OpenAI
Coding questions
- Objective: To compute a new path based on a current location and a change directive.
Changing Working Directory
Curent Change Output
/ /facebook /facebook
/facebook/anin ../abc/def /facebook/abc/def
/facebook/instagram ../../../../. /
To solve this coding question, we can follow a systematic approach. Here’s the strategy:
-
Parse and Normalize Paths: Convert both the current and change paths into lists of directories. This involves splitting the paths by ‘/’ and handling special directory names like ‘.’ (current directory) and ‘..’ (parent directory).
-
Handle Relative Changes: Process the change directory path to reflect changes relative to the current directory. Each ‘..’ in the change path should remove one directory from the end of the current path, while other directory names should be appended to it.
-
Construct the Final Path: Join the processed directories back into a single path string.
-
Optimization Considerations: Since string manipulation can be costly, we should try to minimize operations like concatenation. We’ll use lists to handle path segments and join them only at the end.
-
Time and Space Complexity Analysis: After the code, we will analyze the time and space complexity.
-
Test Cases: Finally, we will write test cases to validate our solution.
Let’s proceed with the implementation:
def resolve_path(current: str, change: str) -> str:
"""
Resolve the final path given a current path and a change path.
Args:
current (str): The current directory path.
change (str): The directory path to change to.
Returns:
str: The resolved final path.
"""
# If the change path is empty, return the current path as is.
if not change:
return current
# If the change path is absolute (starts with '/'), ignore the current path.
if change.startswith("/"):
current = ""
# Initialize a list to store the segments of the final path.
path = []
# Combine the current and change paths, and split into segments.
for segment in (current + "/" + change).split("/"):
# If the segment is "..", move up one directory (remove last element from path).
# Ensure there is a directory to move up from.
if segment == "..":
if path:
path.pop()
# If the segment is a valid directory name (not empty and not "."),
# add it to the path list.
elif segment and segment != ".":
path.append(segment)
# Construct the final path by joining the segments with '/' and adding a leading '/'.
return "/" + "/".join(path)
# Example usage
print(resolve_path("/facebook/anin", "../abc/def")) # Output: "/facebook/abc/def"
# Time and Space Complexity Analysis:
# Time Complexity: O(n + m) or O(n) where n is the length of the current path and m is the length of the change path.
# Space Complexity: O(n + m) for storing the split paths.
Follow ups with ~ home path and symbolic link
def resolve_path(current: str, change: str, home_dir: str, symlink_map: dict) -> str:
"""
Resolve the final path given a current path, a change path, user's home directory, and a symbolic link map.
Args:
current (str): The current directory path.
change (str): The directory path to change to.
home_dir (str): The user's home directory path.
symlink_map (dict): A dictionary mapping symbolic links to their real paths.
Returns:
str: The resolved final path.
"""
if change.startswith("~"):
# Replace '~' with the user's home directory
change = change.replace("~", home_dir, 1)
if change.startswith("/"):
current = ""
path = []
for segment in (current + "/" + change).split("/"):
if segment == "..":
if path:
path.pop()
elif segment and segment != ".":
# Resolve symbolic links
real_path = symlink_map.get(segment, segment)
path.extend(real_path.split("/"))
# Remove empty segments and join to form the final path
return "/" + "/".join(filter(None, path))
# Example usage
home_directory = "/home/user"
symlink_map = {"link": "/real/path/to/link"}
print(resolve_path("/facebook/anin", "~/docs", home_directory, symlink_map)) # Example with '~'
print(resolve_path("/some/path/link", "../nextdir", home_directory, symlink_map)) # Example with symbolic link
Simplify Path Leetcode 71
- Objective: To simplify an existing absolute path according to Unix-style file system rules.
class Solution:
def simplifyPath(self, path: str) -> str:
# Split the path based on "/"
parts = path.split("/")
# Use a stack to keep track of directories
stack = []
for part in parts:
# ".." means to go one directory up which means popping from stack
if part == "..":
if stack:
stack.pop()
# "." means current directory, so we skip/ignore it
elif part == "." or not part:
continue
else:
# Normal directory name, so push to the stack
stack.append(part)
# Join the stack to form the canonical path
return "/" + "/".join(stack)
Cell Representation:
- Define a Cell class to represent each cell in the spreadsheet. This class will store the cell’s value or formula and any additional information needed for efficient computation.
- Handling Formulas: Implement a method to evaluate the formula in a cell. This will involve parsing the formula and fetching values from the referenced cells.
- Optimization Using Caching:Introduce caching to store the evaluated results of cells. This will prevent redundant calculations, especially for cells that are read frequently. Invalidate or update the cache when a cell’s value is changed.
- Dependency Tracking:Maintain a dependency map to track which cells are dependent on the value of other cells. This is crucial for cache invalidation and updating.
- Efficient Value Retrieval and Update:Implement getCellValue and setCellValue methods. getCellValue will fetch the value from the cache if available, or compute it otherwise. setCellValue will update the cell value and invalidate or update the cache and dependencies as needed.
- Handling Circular Dependencies: Add logic to detect and handle circular dependencies to prevent infinite loops.
from typing import Dict, Optional, Set
class Cell:
def __init__(self, value: Optional[str] = None, formula: Optional[str] = None):
self.value = value
self.formula = formula
self.cached_value: Optional[int] = None # Initialize cache for evaluated value, initially None
self.dependencies: Set[str] = set() # Initialize a set to track dependencies "B1": {"A1", "C1"},
# Evaluate value of the cell and return cell value
def evaluate(self, spreadsheet: 'Spreadsheet') -> int:
# If the cached value exists, this line returns it directly.
# The method doesn't need to recompute the cell's value, leading to a performance optimization.
if self.cached_value is not None:
return self.cached_value
if self.formula:
self.cached_value = 0
parts = self.formula.split('+')
for part in parts:
part = part.strip()
if part.isdigit(): # Check if part is a numeric constant
self.cached_value += int(part)
else:
self.cached_value += spreadsheet.get_cell_value(part)
else:
self.cached_value = int(self.value) if self.value is not None else 0
return self.cached_value
def invalidate_cache(self):
self.cached_value = None
class Spreadsheet:
def __init__(self):
self.cells: Dict[str, Cell] = {}
self.dependencies: Dict[str, Set[str]] = {} # Reverse dependency map
def set_cell_value(self, cell_name: str, value: Optional[str] = None, formula: Optional[str] = None):
if cell_name not in self.cells:
self.cells[cell_name] = Cell()
cell = self.cells[cell_name]
if cell.formula != formula:
self.update_dependencies(cell_name, formula)
cell.value = value
cell.formula = formula
cell.invalidate_cache()
self.invalidate_dependent_cells(cell_name)
def get_cell_value(self, cell_name: str) -> int:
if cell_name not in self.cells:
return 0 # Default value for undefined cells
return self.cells[cell_name].evaluate(self)
def update_dependencies(self, cell_name: str, formula: Optional[str]):
# Remove old dependencies
for dep in self.cells[cell_name].dependencies:
self.dependencies[dep].discard(cell_name)
self.cells[cell_name].dependencies.clear()
if formula:
parts = formula.split('+')
for part in parts:
part = part.strip()
if part not in self.cells:
self.cells[part] = Cell()
self.cells[cell_name].dependencies.add(part)
if part not in self.dependencies:
self.dependencies[part] = set()
self.dependencies[part].add(cell_name)
def invalidate_dependent_cells(self, cell_name: str):
if cell_name in self.dependencies:
for dependent in self.dependencies[cell_name]:
self.cells[dependent].invalidate_cache()
# Test Cases
spreadsheet = Spreadsheet()
spreadsheet.set_cell_value("A1", "5")
spreadsheet.set_cell_value("B1", formula="A1+3")
print(spreadsheet.get_cell_value("B1"))
assert spreadsheet.get_cell_value("B1") == 8 # 5 + 3
spreadsheet.set_cell_value("A1", "10")
assert spreadsheet.get_cell_value("B1") == 13, "Assertion was false at line 87" # 10 + 3
print(spreadsheet.get_cell_value("A1"))
print(spreadsheet.get_cell_value("B1"))
# Time and Space Complexity Analysis:
# Time Complexity:
# Evaluating a Cell Value (evaluate):Time Complexity: O(P), where P is the number of parts in the formula.
# Setting a Cell Value (set_cell_value):Time Complexity: O(D), where D is the number of dependencies for the cell being updated. This includes the time to update dependencies and to invalidate the caches of dependent cells.
# Getting a Cell Value (get_cell_value):Time Complexity: O(D + P), where D is the number of dependencies that need to be evaluated, and P is the number of parts in the formula. In the worst case, if a cell depends on every other cell, and if none of the values are cached, this could approach O(N).
# Space Complexity: O(N + D), where N is the number of cells and D is the total number of direct dependencies across all cells
interview question
- I just finished interviewing Open AI five minutes ago, so I’d like to share it with you while I still remember, so I can help you read it! ! !
- Two rounds, the first round of design, the second round of coding
- design is a design webhook I saw in the field. A foreign guy with a very kind attitude designed a webhook. The focus is not on the db. All the information that needs to be requested external url is in As given in the payload, he will focus on how to handle failures, various retry scenarios, how to scale, how to verify that requests are sent to the correct users, etc. The questions asked are many and complicated.
- Coding is another spreadsheet in the field. It starts very simple. A cell can be an int or a formula (A1 + B1). A simple dfs is enough. Then they ask how to
- optimize faster. Basically, the interviewer wants to see how to target multiple Optimization between requests. The whole process was very tense, and I asked questions one after another.
- No, it means calling getCellValue multiple times. How can we get the value directly without recursively calculating the value each time? The general idea is to use a cache, but it needs to be maintained for each setCellValue, because the set between multiple gets will make the cache The value in is not accurate. There may be other better ways, but the interview time is too tight, so I basically just write whatever comes to mind.
Cell A = new Cell(6, null, null); Cell B = new Cell(7, null, null);
Cell C = new Cell(null, "A", "B");
SpreadSheet spreadsheet = new SpreadSheet();
spreadsheet.setCellValue("A", A);
spreadsheet.setCellVaue("B", B);
spreadsheet.setCellValue("C", C);
spreadsheet.getCellValue(C); // expect 13
spreadsheet.updateCellValue("A", 2);
// update spreadsheet.getCellValue(C);
// expect 9
- Google met for an hour, and I came across the original question. Write a cd() method, input: current directory, relative destination, output: the final path is
- equivalent to cd xxxx in the terminal and then pwd
- Leetcode:
- https://leetcode.com/discuss /int … e-working-directory
- https://leetcode.com/problems/simplify-path/
- was written quickly, and then followed up:
- Second question: Add support for the ~ symbol, that is, user home directory
-
Question 3: Add symbolic link support. Given there is a map of symbolic link path and there respective real path.
- One starts with two minutes of self-introduction, then begins with the questions, and the last five minutes are for you to ask questions.
- The examiner is very nice and will send you a LINK to help you do the questions.
- Someone has already sent you the questions in the store, and you just need to write a form.
- Let me add to this, advertise
- The definition is that each cell can be a number or the sum of the other two cells.
- The interviewer has a ready-made TEST CASE and will ask you to run it after writing it to see if it is correct.
Cell
- Implment Spreadsheet with Cells. The first question is very simple, just use DFS to traverse it.
- The second question allows for more efficient search. At that time, another cache was used to store it, and a parent map was stored at the same time. Later I thought it could be stored directly in Cell.
class Spreadsheet { public int getCellValue(String key) public void setCell(String key, Cell cell) }
System Design
- focus on scalability, how to maintain the data
WebHook design
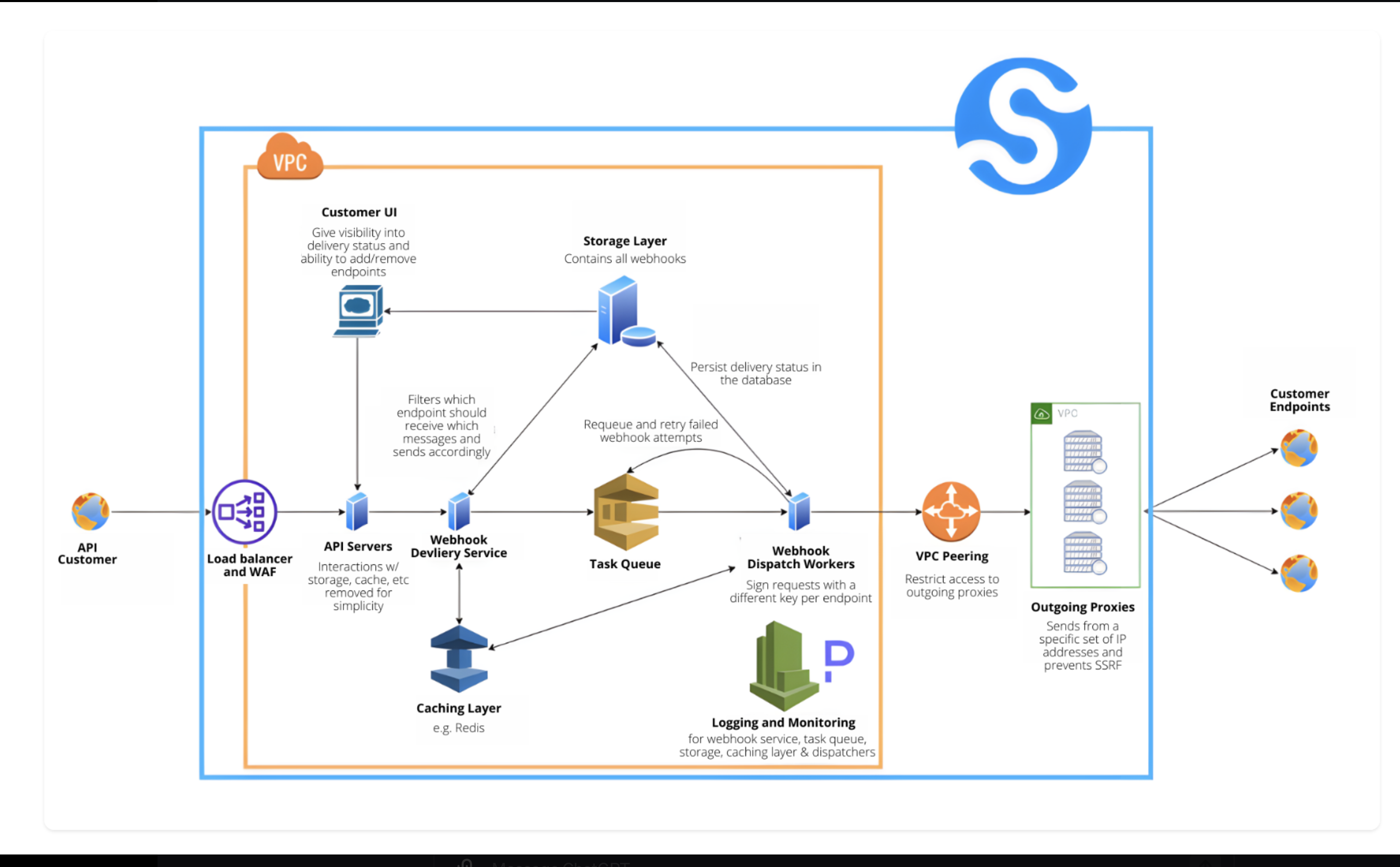
To design a large-scale webhook system based on the architecture provided in the image, we need to establish a comprehensive plan covering functional and non-functional requirements, scale estimation, and the technical details of implementation.
Functional Requirements
- Event Triggering: Ability to detect specific events within the system and trigger webhooks.
- Webhook Registration: Enable clients to register webhooks with custom endpoints.
- Payload Delivery: Deliver data payloads to the registered webhook URLs upon events.
- Delivery Status: Track and persist the status of webhook deliveries.
- Retries: Implement logic to retry failed webhook deliveries.
- Security: Ensure secure delivery of payloads, including signature verification.
Non-Functional Requirements
- Scalability: Must support scaling to handle varying loads.
- Availability: High availability and fault tolerance.
- Performance: Low-latency processing and delivery of webhooks.
- Reliability: Consistent and accurate delivery of webhooks.
- Security: Strong security measures to prevent unauthorized access and data tampering.
Scale Estimation
- Daily Active Users (DAUs): Estimate based on expected client subscriptions.
- Storage: Adequate for storing webhook registrations, payloads, and logs.
- Traffic: Capable of sustaining high traffic, with potential bursts during peak events.
- Latency: Webhook delivery within a few seconds of event detection.
Database Schema
WebhookRegistrations: Storeswebhook_id,client_id,endpoint_url,secret_key,event_types, etc.EventLogs: Recordsevent_id,event_type,timestamp, etc.DeliveryLogs: Tracksdelivery_id,webhook_id,status,attempts,timestamp, etc.
API High-Level Design
POST /register: To register a new webhook.DELETE /webhook/{webhook_id}: To deregister a webhook.GET /delivery/status/{webhook_id}: To check the delivery status of a webhook.
ASCII Architecture Design
Here’s a simplified ASCII version of the architecture:
[ API Customer ] -- [ Load Balancer ] -- [ API Servers ] -- [ Caching Layer ]
| |
| | -- [ Storage Layer ]
| |
[ Webhook Delivery Service ] -- [ Task Queue ] -- [ Dispatch Workers ]
| |
[ Customer Endpoints ] <---------------- [ VPC Peering ] <------------ [ Outgoing Proxies ]
Scaling Considerations
- Load Balancers: Distribute incoming requests evenly across API servers.
- Caching Layer (e.g., Redis): To reduce database load and improve performance.
- Task Queue (e.g., Kafka/RabbitMQ): To manage webhook delivery jobs.
- Dispatch Workers: To asynchronously send webhooks.
- Database Sharding/Replication: For scalability and redundancy.
- Outgoing Proxies: To manage outgoing traffic and enhance security.
End-to-End Process
- Registration: A client registers a webhook via the API, specifying the endpoint and events they are interested in.
- Event Occurs: An event occurs in the system that triggers webhooks.
- Webhook Triggered: The API server detects the event and consults the cache/database for relevant webhook subscriptions.
- Task Queued: The webhook information and payload are queued in the task queue.
- Dispatch: Workers pick up tasks from the queue and send webhook payloads to the client’s endpoints.
- Delivery Tracking: The system logs the delivery status for each webhook attempt. If a delivery fails, it is re-queued for a retry according to the retry logic.
- Security: All outgoing traffic is routed through proxies, which add security layers like signature headers and filter against SSRF.
This design is scalable and robust, ensuring that the webhook system can handle a large number of clients and high volumes of traffic while maintaining performance and reliability.
Overview
- I didn’t pass Onsite, but I’ll come back and briefly talk about my experience and feedback, which will be a blessing to future generations.
- Round 1 System Design
- questions are POI, Yelp or Uber. The HR will tell you the questions when preparing. Don’t doubt it. I’m honest. Prepare well, and get a free
- round 2 Past Project Walk Through
- Prepare a project with the largest scale in the past, and prepare a ppt to explain it. Prepare well. You will generally not fail in home games. You will get a free round
- 3 cross functional behavior
- and The PM talks about how to coordinate the work of multiple roles in a complex environment. There are quite a lot of questions in this round. Be careful. The PM will ask a lot of questions. For example, have you ever put forward product requirements at work? Are there any examples of requests being adopted? Are there any examples of requests being rejected? If you don’t prepare a few more, you will definitely be confused by the questions. Round 4 HM BQ is also very easy to fail. I was stuck in this round and met an Indian manager who was not very easy to talk to. The questions he asked were often convoluted and convoluted, and I said I didn’t quite understand them. There is a question that impressed me. How did you convince the leadership to rewrite the service instead of optimizing the old service? This is a bit difficult for me. My big project was decided by managers and higher-level engineers. I was only responsible for completing it.
- It’s so unprofessional to prepare for so long. You can’t do this if you have money… The
-
second feeling is that the technical difficulty of VO is not that the technical rounds are basically free. On the contrary, the BQ rounds are quite unusual. road. It’s not the common BQ questions. They are looking for leaders, so when preparing for BQ, you must look for examples of lead projects, how to complete projects with multiple groups when the requirements are unclear.
- Internal referral started an intro email. Spoke with the recruiter. Failed at the two-hour tech screen.
- The T/S consists of two sessions: the first was a system design about how to build a site like 大众点评. The topic was one of the many mentioned in an prep email. The questions touched on many of the basics of designing a scalable app. No need to take user feedback into consideration, just how to update restaurant data. I think I did reasonable well. The interviewers were nice, communicative and helpful
- The second was the spreadsheet question others mentioned. Where I failed was I always assumed a tree structure where it should always be a graph. If you are familiar Python, look into the “networkx” package. Implement the basic DFS, then try to improve it with caching, esp how to find outdated downstream nodes once a node is changed.
- The interviewer was nice, encouraging but also somewhat responsible for my failing it. This section was supposed to be in the morning, after the 1st session. But the interviewer was 15 min late and said there was a system wide laptop update. As a result, he couldn’t conduct the interview the
Webhook
- A webhook, not “webshook”, is a method for one system to provide real-time data to another system as soon as an event occurs. It’s essentially a way for systems to communicate asynchronously. Instead of system B regularly checking (polling) system A for changes, system A will just send the data to system B immediately after an event has happened.
How a Webhook Works:
- System A exposes an endpoint (URL) to accept HTTP POST requests. This is the “webhook listener”.
- System B is configured to send POST requests to that endpoint as soon as certain events occur.
- When the specified event occurs in System B, it sends a POST request to System A with the relevant information.
- System A processes the received data.
Basic Design of a Webhook System:
- Endpoint Creation:
- Define an API endpoint in System A where data will be sent. This endpoint should be able to handle POST requests.
- Security:
- Use HTTPS to ensure data is encrypted during transit.
- Consider adding a secret token that System B would send and System A would verify, ensuring the data is coming from a trusted source.
- Payload Design:
- Decide on the data format. JSON is commonly used.
- Include relevant information about the event. For instance, if the event is “new user registration”, the payload might include the user’s name, email, registration time, etc.
- Event Configuration:
- System B should have a way to configure which events should trigger the webhook and where (to which URL) the data should be sent.
- Error Handling:
- If System A fails to process the webhook (e.g., due to a timeout), System B should have a retry mechanism.
- Consider exponential backoff strategies for retries.
- Logging & Monitoring:
- System A should log all incoming webhook data and any processing results or errors.
- Monitor for failed webhook deliveries and notify relevant parties if issues arise.
- Scalability:
- Ensure System A can handle large bursts of incoming webhook data. Consider using a queue (like RabbitMQ, Kafka) to process the data asynchronously.
Usage Scenarios:
- Notification systems: Notifying users or systems of a new event or update.
- Continuous integration/continuous deployment (CI/CD): Triggering a new build or deployment when code is pushed to a repository.
- Payment gateways: Informing a merchant’s system when a new payment has been made or refunded.
- Social media: Informing a system when a new post has been made or a post has been liked, shared, or commented on.
In summary, webhooks provide an efficient way for systems to communicate in real-time, helping to build reactive, dynamic systems.
Yelp
- Understand the problem
- Yelp is a service that leverages a Proximity Server to discover nearby attractions like places, events, locations of restaurants.
- Propose high-level and get buy in
- Functional Requirements:
- Users should be able to add/delete/update Places.
- Given their location (longitude/latitude), users should be able to find all nearby places within a given radius.
- Users should be able to add feedback/review about a place. The feedback can have pictures, text, and a rating.
- Non-functional Requirements:
- Users should have a real-time search experience with minimum latency.
- Our service should support a heavy search load. There will be a lot of search requests compared to adding a new place.
- Highly available during peak spikes
- Scale Estimation
- 100M DAU
- 200 M Business
- 500 Million places
- 100K queries per second
- 20% growth in QPS and locations per year
- Database Schema:
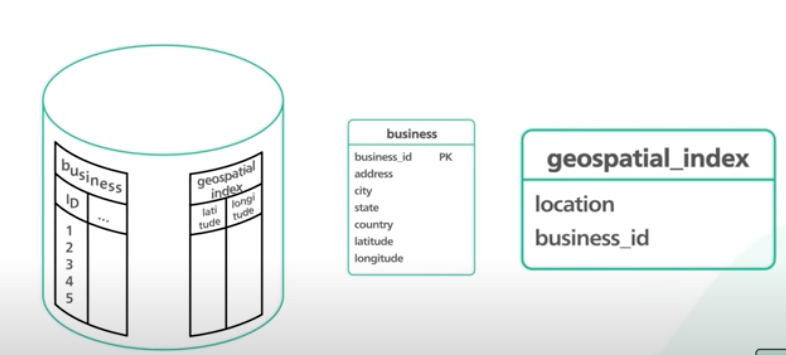
- Location Table
- LocationID (8 bytes): Uniquely identifies a location.
- Name (256 bytes)
- Latitude(8bytes)
- Longitude (8 bytes)
- Description (512 bytes)
- Category (1 byte)
- Reviews for places
- LocationID (8 bytes)
- ReviewID (4 bytes): Uniquely identifies a review, assuming any location will not have more than 2^32 reviews.
- ReviewText (512 bytes)
- Rating (1 byte):
- System APIs
- Location

-
CRUD business

- Data Storage and Indexing Requirements**
- Objective: Store and index datasets (places, reviews, etc.) in a massive database.
- Focus on Read Efficiency: Essential for real-time search results when users query nearby places.
- Data Update Frequency Considerations
- Static Locations: Place locations seldom change, reducing the need for frequent data updates.
- Dynamic Objects: For services tracking frequently moving objects (e.g., people, taxis), a different design approach is required.
- Data Storage Methods and Suitability
- SQL Solution:
- Implementation: Use a database like MySQL. Store each place in a separate row with a unique LocationID, including longitude and latitude in separate columns.
- Indexing: Create indexes on longitude and latitude for faster searches.
- Querying Nearby Places: Utilize a query to find places within a radius ‘D’ from a given location (X, Y).
- Efficiency Concerns: With an estimated 500M places, intersecting lists from separate indexes may not be efficient.
- Grids:
- Implementation: Divide the map into smaller grids, each storing places within specific longitude and latitude ranges.
- Querying Method: Search only relevant grids based on location and radius.
- Grid Identification: Use a four-byte number (GridID) for unique identification.
- Grid Size Determination: Match the grid size to the query distance to minimize the number of grids involved in a search.
- Database Storage: Include GridID in the database and index it for faster searching.
- In-Memory Indexing: Consider storing the index in memory (e.g., hash table) for improved performance.
- Memory Requirements: Estimate the memory needed based on the number of grids and place locations.
- Dynamic Size Grids:
- Objective: Limit the number of places in a grid to 500 for faster searching.
- Method: Break down grids into four smaller grids when they reach the 500-place limit.
- Data Structure: Use a QuadTree, where each node represents a grid and contains information about places in that grid.
- QuadTree Construction: Start with a single node for the entire world and subdivide as needed.
- Grid Identification: Use the QuadTree to locate the grid for a given location and its neighboring grids.
- Memory Requirements: Calculate the memory needed to store the QuadTree and its location data.
- Inserting New Places: Detail the process for adding new places into the database and QuadTree, considering both single-server and distributed scenarios.
- SQL Solution:
- Data Partitioning
- Sharding Based on Regions:
- Approach: Divide places into regions (e.g., zip codes) and store them on fixed nodes based on region.
- Query Process: Query the server holding the user’s location region.
- Challenges:
- High Traffic on Popular Regions: May slow down server performance.
- Uneven Data Distribution: Difficult to maintain uniform distribution as regions grow.
- Recovery Strategies: Repartition data or use consistent hashing for better balance.
- Sharding Based on LocationID:
- Method: Use a hash function to map each LocationID to a server.
- QuadTree Building: Iterate through places, hash each LocationID to determine storage server.
- Querying: All servers respond to a query, with a central server aggregating results.
- QuadTree Structure Variation: Different servers might have different QuadTree structures but will have approximately equal numbers of places.
- Sharding Based on Regions:
- Replication and Fault Tolerance
- Replica Servers: Use master-slave configuration for handling read traffic (slaves) and write traffic (master).
- Handling Server Failures:
- Secondary Replicas: Take over in case of primary server failure.
- Rebuilding Lost Servers: Use a brute-force method or a reverse index for efficient rebuilding of QuadTree servers.
- Reverse Index Solution:
- Implementation: A separate QuadTree Index server mapping Places to their respective QuadTree server.
- Efficiency: Fast rebuilding of servers using the QuadTree Index server.
- Fault Tolerance: Replicas of the QuadTree Index server for backup.
- Cache
- Solution: Implement a cache (e.g., Memcache) for hot places.
- Operation: Application servers check cache before querying the backend database.
- Cache Management: Use Least Recently Used (LRU) policy for cache eviction.
- Load Balancing (LB)
- Placement: Between clients and application servers, and between application servers and backend server.
- Initial Strategy: Start with a Round Robin approach for equal distribution of requests.
- Advanced Considerations: Intelligent LB solutions that adjust traffic based on server load.
- Ranking
- Popularity Tracking: Store a popularity score for each place in both database and QuadTree.
- Querying for Popularity: Request top places based on popularity from each partition of the QuadTree.
- Popularity Updates: Limit frequency of updates to manage resources and system throughput.
- Functional Requirements:
- Design deep-dive
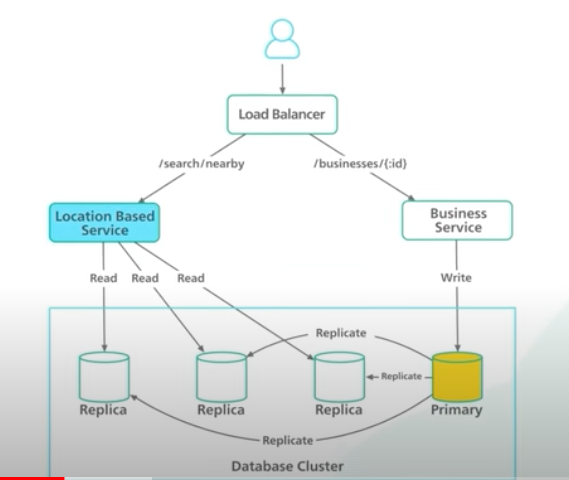
- Database options, Hash vs Tree
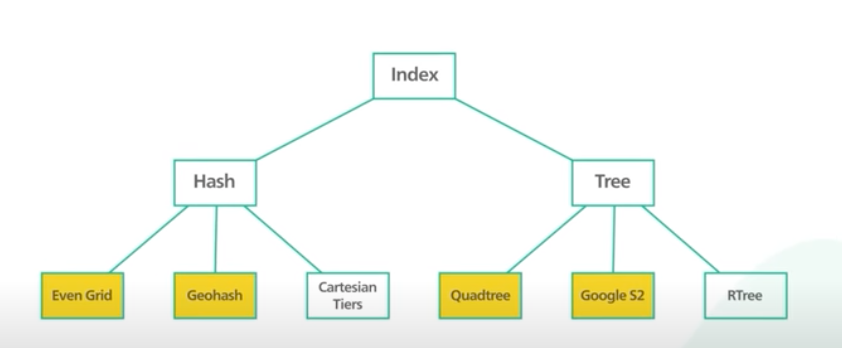
- Both divide the map into small areas and build indexes for search
- Hash based approach divides map into grids and each location is associated with a grid. Can’t be evenly divided because some areas have dense business populations vs others. Geohash helps solve this problem by diving the world into 4 quadrants. Then divides each grid into 4 smaller grids. Repeats until subgrid = desired size.
-
Tree based index: QuadTree and google S2. The common tree-based indices are quadtree and Google s2. A quadtree is a data structure that partitions a two-dimensional space by recursively subdividing it into 4 quadrants. The subdivision stops when the grids meet certain criteria. In our use case, the criterion can be to keep subdividing until the number of business in the grid are no more than some number. Its an in-memory data structure not a database solution. We will use geohash.
-
Scalability and data updating are critical aspects of the architecture for a Yelp-like service. Let’s break down how each would be approached in the proposed system:
- Scalability
- Horizontal Scaling:
- Sharding: Distribute data across multiple servers (shards) based on a sharding key like LocationID. This approach helps manage load and facilitates adding more servers as the data grows.
- Load Balancing: Implement advanced load balancers that can distribute user requests across various application servers based on current load and server performance.
- Vertical Scaling:
- Hardware Upgrades: Improve the capabilities of existing servers by increasing CPU, RAM, or storage. This is typically less favored due to its limits and higher costs.
- Microservices Architecture:
- Decoupling Services: Break down the application into smaller, independent microservices (e.g., user management, reviews, search). This allows for scaling individual components as needed without affecting the entire system.
- Caching:
- High-Traffic Data: Use caching mechanisms for frequently accessed data, reducing the load on the databases and improving response times.
- Content Delivery Network (CDN):
- Static Content: Serve static content like images and scripts from CDNs to reduce the load on the main servers and improve user experience globally.
- Updating Data for New Locations
- Real-Time Data Ingestion:
- APIs for New Entries: Develop APIs to allow adding new places and reviews in real-time. This could include integration with external sources or direct user inputs.
- Database Updates:
- Immediate Storage: Store new location data immediately in the SQL/NoSQL databases.
- Indexing: Update search indexes like Elasticsearch/Solr to reflect new data, ensuring it appears in search results promptly.
- QuadTree Updates:
- Dynamic Adjustment: Modify the QuadTree structure when new places are added, especially in dense areas, to maintain efficient search capabilities.
- Batch Processing:
- Periodic Updates: For non-critical data updates, use batch processing during off-peak hours to reduce the load on the system.
- Replication and Consistency:
- Data Replication: Ensure new data is replicated across all necessary servers to maintain consistency and availability.
- Eventual Consistency Model: Adopt an eventual consistency approach for data updates across distributed systems, especially in a sharded environment.
- Monitoring and Alerts:
- System Monitoring: Implement robust monitoring for the data ingestion and updating process to quickly identify and address any issues.
- Wrap up
Uber
- Understand the Problem
- Uber, a prominent ride-sharing service, connects passengers with drivers through a smartphone app. This system necessitates real-time communication and location updates between drivers and customers. Key challenges include handling frequent location updates from drivers, efficiently matching drivers with passengers, and ensuring real-time updates to both parties during a ride.
- Propose High-Level and Get Buy-In
- The proposed high-level design involves adapting the QuadTree structure from the Yelp system to accommodate the dynamic nature of Uber’s use case. Key elements include:
- Real-Time Location Tracking: Implementing a hash table (DriverLocationHT) to store and frequently update driver locations.
- Efficient Driver-Passenger Matching: Using QuadTree for spatial indexing to quickly find nearby drivers.
- Broadcasting Location Updates: A push-based notification service to update customers about driver locations.
- Capacity Estimation: Considering the sheer volume of users and rides, with a focus on handling massive concurrent location updates and ride requests.
- Design Deep-Dive
- The deep dive into the design involves addressing specific challenges:
- Handling Frequent Location Updates: Instead of constantly updating the QuadTree, we temporarily store the latest driver locations in DriverLocationHT, updating the QuadTree at less frequent intervals (every 15 seconds).
- Memory and Bandwidth Analysis: Calculating the memory requirements for DriverLocationHT and the bandwidth needed for receiving location updates.
- Scalability and Fault Tolerance: Distributing DriverLocationHT across multiple servers based on DriverID and implementing replication for resilience.
- Notification Service: Exploring options like HTTP long polling or push notifications for broadcasting driver locations to customers.
- Efficient Ride Request Handling: Detailing the process of ride requests, driver notifications, and matching algorithms.
- Ranking Drivers: Integrating driver ratings into the search and match process.
- Wrap Up In conclusion, the design for Uber’s backend must efficiently handle real-time location updates, scalable driver-passenger matching, and robust fault tolerance. The proposed solution builds on existing spatial indexing techniques, supplemented with real-time data handling and push notification mechanisms. It also considers the requirements of bandwidth, memory, and scalability to support Uber’s high user and ride volumes. Advanced issues like client network variability and billing for disconnected rides also need consideration.
Webhook: Design and Implementation
- Understand the Problem
- A webhook is a method of augmenting or altering the behavior of a web page or web application with custom callbacks. These callbacks may be maintained, modified, and managed by third-party users and developers who do not necessarily have access to the source code of the web application. The core challenges of designing a webhook system include ensuring secure data transfer, managing high-volume requests, and providing reliable and timely delivery of notifications or data payloads to specified URLs.
- Propose High-Level and Get Buy-In
- The high-level proposal for a webhook system involves:
- Event-Driven Architecture: The system triggers events based on specified actions within the source application.
- Endpoint Configuration: Users can specify endpoints (URLs) where the webhook payloads will be sent.
- Secure Data Transmission: Implementing secure methods (like HTTPS) for data transmission to protect sensitive information.
- Scalability and Reliability: Ensuring the system can handle high volumes of requests and provide reliable delivery.
- User Customization: Allowing users to define events and payload structure.
- Design Deep-Dive
- A detailed design of the webhook system would include:
- Event Listener: A component that monitors specified events within the application.
- Payload Assembly: Upon event detection, the system assembles a data payload relevant to the event.
- HTTP Client Implementation: To send the payload to the user-specified endpoint. This includes handling HTTP methods, authentication, and retries.
- Security Measures: Implementing signature-based verification for payloads and ensuring all communications are encrypted.
- Load Handling and Scaling: Using techniques like queueing and rate limiting to manage high volumes of outgoing webhook calls.
- Failure Handling: Implementing retry mechanisms and logging for failed delivery attempts.
- User Interface: A dashboard or interface for users to configure and manage webhooks, including setting endpoints, defining events, and viewing logs.
- Wrap Up
- In wrapping up, the webhook system design should emphasize secure, efficient, and reliable communication between the application and the user-specified endpoints. It should be scalable to handle varying loads and provide users with sufficient control and visibility over their webhooks. The final design should also consider ease of integration and use, ensuring it can seamlessly augment the application’s capabilities without significant modifications to its core architecture.