Primers • Veo3
Video models are zero-shot learners and reasoners
Overview
Video models represent the natural successor to task-specific computer vision architectures, much as large language models displaced bespoke NLP systems. Generative video models trained on web-scale data with simple continuation objectives (image/video + text continuation) are beginning to demonstrate generalist, zero-shot capabilities across the vision stack—perception, modeling, manipulation, and reasoning. Veo-3, in particular, exhibits emergent abilities such as edge detection, segmentation, keypoint localization, intuitive physics reasoning (rigid/soft body dynamics, buoyancy, refraction), complex manipulations (style transfer, novel-view synthesis, text-conditioned inpainting/outpainting), and chain-of-frames (CoF) reasoning in tasks like maze solving and visual symmetry.
This progression suggests a paradigm shift: machine vision is converging on foundation models analogous to LLMs, with video models as the unifying substrate.
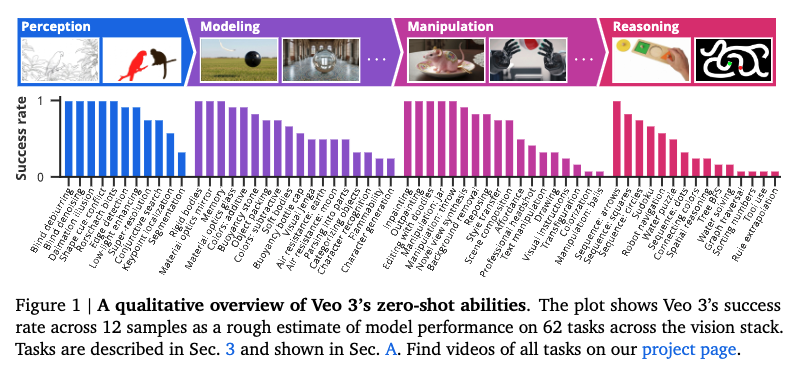
Methodology
The evaluation framework is deliberately minimal. Veo-2 and Veo-3 are prompted with a seed image and natural language instruction, generating 8-second, 720p, 24fps sequences via Google Cloud Vertex AI. A large-language-model-based rewriter processes prompts before forwarding them to the video backbone. Pure LLM baselines fail at tasks requiring temporal-spatial reasoning, isolating Veo’s contribution.
Evaluation spans 18,384 generated videos across 62 qualitative and 7 quantitative benchmarks. Metrics include pass@k, mIoU for segmentation, OIS for edge detection, and human-rated fidelity/precision for edits. Comparisons are drawn against state-of-the-art image models such as Nano Banana and SAMv2, and across Veo-2 vs. Veo-3 to capture scaling trends.
Key findings:
- Strong improvements from Veo-2 → Veo-3, narrowing the gap with task-specific baselines.
- Robustness to prompt variation, though sensitive to prompt engineering.
- CoF reasoning emerges as a temporal analogue to CoT in LLMs.
Formalizing the Paradigm Shift
Zero-shot video generation can be conceptualized as a temporal extension of in-context learning. In LLMs, a prompt
\[P = \{x_1, x_2, \ldots, x_n\}\]conditions the model to produce $y$. In video models, the conditioning sequence consists of both visual and textual tokens:
\[P = \{I_0, T_0, T_1, \ldots, T_n\}\]where $I_0$ is the seed frame and $T_i$ are textual instructions. The output is a sequence of frames:
\[V = \{I_1, I_2, \ldots, I_T\}\]This autoregression induces Chain-of-Frames (CoF) reasoning, a direct temporal analogue of Chain-of-Thought (CoT). Whereas CoT decomposes reasoning into symbolic steps:
\[f(x) \mapsto \{r_1, r_2, \ldots, r_m\} \mapsto y\]CoF decomposes reasoning into visual-temporal increments:
\[f(I_0, T) \mapsto \{I_1, I_2, \ldots, I_T\} \mapsto y\]Intermediate frames act as latent reasoning traces, encoding partial progress toward a solution.
Hierarchy of Capabilities
- Perception (low-level operators)
Edge detection, segmentation, and super-resolution emerge as byproducts of temporal coherence.- OIS for edges: Veo-3 achieves OIS@10 = 0.77, approaching specialized SOTA (0.90).
- Edges often exceed ground-truth annotations, suggesting perceptual granularity beyond dataset scope.
-
Modeling (intuitive physics and categorization)
\[y(t) = y_0 + v_0 t - \frac{1}{2} g t^2\]
Frame-to-frame consistency encodes physical invariants. For example, object trajectories approximate Newtonian dynamics:Veo simulates gravity variation, material deformation, buoyancy, and refraction, implying an implicit world model.
-
Manipulation (scene transformation)
Extends perception + modeling into active editing: background removal, novel-view synthesis, reposing, and style transfer. Latent disentanglement of entities and relations enables tool-use-like affordances. - Reasoning (temporal-symbolic planning)
CoF parallels CoT: reasoning occurs via sequential frame modifications. In maze-solving, paths are drawn incrementally, resembling algorithmic unfolding. Success improves with inference-time scaling (pass@10 ≫ pass@1), echoing LLM scaling laws.
Scaling Law Analogies
Performance scaling from Veo-2 → Veo-3 mirrors the early trajectory of LLMs:
- Gains arise without architectural overhaul, indicating emergent abilities triggered by scale.
- Like GPT-3, Veo-3 underperforms task-specific models but demonstrates adaptability and breadth.
- Inference costs decline super-exponentially, forecasting eventual economic feasibility.
Toward a Unified Vision Foundation Model
Video is the natural substrate for vision foundation models:
- Temporal coherence enforces physical reasoning.
- Frame autoregression enables stepwise reasoning.
- Multimodality aligns seamlessly with text and symbolic instructions.
Thus, video models may subsume segmentation, detection, editing, and physical reasoning under a single generalist architecture, collapsing the fragmented CV ecosystem.
Conclusion
The progression from image-specific systems toward generalist video foundation models marks a pivotal shift in machine vision. Autoregressive video generation with text conditioning yields not only coherent sequences but also emergent competencies across perception, modeling, manipulation, and reasoning. These arise without task-specific supervision, demonstrating that the generative prior alone can instantiate a wide spectrum of classical vision operators.
Chain-of-Frames reasoning plays the role for vision that Chain-of-Thought plays for language: a scaffold for stepwise problem solving. Scaling trends indicate that current deficits relative to specialized systems are temporary, while adaptability and generality are lasting advantages. As computational costs fall, video models are poised to unify vision under a single general-purpose substrate.
In sum, video models are not merely generative systems—they are emerging as zero-shot learners and reasoners with the potential to redefine computer vision itself.