Infrastructure • Apache Glue
- Overview
- Use case
- Glue Data catalog
- AWS Glue Job ETL
- AWS Glue Triggers
- Testing AWS Glue Jobs Locally
Overview
- AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it simple for customers to prepare and load their data for analytics.
- You can create and run an ETL job with a few clicks in the AWS Management Console. AWS Glue discovers your data and stores the associated metadata (e.g., table definition and schema) in the AWS Glue Data Catalog.
-
Once cataloged, your data is immediately searchable, queryable, and available for ETL.
- The image below (source), shows how the AWS Glue environment works.
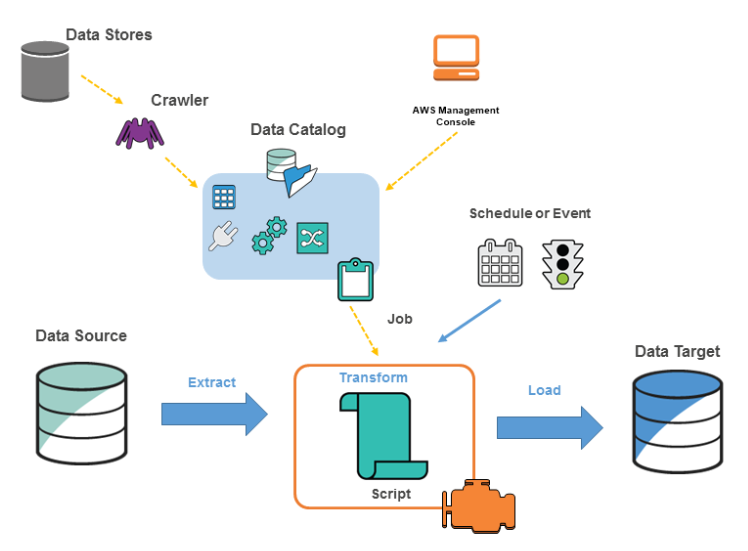
Use case
Start -> Access AWS Management Console -> Create an S3 Bucket
-> Navigate to the S3 service
-> Click on "Create bucket"
-> Provide bucket name, region, and settings
-> Click "Create bucket"
-> Create an IAM Role
-> Navigate to IAM service
-> Click on "Roles" in the left-hand menu
-> Click "Create role"
-> Select "AWS service" as trusted entity
-> Choose "Glue" as the service
-> Click "Next: Permissions"
-> Attach policies (e.g., AmazonS3FullAccess)
-> Click "Next: Tags"
-> Click "Next: Review"
-> Name and create the role
-> Create a Glue Crawler
-> Navigate to the Glue console
-> Click on "Crawlers" in the left-hand menu
-> Click "Add crawler"
-> Enter crawler name and click "Next"
-> Select data store (e.g., S3)
-> Specify the S3 path to data
-> Select IAM role
-> Set output configuration
-> Set crawler schedule
-> Review and create the crawler
-> Run the crawler
-> Query data using Amazon Athena
-> Navigate to Athena console
-> Choose database created by crawler
-> Write SQL queries to explore data
End
Glue Data catalog
- The AWS Glue Data Catalog functions as a persistent metadata repository. It acts as a central hub for storing, annotating, and sharing structural and operational metadata for a wide array of data.
-
Each AWS region maintains its own Glue Data Catalog, ensuring integration across a broad range of AWS services to enhance data discovery, querying, and transformation capabilities.
-
In the Glue console below (source), the Data Catalog is located on the left side of the interface, alongside the areas dedicated to ETL (Extract, Transform, Load) jobs.
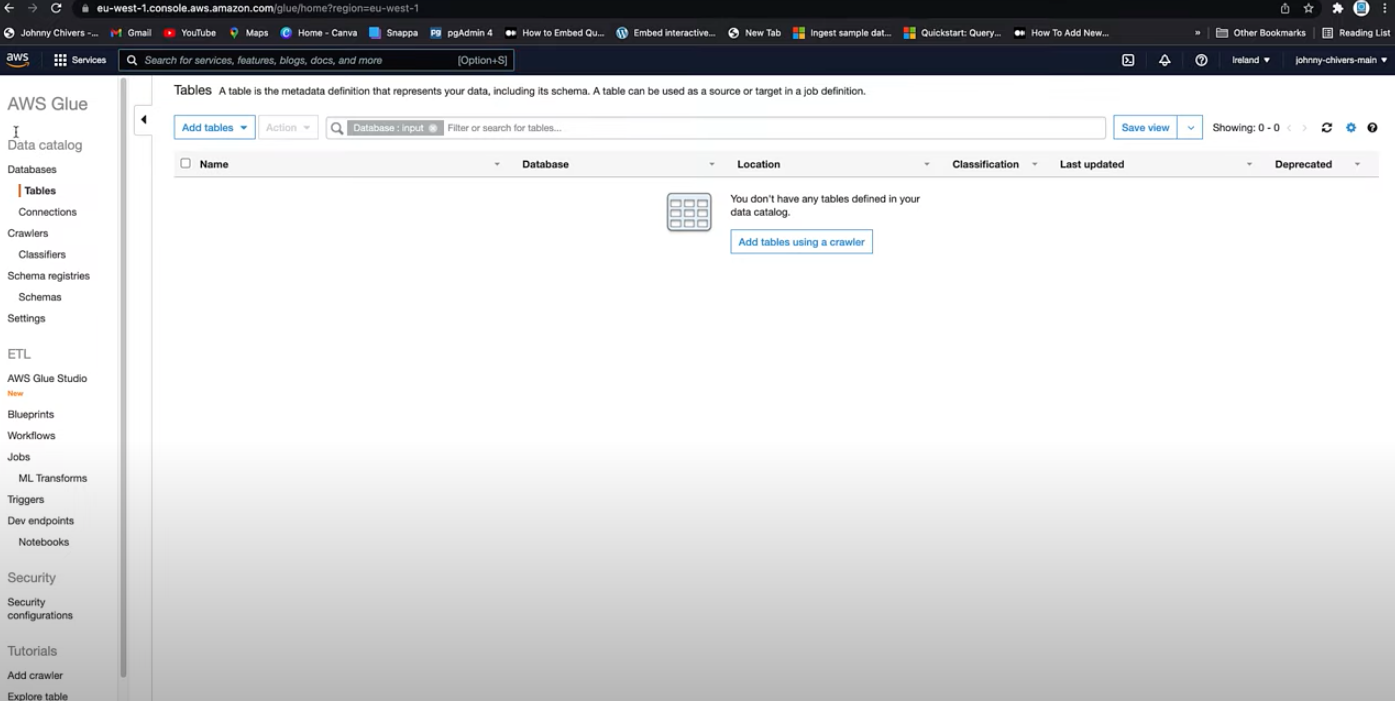
- Schema Registries within AWS Glue are designed for managing and governing schemas associated with real-time data streams. These registries help maintain consistency in data format and ensure compatibility across various data-consuming applications.
- Example Usage: If an organization streams data from IoT devices to AWS for real-time analytics, the Schema Registry can be used to define and enforce the structure of incoming data. This ensures all data adheres to a predefined schema, facilitating reliable real-time analysis and decision-making.
AWS Glue Database
- An AWS Glue Database is a collection of associated data catalog table definitions, which helps in organizing tables into logical groups for better data management and accessibility.
- To facilitate smoother integration and operations within Apache Spark environments, it is required that table names in Glue Database use underscores.
- The database allows for the specification of a physical storage location, typically provided as an S3 URI link. This location directs where the actual data files are stored.
- Additionally, users can add descriptions to each database, enhancing the clarity and understandability of the data’s purpose and structure. This feature is particularly useful for maintaining clear documentation and aiding in data governance practices.
AWS Glue Tables
- AWS Glue Tables serve as metadata definitions that represent your data, essentially providing a structured schema form of the data that resides externally.
- The physical data remains stored in its original location, such as an S3 bucket. The role of AWS Glue Tables is to encapsulate this data in schema format, bringing only the schema information into the Glue Data Catalog.
- This design allows users to manage and query their data schema without altering the actual data’s storage and location, enabling efficient data handling and operations within the AWS ecosystem.
AWS Glue Crawler
- AWS Glue Crawlers are used to automate the process of creating table definitions in the Glue Data Catalog. Below are the steps to add a table using a crawler, as illustrated in the images:
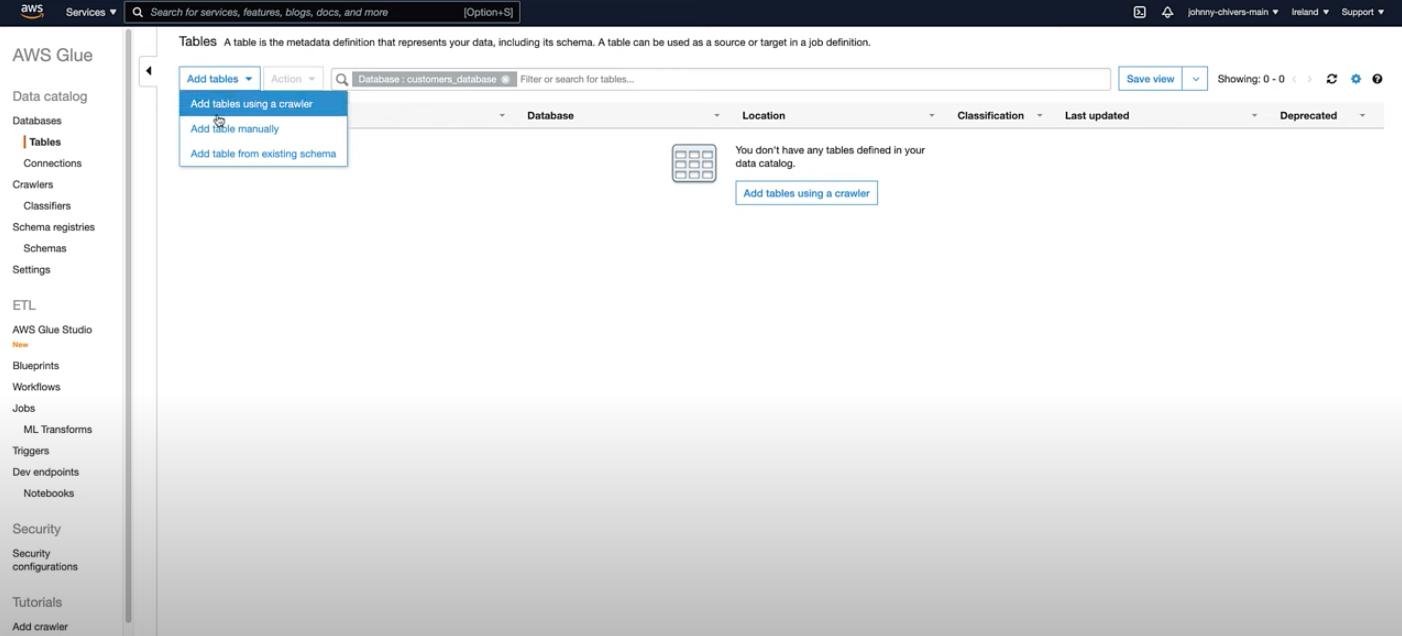
- Here are the steps 1) Create and Name the Crawler: Start by adding a new crawler and naming it appropriately to reflect its function or the data it will process
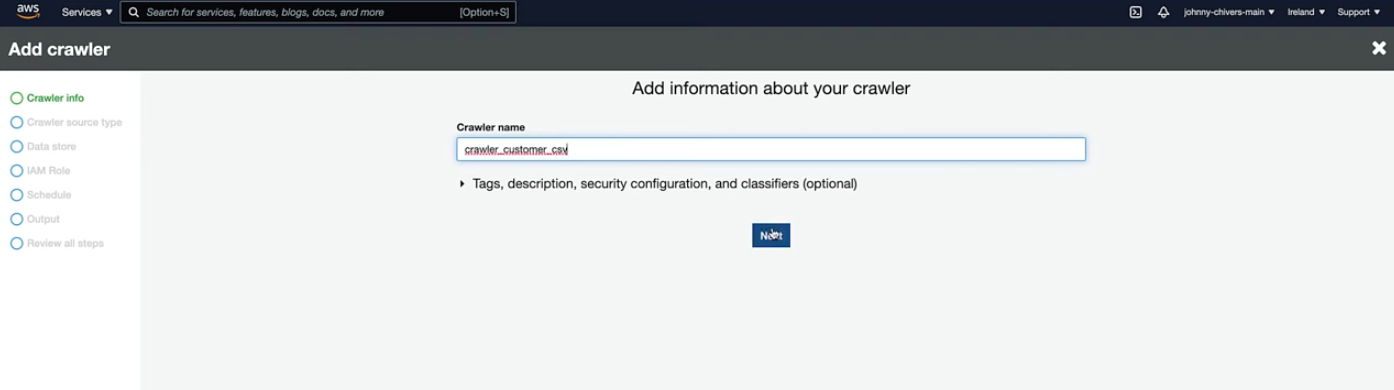
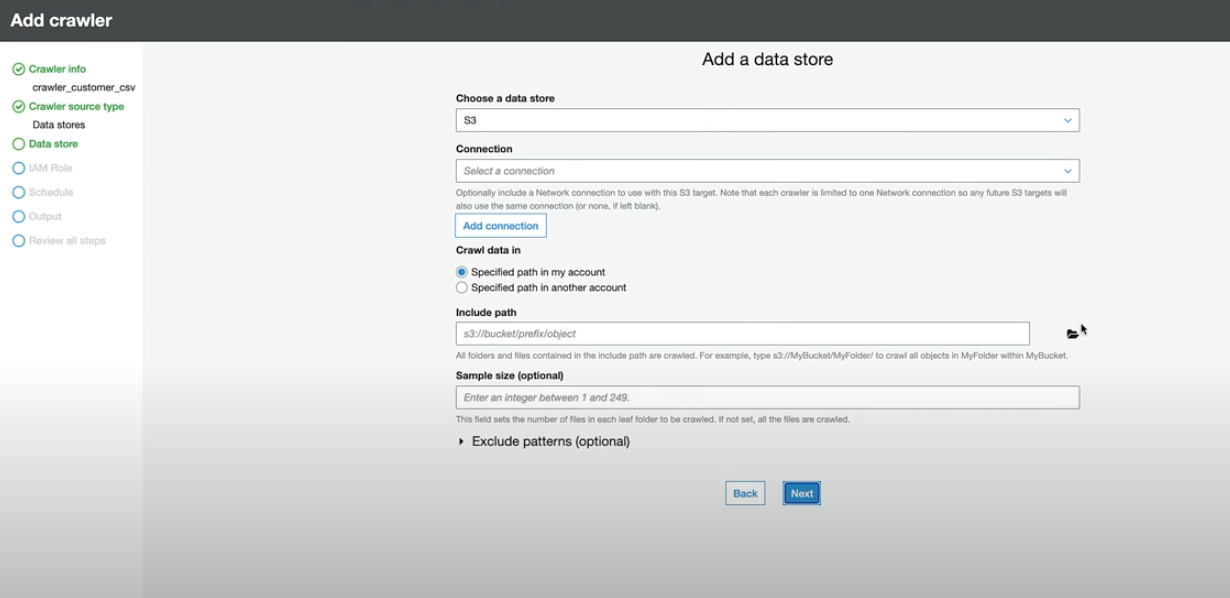
2) Assign an IAM Role: Assign an IAM role to the crawler that has the necessary permissions to access the data sources and populate the Data Catalog.
3) Run the Crawler: Once configured, run the crawler to scan the data source and create metadata entries in the Data Catalog.
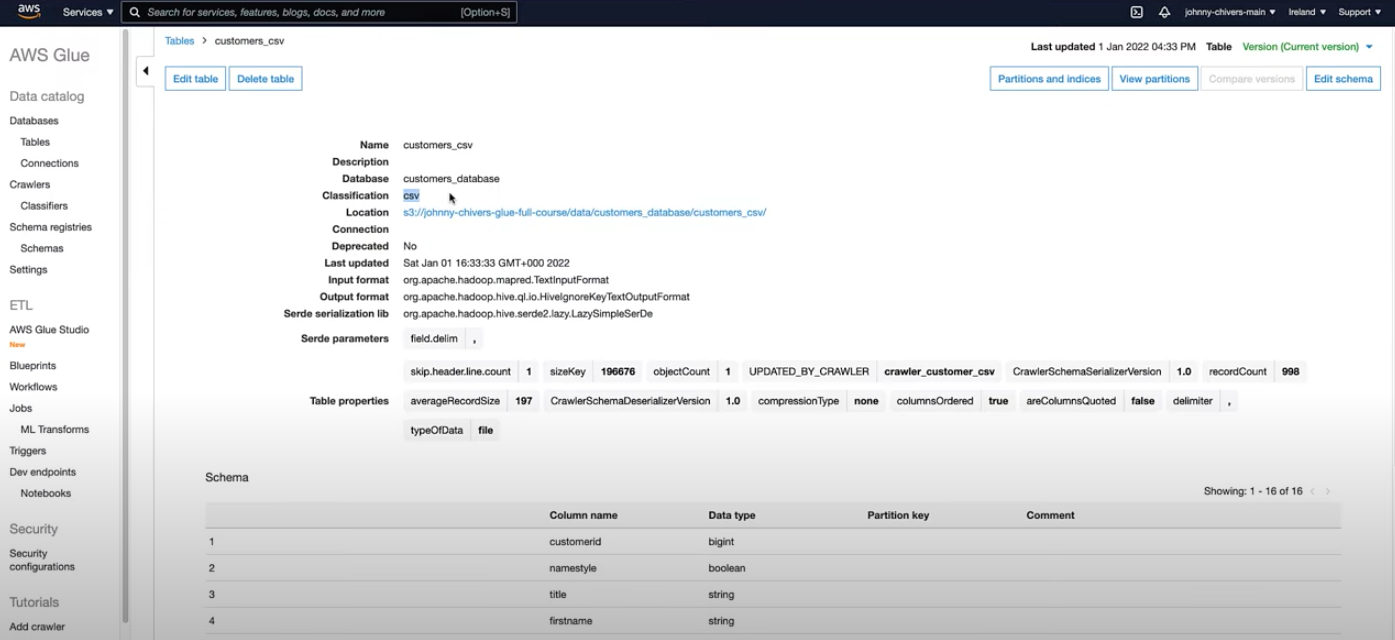
- Handling Columns and Partitions
- The crawler automatically processes and names columns, which are typically kept in lowercase to ensure compatibility with the Apache Spark engine.
- Partitions can be defined in the table structure to improve query performance and data management. Partitions allow you to divide a table into segments, each corresponding to a particular value of one or more columns. This is especially useful for large datasets where operations on smaller subsets of data are common.
- Querying the Data:
- Once the metadata is available in the Glue Data Catalog, you can perform queries on your data using Amazon Athena with SQL syntax or directly on the data stored in S3. This flexibility allows for efficient data analysis and manipulation directly in the cloud.
AWS Glue Job ETL
- AWS Glue ETL (Extract, Transform, Load) jobs are central to data transformation processes within the AWS ecosystem. Here’s a detailed breakdown of how to set up and run an ETL job in AWS Glue:
Key Components
- Transformation Script: The script that contains the logic for data transformation.
- Data Sources: Origins from where data is extracted.
- Data Targets: Destinations where the transformed data is loaded.
- Triggers: Mechanisms that initiate job runs, which can be scheduled or event-triggered.
Setting Up an ETL Job
- Job Configuration:
- Begin by navigating to the ETL jobs tab in the AWS Glue console to add a new job.
- Begin by navigating to the ETL jobs tab in the AWS Glue console to add a new job.
- Add a New Job:
- Proceed to add the job details, including the job name and roles.
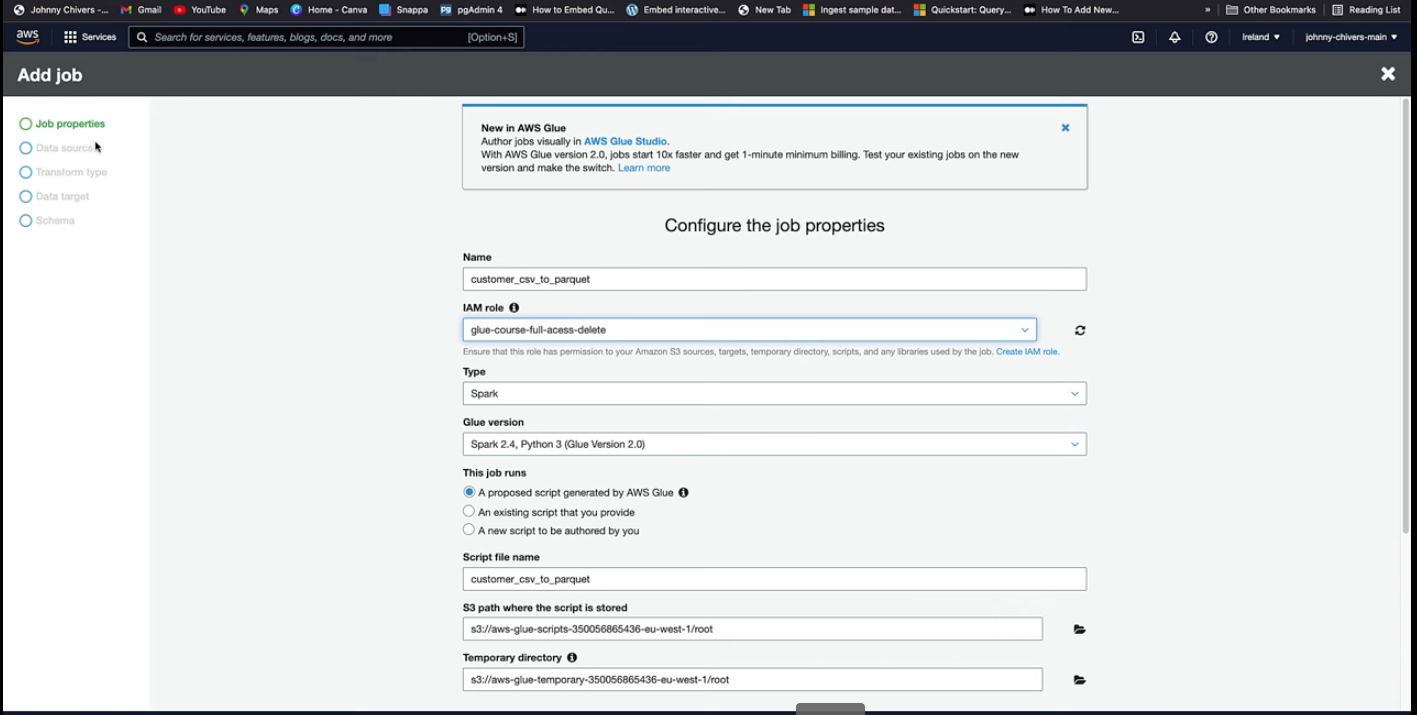
- Proceed to add the job details, including the job name and roles.
- Specify Data Source:
- Choose the data source from which the data will be extracted.
- Set Data Target:
- Define a target for the data, such as a new table in an S3 bucket.
Job Execution and Output
- After configuring the job, you can execute it by clicking ‘Run Job’.
- Navigate to the jobs page to monitor the job’s progress.
- Upon completion, the job outputs the transformed data into the specified S3 bucket.
- Below are examples of the job output and the transformation process:
- Job Output: Illustrates the results stored in S3.
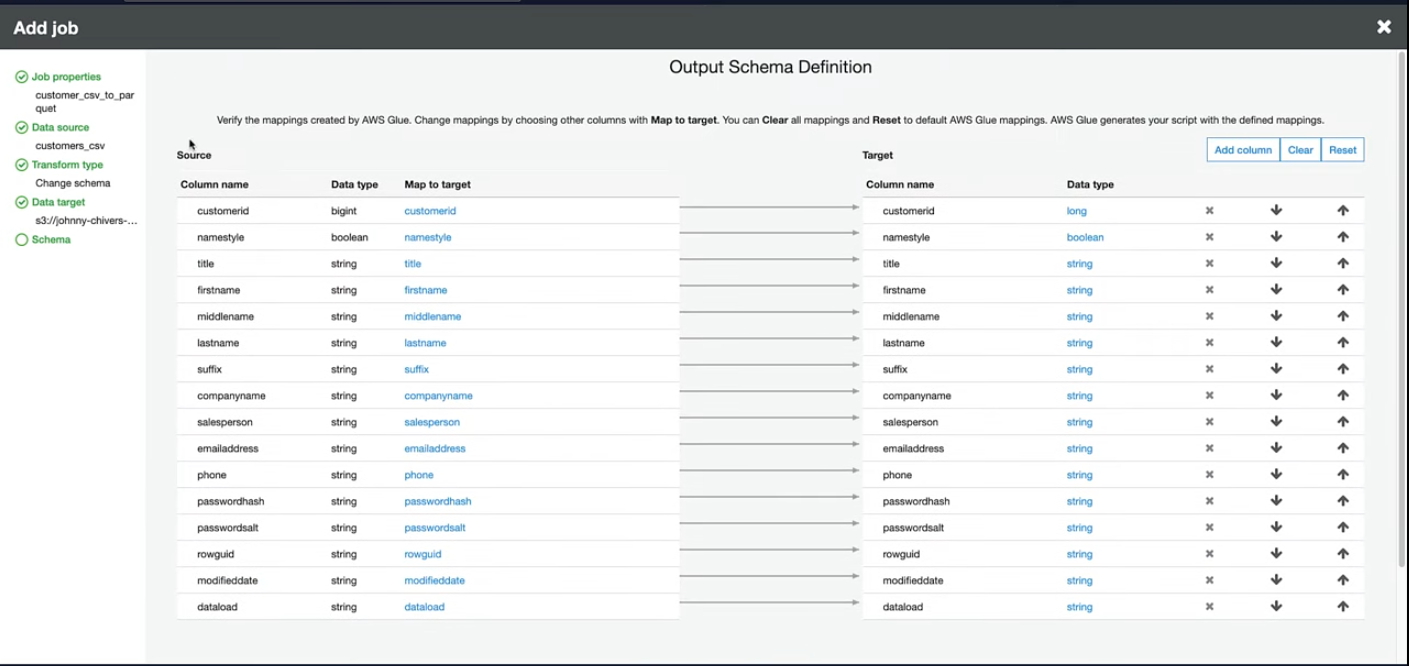
- Data Transformation: Shows the transformation applied to the data.
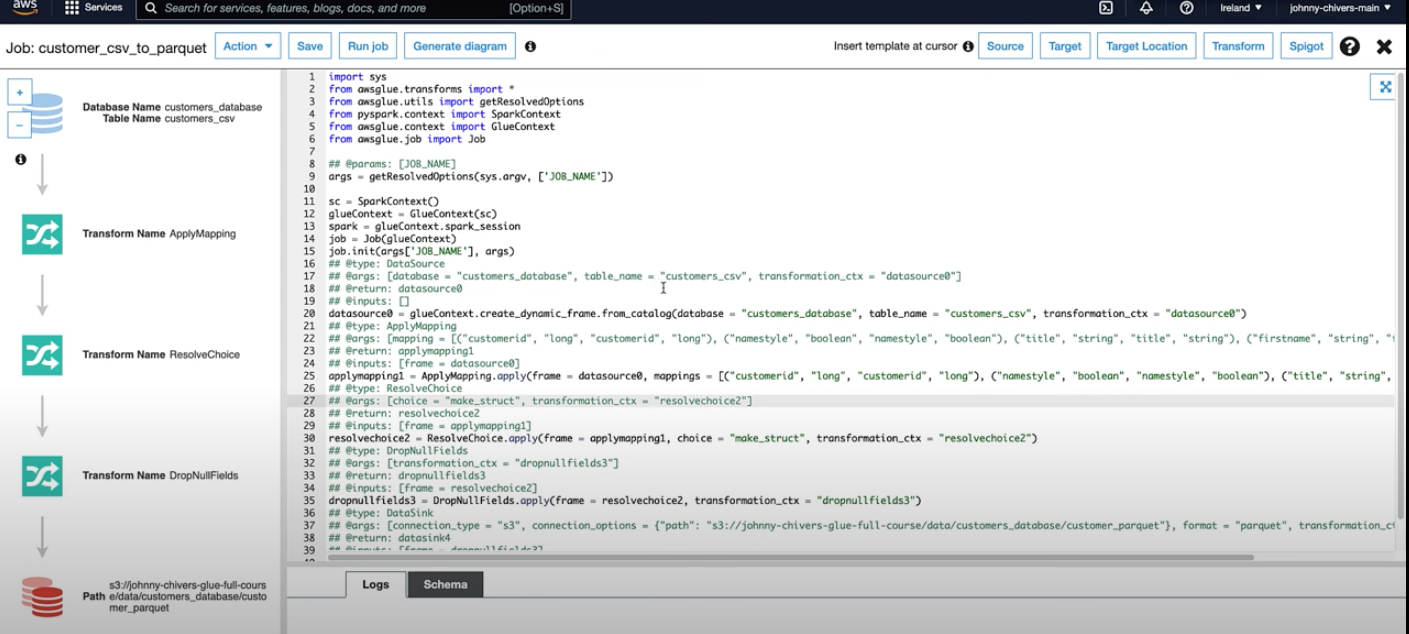
- Job Output: Illustrates the results stored in S3.
Additional Features
- Dynamic Data Frames: Glue uses dynamic data frames to create and manipulate data frames dynamically from the data catalog.
- Resolve Choice: Apply operations to resolve schema mismatches or ambiguities.
- Write Operation: The transformed data is written to the designated S3 location.
AWS Glue Triggers
AWS Glue triggers are essential for automating ETL (Extract, Transform, Load) jobs, allowing users to schedule or trigger jobs based on specific events. Here’s how to work with them:
Setting Up Triggers
- Automate ETL Jobs: Triggers can automatically start ETL jobs according to predefined conditions or schedules.
- Activation: To activate a trigger, navigate to the triggers section in the AWS Glue console and enable the desired trigger. Once activated, the trigger will manage the execution of its associated ETL jobs according to its configuration.
- The image below shows how a typical trigger setup looks in the AWS Glue console:
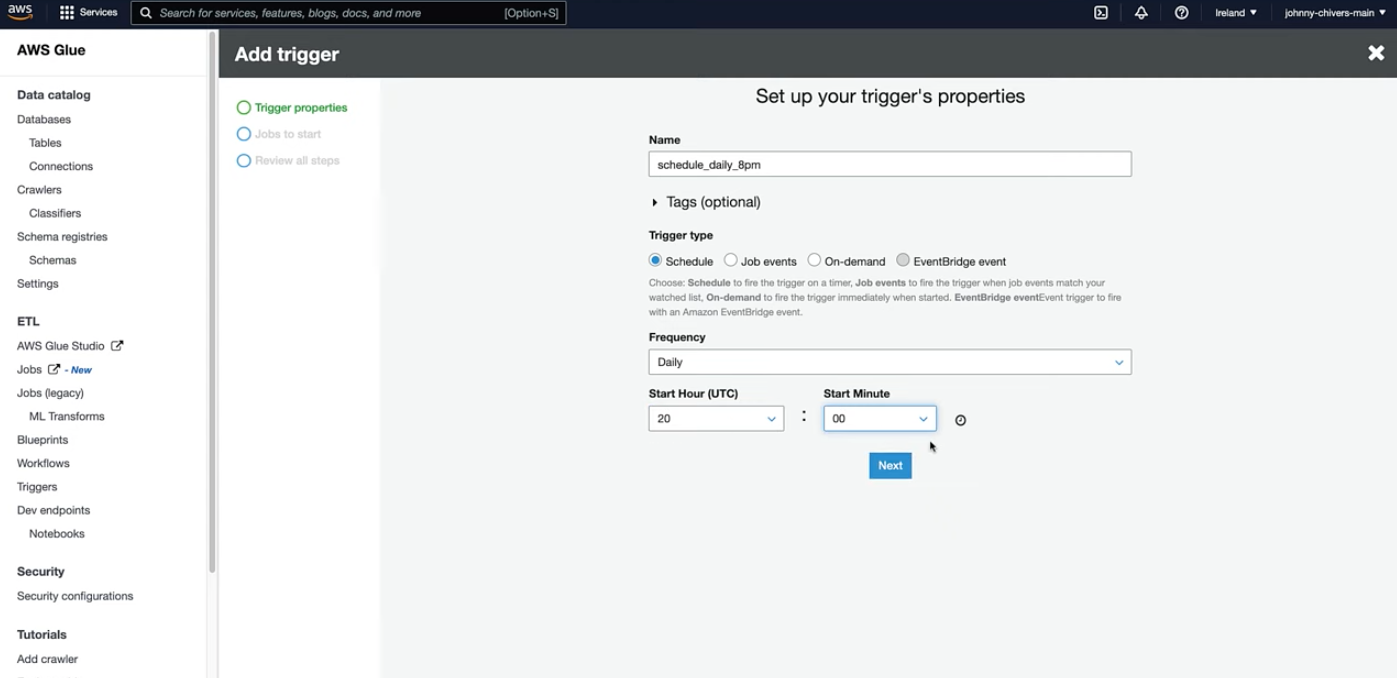
Monitoring Triggers
- After enabling a trigger, you can monitor its status within the AWS Glue console to ensure it is activated and functioning as expected. This helps in maintaining reliable and efficient job execution workflows.
Testing AWS Glue Jobs Locally
Testing AWS Glue scripts locally before deploying them can save time and resources. Here’s a general approach to testing Glue jobs locally:
Environment Setup
- Local Development Environment: Set up a local development environment that mimics the AWS Glue environment. This typically involves installing necessary libraries and SDKs such as AWS SDK, Apache Spark, and Python.
Testing Process
- Write Test Scripts: Create test scripts that invoke your Glue scripts with sample data. This allows you to validate the transformations and outputs without interacting with the full AWS environment.
- Run and Debug: Execute these tests in your local environment. Debug and refine the scripts as necessary based on the test outcomes.
Benefits
- Cost Efficiency: Testing locally can reduce the costs associated with running tests directly in AWS.
-
Faster Development Cycle: Quickly test and iterate over your Glue scripts without deploying them to AWS, speeding up the development process.
- Testing locally can be a powerful way to ensure that your ETL jobs perform as expected before they go live, providing a more controlled and cost-effective approach to development and deployment.