Overview
- Below I have broken down the key components of transformers into bite-sized chunks.
- These are the building blocks of transformers and they will help better understand the insight into GPT, BERT and other models that leverage part of this architecture.
- To give a bit of a background, the original transformer paper: “Attention is all you need”, introduced the concept of self-attention in an encoder-decoder model.
- The transformer from the paper was designed to translate English to German, but it generalized well for other NLP tasks.
- There are many reasons for why transformers revolution NLP, one of the biggest being their ability to use Transfer Learning.
- Transformers are very easily able to mold to perform new tasks that they have not been trained on.
- This can be done by leveraging a pre-trained model for your specific task by only having to slightly alter it, perhaps by fine-tuning it.
- Today, transformers are not just limited to language tasks but are used in vision, music, math, and so much more. The following plot (source) show the transformers family tree with prevalent transformer models:
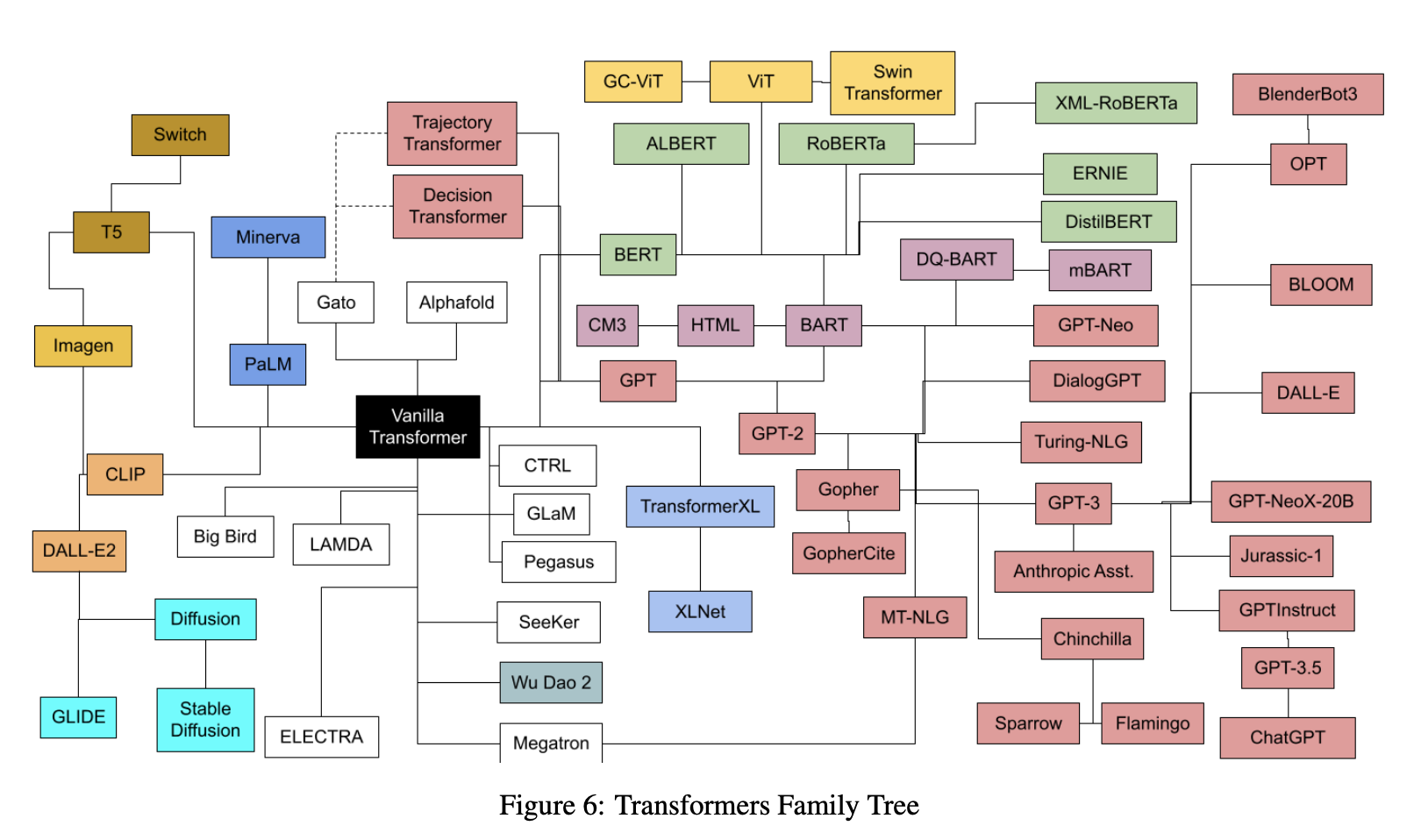
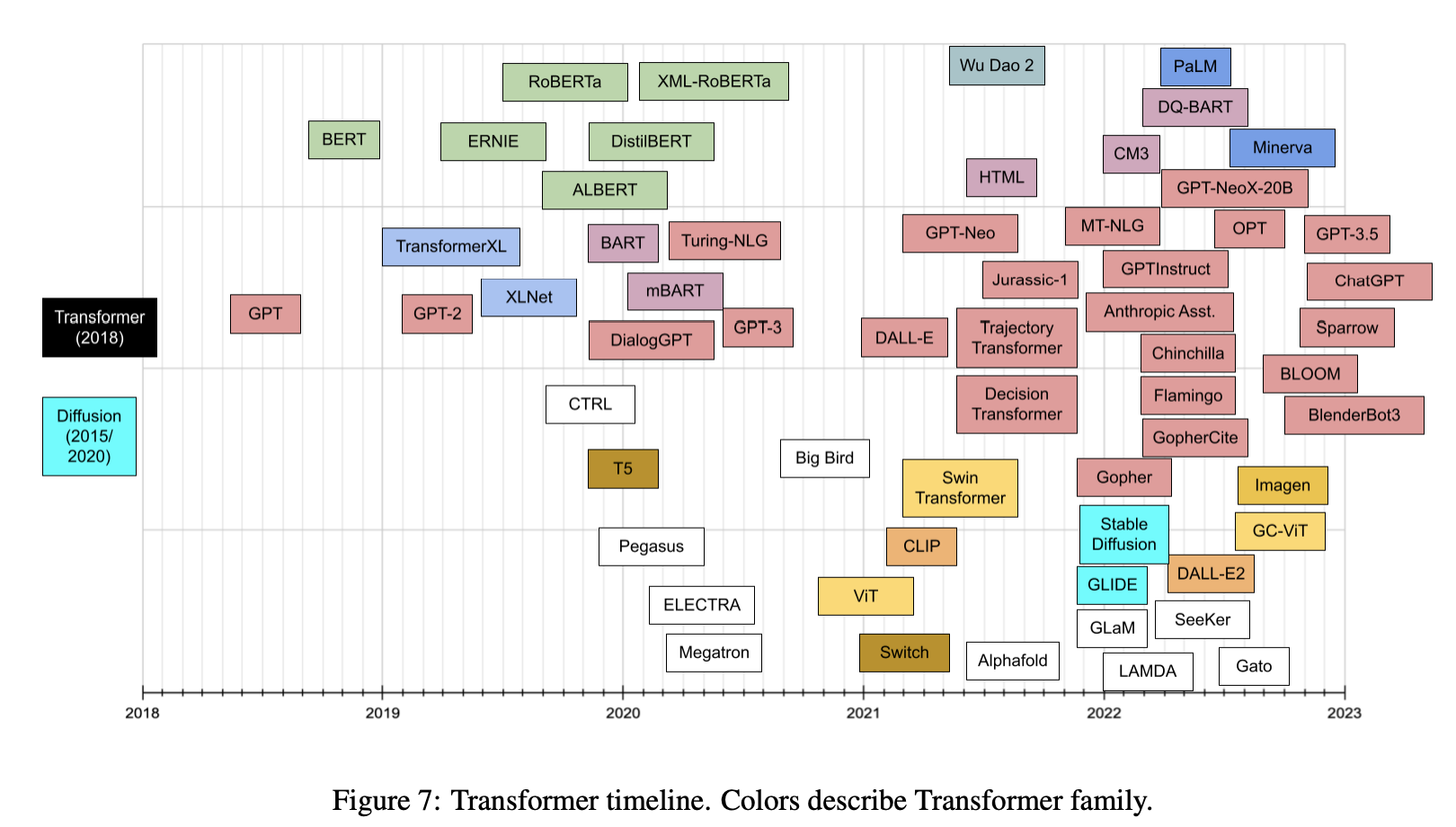
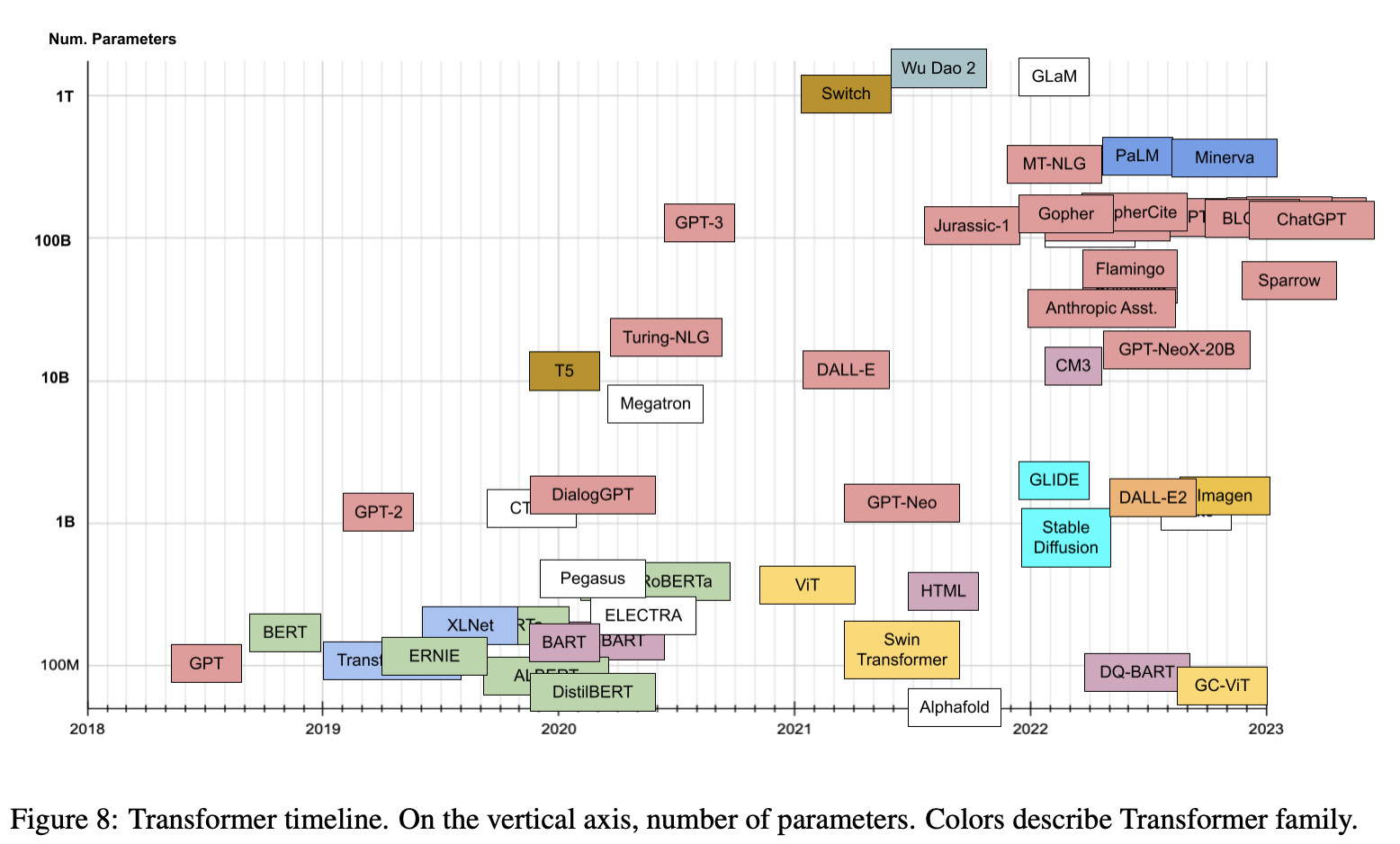
- Lastly, the plot below (source) shows the timeline vs. number of parameters for prevalent transformer models:
Word Embeddings
- “In language, words can be combined to get more complicated concepts. In mathematics, numbers can be added or subtracted to get other numbers.
Could we build a word embedding that captures relations between words, as relations between numbers?” Source Luis Serrano
- The statement above does a great job at capturing the basic idea of word embeddings.
- Word embedding is a technique in natural language processing (NLP) that is used to represent words as numerical vectors in a high-dimensional space.
- The goal of word embedding is to capture the semantic meaning of words and their relationships to other words in the vocabulary.
- The most common way to generate word embeddings is to use unsupervised learning techniques, such as the word2vec algorithm, which learns a vector representation of a word based on the context in which it appears in a large corpus of text.
- The resulting word embeddings can be used in various NLP tasks, such as text classification, named entity recognition, sentiment analysis, and machine translation.
- Word embeddings have become an important tool in NLP because they enable algorithms to work with text data in a more meaningful way.
- By representing words as numerical vectors, machine learning models can more easily recognize patterns and relationships in text data, which can lead to improved accuracy and performance in NLP applications.
- A good word embedding is able to capture all the features of a word.
Sentence Embeddings
- Unlike word embeddings, which represent individual words as vectors, sentence embeddings capture the meaning of entire sentences as vectors.
- This can be useful in NLP tasks such as text classification, sentiment analysis, and machine translation, where the meaning of the entire sentence is important.
- “Human language has structure, sentences, etc.
- How would one be able to represent, for instance, a sentence? Well, here’s an idea. How about the sums of scores of all the words?” Source Luis Serrano
- Sentence embedding is a technique in natural language processing (NLP) that is used to represent a sentence or a document as a single vector in a high-dimensional space.
- The goal of sentence embedding is to capture the semantic meaning of the entire sentence, including the relationships between words, in a way that can be used for downstream NLP tasks.
- There are different approaches to generating sentence embeddings:
- Averaging Word Embeddings: This is a simple approach that involves averaging the individual word embeddings in a sentence to produce the sentence embedding. This approach is easy to implement and computationally efficient, but it may not capture the full meaning of the sentence.
- Recurrent Neural Networks (RNNs): RNNs are a type of neural network that can process sequential data, such as a sentence. They can be used to generate sentence embeddings by processing the words in a sentence sequentially and capturing the context of each word. This approach can capture the order and context of words in a sentence, but it may not be as computationally efficient as the averaging approach.
- Convolutional Neural Networks (CNNs): CNNs are another type of neural network that can be used to generate sentence embeddings. They operate on fixed-size windows of words in a sentence and can capture local features of the sentence. This approach can be faster and more computationally efficient than RNNs, but it may not capture the long-term dependencies in a sentence as well as RNNs.
- Transformer-Based Models: Transformer-based models, such as BERT and GPT, are pre-trained on large datasets and can capture the meaning of sentences and the relationships between words. These models can be fine-tuned for a specific NLP task, such as text classification or sentiment analysis, by adding a task-specific output layer. Transformer-based models have shown state-of-the-art performance on many NLP tasks.
- Encoder-Decoder Models: Encoder-decoder models consist of two neural networks: an encoder that generates a fixed-length encoding of the input sequence and a decoder that generates the output sequence from the encoding. These models can be used to generate sentence embeddings by encoding the input sentence and using the encoding as the sentence embedding. This approach can be used for tasks such as machine translation and summarization.
Attention
- The following infographic (source) provides a quick overview of the constituent steps to calculate attention.
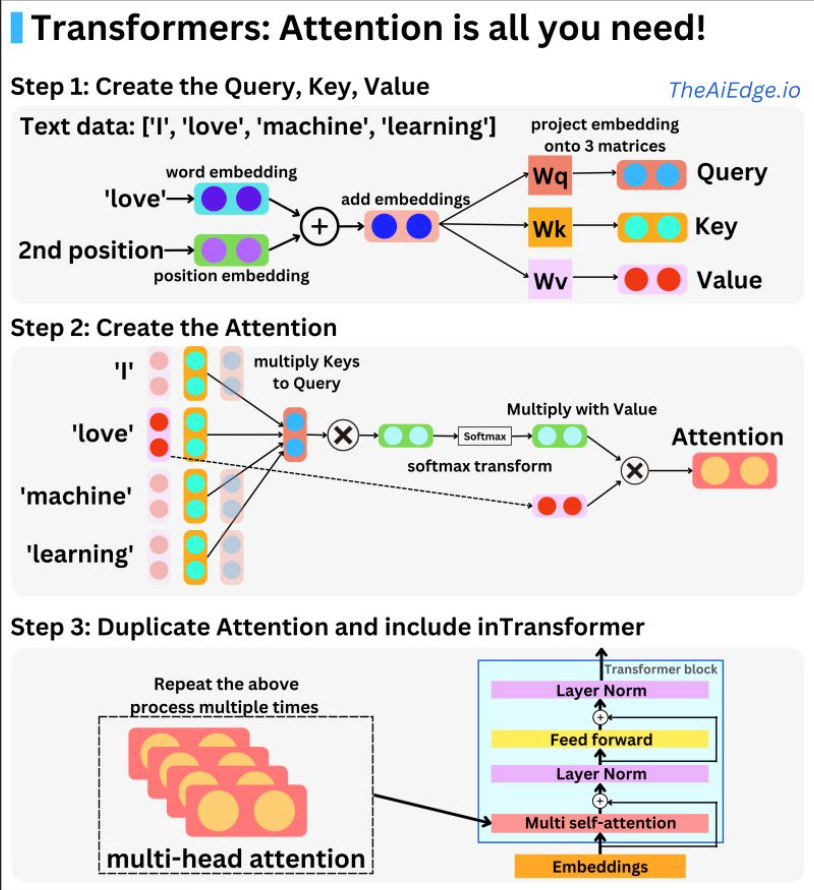
- As indicated in the section on Contextualized Word Embeddings, Attention enables contextualized word embeddings by allowing the model to selectively focus on different parts of the input sequence when making predictions. Put simply, the attention mechanism allows the transformer to dynamically weigh the importance of different parts of the input sequence based on the current task and context.
- In an attention-based model like the transformer, the word embeddings are combined with attention weights that are learned during training. These weights indicate how much attention should be given to each word in the input sequence when making predictions. By dynamically adjusting the attention weights, the model can focus on different parts of the input sequence and better capture the context in which a word appears. As the paper states, the attention mechanism is what has revolutionized Transformers to what we see them to be today.
- Upon encoding a word as an embedding vector, we can also encode the position of that word in the input sentence as a vector (positional embeddings), and add it to the word embedding. This way, the same word at a different position in a sentence is encoded differently.
- The attention mechanism works with the inclusion of three vectors: key, query, value. Attention is the mapping between a query and a set of key-value pairs to an output. We start off by taking a dot product of query and key vectors to understand how similar they are. Next, the Softmax function is used to normalize the similarities of the resulting query-key vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key. (source)
- Thus, the basis behind the concept of attention is: “How much attention a word should pay to another word in the input to understand the meaning of the sentence?”
- As indicated in the section on Attention Calculation, one of the benefits of self-attention over recurrence is that it’s highly parallelizable. In other words, the attention mechanism is performed in parallel for each word in the sentence to obtain their updated features in one shot. Furthermore, learning long-term/long-range dependencies in sequences is another benefit.
- The original paper only described the transformer architecture as the encoder/decoder model, however, since then much progress has been made.
- Let’s look at the different architectures we have available today:
Encoder/Decoder architecture
- The architecture of Transformers consists of an encoder and decoder which are jointly trained to minimize the conditional log-likelihood.
- This architecture type is also known as sequence-to-sequence.
- Their job is to work together in encoding and decoding vectors into output sequences.
- Now lets zoom in and look at the different details of the original transformer architecture as found in “Attention is all you need”:
- Encoder and Decoder both had 6 identical layers.
- Encoder had two sub-layers in each of those 6 layers: multi-head attention and a feed forward network.
- Each of these sub layers had residual connection and layer normalization.
- The output size of the Encoder is 512.
- The Decoder has the 2 sub-layers similar to the Encoder with an addition of a cross-attention sub-layer over the output of the Encoder.
- Attention in this case for encoder has access to all the words in the input while the decoder can only see the word that comes before a given word within the input.
Encoder pretraining
- These are also known as auto-encoders and they only use the encoder portion of the transformer architecture.
- We can utilize the encoder as a standalone by training it with masked words in the input and asking it to reconstruct the sentence.
- Encoders are very useful in tasks that require understanding of complete sentences, such as question answering.
- This is due to the fact that during pretraining, attention layers have access to all the input. This is why we mask the words during pretraining, so it doesn’t just memorize the words/context and actually learns.
Decoder pretraining
- These are also known as autoregressive and they only use the decoder part of the transformer architecture.
- Decoder tasks include predicting the next word since the attention layer can only access the word that came right before it.
- Decoders are also great at text generation.
Why is there no activation applied after multi-head attention layer
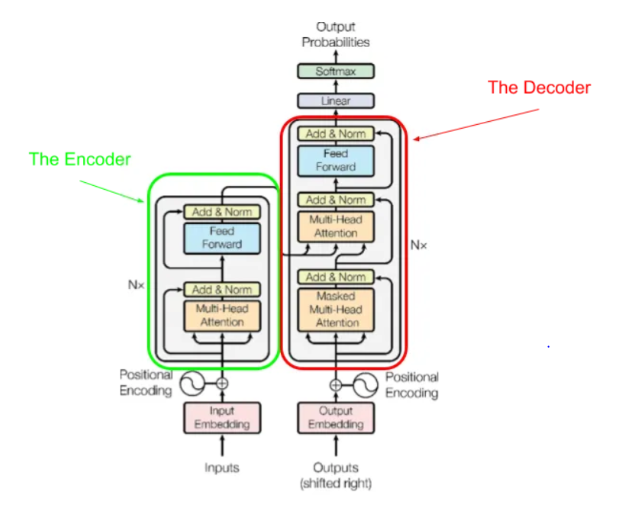
- As we see in the image above, there is indeed no activation applied after the multihead attention layers in both the encoder and decoder.
- As mentioned in the post here, we generally have an activation function between linear layers but we don’t see this in the transformer architecture.
- In order to understand this, we need to first take a step back and look at word-vectors. Cosine similarity is commonly used to compute the distance between word vectors because it is improbable for two words to be colinear in the dimensions where word tokens exist, even if they are trained to have similar values. Nevertheless, if two tokens are semantically similar, they will exhibit a higher cosine similarity than two words that are unrelated.
- Self-attention mechanism exploits this fact since after several of these matrix multiplications, the dissimilar words will zero out or become negative due to the dot product between them. Additionally, similar words will stand out in the resulting matrix.
- “Self attention can be viewed as a weighted average, where less similar words become averaged out faster (toward the zero vector, on average), thereby achieving groupings of important and unimportant words (i.e. attention). The weighting happens through the dot product. If input vectors were normalized, the weights would be exactly the cosine similarities.
- The important thing to take into consideration is that within the self-attention mechanism, there are no parameters; Those linear operations are just there to capture the relationship between the different vectors by using the properties of the vectors used to represent them.” (source)
- It was developed in 2021 by researchers from Microsoft Research Asia and other institutions.
- It is widely used for natural language processing tasks such as language translation and sentiment analysis.
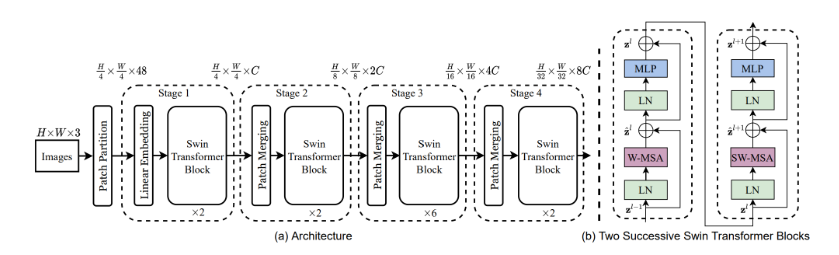
- The Swin Transformer architecture is designed to be more efficient than previous Transformer models, by using a hierarchical structure of smaller sub-groups of attention layers instead of one large attention matrix.
- This allows the model to handle larger input sizes and longer sequences with better scalability and less computational cost.
- Additionally, Swin Transformer uses a “Shifted Window” mechanism that helps reduce the amount of computation required during training.
- Swin Transformer has achieved state-of-the-art results on several benchmark datasets for image classification, object detection, and semantic segmentation tasks, demonstrating its effectiveness in computer vision applications.
Further Reading