
- Best Used For: High-performance distributed computing for machine learning and other intensive workloads.
- Key Details: Offers simple APIs for building and running distributed applications, supports dynamic task graphs, and provides scalability.
- Uber’s Michelangelo:
- Creator: Uber
- Best Used For: Deploying and operating machine learning models at scale.
- Key Details: End-to-end ML platform, supports training, deployment, and managing of ML models, integrates with Uber’s data and infrastructure.
- Horovod:
- Creator: Uber
- Best Used For: Distributed training of deep learning models.
- Key Details: Open-source, works with TensorFlow, Keras, and PyTorch, supports GPU training, and integrates with Kubernetes and Spark.
- AutoML:
- Creator: Varied, as AutoML is a category of tools rather than a single system (e.g., Google’s AutoML).
- Best Used For: Automating the process of applying machine learning to real-world problems.
- Key Details: Provides a suite of tools to automatically train and tune models, requiring minimal human intervention.
- Apache Airflow
- Pros:
- Extensive scheduling capabilities.
- Rich set of integrations with various data sources and services.
- Strong community support, with a large number of contributors.
- Cons:
- Complexity in setup and management, steep learning curve.
- No built-in support for machine learning workflows.
- Metaflow
- Pros:
- Designed with data scientists in mind, focuses on ease of use.
- Integrates seamlessly with AWS for scaling and deployment.
- Built-in data versioning and experiment tracking.
- Cons:
- Less suitable for non-ML batch workflows.
- Mainly tailored for AWS, which might not fit all cloud strategies.
- Luigi
- Pros:
- Simplicity in defining workflows, with a focus on dependency resolution.
- Good for Python-centric teams due to its integration with Python’s ecosystem.
- Cons:
- Not as feature-rich as Airflow for complex task orchestration.
- Limited capabilities for real-time processing.
- MLflow
- Pros:
- Comprehensive platform for the entire ML lifecycle management.
- Language agnostic with APIs for Python, R, Java, and REST.
- Cons:
- Primarily an ML lifecycle tool, not a general workflow orchestrator.
- Might require additional tools for complete end-to-end automation.
- Kubeflow
- Pros:
- Kubernetes-native, leveraging container orchestration for ML workflows.
- Supports a wide range of ML tools and frameworks.
- Cons:
- Can be complex to set up and manage, requiring Kubernetes expertise.
- Overhead might be too high for smaller projects or teams.
- AWS Step Functions
- Pros:
- Serverless orchestration service, highly scalable and reliable.
- Direct integration with many AWS services.
- Cons:
- Locked into the AWS ecosystem, less ideal for hybrid or multi-cloud environments.
- Pricing can become significant at scale.
- Ray.io
- Pros:
- Excellent for distributed computing, offering easy scaling.
- Supports a variety of machine learning and AI libraries.
- Cons:
- More suitable for teams with distributed computing needs.
- Might be too complex for simple, localized tasks.
- Michelangelo
- Pros:
- Provides a full-stack solution for ML model building and deployment.
- Suitable for large-scale, enterprise-grade ML deployments.
- Cons:
- Details about Michelangelo are less publicly documented as it’s an internal Uber tool.
- May not be accessible for smaller teams or organizations.
- Horovod
- Pros:
- Efficient distributed training, especially with GPU support.
- Works with popular deep learning frameworks like TensorFlow and PyTorch.
- Cons:
- Primarily focused on model training, not a full workflow management tool.
- Requires additional infrastructure for large-scale training.
- AutoML (e.g., Google Cloud AutoML)
- Pros:
- Great for automating the development of ML models.
- Accessible to non-experts and provides fast results.
- Cons:
- Less control over the modeling process, which might not suit all advanced use cases.
- Can be costly depending on the provider and usage.
For large-scale teams, it’s crucial to consider factors like the complexity of workflows, the team’s technical expertise, integration with existing tech stacks, scalability requirements, and the specific nature of data processing or ML tasks when choosing between these tools.
Ville tutorial
-
Here are the main technical points from Ville Tuulos’s talk on “Effective Data Science Infrastructure”:
-
Motivation from Netflix Experience: Ville’s motivation for writing the book came from his experience leading the machine learning infrastructure team at Netflix, where the diverse use cases for machine learning across the company highlighted the need for a common infrastructure to support various ML applications.
-
Need for Common Infrastructure: The talk emphasizes the importance of building a common machine learning and data science infrastructure that can handle a wide range of use cases, from natural language processing to computer vision and business analytics.
-
Data Handling and Compute at Scale: Central to effective data science infrastructure is the efficient management of data and the ability to run computations at scale, leveraging cloud resources when necessary.
-
Workflow Management: Ville discusses the concept of workflows or Directed Acyclic Graphs (DAGs) for orchestrating complex machine learning processes, including data preprocessing, model training, and evaluation.
-
Versioning and Collaboration: The ability to manage multiple versions of machine learning models and workflows, track experiments, and facilitate collaboration among data scientists and engineers is highlighted as a critical component of effective infrastructure.
-
Dependency Management: The talk touches on the challenge of managing external dependencies in machine learning projects, ensuring reproducibility and stable execution environments despite the fast evolution of ML libraries and frameworks.
-
Prototyping to Production Continuum: Ville proposes a continuum approach for moving machine learning projects from prototyping to production, emphasizing the importance of scalability, robustness, and automation in production-ready ML systems.
-
Cloud-based Workstations and Development Environments: The use of cloud-based workstations for development is advocated to bridge the gap between prototyping and production environments, making the use of IDEs like Visual Studio Code for remote development.
-
Metaflow as a Reference Implementation: The open-source framework Metaflow, developed at Netflix, is presented as a reference implementation for managing data, compute resources, workflows, versioning, and dependencies in machine learning projects.
-
Scheduled Execution and Production Readiness: Ville concludes with the concept of scheduled execution for production workflows, leveraging AWS Step Functions for automated, robust, and scalable ML model deployment and monitoring.
-
The talk provides a comprehensive overview of the essential elements required for setting up an effective data science infrastructure, drawing on Ville Tuulos’s extensive experience and the Metaflow framework.
Compute types
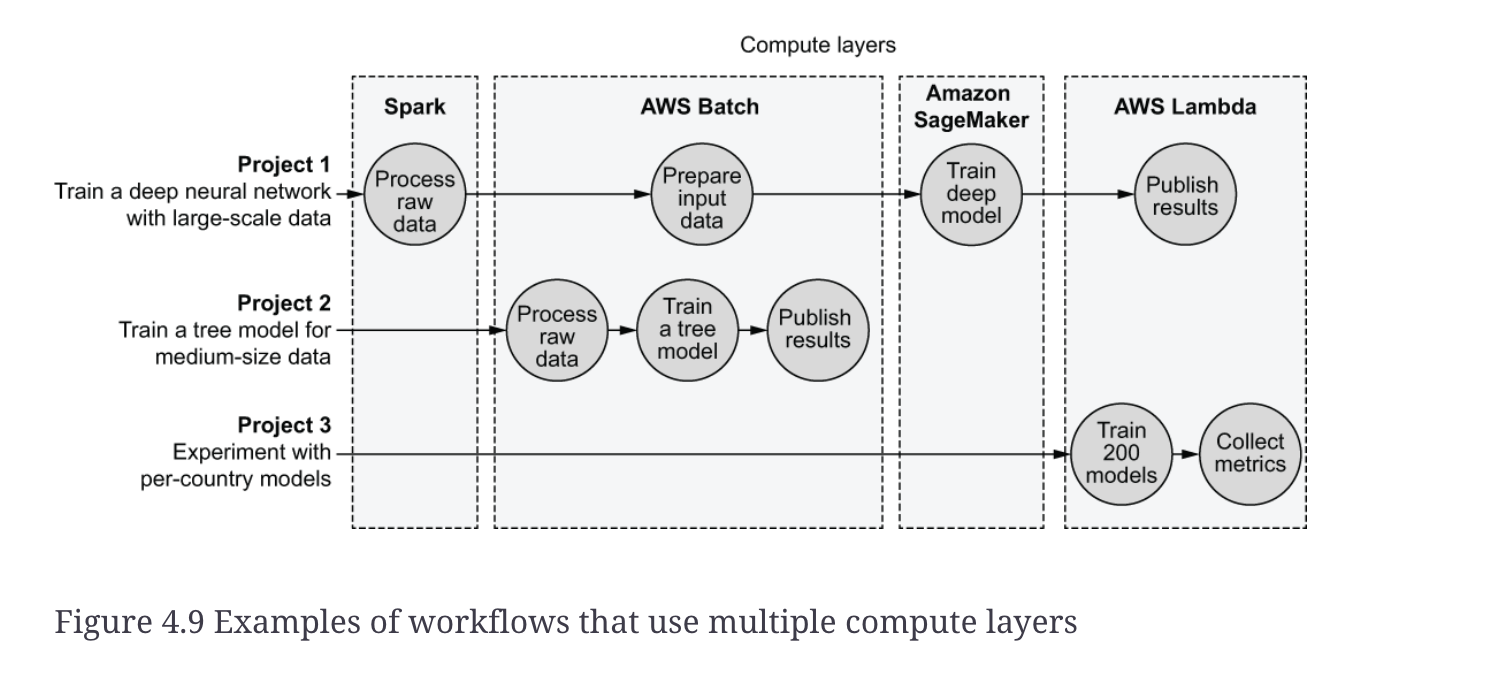
- The figure depicts the following three projects, each with a workflow of their own:
- Project 1 is a large, advanced project. It needs to process a large amount of data, say a text corpus of 100 GB, and train a massive deep neural network model based on it. First, large-scale data processing is performed with Spark, which is optimized for the job. Additional data preparation is performed on a large instance managed by AWS Batch. Training a large-scale neural network requires a compute layer optimized for the job. We can use Amazon SageMaker to train the model on a cluster of GPU instances. Finally, we can send a notification that the model is ready using a lightweight task launched on AWS Lambda.
- Project 2 trains a decision tree using a medium-scale, say, 50 GB, dataset. We can process data of this scale, train a model, and publish results, on standard CPU instances with, say, 128 GB of RAM. A general-purpose compute layer like AWS Batch can handle the job easily.
- Project 3 represents an experiment conducted by a data scientist. The project involves training a small model for each country in the world. Instead of training 200 models sequentially on their laptop, they can parallelize model training using AWS Lambda, speeding up their prototyping loop.
- As figure 4.9 illustrates, the choice of compute layers depends on the type of projects you will need to support. It is a good idea to start with a single, general-purpose system like AWS Batch and add more options as the variety of use cases increases.
Infrastructure
-
AutoML: Amazon SageMaker Autopilot
-
Software consideration:
- Realtime or Batch
- Cloud vs Edge/Browser
- Compute resources (CPU/ GPU/ memory)
- Latency, throughput (QPS)
- Logging
- Security and privacy
- Experiment tracking: Sagemaker Studio, Weights and Biases

- Common Deployment case: Gradual ramp up with monitoring / Rollback
- New product/ capability:
- Shadow mode: ML system shadows the human and runs in parallel but output is not used for any decision
- Automate/assist with manual task:
- Canary deployment: run only on small fraction of traffic initially. Monitor system and ramp up traffic gradually
- Replace previous ML system:
- Blue / Green deployment: Blue old version, Green new version, have router go from blue to green w/ easy way to rollback. Can also use with gradual dial up.
- New product/ capability:
-
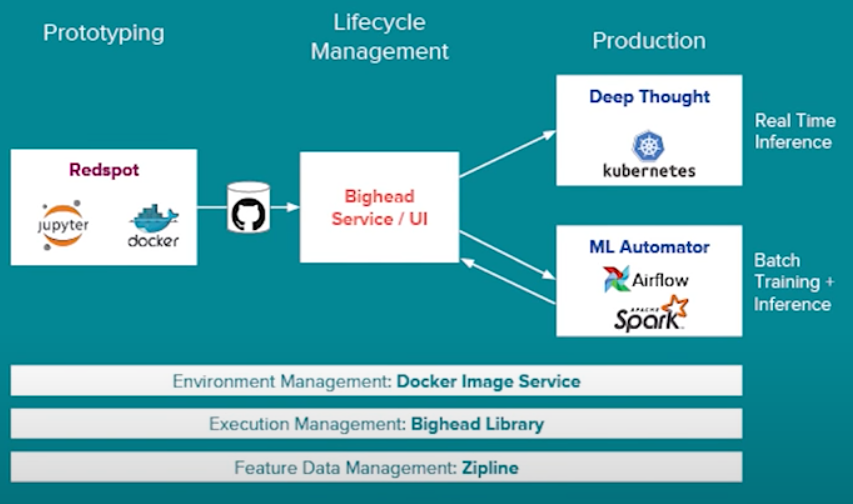
Success Criteria: Enable our Scientists and Engineers to try out and test, offline experiments as fast as possible, from ideation to productionization. The infrastructure should support rapid iteration, high-performance computing, and efficient data management.
- Model Selection:
- Ray: An open-source framework that provides a simple, universal API for building and running distributed applications. It’s used for parallel and distributed computing, making it suitable for training and serving ML models at scale. Ray supports model selection by enabling parallel experiments and hyperparameter tuning.
- Amazon SageMaker: Provides a comprehensive environment for building, training, and deploying machine learning models at scale. It supports direct integration with Ray for distributed computing.
- Data:
- Fact Store: Immutable data at Netflix
- Cassandra: A distributed NoSQL database known for its scalability and high availability without compromising performance. Suitable for managing the Fact Store where read and write throughput is critical.
- S3: Amazon Simple Storage Service (S3) is a scalable, high-speed, web-based cloud storage service. It’s used for storing and retrieving any amount of data at any time, ideal for large datasets used in ML.
- Parquet Files: A columnar storage file format optimized for use with big data processing frameworks like Hadoop and Spark. It’s efficient for both storage and computation, making it ideal for storing large datasets that need to be processed for ML.
- Fact Store: Immutable data at Netflix
- Amazon DynamoDB: A fast and flexible NoSQL database service for any scale. It can complement Cassandra for managing immutable data, offering seamless scalability and integration with other AWS services.
- Amazon S3: Already mentioned, it’s the backbone for storing vast amounts of data in a durable, accessible, and scalable way.
- Amazon FSx for Lustre: A high-performance file system optimized for fast processing of large datasets, which can be used alongside or as an alternative to HDFS in some contexts. It integrates well with S3 for storing and processing large-scale datasets.
- Train/ ML Pipeline automation:
- Apache Spark: A unified analytics engine for large-scale data processing. It’s used for data preparation, feature extraction, and ML model training, especially when dealing with large datasets.
- TensorFlow: An open-source framework for numerical computation and machine learning. TensorFlow can be used within pipelines for model training and inference, leveraging its comprehensive ecosystem for deep learning.
- Workflow Scheduling: Tools like Apache Airflow or Prefect can be used to automate and manage the ML pipeline workflows, ensuring that data processing, model training, and other tasks are executed in a reliable and scalable manner.
- Training Pipeline: This refers to the entire process of data preparation, model training, validation, and testing. Tools like TensorFlow Extended (TFX) could be integrated here for end-to-end machine learning pipeline capabilities.
- AWS Step Functions: Can orchestrate AWS services, automate workflows, and hence, manage ML pipelines efficiently. It provides a reliable way to coordinate components of the training pipeline.
- AWS Glue: A fully managed extract, transform, and load (ETL) service that makes it easy for preparing and loading data for analytics. It can be used for data preparation stages in ML pipelines.
- Amazon SageMaker (for Training Pipeline): Facilitates the creation, training, and tuning of machine learning models. Provides a fully managed service that covers the entire machine learning workflow.
- Serve:
- Ray or Flink: For serving models, especially in real-time applications. Flink provides high-throughput, low-latency streaming data processing and can be used for real-time model inference.
- EV Cache: An in-memory caching solution that can be used to store pre-computed model predictions or feature vectors for fast retrieval during model inference, enhancing performance.
- Amazon SageMaker (for Serving): Enables developers to easily deploy trained models to production so they can start generating predictions (also known as inference).
- Amazon ElastiCache: Similar to EV Cache, ElastiCache supports in-memory caching to enhance the performance of model inference by caching results or frequently accessed data.
- Maintain:
- Hadoop: A framework that allows for the distributed processing of large data sets across clusters of computers. It’s useful for data storage and processing, supporting the infrastructure’s maintenance, especially for large-scale data.
- Presto and Hive: Both are query engines but serve different purposes. Presto is used for interactive querying, while Hive is more suited for batch processing jobs. They can be used for data analysis and maintenance tasks, such as monitoring data quality and performance.
- Amazon CloudWatch: Offers monitoring and observability of AWS cloud resources and applications, crucial for maintaining the health and performance of ML infrastructure.
- AWS Lake Formation: Builds, secures, and manages data lakes. It simplifies data ingestion, cataloging, and cleaning, supporting the maintenance of a clean, well-organized data repository.
- Model A/B Testing:
- Ablaze A/B Testing: A tool specifically designed for conducting A/B testing in machine learning models. It helps in evaluating the performance of different model versions in a production environment, facilitating data-driven decision-making.
- Amazon SageMaker (A/B Testing): Supports A/B testing natively, allowing users to easily compare different model versions directly within the service.
- Deployment:
- ONNX (Open Neural Network Exchange): Facilitates model deployment by providing an open standard for representing ML models. This allows models to be shared between different ML frameworks, easing deployment processes.
- AWS Lambda: For running inference code without managing servers. It can be triggered by events, making it suitable for lightweight, real-time inference needs.
- Amazon EKS (Elastic Kubernetes Service) or Amazon ECS (Elastic Container Service): For deploying containerized applications, including machine learning models, at scale.
- Inference:
- Real-Time Stream: Technologies like Apache Kafka can be used to handle real-time data streams for model inference, enabling applications to process data and make predictions in real-time.
- Amazon Kinesis: For real-time data streaming and processing, enabling real-time analytics and inference on data in motion.
- Amazon SQS and SNS: For message queuing and notifications, facilitating asynchronous communication between different parts of the ML infrastructure, especially useful in decoupling ingestion and processing.
- Data Drift:
- Marken: Although not a widely recognized tool in the public domain (as of my last update), in the context of ML infrastructure, tools designed to monitor data drift are critical. They evaluate how the model’s input data distribution changes over time, potentially impacting model performance.
- Amazon CloudWatch and Amazon SageMaker Model Monitor: For monitoring the performance of machine learning models and detecting data drift, ensuring models remain accurate over time.
Below are the areas of focus:
- Technical Screen: You’ll be asked to participate in a system design exercise and discussion.
- Culture Alignment: The value of people over process is integrated into all aspects of our roles. We’ll be assessing your ability to thrive in this type of environment and the overall Netflix culture.
- Team Partnership: You’ll meet with a team member to discuss how you collaborate as a leader on a broad scale.
- Metaflow Partnership: You’ll meet with internal customers of Metaflow and will evaluate your ability to partner with them.
Q’s
- What was the most challenging project you have worked on?
-
Increase experimentation velocity via configurable, modular flows. Amazon Music personalization, North - South Carousels
- Flows: allows swapping out models with ease w/in the config file
- Implement data from S3 via DataSource
-
SageMaker inference toolkit
- Ideation -> productionization time reduce
- Repetitve manual effort due to complex, fragmented code process
- One of the most challenging projects I’ve had to work on is creating a unified infrastructure for Amazon Music.
- S: So the Amazon entertainment suite, Music, Prime Video, Audible, Wondery Podcast, we cross collaborate often. There’s a lot of cross-functional, item-to-item recommendation systems we run that help both products.
- In this case, we wanted to collaborate with Prime Video, Taylor Swift is a big artist on our platform and she’s recently done a tour which she’s made into a movie and whenever the user pauses, they basically should have a link back to Music to listen to that song/ playlist. For many artists, as well as original shows that have playlists on our app.
- T: Our task was to collaborate, in the past, to get from research to production for us would be a fairly long process, just to get from research to productionization takes months.
- Every single team has their own approach to go to prod from research. Own pipelines/ tooling platform for common tasks
- Lack of standardized metrics and analysis tools: calculating position
- Lack of established component APIs: Each model would have it’s own APIs so to switch out the model, would require a lot of work to adapt the model to the existing interface
- Feature engineering inside the model, makes the model not transferrable
- Metrics: not measuring
- Research - python tooling, prod: Scala/ Java code -> ONNX. Checking in code, setting in pipelines, periodic flows needed in prod, monitoring steps. Was model in research same as in prod, are we measuring it the same
- Two different pipelines, environment variables in different files, dynamo db has configs everywhere, different clusters, EMR jobs, hard to test change isn’t breaking anything. Time to onboard was too long, too many tooling. New processes.
- Bottom line was, we were not able to get from prototype to production with high velocity which was stifling our need for increased experimentation.
- A: This was our current norm, we would make snowflake/ unique but repetitive fixes for each collaboration we did. We would have different env variables, clusters, components that we would have to rebuild just for this project. Time to onboard was long, too much tooling here. Outside of this, we also needed to configure regular jobs, retries, monitoring, cost analysis needed to be set up, data drift checks.
- Our original methodology included creating a new pipeline for each project, we were maintaining as you can imagine, quite a few pipelines in quite a few environments.
- This was inefficient, I wanted to create a solution that would be less problem specific and more easy to be reusable. I wanted to change the way we do things. This overhead was neither good for our customers, it stifles experimentation, nor was it good for our data scientists, to be working on repetitive non creative tasks. Thats not why we hired them.
- As part of this collaboration, I wanted to fix this bottleneck of course, along with our cross collaborators and team members.
- Researched a few options out in the market as well as custom solutions. Airflow, Metaflow
- R: Our eventual goal is to have a unified platform that the entire entertainment suite at Amazon can leverage
- R:
- When did you question the status quo?
- Daily update meetings / project
- The issue is when you have a daily meeting, it’s hard to come into the meeting with a proper agenda and make sure everyone’s time is respected. There are nominal movements within projects on an everyday basis.
- Work with Program Managers, create excel sheets categorizing tasks, as well as Jira tickets, and sync up on a less frequent cadence. There should be a point/agenda to a meeting
- Daily update meetings / project
- Can you share your experience working with distributed systems?
- Why do you want to switch jobs?
- It’s not so much that I want to leave, it’s more so that I want to join Netflix and let me explain.
- There are two pillars that I see are important for a manger, the culture and the technology and this role has both.
- The FnR culture, the culture of candor and frequent constructive feedback, having people over processes. As a leader, I’m always striving to grow and seek how to improve
- No rules, rules Reed Hastings. Ville Tuulos Effective Data Science Infrastructure
- metaflow, glorious product
- How do you communicate with stakeholders?
- how to gear the message towards the audience, audience intended messaging
- Which culture memo is your favorite and why?
- FnR, Keepers Test, People over Process,
- Why do you like working in the internal tools team? (Noted that this was mentioned to fit in with their team)
- The assignment was to be an API aggregator
- HR specifically reminded me that you should focus on saying “I” more and “we” less when answering questions in the future. They emphasized that he’s a pretty good person.
- What aspects do you agree with in the Culture memo?
- What aspects do you disagree with, or what are the problems in the Culture memo?
- How do your teammates describe you?
- Could you elaborate on the constructive feedback (co) that you received?
- The first round can’t exactly be labeled as technical; it was more about HR behavioral aspects. Traditional behavioral issues are typically seen as HR matters.
- In the second round, a person asked a question about Java ConcurrentHashMap. The question wasn’t difficult, but since the interviewee had been using Go before, he was only somewhat familiar with ConcurrentHashMap, leading to an average performance in this round.
- After dinner, the interviewer from India asked me to design a database that stores time series data to support queries with specific conditions, such as finding the maximum value within a certain time period. This is a classic time series database design question, and there should be a lot of information on the Internet about it.
- A second interviewer from India discussed designing something similar to Netflix. (Note: The rest of the message seems to refer to a content access system based on points, which is unrelated to the interview context.)
- The overall interview was very good. The questions were all quite realistic, and there were no tricky brain-teasers. However, due to my lack of preparation or experience in certain areas, I didn’t perform as well as I hoped. It’s clear that Netflix sets a high bar for its engineers.
-
The interview was with a group from Infra for a senior software engineer position:
- First Round of Coding:
- Task: Implement a rate limiter, which is a very common exercise. The goal might be to write a function that, for example, rejects calls if it is invoked more than 10 times in one second. Then, the question extended to how to implement a per-caller rate limiter in Java, involving multi-threading and locks.
-
Another question involved merging two sorted arrays, which was not difficult.
- Second Round of Coding:
- Scenario: There are n students (0 to n-1) in the classroom, and each student has a best friend (one-way relationship; if A is B’s best friend, B is not necessarily A’s best friend).
- Input: A size n integer array M where M[i] is student i’s best friend.
- Constraint: Every student needs to sit next to his best friend.
- Output: The number of groups (students sitting together form a group) and how many students are in the largest group.
-
Example: Given M: [1,0,3,4,5,2], 0 and 1 sit together, 2, 3, 4, 5 form a circle. Thus, there are 2 groups, with the largest group having 4 students.
- Few interviews on Netflix in Dili, with minimal experience on engineering management roles.
- Contributed one interview but often struggled with insufficient points, leading to a request for support.
- Received a referral from a previous colleague; the recruiter contacted swiftly the next day.
- First interview: a half-hour phone call with the recruiter focusing on behavioral issues. Essential to review the culture deck beforehand.
- Second interview: a half-hour call with the hiring manager, centered around management issues, not technical.
- Two rounds of on-site interviews followed:
- The first on-site round involved meetings with the engineering group.
- The second on-site round involved meetings with cross-functional and higher-level leaders.
- Three interviews were conducted in the first on-site round, with an initial expectation of system design discussions, which ultimately focused solely on behavioral aspects.
- Answers to questions were very general; regretted forgetting important points from the culture deck.
-
No news yet from the first round of on-site interviews; hopeful for a positive outcome, otherwise considering a move to Facebook to start anew.
-
Designing a counter system, like a view count or metrics tracker, involves several stages, starting from a single server on bare metal infrastructure and eventually scaling up to a cloud-based solution. This process is iterative and can vary significantly based on specific requirements, traffic expectations, and technological preferences. Here’s a structured approach to designing and scaling such a system:
-
Initial Design on a Single Server (Bare Metal)
- Counter Storage: Implement the counter using an in-memory data structure for fast read/write operations, such as a hash map where keys are resource identifiers (e.g., video IDs for view counts) and values are the counts.
- Persistence: Periodically write the in-memory counts to a disk-based database to ensure durability. SQLite or a simple file-based storage could work at this scale.
- Concurrency Handling: Use locks or atomic operations to manage concurrent accesses to the counter to ensure accuracy.
- Caching Strategy: Implement caching to reduce read load, especially for frequently accessed counters.
-
Scaling Up: Multi-Server Environment
- Data Partitioning (Sharding): As traffic grows, partition the data across multiple servers to distribute the load. This can be based on resource IDs or hash-based sharding.
- Load Balancing: Introduce a load balancer to distribute incoming requests evenly across servers.
- Replication: Implement replication for each shard to improve availability and fault tolerance.
- Consistency and Synchronization: Employ consistency mechanisms like eventual consistency or stronger consistency models, depending on the requirement. This might involve distributed locks or consensus protocols in complex scenarios.
-
Moving to the Cloud
- Leverage Managed Services: Utilize cloud-native services for databases, caching, and load balancing to reduce management overhead. Services like Amazon RDS for databases, ElastiCache for caching, and Elastic Load Balancer can be beneficial.
- Auto-Scaling: Implement auto-scaling for the application servers and databases based on load, ensuring that the system can handle spikes in traffic without manual intervention.
- Global Distribution: If the audience is global, consider using a Content Delivery Network (CDN) for caching views at edge locations to reduce latency.
- Monitoring and Metrics: Use cloud monitoring tools to track system performance, usage patterns, and potential bottlenecks. This data is crucial for making informed scaling decisions.
-
Conversation-Driven Design Considerations
- Deep Dive on Assumptions: Be prepared to discuss and justify every assumption, such as why a particular database or caching strategy was chosen.
- Component Justification: For each component proposed, explain its role, how it fits into the overall architecture, and why it’s the best choice.
- Handling Failures: Discuss strategies for dealing with component failures, data inconsistencies, and other potential issues that could arise during scaling.
- Security and Compliance: Ensure that the design incorporates necessary security measures and complies with relevant data protection regulations, especially when moving to the cloud.
-
This approach not only helps in tackling the technical challenges of scaling but also prepares you for a detailed discussion with an interviewer, demonstrating your ability to think critically about system design and scalability.
-
Your description outlines a comprehensive interview process for a machine learning engineering position, starting from the initial resume submission to the onsite interview rounds. Here’s a structured summary:
- Initial Steps:
- Resume Submission: You submitted your resume online in mid-September.
- Initial Appointment: The recruiter scheduled a meeting at the hiring manager’s (HM) store within 3 days to assess if your work projects align with the job requirements.
-
Technical Screen: One week after the initial appointment, a technical screening was arranged.
- Technical Screening:
- Interviewer Background: The interviewer, an Indian male ML engineer, recently graduated from Faye Wong University and has over 4 years of experience. He is described as very nice and specializes in causal inference.
-
Interview Focus: The main part of the interview involved introducing an ML project followed by a discussion on statistics and ML through eight-part essays. Shortly after the interview, the recruiter contacted you for the onsite interview.
- Onsite Interview:
- Overview: The HM outlined a five-round onsite interview process, warning of a potential “sudden death” round in the middle.
- Round 1 (Indian Uncle): You were given two lists of movies/shows with various details from Faye Wong and a third party. The task involved writing code to find the closest matches and discussing how ML could solve real-world problems, deploy monitoring indicators, and design statistical tests.
-
Round 2 (Indian Lady): Focused on recommendation systems and search functionalities, with detailed questions about handling scenarios encountered by Faye Wong. For instance, what to do if a searched movie is unavailable and how to leverage the recommendation algorithm and context information. The round concluded with coding questions on serializing and deserializing ML model parameters. You noted a contrast in friendliness compared to the male interviewer.
- Round 3: Brother Xiaobai
- Interviewer Description: Brother Xiaobai is described as looking very cool and cute. It’s unclear if this person is also from Faye Wong or another entity.
-
Interview Focus: This round seems to involve Faye Wong’s dataset of movie/show pairs (title1, title2), representing the number of viewers of similar movies in different regions. Unfortunately, the description of the task or questions for this round was not completed.
-
To provide a useful continuation or answer, I’d need more details about what Brother Xiaobai’s round involved. Was it a coding challenge, a discussion on handling large datasets, or perhaps a machine learning model design question related to viewer prediction or regional preferences analysis?
- Additional Interview Focus with Brother Xiaobai or Subsequent Rounds:
- Behavioral Questions (BQ): The interviewer asked about your views on their company culture along with some general questions, indicating an interest in assessing cultural fit and personal values.
- Design Questions: Surprisingly, the interview also included technical design questions, such as:
- A/B Testing: Discussing approaches to conduct A/B tests, which are critical for evaluating new features or changes in a controlled manner.
- ML Deployment Issues: Questions on machine learning deployment challenges, including best practices for deploying models into production.
- Data Monitoring: A specific focus on how to monitor data drift, especially when true labels cannot be obtained in a timely manner, using tools like Metaflow or similar technologies. This implies a deep dive into managing model performance and reliability over time in real-world scenarios.
- Closing Thoughts:
- The interviewer conveyed a technically strong impression, reflecting a comprehensive assessment covering technical skills, cultural fit, and practical challenges in ML deployment and maintenance.
-
The message ends with well-wishes for the New Year, hoping that the shared experiences will be beneficial to others and expressing optimism for receiving attractive job offers in the future.
- Design a distributed database that syncs across 3 regions and 3 zones within the regions.
- Requirement: eventually consistent system
- Netflix/youtube offers multiple services. I am trying to design a system that counts how minutes watched on particular video, number of video watched completely and Category of videos most watched.
- I am new to system design when it comes to complex designs. If you have any links or documents that would be helpful. I would appreciate your help in advance.
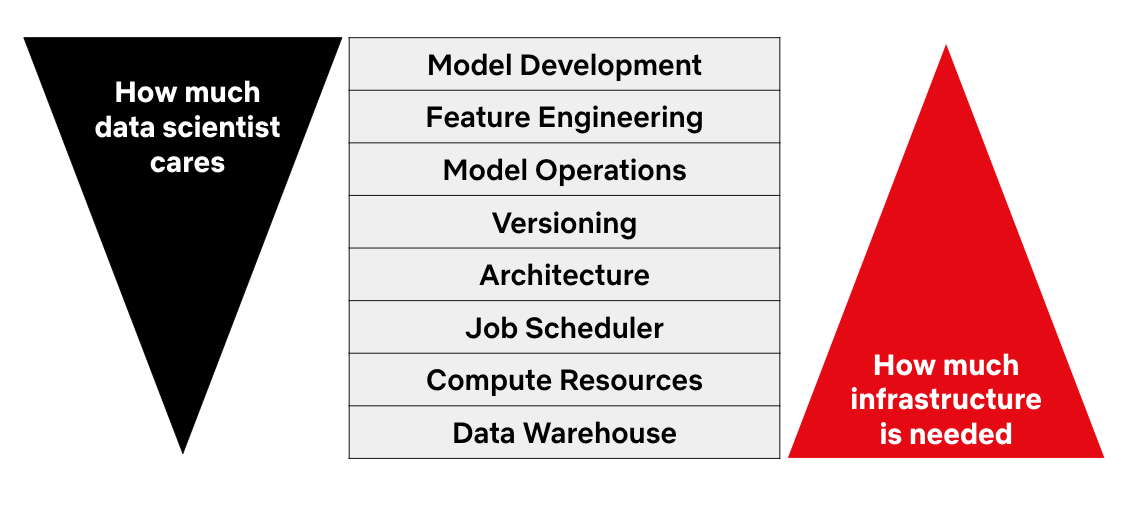
The motivation
- Real-life production ML systems operate autonomously, reacting to new data and events automatically. Besides indvidual workflows, Metaflow allows you to build advanced reactive ML systems. For instance, you can trigger a workflow whenever new data is available:
- We’re spending way too much time on infrastructure and tooling
- Parallelization/ orchestration is an issue
- Software engineers have great hygiene with git, but what about ML engineers?
- Model Development
- Feature Engineering
- Model Operations in production
- Versioning the data, the features, the models
- Job schedulers
- Compute resources
- Data warehouse
- Ville Tuulos -> architect for MetaFlow / founder of Outerbounds
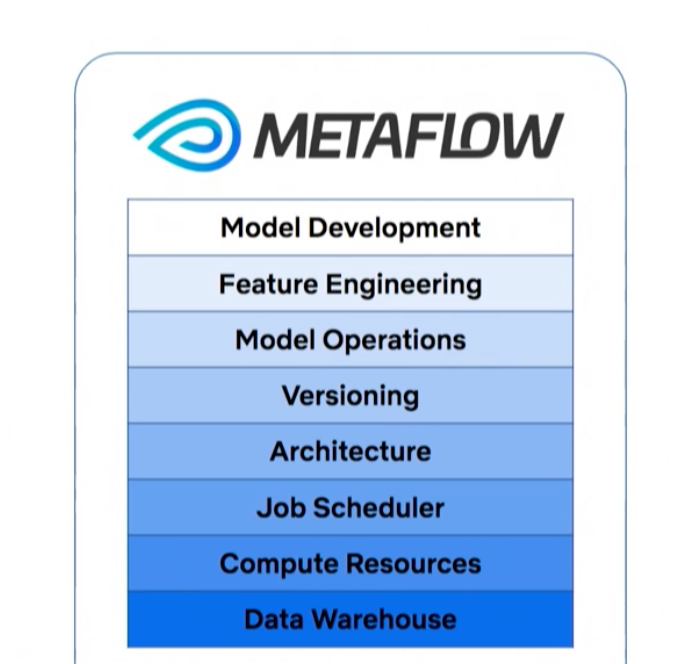
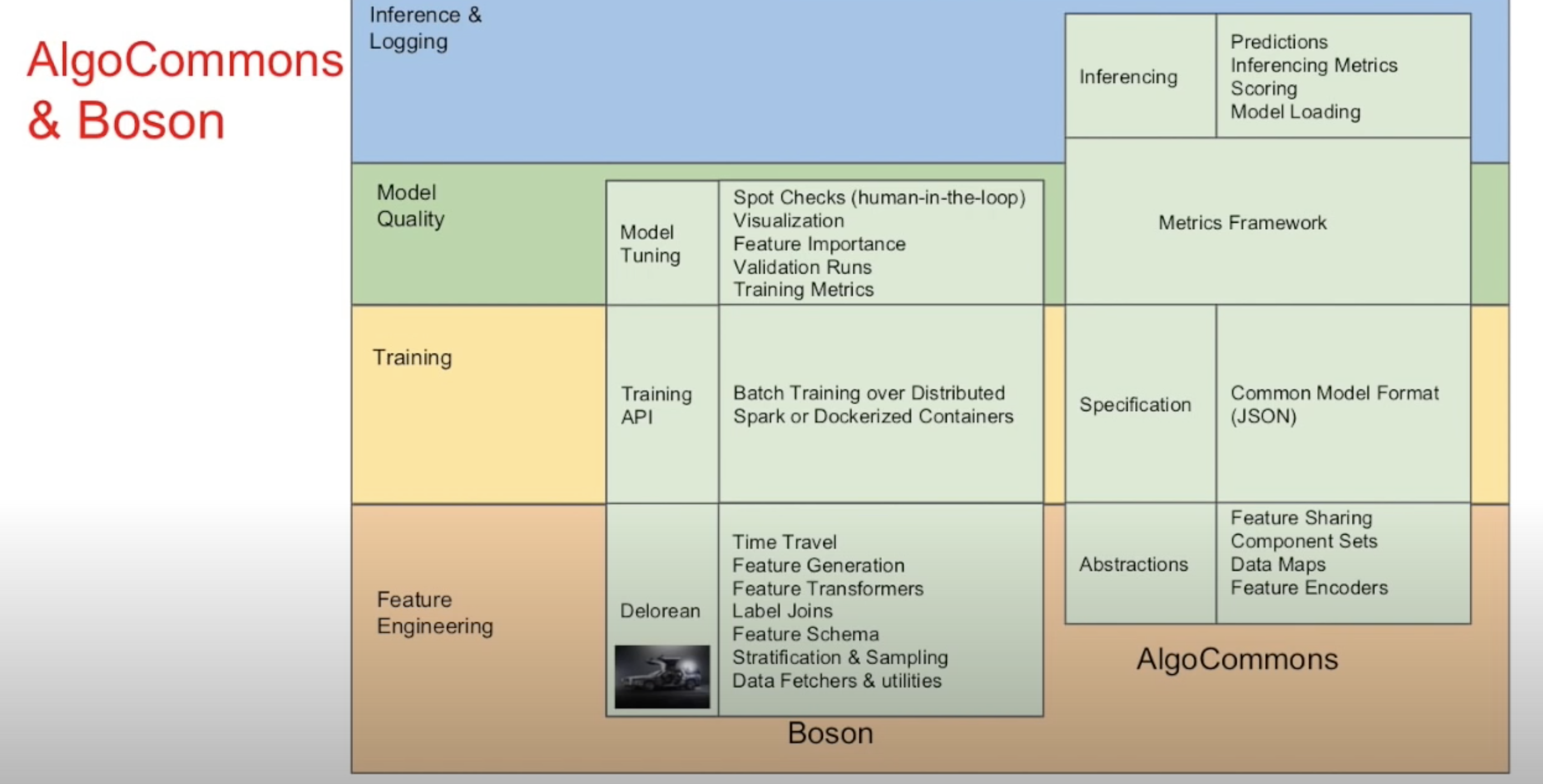
- Metaflow only cares about the bottom of the stack
-
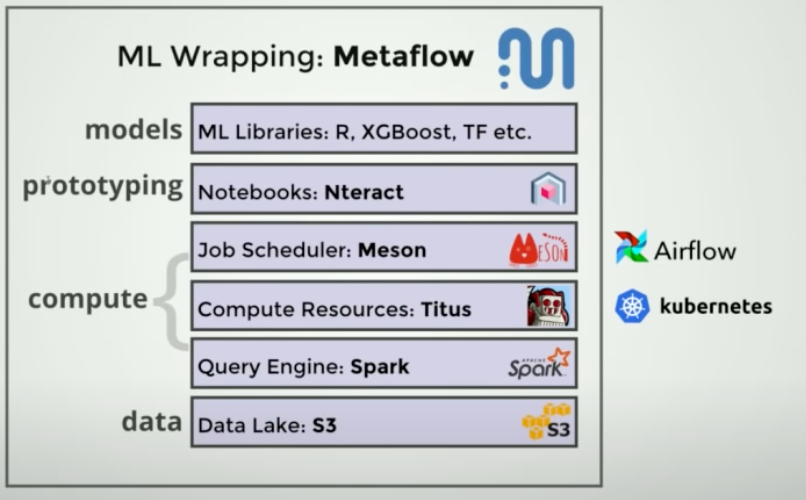
- Metaflow UI, support for the other clouds, tagging (add a label to each run this run corresponds to production, git message)
- It provides a Python-based interface that simplifies the entire lifecycle of data science workflows, from data processing and experimentation to model deployment.
- With features like automatic versioning of experiments, easy scalability from a laptop to the cloud, and integration with existing data science tools, Metaflow focuses on enhancing the productivity of data scientists by abstracting away the complexities of infrastructure and pipeline management.
- This allows data scientists to concentrate more on data analysis and model building, rather than on the technical details of implementation and deployment.
Competitors
- Luigi by Spotify (cant test locally)
- Airflow (how do I do compute, does not do versioning)
Problems
- Which version of Tensorflow do we need
What is Metaflow?
- Metaflow helps you access data, run compute at scale, and orchestrate complex sets of ML and AI workflows while keeping track of all results automatically. In other words, it helps you build real-life data, ML, and AI systems.
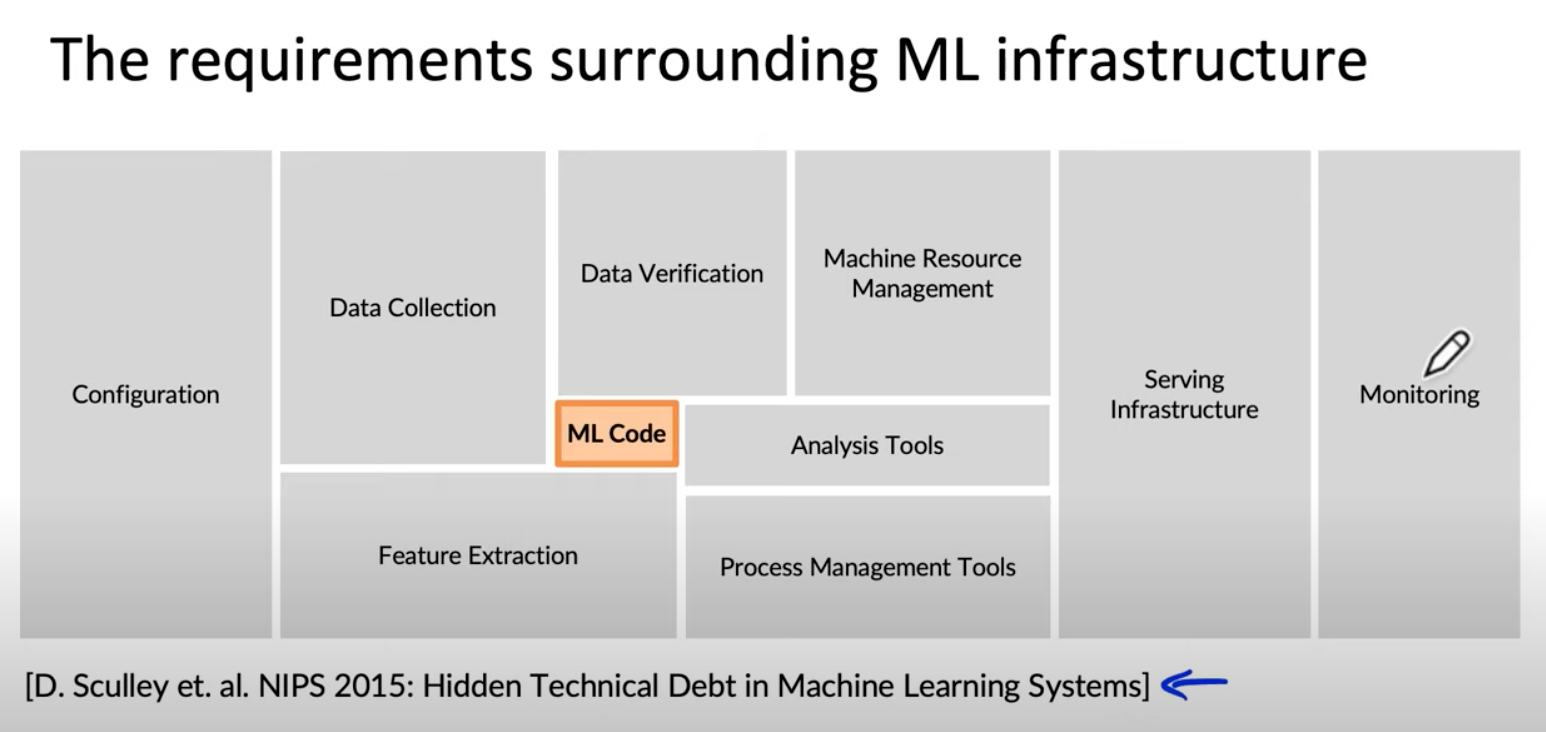
It is one thing to build systems and another to operate them reliably. Operations are hard because systems can misbehave or fail in innumerable ways; we need to quickly understand why and proceed to resolve the issue. The challenge is especially pronounced in data, ML, and AI systems, which can exhibit a cornucopia of failure patterns - some related to models, some to code, some to infrastructure, and many related to data.
-
Workflow Orchestration : Metaflow helps structure data science projects by organizing the code into easily manageable, logical steps. It provides a way to define workflows, which are sequences of steps, each performing a specific task (e.g., data preprocessing, training a model).
-
Code Execution on Various Platforms : While Metaflow itself doesn’t provide computational resources, it simplifies the process of running code on different platforms. It allows seamless switching from running code on a local machine to executing it on larger-scale cloud platforms like AWS.
-
Automatic Data Versioning and Logging : Metaflow automatically versions and logs all data used and produced at each step of a workflow. This feature makes it easy to track experiments, reproduce results, and understand the flow of data through the various steps.
-
Built-in Scaling and Resource Management : Metaflow can automatically scale workflows, handling resource allocation and parallelization. This means it can execute tasks on larger datasets and compute clusters without requiring significant changes to the code.
-
Experiment Tracking and Debugging : With its built-in tracking and logging, Metaflow simplifies debugging and tracking the progress of experiments. Data scientists can easily access previous runs, inspect results, or compare different iterations of their models.
-
Integration with Existing Data Tools : Metaflow is designed to work well with commonly used data science tools and libraries (like Jupyter, pandas, scikit-learn), allowing data scientists to continue using familiar tools while benefiting from the additional capabilities Metaflow provides.
-
Simplified Deployment : Metaflow can package and deploy models, taking care of dependencies and environment configurations, which simplifies the process of moving a model from development to production.
-
Plugin Architecture : Metaflow offers a plugin architecture, allowing for customization and extension. For example, while it doesn’t provide its own storage, it can be configured to interface with different storage solutions.
-
In summary, Metaflow acts as a facilitator and orchestrator for data science projects. It provides the framework and tools to efficiently manage, execute, and track data science workflows, leveraging existing infrastructure (like AWS) for storage, computation, and other needs. Its primary aim is to make the life of a data scientist easier by abstracting away many of the complexities involved in running data science projects at scale.
Metaflow observability
Metaflow achieves its functionality through a combination of a well-designed Python library, a set of conventions and best practices for workflow design, and integration with underlying infrastructure, particularly cloud services. Here’s a closer look at how Metaflow accomplishes its objectives:
Python Library and API
- Workflow Definition: Metaflow provides a Python library that allows data scientists to define workflows as Python scripts. Each script can be broken down into steps, with each step representing a part of the data science process (like data loading, preprocessing, training models, etc.).
- Decorators: It uses decorators extensively to add additional functionalities to steps in the workflow. These decorators handle things like specifying resources required (CPU, memory), managing dependencies, and branching logic in the workflow.
Data Versioning and Logging
- Automatic Versioning: Metaflow automatically versions the data at each step of the workflow. This means every time a step is executed, the data inputs and outputs are logged and versioned.
- Artifact Tracking: It tracks all data used and produced in the workflow, known as “artifacts,” which can include datasets, models, or even intermediate variables.
Execution on Various Platforms
- Local and Cloud Execution: While you can run Metaflow on a local machine, it also integrates with cloud platforms (AWS in particular). Metaflow can execute workflows on AWS, managing tasks such as spinning up necessary compute instances and scaling resources as needed.
- Containerization: Metaflow can package workflows into containers, allowing for consistent execution environments, both locally and in the cloud.
Resource Management
- Resource Allocation: Metaflow allows you to specify the resources needed for each step (like CPU and memory). It manages the allocation of these resources, whether on a local machine or in the cloud.
- Parallelization and Scaling: For steps that can be executed in parallel (like training models with different hyperparameters), Metaflow can manage the parallel execution and scaling.
Experiment Tracking and Debugging
- Metadata Service: Metaflow maintains a metadata service to keep track of all runs and their corresponding data. This service enables easy tracking and comparison of different runs.
- Debugging Support: The framework provides tools to inspect previous runs, which is particularly useful for debugging and understanding the workflow’s behavior.
Integration with Cloud Services
- AWS Integration: Metaflow offers deep integration with AWS services. This includes using S3 for data storage, AWS Batch for compute tasks, and AWS Step Functions for orchestrating complex workflows.
Plugin Architecture
-
Customization: The plugin architecture of Metaflow allows it to be extended and customized to fit specific needs. This could include integrating with different storage solutions, compute environments, or data processing tools.
-
In essence, Metaflow automates and simplifies many of the routine but complex tasks associated with running data science projects. Its design is focused on making these tasks as seamless and straightforward as possible, allowing data scientists to focus on the actual science rather than the underlying infrastructure and operational details.
Certainly! Here’s a simple example to illustrate how Metaflow is used in a data science workflow. This example will demonstrate defining a workflow, using decorators for resource allocation, versioning, and running steps, and integrating with AWS for cloud execution.
Please note, this is a basic illustration. In real-world scenarios, workflows can be much more complex and involve advanced features of Metaflow.
Sample Metaflow Workflow
First, make sure you have Metaflow installed. You can install it using pip:
pip install metaflow
Now, let’s create a simple workflow with Metaflow:
from metaflow import FlowSpec, step, card
class MyDataScienceProject(FlowSpec):
@step
def start(self):
"""
The 'start' step is the entry point of the flow.
"""
print("Starting data science workflow...")
# Initialize some data
self.my_data = [1, 2, 3, 4, 5]
self.next(self.process_data)
@step
def process_data(self):
"""
A step to process data.
"""
print("Processing data...")
# Perform some data processing
self.processed_data = [x * 2 for x in self.my_data]
self.next(self.end)
@step
def end(self):
"""
The 'end' step concludes the flow.
"""
print("Processed data:", self.processed_data)
print("Workflow is complete.")
# Run the flow
if __name__ == '__main__':
MyDataScienceProject()
Running the Flow
To run this Metaflow script, save it as a Python file (e.g., my_data_science_project.py) and execute it from the command line:
python my_data_science_project.py run
Explanation
- @step Decorator: Each method in the class decorated with
@steprepresents a step in the workflow. Metaflow automatically manages the transition from one step to the next. - Data Passing: Metaflow automatically handles the passing of data (
self.my_dataandself.processed_data) between steps. - Workflow Definition: The workflow is defined as a Python class (
MyDataScienceProject), making it intuitive for Python programmers. - Execution: Running the script with
python my_data_science_project.py runexecutes the workflow from start to end.
Integration with AWS
Metaflow can seamlessly scale this workflow to AWS. By using decorators like @batch or @step, you can specify resources and configure AWS execution. However, running workflows on AWS requires setup and configuration of your AWS environment, and the appropriate AWS-related decorators in your script.
This example is a basic demonstration. Metaflow supports much more sophisticated functionalities, including conditional branching, parallelization, complex data manipulations, integration with external data sources, and model deployment. For more advanced use cases, you would typically leverage these additional features of Metaflow.
Metaflow
Pros:
- User-Friendly for Data Scientists: Metaflow is designed with a focus on the data scientist’s workflow, making it easy to prototype, build, and deploy models without deep expertise in infrastructure management.
- Integrated Workflow Management: It provides a seamless experience from data extraction to model deployment, with automatic versioning, easy access to past runs, and experiment tracking.
- Abstraction from Infrastructure: Metaflow abstracts away many infrastructure details, allowing data scientists to focus on model development and experimentation.
- Scalability and Flexibility: It easily scales from a single machine to cloud-based resources, handling resource allocation and parallelization effectively.
- Integration with Common Tools: Metaflow integrates well with popular data science tools and libraries.
Cons:
- Limited to Python: As of now, Metaflow is primarily Python-based, which might be a limitation if your workflow requires other programming languages.
- Less Control Over Infrastructure: While abstraction is beneficial for simplicity, it can limit control over the underlying infrastructure, which might be a drawback for complex, customized workflows.
- Dependence on Metaflow’s Design Choices: Users are somewhat at the mercy of the design and architectural decisions made by the Metaflow team.
Outerbounds
- Model training platform that helps gets from prototype to production faster than any platform
- @Resource: decorator for GPU compute
- Amazon prime uses it
- daily cost keeps track, dashboard
- who ran what training
- monitoring
- requesting this much memory but only using this much during training
- Cost reporting with metaflow
- Support
- Data agnostic
- create an IAM role -> dev opsy
- very standard cloud formation
- easy ramp up
- desktop VS code
- docker image
- Role based access control
-
Cost monitoring
- Data drift handling: https://arize.com/model-drift/
Metaflow job descrip
- Engineering Manager, Metaflow, Machine Learning Platform
- Netflix · Los Gatos, CA · Reposted 1 week ago · Over 100 applicants
- $180,000/yr - $900,000/yr Full-timeMatches your job preferences, job type is Full-time.
- 10,001+ employees · Entertainment Providers
- Skills: Engineering Management, Computer Science, +8 more
- Netflix is the world’s leading streaming entertainment service with 238M paid memberships in over 190 countries enjoying TV series, documentaries, and feature films across a wide variety of genres and languages. Machine Learning drives innovation across all product functions and decision-support needs. Building highly scalable and differentiated ML infrastructure is key to accelerating this innovation.
- We are looking for an experienced engineering leader to lead the Metaflow team in the Machine Learning Platform org. The ML Platform org is chartered to maximize the business impact of all ML practice at Netflix and innovate on ML infrastructure to support key product functions like personalized recommendations, studio innovations, virtual productions, growth intelligence, and content demand modeling among others.
- Metaflow is an OSS ML platform developed here at Netflix, and now leveraged by several companies around the world. The Metaflow team within Netflix continues to develop our internal version and ecosystem of Metaflow, the most advanced in the world, to drive even higher levels of ML productivity for our customers. Our internal ecosystem includes fast data processing, ML serving capabilities, and other extensions not available elsewhere.
- In this role you will be responsible for a high visibility, widely adopted product that 100+ ML projects within Netflix, spanning consumer scale personalization, growth, studio algorithms, and content understanding models. We are looking for a leader who has prior experience building ML infrastructure, has a strong product sense, and technical vision to help take Metaflow to the next level of impact. Metaflow has the opportunity to grow in many ways such as higher level ML abstractions to reduce the boiler plate for common use cases, improving Metaflow core in collaboration with OSS to make the existing capabilities more flexible and powerful, and deepening our integration with other internal platform offerings.
- Expectations
- Vision: Understanding the media business and how technology is changing the landscape will allow you to lead your team by providing clear technical and business context.
- Partnership & Culture: Establishing positive partnerships with both business and technical leaders across Netflix will be critical. We want you to regularly demonstrate the Netflix culture values like selflessness, curiosity, context over control, and freedom & responsibility in all your engagements with colleagues.
- Judgment: Netflix teams tend to be leaner compared to our peer companies, so you will rely on your judgment to prioritize projects, working closely with your partners - the personalization research leaders.
- Technical acumen: We expect leaders at Netflix to be well-versed in their technical domain and be a user of the products we are building, so they can provide guidance for the team when necessary. Proficiency in understanding the needs of research teams and how to bring efficient ML infrastructure to meet those needs will be crucial.
- Recruiting: Building and growing a team of outstanding engineers will be your primary responsibility. You will strive to make the team as excellent as it can be, hiring and retaining the best, and providing meaningful timely feedback to those who need it.
- Minimum Job Qualifications
- Experience leading a team responsible for large-scale ML Infrastructure
- Strong product sense – you take pride in building well designed products that users love.
- Outstanding people skills with high emotional intelligence
- Excellent at communicating context, giving and receiving feedback, fostering new ideas, and empowering others without micromanagement
- Willing to take action, without being stubborn - the ability to recognize your own mistakes
- Your team and partners see your humility all the time and diverse high-caliber talent wants to work with you
- Preferred Qualifications
- 10+ years of total experience including 3+ years of engineering management
- Experience with modern OSS ML frameworks such as Tensorflow, PyTorch, Ray.
- Prior experience building and scaling Python ML infrastructure
- Prior experience in personalization or media ML domains.
- Exposure to Kubernetes or other container orchestration systems
- BS/MS in Computer Science, Applied Math, Engineering or a related field
- ML practitioner leader or individual contributor experience owning end-to-end ML functions for a product domain
- Our compensation structure consists solely of an annual salary; we do not have bonuses. You choose each year how much of your compensation you want in salary versus stock options. To determine your personal top of market compensation, we rely on market indicators and consider your specific job family, background, skills, and experience to determine your compensation in the market range. The range for this role is $180,000 - $900,000.
- Netflix provides comprehensive benefits including Health Plans, Mental Health support, a 401(k) Retirement Plan with employer match, Stock Option Program, Disability Programs, Health Savings and Flexible Spending Accounts, Family-forming benefits, and Life and Serious Injury Benefits. We also offer paid leave of absence programs. Full-time hourly employees accrue 35 days annually for paid time off to be used for vacation, holidays, and sick paid time off. Full-time salaried employees are immediately entitled to flexible time off. See more detail about our Benefits here.
- Netflix is a unique culture and environment. Learn more here.
- We are an equal-opportunity employer and celebrate diversity, recognizing that diversity of thought and background builds stronger teams. We approach diversity and inclusion seriously and thoughtfully. We do not discriminate on the basis of race, religion, color, ancestry, national origin, caste, sex, sexual orientation, gender, gender identity or expression, age, disability, medical condition, pregnancy, genetic makeup, marital status, or military service.
AWS Stack Services (e.g., AWS Step Functions, SageMaker, AWS Glue)
Pros:
- Highly Customizable: AWS services offer granular control over every aspect of the infrastructure and workflow, allowing for highly tailored solutions.
- Tight Integration with AWS Ecosystem: They provide seamless integration with a wide range of AWS services, which is beneficial for projects heavily reliant on the AWS ecosystem.
- Scalability and Reliability: AWS services are known for their scalability and reliability, capable of handling very large-scale data processing needs.
- Support for Diverse Workflows: AWS offers a diverse set of tools that can support various types of data workflows, including batch processing, real-time analytics, and machine learning.
Cons:
- Complexity and Learning Curve: The use of AWS services typically requires a good understanding of cloud infrastructure, which can have a steep learning curve.
- Management Overhead: There is more overhead in terms of setting up, configuring, and managing different services and ensuring they work together seamlessly.
- Cost Management: While AWS offers pay-as-you-go pricing, managing costs can be complex, especially with multiple integrated services.
- Potentially More Fragmented Workflow: Using multiple AWS services might lead to a more fragmented workflow compared to an integrated solution like Metaflow.
In summary, Metaflow offers an easier, more integrated experience for data scientists, focusing on simplicity and ease of use, while AWS services offer more control, customization, and tight integration with the AWS ecosystem, albeit with a higher complexity and management overhead. The choice between them will depend on the specific needs of the project, the technical expertise of the team, and the desired level of control over infrastructure and workflow management.
Fairness among New Items in Cold Start Recommender Systems
- Heater, DropoutNet, DeepMusic, and KNN
- Investigated fairness among new items in cold start recommenders.
- Identified prevalent unfairness in these systems.
- Proposed a novel learnable post-processing framework to enhance fairness.
- Developed two specific models, Scale and Gen, following the framework.
- Conducted extensive experiments, showing effectiveness in enhancing fairness and preserving utility.
- Future research planned to explore recommendation fairness between cold and warm items in a unified scenario.
- This work examines the fairness among new items in cold start recommendation systems, highlighting the widespread presence of unfairness.
- To address this issue, a novel learnable post-processing framework is introduced, with two specific models – Scale and Gen – designed following this approach.
- Extensive experiments demonstrate the effectiveness of these models in enhancing fairness while maintaining recommendation utility.
- Future research aims to explore fairness between cold and warm items in a unified recommendation context.
- Mean Discounted Gain
Data drift
Data drift refers to the change in the statistical properties of the data that a model is processing over time. This can lead to decreased model performance if the model was trained on data with different statistical properties. Detecting data drift without access to labels can be more challenging, but it is still possible through various techniques.
-
Statistical Tests: You can conduct statistical tests on the features in your data to check for changes in distribution. Kolmogorov-Smirnov or Chi-squared tests are often used to compare the distribution of the current data with the distribution of the data on which the model was trained. If the test indicates a significant difference, it could be a sign of data drift.
-
Monitoring Feature Statistics: Continuously monitor summary statistics (e.g., mean, median, standard deviation, etc.) of your input features. If there are significant changes in these statistics over time, it may indicate data drift. You can set threshold levels to trigger alerts if the statistics deviate beyond acceptable bounds.
-
Using Unsupervised Learning: Techniques like clustering or dimensionality reduction (e.g., PCA) can be used to represent the data in a way that makes it easier to spot changes. By regularly fitting these techniques to the incoming data and comparing the results with the original training data, you might identify shifts in the data structure.
-
Comparing Prediction Distributions: Even without labels, you can compare the distribution of predictions made on the current data to the distribution of predictions made on the training or validation data. A significant shift might indicate a change in the underlying data distribution.
-
Residual Analysis: If you can obtain a small subset of labeled data, you can analyze the residuals (the difference between the predictions and the true labels). A change in the distribution of residuals over time might be indicative of data drift.
-
Creating a Proxy for Labels: If your production environment involves users interacting with the predictions (e.g., clicking on recommended items), you might create a proxy for true labels based on user behavior and use this to detect changes.
-
Human-in-the-Loop: Depending on the application, it might be feasible to introduce a human review process to periodically evaluate a subset of the predictions. While not fully automated, this can be a powerful way to detect issues that automated methods might miss.
-
Use of Drift Detection Libraries: There are libraries and tools designed specifically for drift detection, like the Python library Alibi-Detect, that can be implemented to monitor for data drift.
Remember, detecting data drift is not always straightforward, especially without access to true labels. The appropriate approach may depend on the specifics of your data, model, and application. It’s often useful to combine multiple methods to create a more robust detection system. Regularly reviewing and updating your model with new training data reflecting the current data distribution is an essential part of maintaining model performance.
Causal Ranker
Certainly! Here’s a bullet-point summary of the information you provided about the Causal Ranker Framework by Netflix:
- Overview:
- Authors: Jeong-Yoon Lee, Sudeep Das.
- Purpose: To enhance recommendation systems by incorporating causal inference into machine learning.
- Concept: Moving beyond mere correlations to understand causal mechanisms between actions and outcomes.
- Machine Learning vs Causal Inference:
- Machine Learning: Focuses on associative relationships, learning correlations between features and targets.
- Causal Inference: Provides a robust framework that controls for confounders to estimate true incremental impacts. This adds understanding of the causal relationship between actions and results.
- Application at Netflix:
- Current Systems: Netflix uses recommendation models for personalizing content on user homepages.
- Need: Netflix identified the potential benefit of adding algorithms that focus on making recommendations more useful in real-time, rather than merely predicting engagement.
- Causal Ranker Framework:
- Introduction: A new model applied as a causal adaptive layer on top of existing recommendation systems.
- Components: Includes impression (treatment) to play (outcome) attribution, true negative label collection, causal estimation, offline evaluation, and model serving.
- Goal: To find the exact titles members are looking to stream at any given moment, improving recommendations.
- Reusability: Designed with generic and reusable components to allow adoption by various teams within Netflix, promoting universal improvement in recommendations.
- Implications:
- Scalability: By combining machine learning with causal inference, the framework offers a powerful tool that can be leveraged at scale.
- Potential Impact: Enhancing personalization, meeting user needs more effectively, and aligning recommendations with users’ immediate preferences.
- The Causal Ranker Framework symbolizes an innovative step in recommendation systems, emphasizing the importance of understanding causal relationships and catering to real-time user needs. Its flexibility and comprehensive design have positioned it as a potential game-changer within Netflix’s personalization efforts and possibly beyond.
Question bank
- Behavior interview with hiring manager
- Past projects - most challenging part, your role
- The most challenging thing about being a manager is also the most rewarding. As the team’s manager, I’m responsible for not just my own success but that of my team as well. In that sense, my charter typically involves a much bigger scope than as my prior role as an individual contributor. However, navigating a big ship comes with its own set of unique responsibilities. You are responsible not only for yourself, but for your team. So you must continually measure their performance, set clear expectations/goals/priorities, make sure the communication is crisp and clear, motivate them, and keep them focused. At the end of the day, it is a great feeling to be able to accomplish this.
- Also, another important aspect of this position would be to build the relationship with my employees because that will take time. However, I also feel it is one of the most rewarding part of this position. I enjoy relationship-building and helping others to achieve their success.
- Tell me a time when you disagree with the team
- I can tell you a time where I disagreed with my leadership.
- At the time, we were working on content to content recommendations, books to podcast with cross collaborations with Amazon retail, audible and wondery (podcast platform).
- There were a lot of novel insights and a unique architecture we approached to solve this and thus, we decided to get a publication out of this.
- The process to start this off at Amazon, requires Director level approval to kick off the writing process, however, my managers manager, who sits under the Director, wanted to set up a meeting to discuss this before we presented it to the Director to approve.
- This went against Amazon’s policies and would hinder time to submit to the conference. I respectfully,
- Tell me a time when you inherited a system in bad shape
- How do you prioritize
- Name five devices you can watch Netflix on – Systems engineer candidate
- What would you do if you were the CEO? – Partner product group candidate
- Describe how you would deal with a very opinionated coworker.
- I think netflix coins this term as “brilliant jerks.” Engin. Complaints about everyone on the team.
- They were
- Tell me about a previous time you screwed up at your previous job.
- What has been the biggest challenge while you work?
- How do you improve Netflix’s service? – Financial analyst candidate
- Who do you think are Netflix’s competitors and why? – Creative coordinator candidate
-
How do you test the performance of your service? – Software engineer candidate
- Because Netflix is focused on maintaining a strong company culture—the majority of questions that the hiring manager will ask will be situational, cultural, and behavioral-style questions. Like the example questions above.
- When asked these questions it is very easy to get nervous and mix up all of our responses. In this situation, the best way to stay structured is by using the STAR Methodology, which stands for Situation, Task, Action, and Result
- Let’s dive into an example so that you can better understand this method:
- Example question:
- How did you handle a task where you had a deadline that you couldn’t meet?
- Situation:
-
Don’t generalize the information that you are conveying**. Be as specific as possible when describing the situation, so that the person asking the question understands the context.
-
Example: Because the last company I was working at was growing so quickly, we did not have enough staff to cover all of the projects. Most people like me had more projects than we could handle, and that did cause stress and tension.
- Task:
-
Describe your responsibility and the goal you were working towards.
-
Example: I was a project manager that was in charge of application releases. I had to make sure that the applications were launched in the right order and on the right date.
- Action:
-
You must provide what specific actions you took towards solving the problem. Also, make sure that you do not focus on talking about any other team member. Try using the word “I” and not “we”.
-
Example: To make sure that I wasn’t too overwhelmed, I created a project timeline. I then organized all of the app launches in order of priority. If an application was not going to be launched on time or if it had low priority—I made sure to bring this up to my superiors and explain what my plan was.
- Result:
-
This is your time to shine. Describe the outcome of the situation in detail, and show how you were able to solve the problem.
-
Example: Because I created a timeline and took charge of prioritizing the launch, we were able to be much more efficient. Once the big launches were done, I was able to create much more time for the team. This led us to complete more projects than we thought was possible and generate more revenue for the company.
- hm screening team lead, they asked about the current system in very, very detailed terms.
- You must be very clear about your project and failure point. There are still a lot of bq, and the previous experience still has scenario based problems.
- cross functional
- Then I introduced myself. After talking about the background, I said that I want to go through all the projects on the resume for you? He said you tell me your favorite, so I will tell you one. After he finished speaking, he began to ask questions. If you want causal to be based on what assumptions, how did you rule out some possible reasons, are you confident that you ruled out other things that may affect causality? I said what I controlled, what fixed effects I added, so I was comparing with whom, and what robustness checks I did..
- under what circumstance is the power the highest for A/B test
- Suppose you want to do an experiment, that is, whether to use static pictures or dynamic videos on the netflix homepage, so that more people can sign up for subscription.
- I said, first of all, I need to determine my population, ah, do you want to be global or just the United States. He said global.
- Then I said that I want to determine my sample, it is best that a certain percentage of people from each country come in as a sample.
- Then I need to determine my time. Then I have to take into account that the audiences who come in at different times in the morning, noon and evening are different. The audience who come in on weekdays and weekends are different. Holidays may also be a problem, but you can’t do this experiment. Years, so it must be at least a week? (Then my brother praised me! He said I thought well!)
- Then I want to determine the outcome variable, that is whether to sign up.
- Wow, a lot of details, I said just do a t test, if there is no problem with the randomization (for example, I check the balance)
- What is the common misunderstanding of P value?
- Ans: The hypothesis can only reject or not reject, but not accept.
your projects
ooooo
- A director, Uncle Bai, mainly asked BQ, what he thinks of their culture, and some general questions.
- Surprisingly, I was even asked some questions about design, a/b test and Ml deployment, how to monitor data drift if the true label cannot be obtained in time on metaflow, etc.
- It feels technically strong.
- Kolmogorov
Syllabus
- Since the goal is to prepare for the specific role at Netflix, focusing on applied aspects of econometrics and causal inference that relate to personalization, satisfaction estimation, and working with large-scale data, the study plan would be as follows:
Week 1-2: Introduction to Econometrics
- Reading: “Introductory Econometrics: A Modern Approach” by Jeffrey M. Wooldridge - Focus on introductory chapters.
- Online Course: Coursera’s “Econometrics: Methods and Applications” - Focus on the basic methods and applications.
- Hands-on Practice: Work with simple datasets to apply linear regression and understand the assumptions behind it.
Week 3-4: Time-Series Analysis & Forecasting
- Reading: “Applied Econometric Time Series” by Walter Enders.
- Online Tutorial: “Time Series Analysis in Python” on DataCamp or similar platforms.
- Project: Forecasting a time series data like stock prices or user activity trends.
Week 5-6: Causal Inference - Basics
- Reading: “Causal Inference in Statistics: A Primer” by Judea Pearl.
- Online Course: “Causal Inference” on Coursera by Columbia University.
- Hands-on Practice: Implementing propensity score matching and other techniques on observational data.
Week 7-8: Experimental Design & A/B Testing
- Reading: “Field Experiments: Design, Analysis, and Interpretation” by Alan S. Gerber and Donald P. Green.
- Online Tutorial: A/B Testing tutorials on platforms like Udacity.
- Project: Design a hypothetical A/B test for a feature that could enhance user satisfaction.
Week 9-10: Advanced Causal Inference & Machine Learning Integration
- Reading: “Causal Inference for Statistics, Social, and Biomedical Sciences” by Guido W. Imbens and Donald B. Rubin.
- Online Course: “Causal Machine Learning” on Coursera by University of Pennsylvania.
- Hands-on Practice: Apply causal machine learning techniques to a complex dataset.
Week 11-12: Reinforcement Learning
- Reading: “Reinforcement Learning: An Introduction” by Richard S. Sutton and Andrew G. Barto.
- Online Course: “Reinforcement Learning Specialization” on Coursera by the University of Alberta.
- Project: Build a simple recommendation system using reinforcement learning.
Week 13-14: Application to Real-World Problems
- Case Studies: Research and analyze Netflix’s research papers or blogs related to personalization, satisfaction estimation.
- Project: Work on a complex project that integrates econometrics, causal inference, and machine learning to solve a real-world problem similar to what Netflix is facing.
Ongoing: Networking & Keeping Up-to-Date
- Conferences & Workshops: Attend industry conferences related to data science, econometrics, and machine learning.
- Blogs & Podcasts: Follow related blogs and podcasts like “Not So Standard Deviations” to keep up with the latest in the field.
Remember, this study plan can be tailored to fit your specific needs and existing knowledge base. It combines a mix of theoretical understanding with hands-on practice and real-world applications, focusing on areas most relevant to the Netflix role.