AutoComplete Search
- Overview
- Step 1: Understand the problem and establish design scope
- Back of the envelope estimation
- Step 2 Propose high-level design and get buy-in
- Step 3 Design deep dive
- Step 4 - Wrap up:
Overview
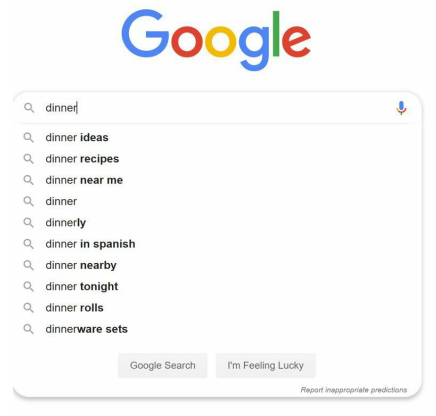
- Search autocomplete, also known as typeahead, search-as-you-type, or incremental search, is a feature that provides suggestions or completions as users type in a search box.
- Examples of search autocomplete can be seen on platforms like Google and Amazon, where relevant search suggestions are presented to users.
- Designing a search autocomplete system, also referred to as “design top k” or “design top k most searched queries,” is a common interview question.
- The goal is to create a system that efficiently generates and presents a list of autocomplete suggestions based on user input.
- The system should consider factors such as search query frequency, relevance, and responsiveness.
- Techniques such as prefix matching, trie data structures, caching, and ranking algorithms are often employed in designing search autocomplete systems.
- The system should handle large datasets and be scalable to accommodate high traffic and frequent updates to search data.
- Other considerations include optimizing storage and retrieval, handling misspellings, and incorporating user feedback to improve the autocomplete suggestions.
- The interview question provides an opportunity to discuss various aspects of system design, algorithms, data structures, and performance optimization.
Step 1: Understand the problem and establish design scope
To effectively approach a system design interview question, it is crucial to seek clarification through relevant questions. Here is an example of candidate-interviewer interaction:
-
Candidate: Is the matching only supported at the beginning of a search query or in the middle as well? Interviewer: Only at the beginning of a search query.
-
Candidate: How many autocomplete suggestions should the system return? Interviewer: 5
-
Candidate: How does the system know which 5 suggestions to return? Interviewer: This is determined by popularity, decided by the historical query frequency.
-
Candidate: Does the system support spell check? Interviewer: No, spell check or autocorrect is not supported.
-
Candidate: Are search queries in English? Interviewer: Yes. If time allows at the end, we can discuss multi-language support.
-
Candidate: Do we allow capitalization and special characters? Interviewer: No, we assume all search queries have lowercase alphabetic characters.
Summary of Requirements:
-
Fast response time: Autocomplete suggestions must appear quickly as users type their search queries, ideally within 100 milliseconds to prevent stuttering.
-
Relevant: Autocomplete suggestions should be pertinent to the search term.
-
Sorted: Results returned by the system must be sorted by popularity or other ranking models.
-
Scalable: The system should handle high traffic volume efficiently.
-
Highly available: The system must remain accessible even if parts of it go offline, slow down, or encounter unexpected network errors.
Back of the envelope estimation
• Assume 10 million daily active users (DAU). • An average person performs 10 searches per day. • 20 bytes of data per query string: • Assume we use ASCII character encoding. 1 character = 1 byte • Assume a query contains 4 words, and each word contains 5 characters on average. • That is 4 x 5 = 20 bytes per query. • For every character entered into the search box, a client sends a request to the backend for autocomplete suggestions. On average, 20 requests are sent for each search query. For example, the following 6 requests are sent to the backend by the time you finish typing “dinner”. search?q=d search?q=di search?q=din search?q=dinn search?q=dinne search?q=dinner • ~24,000 query per second (QPS) = 10,000,000 users * 10 queries / day * 20 characters / 24 hours / 3600 seconds. • Peak QPS = QPS * 2 = ~48,000 • Assume 20% of the daily queries are new. 10 million * 10 queries / day * 20 byte per query * 20% = 0.4 GB. This means 0.4GB of new data is added to storage daily
Step 2 Propose high-level design and get buy-in
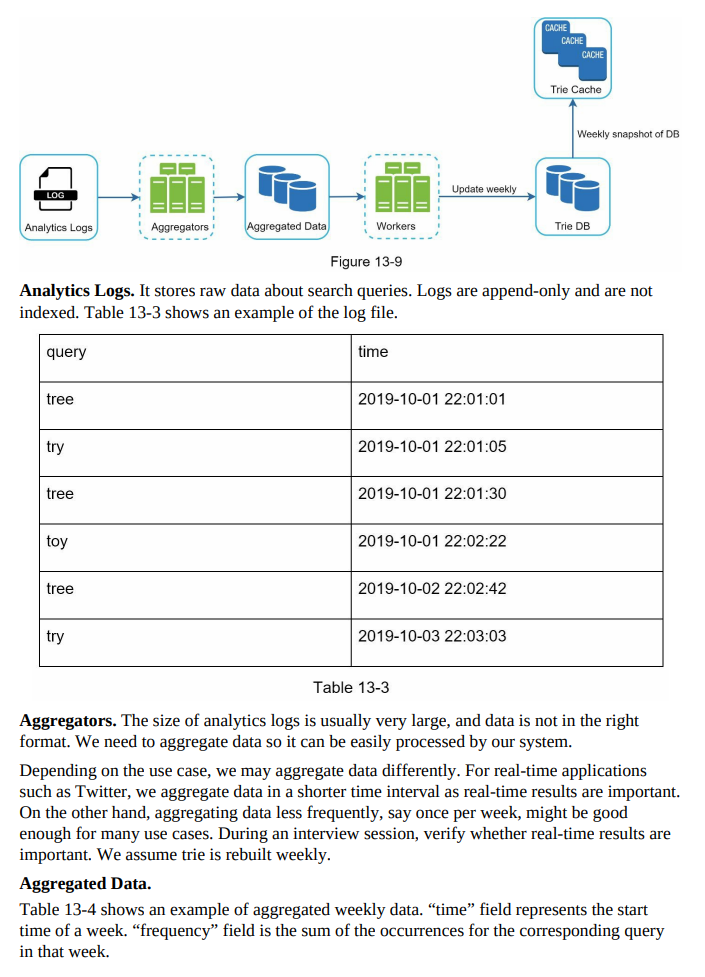
- Data gathering service:
- It gathers user input queries and aggregates them in real-time.
- Real-time processing is not practical for large data sets, but it serves as a starting point.
- A more realistic solution will be explored in the deep dive.
- Query service:
- Given a search query or prefix, it returns the 5 most frequently searched terms.
- Data gathering service example:
- Assume a frequency table stores query strings and their frequencies.
- Initially, the frequency table is empty.
- As users enter queries (e.g., “twitch,” “twitter,” “twitter,” “twillo”), the frequency table is updated accordingly.
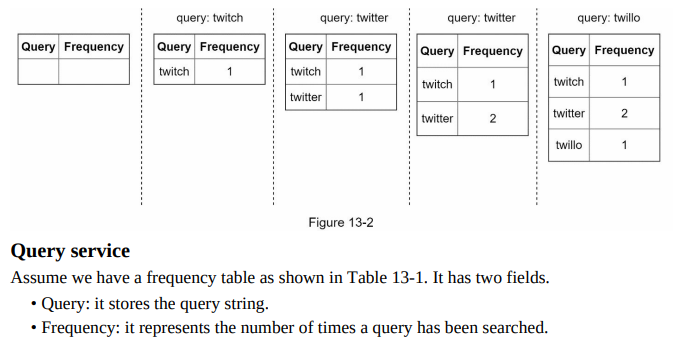

- This is an acceptable solution when the data set is small. When it is large, accessing the database becomes a bottleneck. We will explore optimizations in deep dive.
Step 3 Design deep dive
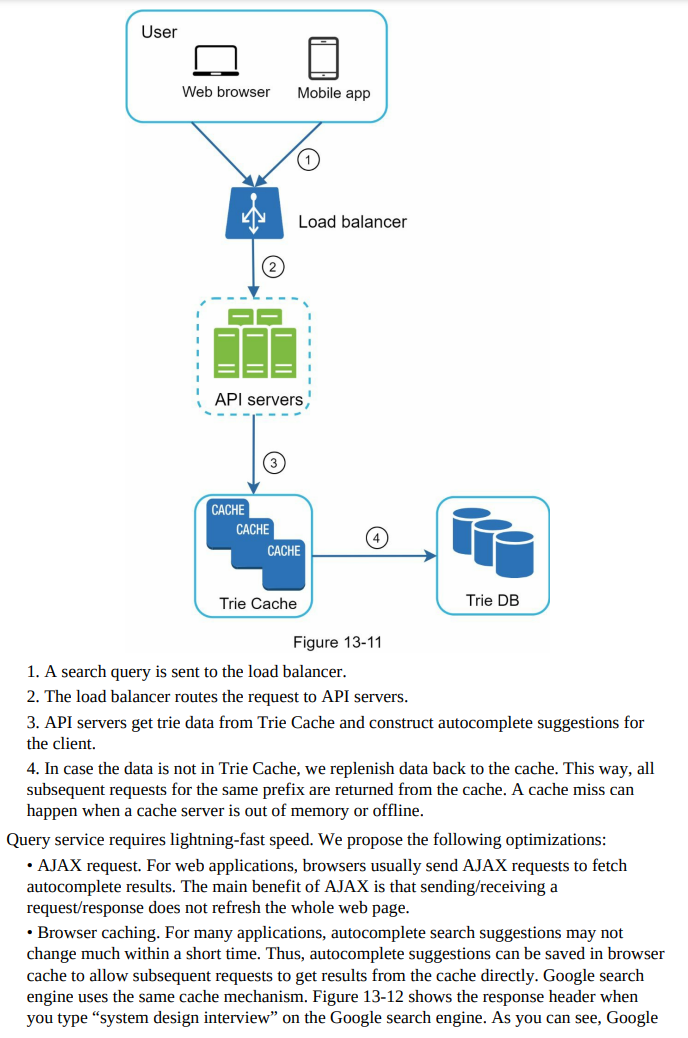
- In the high-level design, we discussed the data gathering service and query service as a starting point.
- In this section, we will dive deep into the following components and explore optimizations:
- Trie data structure
- Data gathering service
- Query service
- Scaling the storage
- Trie operations
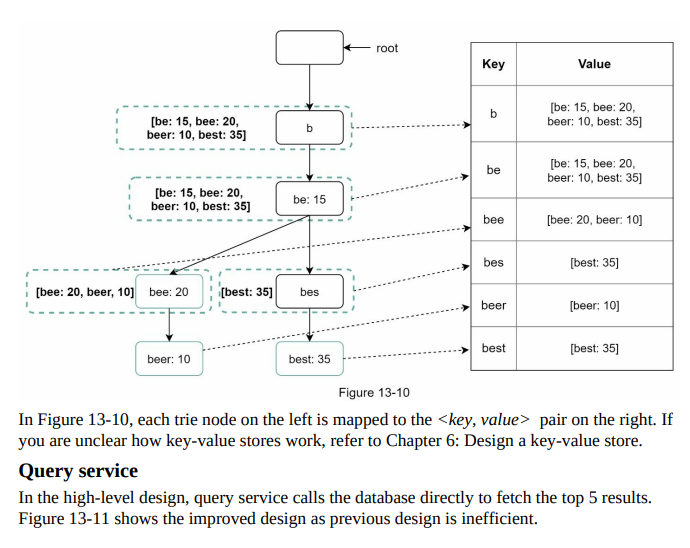
- Trie data structure:
- Relational databases are inefficient for fetching the top 5 search queries.
- The trie (prefix tree) data structure is used to overcome this problem.
- We will design a customized trie to improve response time.
- Understanding the basic trie data structure is essential, and we will focus on optimization.
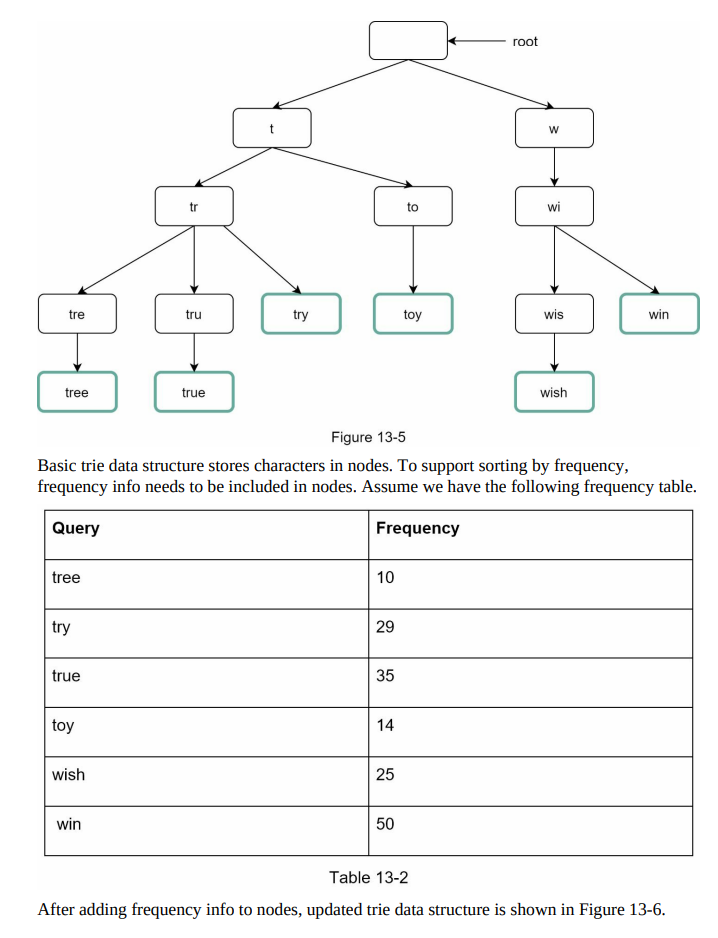
- Basic Trie Overview:
- Trie is a tree-like data structure designed for string retrieval operations.
- Each node represents a character and has 26 children, one for each possible character.
- Each tree node represents a single word or a prefix string.
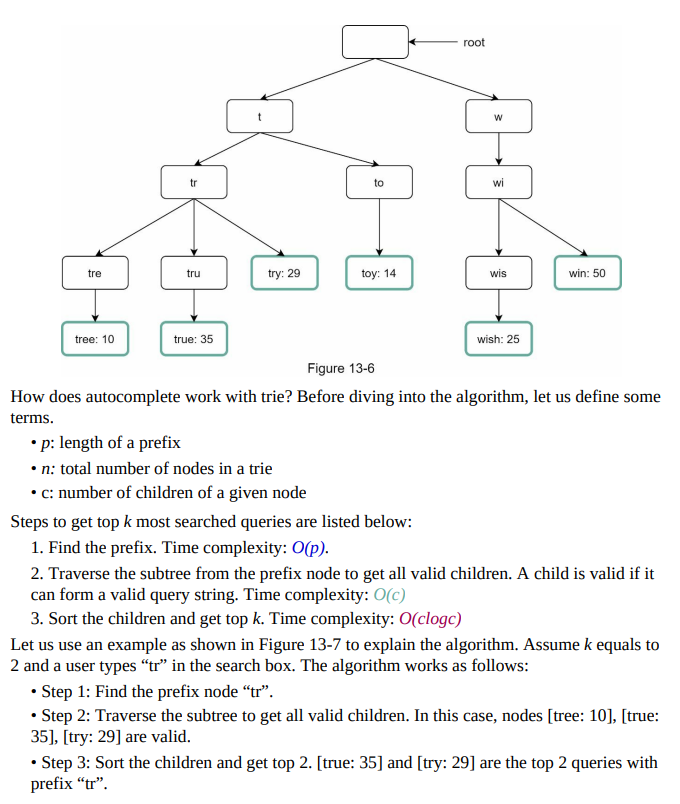
- Figure 13-5 shows an example trie with highlighted search queries “tree,” “try,” “true,” “toy,” “wish,” “win.”
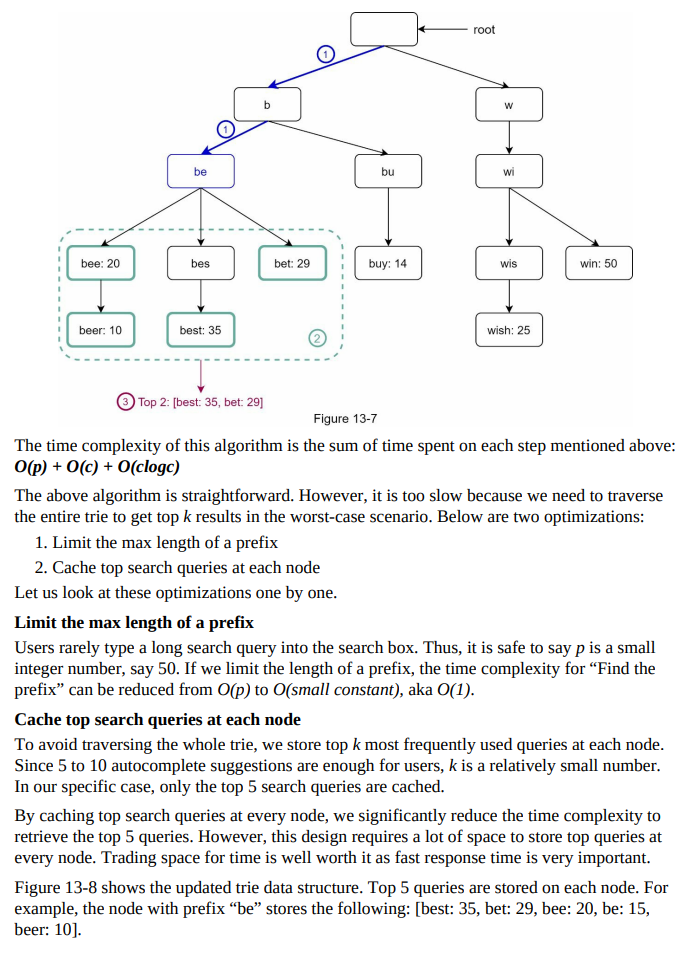
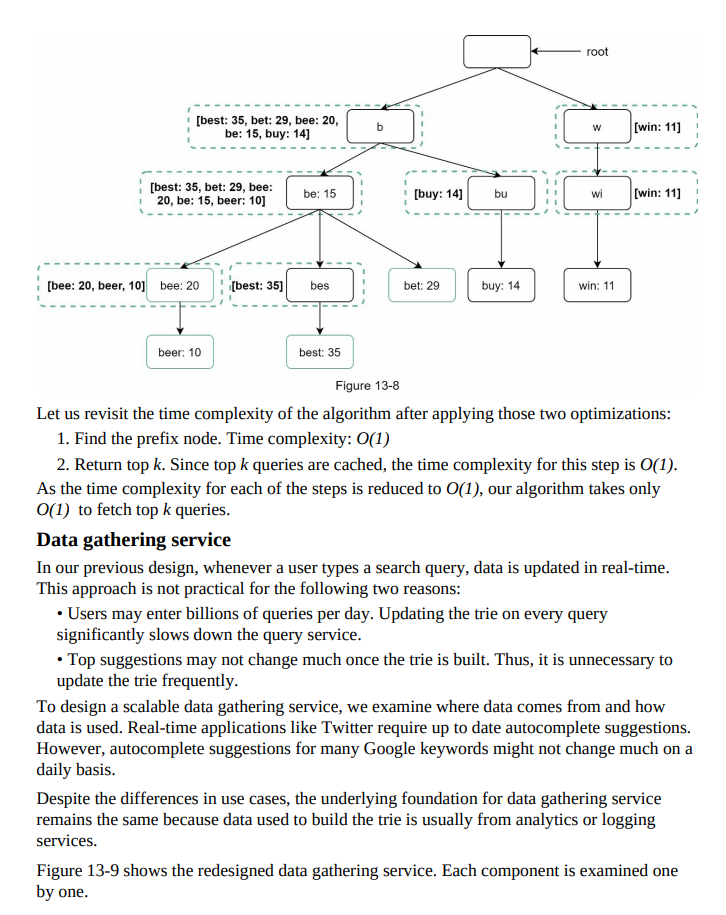
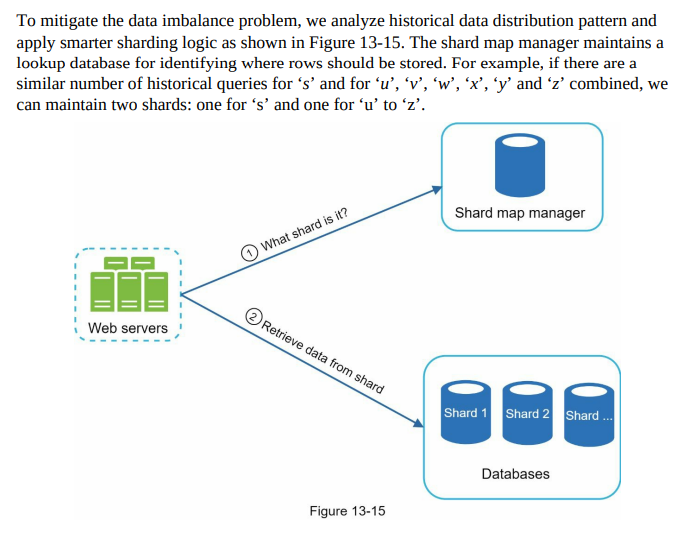
Step 4 - Wrap up:
- After completing the deep dive, your interviewer may ask follow-up questions.
- Interviewer: How do you extend the design to support multiple languages?
- To support non-English queries, Unicode characters are stored in trie nodes.
- Interviewer: What if top search queries differ between countries?
- Different tries can be built for different countries, and CDNs can store tries to improve response time.
- Interviewer: How can we support trending (real-time) search queries?
- The original design is not suitable due to offline workers and time-consuming trie building.
- Suggestions for building a real-time search autocomplete system:
- Reduce working data set by sharding.
- Modify the ranking model to give more weight to recent search queries.
- Stream processing with tools like Apache Hadoop MapReduce, Apache Spark Streaming, Apache Storm, Apache Kafka, etc.
- Detailed discussion on these topics is beyond the scope of this book due to specific domain knowledge required.