Youtube video search
- Overview
- ML problem
- input/output
- Choose ML Category
- High Level overview
- Data Preparation
- Text Normalization
- Tokenization
- Model Development
- Model training
- Evaluation
- Talking points
Overview
- On video-sharing platforms such as YouTube, the number of videos can quickly grow into the billions. In this chapter, we design a video search system that can efficiently handle this volume of content. As shown in Figure 4.1, the user enters text into the search box, and the system displays the most relevant videos for the given text.
Requirements
- Search system for videos
- Input text query and output list of videos relevant to search query
- Let’s summarize the problem statement. We are asked to design a search system for videos. The input is a text query, and the output is a list of videos that are relevant to the text query. To search for relevant videos, we leverage both the videos’ visual content and textual data. We are given a dataset of ten million ⟨ video, text query⟩ pairs for model training.
ML problem
- Ranking videos according to relevance to text query
- Users expect search systems to provide relevant and useful results. One way to translate this into an ML objective is to rank videos based on their relevance to the text query.
input/output
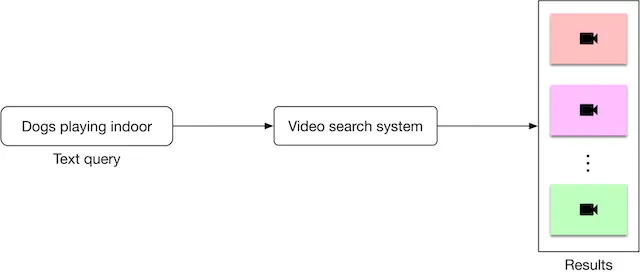
- Input text query
- Video search system
- outputs ranked video results
- As shown in Figure 4.2, the search system takes a text query as input and outputs a ranked list of videos sorted by their relevance to the text query.
Choose ML Category
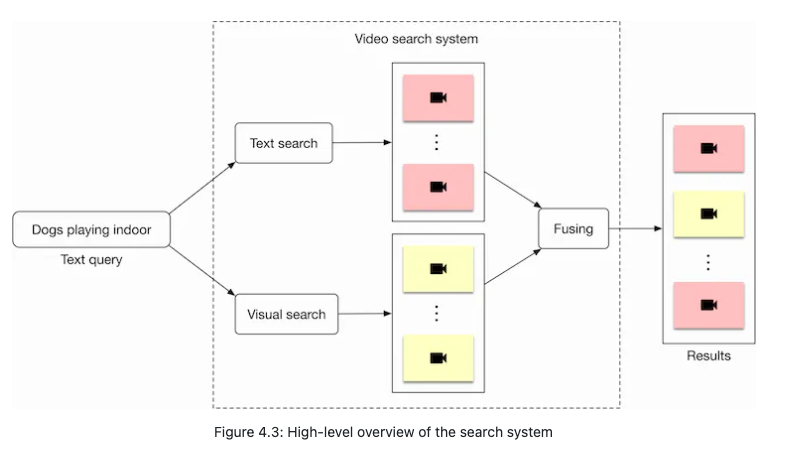
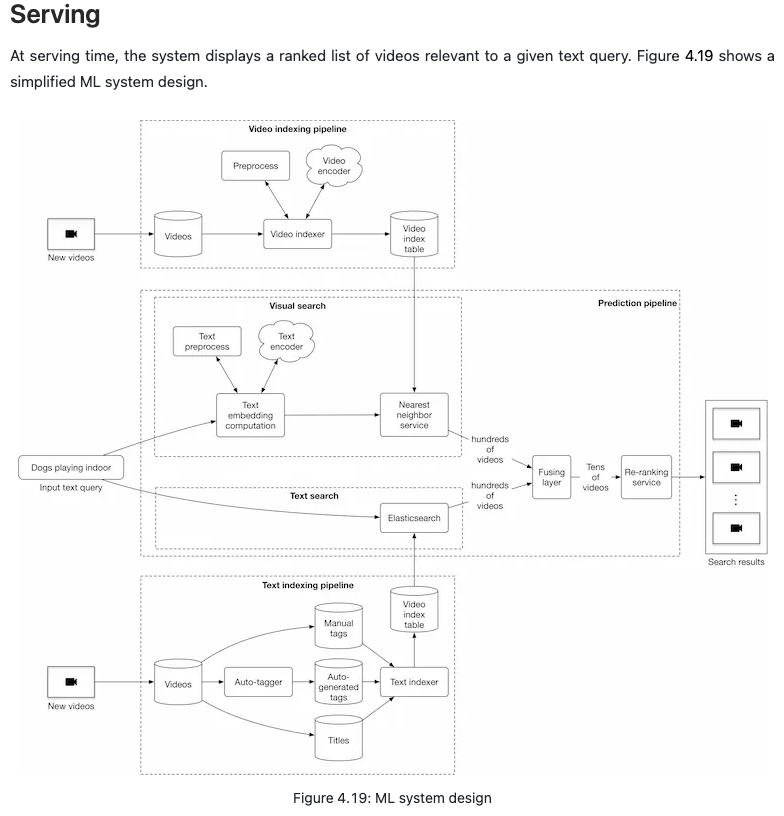
- In order to determine the relevance between a video and a text query, we utilize both visual content and the video’s textual data. An overview of the design can be seen in Figure 4.3.
- Let’s briefly discuss each component in the image below.
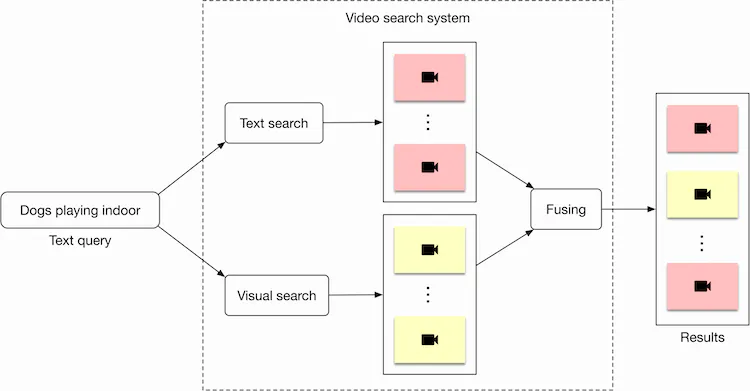
- Visual search
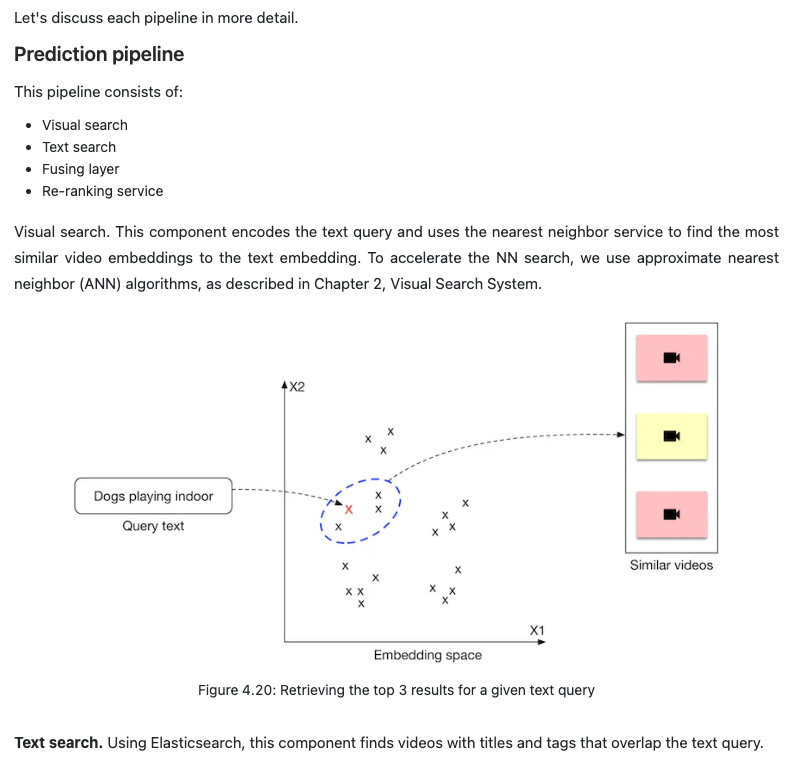
- This component takes a text query as input and outputs a list of videos. The videos are ranked based on the similarity between the text query and the videos’ visual content.
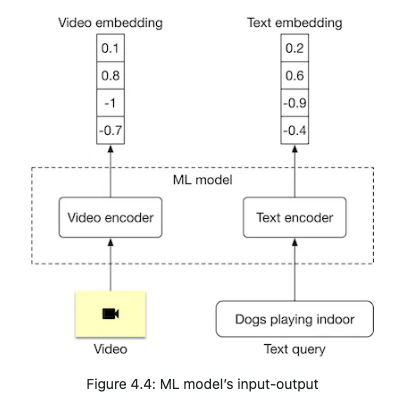
- Representation learning is a commonly used approach to search for videos by processing their visual content. In this approach, text query and video are encoded separately using two encoders. As shown in Figure 4.4, the ML model contains a video encoder that generates an embedding vector from the video, and a text encoder that generates an embedding vector from the text. The similarity score between the video and the text is calculated using the dot product of their representations.
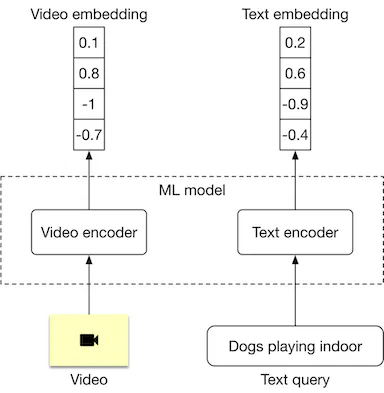
- In order to rank videos that are visually and semantically similar to the text query, we compute the dot product between the text and each video in the embedding space, then rank the videos based on their similarity scores.
- Text search
- Figure 4.5 shows how text search works when a user types in a text query: “dogs playing indoor”. Videos with the most similar titles, descriptions, or tags to the text query are shown as the output.
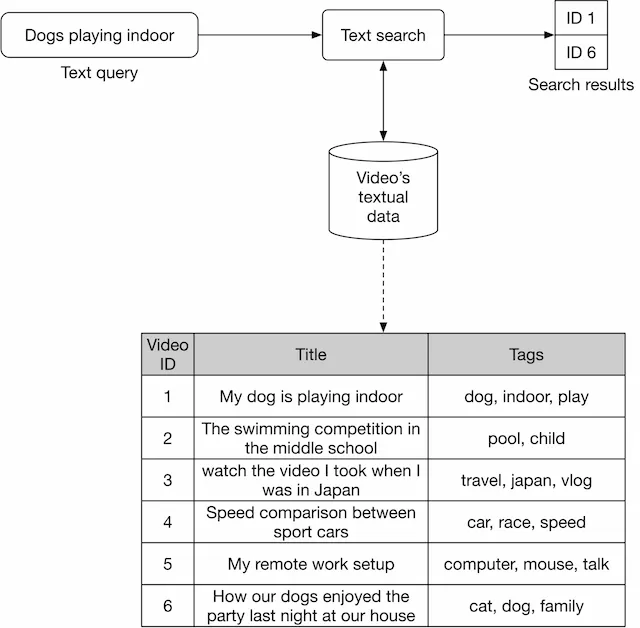
- The inverted index is a common technique for creating the text-based search component, allowing efficient full-text search in databases. Since inverted indexes aren’t based on machine learning, there is no training cost. A popular search engine companies often use is Elasticsearch, which is a scalable search engine and document store. For more details and a deeper understanding of Elasticsearch, refer to [1].
- Figure 4.5 shows how text search works when a user types in a text query: “dogs playing indoor”. Videos with the most similar titles, descriptions, or tags to the text query are shown as the output.
High Level overview
- Visual search:
- This component takes in a text query as input and outputs list of videos
- Looks at the simmilarity between text query and video visual content
- Text search:
- Videos are retreived with the most similar titles,, descriptions or tags
- The inverted index is a common technique for creating the text-based search component, allowing efficient full-text search in databases. Since inverted indexes aren’t based on machine learning, there is no training cost. A popular search engine companies often use is Elasticsearch, which is a scalable search engine and document store. For more details and a deeper understanding of Elasticsearch, refer to [1].
Data Preparation
- Data engineering
- Since we are given an annotated dataset to train and evaluate the model, it’s not necessary to perform any data engineering. Table 4.1 shows what the annotated dataset might look like.
- Features Engineering
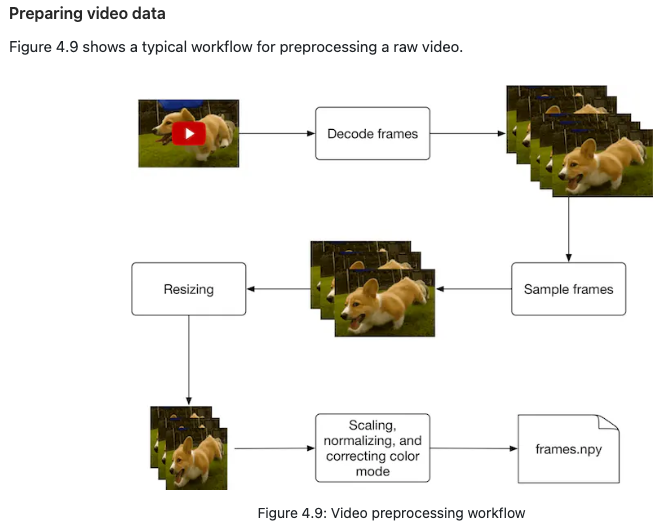
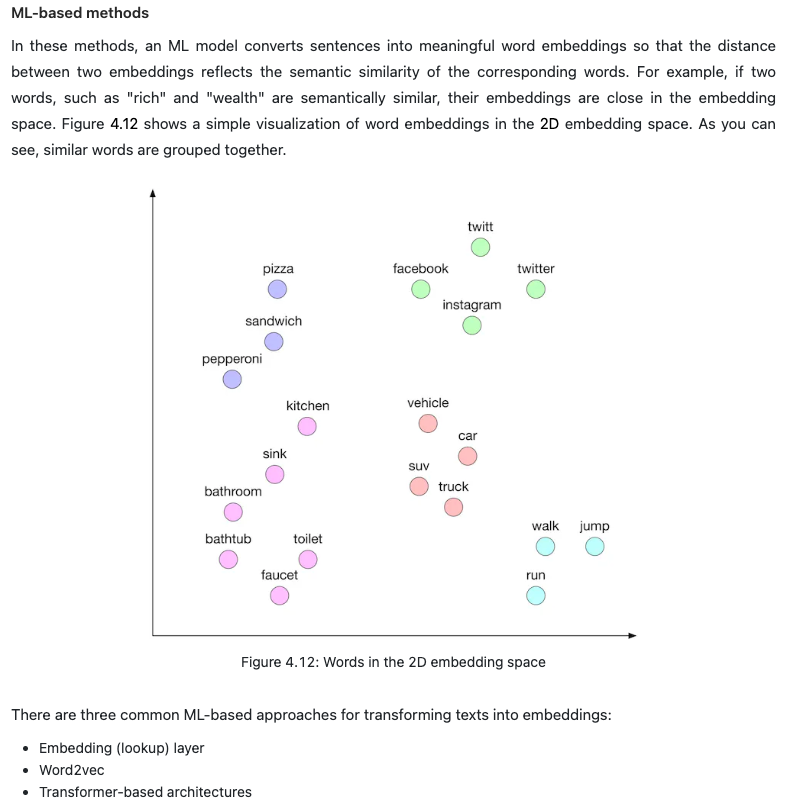
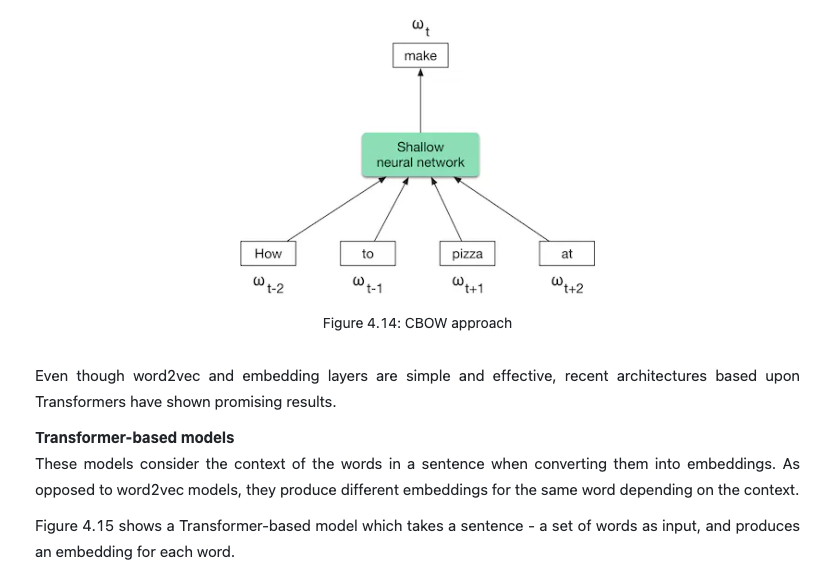
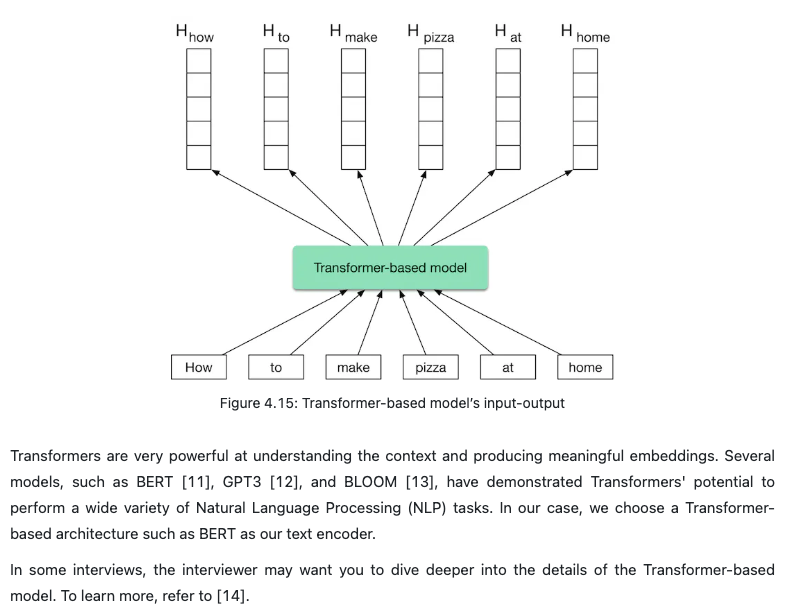
- Almost all ML algorithms accept only numeric input values. Unstructured data such as texts and videos need to be converted into a numerical representation during this step. Let’s take a look at how to prepare the text and video data for the model.
- Preparing text data
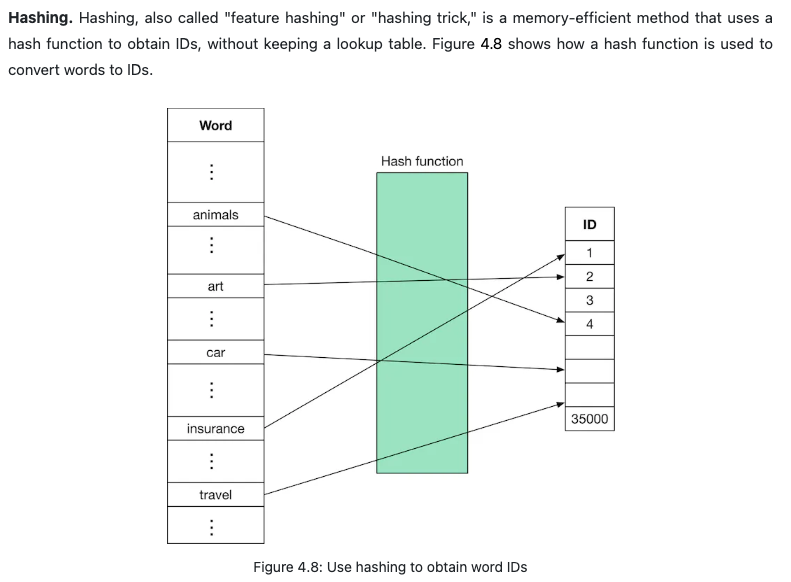
- As shown in Figure is typically represented as a numerical vector using three steps: text normalization, tokenization, and tokens to IDs
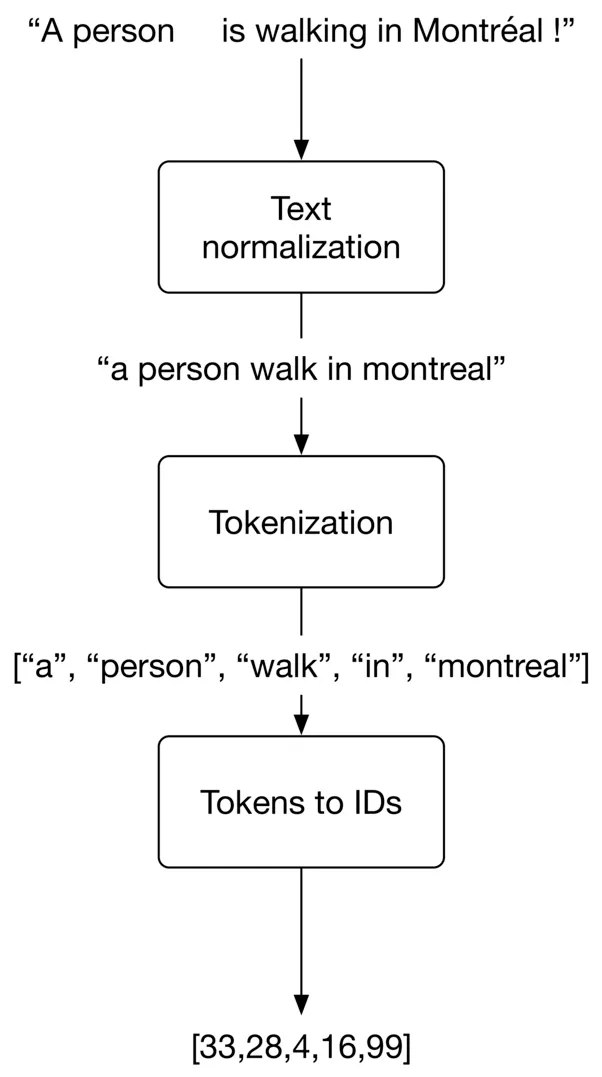
- As shown in Figure is typically represented as a numerical vector using three steps: text normalization, tokenization, and tokens to IDs
Text Normalization
Text normalization, often termed as text cleanup, is a process that aims to make words and sentences consistent. It addresses issues such as varied spellings of the same word or inconsistencies in sentence structure.
Illustrative Example:
- “dog”, “dogs”, and “DOG!” - Despite different spellings and punctuation, all refer to the same entity.
- Consider the sentences:
- “A person walking with his dog in Montréal !”
- “a person walks with his dog, in Montreal.”
Both convey the same meaning but have different punctuation and verb tenses.
Common Methods for Text Normalization:
- Lowercasing: Convert all characters to lowercase, preserving the essence of words/sentences.
- Punctuation Removal: Eliminate punctuation such as periods, commas, question marks, and exclamation points.
- Trim Whitespaces: Remove extra whitespaces, especially leading and trailing ones.
- Normalization Form KD (NFKD) [3]: Decompose combined characters into simpler ones.
- Strip Accents: Eliminate accent marks from words, e.g., Màlaga → Malaga, Noël → Noel.
- Lemmatization and Stemming: Establish a standard form for related word variants, e.g., walking, walks, walked → walk.
Tokenization
Tokenization entails breaking down textual content into smaller segments, termed tokens. Typically, tokenization manifests in three main forms:
- Word Tokenization: Dismantle the text into discrete words based on delineated delimiters. For instance, “I have an interview tomorrow” would be tokenized as [ “I”, “have”, “an”, “interview”, “tomorrow”].
- Subword Tokenization: Segment the text into subwords or n-gram characters.
- Character Tokenization: Deconstruct the text into individual characters.



Model Development



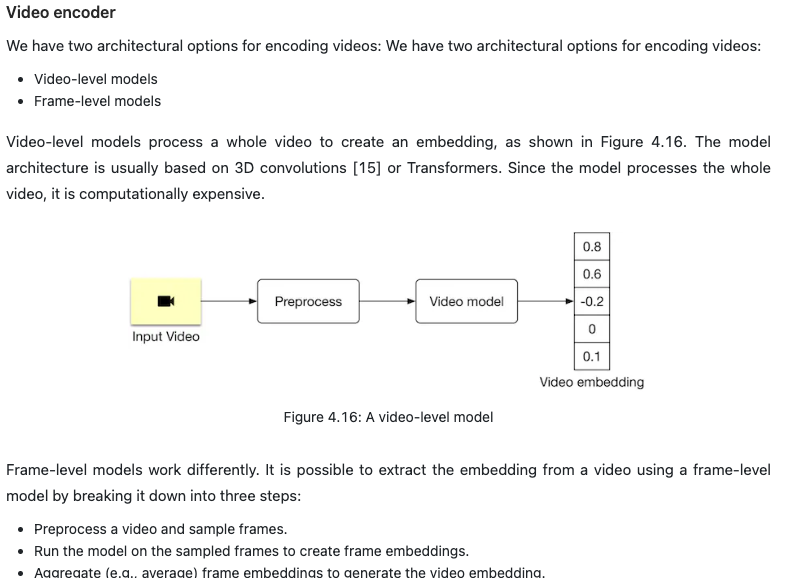
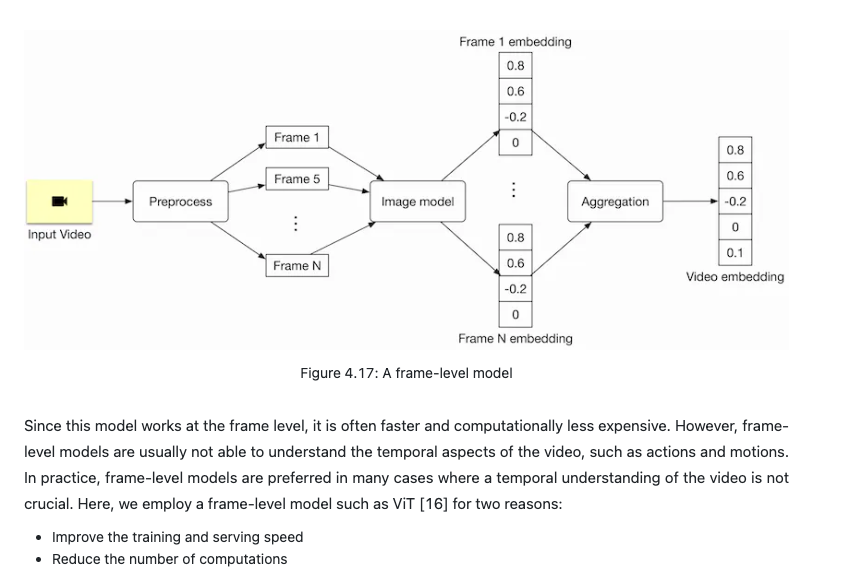
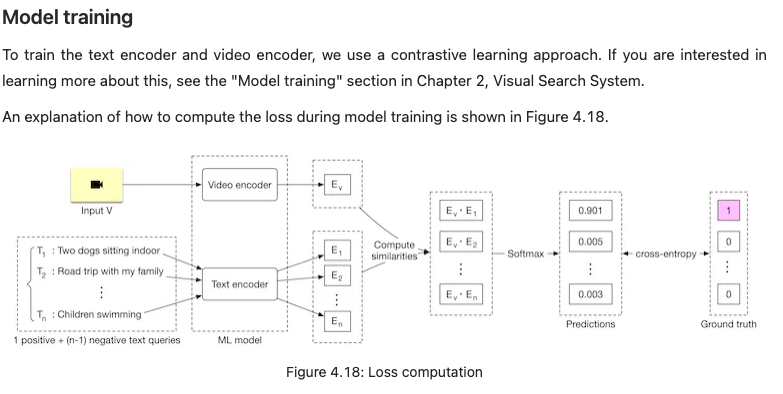
Model training
Evaluation



Talking points
