Primers • DeepSeek-R1
- Introduction
- Architectural Foundations
- Overview
- Mixture of Experts (MoE)
- Multihead Latent Attention (MLA)
- Overview
- Key Features
- Evolution from DeepSeek-V2 to DeepSeek-R1
- MLA in DeepSeek-V2
- Enhancements in DeepSeek-V3
- Further KV Cache Reduction through Optimized Compression Techniques
- Optimized Compression Formulation
- Inference-Time Expansion
- Query Compression for Activation Memory Savings
- Reduction in Activation Memory
- Enhanced Numerical Stability with FP8 Mixed Precision
- Adaptive Routing for Load Balancing in MLA
- Enhancements in DeepSeek-R1
- Comparative Analysis
- Implementation
- Background: Standard Multi-Head Attention (MHA)
- Low-Rank Key-Value Joint Compression
- Multi-Stage Compression
- Query Compression and Optimization
- Decoupled Rotary Position Embedding (RoPE)
- Attention Computation in MLA
- RL-Optimized MLA
- Computational and Hardware Optimization
- Comparative Efficiency Analysis
- DeepSeek-R1-Zero \(\rightarrow\) Training Pipeline: Pure Reinforcement Learning in DeepSeek-R1-Zero
- DeepSeek-R1 \(\rightarrow\) Training Pipeline: Cold-Start SFT to Multi-Stage RL
- Stage 1: Cold Start with SFT
- Stage 2: RL
- DeepSeek’s RL Methodology: A Conceptual Overview
- Background: Policy Optimization
- Group Relative Policy Optimization (GRPO)
- Reward Functions
- Stage 3: Rejection Sampling & Expanded Supervised Fine-Tuning
- Stage 4: Secondary RL for Alignment & Generalization
- Comparing Training Pipelines: DeepSeek-R1 vs. DeepSeek-R1-Zero
- GRPO Variants
- Emergent Reasoning Behaviors
- Distillation: Reasoning in Compact Models
- Results
- Prompt Template
- Open Questions
- Other Reasoning Models
- DeepSeek R1-1776
- Open-Source Reasoning Datasets
- FAQs
- Is GRPO a policy gradient algorithm?
- Is GRPO an actor-critic algorithm?
- Can GRPO be applied to outcome supervision or process supervision or both? How is the advantage computed from reward in either case?
- How is a reward model different from a value/critic model in policy optimization algorithms such as GRPO?
- In the equation for GRPO, what is the role of the old policy compared to the reference policy?
- Why is the PPO/GRPO objective called a clipped “surrogate” objective?
- What are some considerations around the reasoning tokens budget in reasoning LLMs?
- Further Reading
- References
Introduction
- DeepSeek-R1 and DeepSeek-R1-Zero represent a landmark in reasoning-capable Large Language Models (LLMs). Released under an MIT license, this model rivals closed-source giants like OpenAI’s o1 and o3 series while pioneering a reinforcement learning (RL)-driven framework for reasoning tasks.
- Both models leverage Group Relative Policy Optimization (GRPO), introduced in DeepSeekMath, which replaces traditional methods like PPO, making training both efficient and scalable. They also utilize Multihead Latent Attention (MLA), introduced in DeepSeek-V2, which reduces computational and memory inefficiencies particularly for long-context processing by projecting Key-Query-Value (KQV) matrices into a lower-dimensional latent space.
- DeepSeek-R1-Zero demonstrates how reasoning capabilities emerge naturally purely through RL without any Supervised Fine-Tuning (SFT). By relying solely on self-evolution through RL, DeepSeek-R1-Zero naturally developed powerful reasoning behaviors but also exhibited challenges such as poor readability and language mixing. DeepSeek-R1 built upon this foundation and addressed the aforementioned issues by incorporating multi-stage training and a small amount of cold-start data to improve reasoning performance and usability.
- Through innovations like GRPO, FP8 quantization, and emergent Chain-of-Thought (CoT) reasoning, both models rival closed-source models while fostering transparency and accessibility. As the research community builds upon these innovations, DeepSeek-R1 signals a shift towards efficient, reasoning-driven AI accessible to all.
- This primer explores its architecture, multi-stage training pipeline, GRPO mechanics, and emergent reasoning behaviors, alongside how distillation propagates reasoning capabilities to smaller models.
Architectural Foundations
- DeepSeek-R1 builds upon the foundational advancements introduced in DeepSeek-V2 — specifically, Mixture of Experts (MoE) and Multihead Latent Attention (MLA) — and DeepSeek-V3 — specifically, Multi-Token Prediction (MTP) — integrating cutting-edge architectural innovations that optimize both training efficiency and inference performance.
- This section provides a detailed breakdown of the architectural components that evolved from DeepSeek-V2 and DeepSeek-V3 to DeepSeek-R1, highlighting improvements that make DeepSeek-R1 a leading open-source model, capable of rivaling proprietary alternatives in reasoning efficiency and performance.
Overview
-
DeepSeek-R1 incorporates several advanced techniques to achieve remarkable efficiency improvements:
-
Mixture of Experts (MoE) Architecture: DeepSeek-R1 utilizes a Mixture of Experts model, which decomposes a large model into smaller, specialized sub-models. This architecture allows for the activation of only relevant sub-models during specific tasks, enabling the system to operate efficiently on consumer-grade GPUs.
-
Key-Value Memory Compression via Multihead Latent Attention (MLA): By implementing sophisticated compression algorithms, DeepSeek-R1 achieves a 93% reduction in the storage requirements for key-value indices, which are known to consume considerable amounts of VRAM.
-
Multi-Token Prediction: DeepSeek-R1 is designed to predict multiple tokens simultaneously rather than one at a time. This strategy effectively doubles the inference speed, enhancing overall performance.
-
Low-Precision Computation: DeepSeek-R1 employs mixed-precision arithmetic, performing a significant portion of computations using 8-bit floating-point numbers instead of the standard 32-bit. This approach substantially reduces memory consumption and accelerates processing speeds.
-
-
Collectively, these innovations contribute to DeepSeek-R1’s significant advancements in training efficiency, reportedly achieving a 45-fold improvement over previous models.
Mixture of Experts (MoE)
Overview
- The Mixture of Experts (MoE) mechanism, the “sparse” MoE variant of which was originally proposed in Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer by Shazeer et al. (2017), selectively activates a subset of the total model parameters at each inference step, achieving computational savings while maintaining model quality. This approach enables scaling up model parameters without a proportional increase in computational cost.
- DeepSeekMoE introduced the initial MoE architecture that V2, V3, and R1 build on. Specifically, DeepSeek-R1 utilizes the same MoE architecture as DeepSeek-V3, focusing its enhancements solely on training methods such as reinforcement learning and supervised fine-tuning, without modifying the underlying model structure.
Key Features
-
Reinforcement Learning-Based Expert Routing: DeepSeek-R1 replaces static gating functions with a reinforcement learning (RL) policy to dynamically assign tokens to experts. The RL-based router optimizes expert selection by maximizing load balancing while minimizing routing entropy, leading to more efficient token-expert mapping.
-
Hierarchical Entropy-Gated MoE (HE-MoE): The expert selection process is refined with a multi-level gating mechanism. Tokens first pass through a global selection phase, followed by cluster-level pruning, and finally, an entropy-aware adjustment ensures balanced expert activation. This approach prevents expert over-specialization and improves generalization.
-
Device-Constrained Expert Allocation (DCEA): Experts are assigned based on available compute resources, reducing cross-device communication overhead. The model selects experts within a constrained pool of devices, lowering synchronization costs and increasing training efficiency.
-
Load-Balanced Expert Utilization with RL-Based Adjustments: Instead of relying on auxiliary loss functions to balance load, DeepSeek-R1 dynamically adjusts expert activation probabilities using RL-based bias terms. This ensures consistent workload distribution without additional loss penalties, improving stability and convergence.
-
Full Token Retention (No Token Dropping): Unlike earlier iterations that dropped low-affinity tokens to balance computational load, DeepSeek-R1 retains all tokens during both training and inference. This ensures that no information is lost, leading to improved model coherence and generalization.
-
Adaptive Expert Specialization: By incorporating entropy-based constraints, DeepSeek-R1 ensures that experts remain specialized but not overly rigid. This dynamic specialization enhances both accuracy and efficiency while maintaining flexibility in expert activation.
Evolution from DeepSeekMoE to DeepSeek-R1
DeepSeekMoE
- Compared to a vanilla sparse MoE architecture such as the one proposed in Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, DeepSeekMoE refines expert selection, routing, and load balancing strategies to reduce computational overhead. It proposed two principal strategies:
- Fine-Grained Expert Segmentation: Each FFN was split into multiple smaller experts, activated flexibly to maintain specialization.
- Shared Expert Isolation: Some experts were made always-active to capture common knowledge and reduce redundancy.
- DeepSeekMoE demonstrated that with only 40% of the computation of comparable dense models, it could achieve similar or better performance, showing strong specialization and scalability.
- Below, we detail the MoE-specific mechanisms in DeepSeekMoE, breaking them down into their individual components.
Basic Architecture of DeepSeekMoE
- DeepSeekMoE is designed with fine-grained expert segmentation and shared expert isolation, which increase specialization while reducing redundancy. The MoE architecture in DeepSeek-V2 consists of:
- \(N_s\) shared experts, which process all tokens.
- \(N_r\) routed experts, which are selectively activated for tokens based on a gating function.
- Each token is processed by a fixed number \(K_r\) of routed experts.
-
The output of the MoE layer is computed as:
\[h'_t = u_t + \sum_{i=1}^{N_s} FFN^{(s)}_i (u_t) + \sum_{i=1}^{N_r} g_{i,t} FFN^{(r)}_i (u_t)\]- where:
- \(FFN^{(s)}_i\) represents a shared expert.
- \(FFN^{(r)}_i\) represents a routed expert.
- \(g_{i,t}\) is the gating function, determining expert selection for token \(t\).
- where:
-
The gating function follows:
\[g_{i,t} = \begin{cases} s_{i,t}, & s_{i,t} \in \text{Top-}K_r(\{s_{j,t} \mid 1 \leq j \leq N_r\}) \\ 0, & \text{otherwise} \end{cases}\]- where \(s_{i,t}\) is the softmax-weighted token-expert affinity:
- where \(e_i\) is the centroid of expert \(i\).
Enhancements in DeepSeek-V2
Auxiliary Losses for Load Balancing
- DeepSeek-V2 improves upon DeepSeekMoE and addresses challenges of expert specialization and efficiency through refined routing and load balancing mechanisms.
- It incorporates three auxiliary losses to ensure balanced utilization of experts and devices:
- Expert-Level Balance Loss: Prevents routing collapse by encouraging uniform usage of routed experts. The loss minimizes the imbalance across experts by considering the fraction of tokens assigned and the average selection probability for each expert.
- Device-Level Balance Loss: Ensures computation is evenly spread across devices by grouping experts into device partitions and balancing token assignments across these groups.
- Communication Balance Loss: Promotes balanced incoming communication to each device, preventing bottlenecks from uneven token traffic during expert selection.
- Together, these auxiliary losses help avoid situations where certain experts or devices become overloaded while others remain underutilized, ensuring training stability and improving throughput efficiency.
Device-Limited Routing
- To further reduce communication overhead, DeepSeek-V2 restricts the number of devices a token can interact with during expert routing.
- For each token:
- \(M\) devices (typically 3) with the highest affinity scores are selected first.
- The final \(K_r\) experts are then chosen from these selected devices.
- This method reduces cross-device synchronization without significantly impacting performance.
Token-Dropping Strategy
- Although auxiliary losses improve balance, perfect load uniformity cannot be guaranteed. To address residual imbalance, DeepSeek-V2 implements a token-dropping strategy:
- The computational budget per device is estimated.
- Tokens with the lowest affinity scores are selectively dropped until the device stays within budget.
- Approximately 10% of training sequences are exempt from dropping, preserving model diversity and generalization capability.
- This flexible strategy allows DeepSeek-V2 to maintain high training and inference efficiency without significantly degrading model quality.
Enhancements in DeepSeek-V3
- DeepSeek-V3 introduces several significant improvements to the MoE framework compared to DeepSeek-V2 by introducing dynamic expert routing, reinforcement learning-based load balancing, and enhanced sparsity constraints.
- These enhancements primarily focus on increasing model efficiency, reducing communication overhead, maintaining high token retention, and ensuring expert load balancing without auxiliary losses. Key improvements include:
Auxiliary-Loss-Free Load Balancing
-
In contrast to DeepSeek-V2, which relies on auxiliary losses to ensure balanced expert utilization, DeepSeek-V3 primarily adopts an auxiliary-loss-free strategy. Instead of penalizing imbalance with additional loss terms, DeepSeek-V3 dynamically adjusts expert selection using bias terms. Specifically, each expert is associated with a bias term \(b_i\), which is added to the token-expert affinity score \(s_{i,t}\) to determine top-\(K_r\) expert selection:
\[g'_{i,t} = \begin{cases} s_{i,t}, & s_{i,t} + b_i \in \text{Top-}K_r(\{s_{j,t} + b_j \mid 1 \leq j \leq N_r\}) \\ 0, & \text{otherwise} \end{cases}\] -
The bias term \(b_i\) is dynamically updated during training based on expert load:
\[b_i \leftarrow b_i - \gamma \quad \text{(if overloaded)}, \quad b_i \leftarrow b_i + \gamma \quad \text{(otherwise)},\]where \(\gamma\) is a small hyperparameter controlling the bias adjustment speed.
-
This bias-based adjustment ensures that expert load remains balanced across the batch without relying on explicit auxiliary loss penalties, improving training stability and model performance.
-
Complementary Sequence-Wise Auxiliary Loss:
Although DeepSeek-V3 primarily balances loads without auxiliary losses, it introduces a very small sequence-wise auxiliary loss to prevent extreme expert imbalance within individual sequences. This loss lightly encourages balanced expert usage per sequence but uses an extremely small weighting factor, minimizing any impact on model optimization.
Node-Limited Routing (NLR)
- To minimize cross-node communication during expert routing, DeepSeek-V3 restricts the number of nodes each token can communicate with. Tokens are routed only to experts located on a limited set of nodes, selected based on aggregated token-expert affinity scores. This strategy significantly reduces synchronization overhead without degrading model performance.
Improved Expert Selection Mechanism
-
DeepSeek-V3 refines expert selection by adopting a sigmoid-based token-expert affinity function, replacing the softmax-based approach used in DeepSeek-V2:
\[s_{i,t} = \sigma ( u_t^T e_i ),\]where \(e_i\) is the centroid vector for expert \(i\) and \(\sigma(\cdot)\) denotes the sigmoid function.
-
After selecting the top-\(K_r\) experts based on bias-adjusted affinities, the final gating values are normalized among the selected experts:
\[g_{i,t} = \frac{ g'_{i,t} }{ \sum_{j \in \text{Top-}K_r} g'_{j,t} }.\] -
This adjustment smooths expert selection, avoiding extreme affinity values and improving both specialization and load balance.
Enhanced Sparsity Constraints with Hierarchical Gating
-
To avoid over-specialization and encourage generalization, DeepSeek-V3 introduces a hierarchical gating mechanism for expert selection. Instead of using traditional top-\(K\) gating, DeepSeek-V3 applies sparsity constraints in multiple stages:
- Global Selection: An initial coarse-level selection of experts is performed.
- Fine-Grained Expert Selection: Experts are then further refined within clusters based on token-expert affinities.
- Entropy-Based Adjustments: Entropy-based techniques are applied to maintain balanced expert utilization and prevent extreme specialization.
-
These improvements promote better load balance and generalization without requiring additional loss penalties.
No Token-Dropping Strategy
- DeepSeek-V2 implemented a token-dropping strategy to balance computation per device. However, DeepSeek-V3’s enhanced auxiliary-loss-free load-balancing mechanism eliminates the need for token dropping, ensuring 100% token retention during both training and inference. This improves generalization and avoids loss of information during model updates.
Comparative Analysis
- DeepSeek-R1 represents the most advanced iteration of the MoE framework, building upon the optimizations introduced in DeepSeek-V2 and DeepSeek-V3. Below, we compare key MoE features across these three versions, highlighting improvements in efficiency, expert routing, load balancing, and inference performance.
| Feature | DeepSeekMoE | DeepSeek-V2 | DeepSeek-V3 / DeepSeek-R1 |
|---|---|---|---|
| Fine-Grained Expert Segmentation | ✅ Introduced | ✅ Continued | ✅ Continued |
| Shared Expert Isolation | ✅ Introduced | ✅ Continued | ✅ Continued |
| Auxiliary Losses for Load Balancing | ❌ Not used | ✅ Added (Expert/Device/Comm balance losses) | ❌ Mostly removed (bias-based balancing) |
| Bias-Based Load Balancing | ❌ Not used | ❌ Not used | ✅ Introduced |
| Node-Limited Routing | ❌ Not used | ✅ Introduced (device-limited) | ✅ Improved (node-limited) |
| Hierarchical Gating (Entropy-Based) | ❌ Not used | ❌ Not used | ✅ Introduced |
| Sigmoid-Based Expert Affinity | ❌ Not used (Softmax) | ❌ Not used (Softmax) | ✅ Introduced (Sigmoid) |
| Token Dropping Strategy | ❌ No dropping | ✅ Introduced | ❌ Eliminated |
| Reinforcement Learning for Expert Routing | ❌ Not used | ❌ Not used | ❌ Not used |
| Change to MoE Architecture | ✅ Initial design | ✅ Refinements added | ✅ Further refinements, no structural change in R1 |
Mathematical Formulation
Expert Selection
-
In DeepSeek-R1 (which mostly inherits the MoE architecture from DeepSeek-V3), each token is routed to a subset of experts based on a learned gating function. The gating function computes an affinity score for each expert, and the top-K experts are selected for each token based on these scores.
-
The final output is computed as:
\[y = \sum_{k \in \text{TopK}(x)} G_k(x) E_k(x)\]- where:
- TopK(x) refers to the indices of the top-K experts selected per token.
- \(E_k(x)\) is the output of expert \(k\) on input \(x\).
- \(G_k(x)\) represents the normalized gating weight.
- where:
Load Balancing Loss
- DeepSeek-V3 adopts an auxiliary-loss-free strategy to encourage balanced expert utilization. Instead of explicitly adding a load balancing loss during training, the model architecture is designed to promote even expert usage through fine-grained expert segmentation and shared expert isolation.
Multihead Latent Attention (MLA)
Overview
- Multihead Latent Attention (MLA) enhances efficiency by projecting Key-Query-Value (KQV) matrices into a lower-dimensional latent space, significantly reducing computational and memory costs.
- Low-rank compression techniques in MLA minimize the storage overhead of the Key-Value (KV) cache, ensuring faster inference and supporting longer context lengths or larger batch sizes.
- By utilizing decoupled rotary positional embeddings and latent-space compression, MLA ensures minimal accuracy degradation while maintaining computational efficiency.
Key Features
- Low-Rank Key-Value Compression: MLA compresses key-value pairs into a shared latent space using low-rank projections, significantly reducing memory overhead. DeepSeek-R1 leverages this technique from previous DeepSeek versions to enable efficient long-context processing.
- Decoupled Rotary Position Embedding (RoPE): Introduced in DeepSeek-V2, decoupled RoPE prevents position-dependent transformations from interfering with latent-space compression, ensuring effective positional encodings without compromising compression efficiency.
- Efficient Multihead Attention with Compressed Storage: MLA stores compact latent representations instead of full-dimensional keys and values, drastically reducing inference memory requirements while preserving attention fidelity.
- Learned Projection Matrices: Separate, learned projection matrices for queries, keys, and values are optimized during model training to balance storage efficiency and model accuracy. These matrices remain fixed after training.
- Inference-Efficient Cache Mechanism: DeepSeek-V2 achieved a 93.3% reduction in KV cache size compared to standard Multi-Head Attention. DeepSeek-R1 continues to benefit from this efficiency, supporting longer context lengths and faster inference.
- Enhanced Reasoning with RL-Optimized Attention: DeepSeek-R1 improves reasoning performance by applying reinforcement learning (GRPO) to prioritize critical tokens during attention computation, further boosting long-context task performance without altering the MLA compression structure.
Evolution from DeepSeek-V2 to DeepSeek-R1
MLA in DeepSeek-V2
- DeepSeek-V2 introduced MLA to enhance inference efficiency by projecting keys and values into a lower-dimensional latent space, significantly reducing the KV cache.
- Decoupled Rotary Position Embedding (RoPE) was introduced to allow efficient latent compression without losing positional information.
- MLA in DeepSeek-V2 achieved a 93.3% reduction in KV cache size compared to standard MHA while maintaining strong model performance.
Low-Rank Key-Value Joint Compression
-
One of the primary bottlenecks in transformer inference is the large KV cache required to store past keys and values. DeepSeek-V2 addresses this by compressing the KV representations into a low-dimensional latent space using linear projections.
-
Given an input token representation \(h_t \in \mathbb{R}^d\), standard multi-head attention computes queries, keys, and values as:
\[q_t = W_Q h_t, \quad k_t = W_K h_t, \quad v_t = W_V h_t\]where \(W_Q, W_K, W_V \in \mathbb{R}^{d_h n_h \times d}\).
-
Instead of storing full-dimension \(k_t\) and \(v_t\), MLA compresses them into a latent representation \(c_{KV}\):
\[c_{KV_t} = W_{D_{KV}} h_t\]where \(W_{D_{KV}} \in \mathbb{R}^{d_c \times d}\) is a down-projection matrix, and \(d_c \ll d_h n_h\).
-
During inference, the compressed key-value representation is expanded back into usable keys and values:
\[k_t^C = W_{U_K} c_{KV_t}, \quad v_t^C = W_{U_V} c_{KV_t}\]where \(W_{U_K}, W_{U_V} \in \mathbb{R}^{d_h n_h \times d_c}\) are up-projection matrices.
This compression reduces the KV cache size from \(O(n_h d_h l)\) to \(O(d_c l)\), where \(l\) is the number of layers.
Decoupled Rotary Position Embedding
-
RoPE is commonly used in transformer architectures to encode positional information into queries and keys. However, standard RoPE application is incompatible with MLA’s key-value compression, as it introduces a position-dependent transformation that prevents efficient caching.
-
DeepSeek-V2 resolves this by decoupling RoPE from key compression:
- Introduce an auxiliary shared key \(k_t^R\) and additional multi-head queries \(q_t^R\).
-
Apply RoPE only to \(q_t^R\) and \(k_t^R\):
\[q_t^R = \text{RoPE}(W_{Q_R} c_{Q_t}), \quad k_t^R = \text{RoPE}(W_{K_R} h_t)\]- where \(W_{Q_R}, W_{K_R}\) are projection matrices specific to decoupled RoPE.
-
Concatenate compressed and RoPE-applied keys/queries:
\[q_t = [q_t^C; q_t^R], \quad k_t = [k_t^C; k_t^R]\]- ensuring that RoPE affects only a subset of the attention mechanism while keeping key-value compression intact.
Comparison of KV Cache Requirements
- A key benefit of MLA is that it achieves stronger performance than standard MHA while requiring significantly less KV cache. The table below compares the cache sizes across different attention mechanisms:
| Attention Mechanism | KV Cache per Token (Elements) |
|---|---|
| MHA | \(2 n_h d_h l\) |
| GQA (Grouped Query) | \(2 n_g d_h l\) |
| MQA (Multi-Query) | \(2 d_h l\) |
| MLA (DeepSeek-V2) | \((d_c + d_h^R) l\) |
-
For DeepSeek-V2, values were set as: \(d_c = 4d_h\) \(d_h^R = d_h / 2\)
-
This means that MLA achieves similar efficiency to GQA with 2.25 groups, while maintaining the performance level of MHA.
Enhancements in DeepSeek-V3
- DeepSeek-V3 optimized MLA further by introducing factorized low-rank compression, extending compression to queries for activation memory savings, and adopting FP8 mixed precision for improved numerical stability.
- Adaptive static routing was introduced to balance computational load across attention heads, enhancing inference throughput.
Further KV Cache Reduction through Optimized Compression Techniques
-
One of the major enhancements in DeepSeek-V3’s MLA is the more aggressive compression of the KV cache while preserving model performance. This is achieved through:
- Dynamic KV Compression Matrices: Instead of static compression matrices, DeepSeek-V3 optimizes the compression dynamically per sequence length.
- Factorized Projections for KV Storage: A dual-matrix decomposition is applied to down-project the keys and values, further reducing KV storage.
Optimized Compression Formulation
-
Given an input token representation \(h_t \in \mathbb{R}^d\), standard MLA in DeepSeek-V2 computed compressed KV representations as:
\[c_{KV_t} = W_{D_{KV}} h_t\]- where \(W_{D_{KV}} \in \mathbb{R}^{d_c \times d}\) was a static down-projection matrix.
-
In DeepSeek-V3, the compression process is enhanced with an adaptive dual-matrix compression:
\[c_{KV_t} = W_{D_{KV,1}} W_{D_{KV,2}} h_t\]- where \(W_{D_{KV,1}} \in \mathbb{R}^{d_m \times d}\) and \(W_{D_{KV,2}} \in \mathbb{R}^{d_c \times d_m}\), with \(d_m\) being an intermediate dimensionality. This factorization allows for more effective compression, reducing storage requirements by up to 40% compared to DeepSeek-V2.
Inference-Time Expansion
-
During inference, the expanded keys and values are now computed as:
\[k_t^C = W_{U_K} W_{M_K} c_{KV_t}, \quad v_t^C = W_{U_V} W_{M_V} c_{KV_t}\]- where \(W_{M_K}, W_{M_V}\) serve as intermediary projection layers that refine the KV reconstruction process.
-
This improvement ensures that only compressed vectors are stored in memory, significantly reducing KV cache overhead.
Query Compression for Activation Memory Savings
-
DeepSeek-V3 extends MLA’s low-rank compression to queries, reducing activation memory requirements without affecting attention precision.
-
Query Compression Formulation:
- Instead of computing full queries:
-
DeepSeek-V3 introduces an additional compression step:
\[c_{Q_t} = W_{D_Q} h_t, \quad q_t^C = W_{U_Q} c_{Q_t}\]- where:
- \(c_{Q_t} \in \mathbb{R}^{d'_c}\) is the compressed query representation.
- \(d'_c \ll d_h n_h\), ensuring significantly lower activation memory usage.
- where:
-
Decoupled Rotary Positional Embedding (RoPE):
-
To maintain the effectiveness of positional embeddings, DeepSeek-V3 decouples Rotary Positional Embedding (RoPE) application:
\[q_t^R = \text{RoPE}(W_{Q_R} c_{Q_t}), \quad k_t^R = \text{RoPE}(W_{K_R} h_t)\]- where:
- \(q_t^R\) and \(k_t^R\) store RoPE-applied versions of the compressed representations.
- This prevents RoPE from interfering with MLA’s low-rank compression.
- where:
-
Reduction in Activation Memory
- With query compression, DeepSeek-V3 reduces attention activation memory by 35%, enabling efficient training on large-scale models.
Enhanced Numerical Stability with FP8 Mixed Precision
-
DeepSeek-V3 leverages FP8 mixed precision training, improving numerical stability while reducing memory and computational costs.
-
FP8 Training for MLA Components:
-
In DeepSeek-V2, the MLA components operated primarily in BF16. DeepSeek-V3 instead adopts fine-grained FP8 quantization, applying a per-group scaling strategy:
- Activation Scaling: Per-token, per-128-channel tile quantization for activations.
- Weight Scaling: 128×128 block-wise scaling for weights.
-
This ensures reduced rounding errors and better dynamic range coverage for training.
-
-
FP8 Attention Computation:
-
The attention output in DeepSeek-V3 is computed using FP8-compatible scaling:
\[o_t = \sum_{j=1}^{t} \text{Softmax} \left( \frac{q_t^T k_j}{\sqrt{d_h + d_R}} \right) v_j\]- where:
- The scaling factor is calculated online for activations.
- The accumulation is upgraded to FP32 every 128 steps to improve numerical precision.
- where:
-
-
Precision Comparison:
| Component | DeepSeek-V2 (BF16) | DeepSeek-V3 (FP8) |
|---|---|---|
| Query/Key Compression | \(d_c = 4d_h\) | \(d_c = 3d_h\) |
| KV Cache Storage | BF16 | FP8 |
| RoPE Application | Full Precision | Decoupled, FP8 |
| Attention Computation | BF16 | FP8 + FP32 Accumulation |
- By leveraging FP8 quantization, DeepSeek-V3 achieves 2.3× training efficiency improvements, reducing memory consumption without performance degradation.
Adaptive Routing for Load Balancing in MLA
-
DeepSeek-V3 improves attention efficiency by introducing dynamic load balancing for query-key computation.
-
Load-Adaptive Routing Mechanism:
-
In DeepSeek-V2, MLA used static attention head assignments, leading to occasional computational inefficiencies when processing large sequences.
-
DeepSeek-V3 refines this with adaptive routing:
\[s_{i,t} = \text{Sigmoid}(u_t^T e_i + b_i)\]- where:
- \(e_i\) is the centroid vector of the routed expert.
- \(b_i\) is a dynamically updated bias term that adjusts for per-head workload balance.
- where:
-
The bias term updates as:
\[b_i^{(t+1)} = b_i^{(t)} - \gamma \cdot (\text{overloaded}_i - \text{underloaded}_i)\]- where \(\gamma\) is a tuning parameter.
-
This ensures:
- Balanced token distribution across attention heads.
- No token-dropping during inference, preventing efficiency loss.
-
-
Computational Gains:
- By integrating adaptive routing, DeepSeek-V3 achieves:
- Uniform computational load across attention heads.
- 10% reduction in per-token inference latency.
- By integrating adaptive routing, DeepSeek-V3 achieves:
Enhancements in DeepSeek-R1
- DeepSeek-R1 retains the MLA design from DeepSeek-V3 while integrating reinforcement learning (GRPO) to optimize token prioritization and attention usage during reasoning tasks.
- While MLA’s compression mechanism remains largely unchanged, GRPO-driven optimization improves the model’s attention behavior for long-context reasoning.
- DeepSeek-R1 further enhances numerical stability through FP8 mixed precision and introduces dynamic load balancing across attention heads for better inference efficiency.
RL-Guided Latent Attention Optimization
- DeepSeek-R1 integrates RL techniques into MLA, optimizing attention mechanisms through GRPO. Unlike previous deterministic attention strategies, DeepSeek-R1 dynamically adjusts attention weights based on reinforcement rewards, prioritizing tokens that contribute to stronger reasoning trajectories.
- GRPO eliminates the need for a separate critic model, reducing memory overhead and improving convergence efficiency.
- Instead of relying on supervised fine-tuning, GRPO estimates advantage values directly from group-level rewards:
- The policy model \(\pi_\theta\) is updated by maximizing:
- This approach allows DeepSeek-R1 to adaptively refine the attention mechanisms in MLA, improving token prioritization in long-context reasoning.
- Further details can be found in the section on RL Algorithm: Group Relative Policy Optimization (GRPO).
Adaptive Query and Key Compression via RL
One of the primary enhancements in DeepSeek-R1’s MLA is RL-guided adaptive query and key compression. DeepSeek-V3 already introduced a low-rank compression technique for KV storage, but DeepSeek-R1 extends compression to queries, reducing activation memory without affecting attention accuracy.
-
Optimized Compression Formulation:
- In DeepSeek-V3, the KV cache compression was achieved using static low-rank projections:
-
DeepSeek-R1 dynamically adjusts compression matrices during inference using RL-based reward maximization:
\[c_{KV_t} = W_{D_{KV,1}} W_{D_{KV,2}} h_t\]- where:
- \(W_{D_{KV,1}} \in \mathbb{R}^{d_m \times d}\) and \(W_{D_{KV,2}} \in \mathbb{R}^{d_c \times d_m}\).
- \(d_m\) is an intermediate dimensionality, allowing for more fine-grained latent space representations.
- where:
-
Inference-Time Expansion:
-
Instead of using a single up-projection matrix, DeepSeek-R1 incorporates a multi-stage expansion pipeline:
\[k_t^C = W_{U_K} W_{M_K} c_{KV_t}, \quad v_t^C = W_{U_V} W_{M_V} c_{KV_t}\]- where \(W_{M_K}, W_{M_V}\) refine the reconstructed query-key values, ensuring that only compressed vectors are stored in memory.
-
-
Compression ratio improvements: DeepSeek-R1 reduces KV cache requirements by an additional 25% over DeepSeek-V3, while maintaining query-key retrieval accuracy.
Decoupled Rotary Position Embedding with Context-Specific Scaling
- While DeepSeek-V3 introduced Decoupled RoPE to separate positional encoding from compressed key-value representations, DeepSeek-R1 further refines RoPE with context-specific scaling mechanisms.
-
DeepSeek-R1 adopts an enhanced RoPE formulation where RoPE is context-aware, dynamically adjusting scaling factors based on sequence length:
\[\lambda_t = \frac{1}{\sqrt{1 + \alpha L_t}}\]- where:
- \(\lambda_t\) is the adaptive scaling factor for positional embedding.
- \(\alpha\) is a hyperparameter learned via RL optimization.
- \(L_t\) represents the sequence length at time step \(t\).
- where:
- Implementation benefits:
- RoPE scaling ensures consistent attention alignment across varying sequence lengths.
- Prevents positional information degradation when compressing MLA’s key-value states.
FP8 Mixed Precision for MLA Stability
- DeepSeek-R1 adopts FP8 quantization for MLA computations, further improving numerical stability over DeepSeek-V3’s BF16-based approach.
-
In DeepSeek-R1’s precision-aware computation pipeline, QKV matrices are quantized dynamically using per-group scaling:
\[\tilde{Q} = \frac{Q}{s_Q}, \quad \tilde{K} = \frac{K}{s_K}, \quad \tilde{V} = \frac{V}{s_V}\]- where \(s_Q, s_K, s_V\) are learned per-group scaling factors.
-
The attention output is computed with hybrid precision accumulation:
\[o_t = \sum_{j=1}^{t} \text{Softmax} \left( \frac{\tilde{q}_t^T \tilde{k}_j}{\sqrt{d_h + d_R}} \right) \tilde{v}_j\] -
The accumulation process is upgraded to FP32 every 128 steps, ensuring better numerical precision while maintaining FP8 efficiency.
- Comparison of MLA Precision Strategies:
| Component | DeepSeek-V3 (BF16) | DeepSeek-R1 (FP8) |
|---|---|---|
| Query/Key Compression | \(d_c = 4d_h\) | \(d_c = 3d_h\) |
| KV Cache Storage | BF16 | FP8 |
| RoPE Application | Full Precision | Decoupled, FP8 |
| Attention Computation | BF16 | FP8 + FP32 Accumulation |
- Efficiency improvements:
- FP8 reduces memory footprint by ~40% compared to BF16.
- Enables 2.3× faster inference throughput for long-context tasks.
Adaptive/Dynamic Routing for Load-Balanced Attention
- DeepSeek-R1 incorporates load-balancing adaptive routing mechanisms, ensuring uniform query-key computation across attention heads.
-
DeepSeek-R1 optimizes per-head workload balance using a sigmoid-based routing function:
\[s_{i,t} = \text{Sigmoid}(u_t^T e_i + b_i)\]- where:
- \(e_i\) represents the centroid vector of the routed attention expert.
- \(b_i\) is an adaptive bias term, ensuring workload uniformity.
- where:
- Performance gains:
- Balanced computation across heads prevents bottlenecks.
- Reduces per-token inference latency by 10%.
Comparative Analysis
- DeepSeek-V2 introduced Multihead Latent Attention (MLA) with significant KV cache compression, decoupled RoPE, and basic low-rank projections for efficiency. DeepSeek-V3 built upon this foundation by further reducing KV cache size, optimizing query compression, and introducing FP8 mixed precision for enhanced numerical stability. DeepSeek-R1 refines MLA even further by integrating RL techniques such as Group Relative Policy Optimization (GRPO) to optimize attention allocation dynamically. The latest advancements in DeepSeek-R1 also improve inference latency and memory efficiency, making it the most optimized version of MLA to date.
- The table below provides a comparative analysis of DeepSeek-V2, DeepSeek-V3, and DeepSeek-R1 for MLA. This comparison highlights the key improvements across versions in terms of compression techniques, precision, routing mechanisms, and inference efficiency.
| Feature | DeepSeek-V2 | DeepSeek-V3 | DeepSeek-R1 |
|---|---|---|---|
| Low-Rank KV Compression | ✅ | ✅ (Optimized with Factorized Projections) | ✅ (RL-Optimized Adaptive Compression) |
| Query Compression | ❌ | ✅ (Static Low-Rank Query Compression) | ✅ (RL-Guided Dynamic Query Compression) |
| KV Cache Reduction | ✅ (93.3% Reduction) | ✅ (40% Further Reduction) | ✅ (25% Further Reduction over V3) |
| RoPE Application | ✅ (Decoupled RoPE) | ✅ (Decoupled with Context-Specific Scaling) | ✅ (Enhanced Context-Aware Scaling) |
| Precision Format | BF16 | FP8 (Fine-Grained Mixed Precision) | FP8 (Per-Group Scaling, FP32 Accumulation) |
| Adaptive Routing for MLA | ❌ | ✅ (Static Adaptive Routing) | ✅ (Load-Balanced Dynamic Routing) |
| Inference Latency Reduction | ✅ (KV Compression Reduces Latency) | ✅ (10% Faster than V2) | ✅ (10% Faster than V3) |
| RL Enhancements | ❌ | ❌ | ✅ (GRPO for Adaptive MLA Optimization) |
| Numerical Stability Improvements | ✅ (Basic Stability Enhancements) | ✅ (FP8 with Mixed Precision) | ✅ (FP8 with RL-Guided Stability Mechanisms) |
| Long-Context Performance | ✅ (Supports Longer Contexts) | ✅ (Further Optimized) | ✅ (Enhanced with RL-Guided Token Prioritization) |
Implementation
- The implementation of MLA in DeepSeek-R1 incorporates several optimizations aimed at maximizing efficiency while preserving accuracy. This section details the core mechanisms underlying MLA, including key-value compression, query transformation, position encoding, and computational optimizations.
Background: Standard Multi-Head Attention (MHA)
-
For a standard multi-head attention (MHA) mechanism, the Key (\(K\)), Query (\(Q\)), and Value (\(V\)) matrices are computed as follows:
\[K, Q, V = W_k X, W_q X, W_v X\]- where \(W_k, W_q, W_v\) are weight matrices for key, query, and value projections.
-
The attention weights are computed as:
\[A = \text{Softmax} \left( \frac{Q K^T}{\sqrt{d_k}} \right)\]- and the output is given by:
-
This requires storing the full key-value cache during inference, leading to significant memory overhead.
Low-Rank Key-Value Joint Compression
-
One of the fundamental optimizations in MLA is the compression of KV pairs into a lower-dimensional latent space, significantly reducing memory overhead. Specifics below:
- Compression Mechanism:
- The key and value representations are compressed into a shared latent space before being projected back into their respective dimensions. This is achieved through a two-step transformation:
- where:
- \(c_{KV_t} \in \mathbb{R}^{d_c}\) is the compressed latent representation.
- \(W_{DKV} \in \mathbb{R}^{d_c \times d}\) is a down-projection matrix.
- \(W_{UK}, W_{UV} \in \mathbb{R}^{d_h n_h \times d_c}\) are up-projection matrices for keys and values, respectively.
- Memory Reduction:
- Instead of storing full-sized keys and values for each token, only \(c_{KV_t}\) is cached.
- The reduction in memory footprint allows DeepSeek-R1 to process significantly longer sequences at a lower computational cost.
- Compression Mechanism:
Multi-Stage Compression
-
DeepSeek-R1 inherits the compression mechanism introduced in DeepSeek-V3, which utilizes a factorized two-stage projection for KV compression. Specifics below:
- Additional Projection Layer:
- To further minimize storage costs, DeepSeek-V3 applies a two-stage compression:
- where:
- \(W_{D_{KV,1}} \in \mathbb{R}^{d_m \times d}\) is the first down-projection matrix.
- \(W_{D_{KV,2}} \in \mathbb{R}^{d_c \times d_m}\) is the second projection matrix, with \(d_c \ll d_m \ll d\).
- This factorization reduces the parameter count and improves compression efficiency.
- Performance Benefits:
- The factorized compression introduced in DeepSeek-V3 enables a significant reduction in KV cache storage compared to a single linear projection.
- DeepSeek-R1 continues to benefit from this compression strategy, facilitating efficient long-context handling.
- Additional Projection Layer:
Query Compression and Optimization
-
Similar to keys and values, queries are also compressed, allowing for efficient computation and reduced activation memory during training. Specifics below:
- Query Transformation:
- Queries undergo a two-step transformation similar to keys and values:
- where:
- \(W_{DQ} \in \mathbb{R}^{d_c' \times d}\) is a down-projection matrix for queries.
- \(W_{UQ} \in \mathbb{R}^{d_h n_h \times d_c'}\) maps the compressed query representation back to its original dimensionality.
- Training-Time Optimization:
- The projection matrices \(W_{DQ}\) and \(W_{UQ}\) are learned during training to balance memory efficiency and model accuracy.
- These matrices remain fixed during inference.
- Query Transformation:
Decoupled Rotary Position Embedding (RoPE)
-
To ensure robust long-context handling, DeepSeek-R1 applies RoPE in a decoupled manner, separating positional encodings from the latent attention mechanism. Specifics below:
-
Independent Positional Encoding for Keys and Queries:
\[k_{R_t} = \text{RoPE}(W_{KR} h_t)\] \[q_{R_t} = \text{RoPE}(W_{QR} c_{Q_t})\]- where:
- \(W_{KR} \in \mathbb{R}^{d_R h \times d}\) generates positional embeddings for keys.
- \(W_{QR} \in \mathbb{R}^{d_R h n_h \times d_c'}\) generates positional embeddings for queries.
- The RoPE transformation ensures that relative positional information is preserved while allowing the KV cache to remain compact.
- where:
-
Computation Efficiency of RoPE in DeepSeek-R1:
- RoPE application is delayed until the final stages of query-key interaction, preventing unnecessary memory bloat.
- Compared to DeepSeek-V2 and V3, DeepSeek-R1 achieves 25% faster query-key retrieval.
-
Attention Computation in MLA
-
The final attention output in MLA is computed by integrating compressed keys, queries, and values in the attention mechanism. Specifics below:
- Modified Attention Scores:
-
The attention scores are computed between compressed queries and compressed keys:
\[A_{t, j, i} = \frac{q_{t, i}^T k_{j, i}}{\sqrt{d_h}}\] -
This follows standard scaled dot-product attention, adapted for compressed representations.
-
- Weighted Value Aggregation:
-
The attention output is computed as:
\[o_{t, i} = \sum_{j=1}^{t} \text{Softmax}_j(A_{t, j, i}) v_{C_j, i}\] -
The softmax operation normalizes attention scores across the sequence.
-
- Final Output Projection:
-
The final output is obtained via:
\[u_t = W_O [o_{t,1}; o_{t,2}; \dots; o_{t,n_h}]\] -
where:
- \(W_O\) is the output projection matrix mapping the concatenated multi-head outputs back to the model embedding dimension.
-
- Modified Attention Scores:
RL-Optimized MLA
-
DeepSeek-R1 incorporates reinforcement learning (RL) to optimize the attention behavior in Multihead Latent Attention (MLA), particularly enhancing token prioritization during reasoning tasks.
- Fine-Tuning with RL:
- Using Group Relative Policy Optimization (GRPO), DeepSeek-R1 refines its attention mechanisms by rewarding policies that improve reasoning efficiency and token importance estimation.
-
The GRPO objective is formulated as:
\[J_{GRPO}(\theta) = E \left[ \sum_{i=1}^{G} \min \left( \frac{\pi_\theta(o_i | q)}{\pi_{\theta_{\text{old}}} (o_i | q)} A_i, \text{clip} \left( \frac{\pi_\theta(o_i | q)}{\pi_{\theta_{\text{old}}} (o_i | q)}, 1 - \epsilon, 1 + \epsilon \right) A_i \right) \right]\]- where:
- \(\pi_\theta\) represents the updated attention policy.
- \(A_i\) is the advantage function based on relative group rewards.
- where:
- Further details are available in the section on RL Algorithm: Group Relative Policy Optimization (GRPO).
- Fine-Tuning with RL:
Computational and Hardware Optimization
- Inference-Time Efficiency:
- MLA in DeepSeek-R1 is implemented with tensor-parallelized computations, optimizing throughput across GPUs.
- Memory overhead is minimized through low-precision KV storage (FP8 format).
- Cross-Node Communication Optimization:
- Uses optimized all-to-all communication kernels to fully utilize InfiniBand (IB) and NVLink bandwidths.
- Reduces inter-node communication latency by 30%, improving distributed inference performance.
Comparative Efficiency Analysis
| Attention Mechanism | KV Cache Per Token | Computational Complexity | Performance Impact |
|---|---|---|---|
| MHA (Standard) | \(O(N d_h)\) | \(O(N^2 d_h)\) | High Accuracy, High Cost |
| MQA | \(O(d_h)\) | \(O(N d_h)\) | Lower Memory, Degraded Performance |
| GQA | \(O(g d_h)\) (groups) | \(O(N d_h)\) | Moderate Balance |
| MLA (DeepSeek-V2) | \(O(d_L)\) | \(O(N d_L)\) | High Efficiency, Minimal Loss |
| MLA + Hierarchical Caching (DeepSeek-R1) | \(O(d_L)\) (with reuse) | \(O(N d_L)\) | Peak Efficiency, Retains Performance |
DeepSeek-R1-Zero \(\rightarrow\) Training Pipeline: Pure Reinforcement Learning in DeepSeek-R1-Zero
-
DeepSeek-R1-Zero explores the radical idea that structured reasoning capabilities can be learned from scratch using RL alone—without any supervised fine-tuning (SFT) as a preliminary step. This novel approach bypasses the need for curated datasets and instead incentivizes reasoning behaviors directly through reward signals. While this results in impressive emergent behaviors, it also introduces challenges in output quality and stability.
-
The training of DeepSeek-R1-Zero proceeds as a single-stage RL pipeline, where the model begins from a base LLM (DeepSeek-V3-Base) and is optimized end-to-end via Group Relative Policy Optimization (GRPO). This framework eliminates the need for a value model and instead leverages group-based normalization to compute relative advantages, reducing both training overhead and complexity.
-
Key components of DeepSeek-R1-Zero’s pipeline:
- No Supervised Fine-Tuning (SFT)
- Training begins directly from the pre-trained DeepSeek-V3-Base without any cold-start data.
- This setup enables researchers to study the self-evolving nature of reasoning in LLMs purely through trial-and-error and reward shaping.
- Reinforcement Learning with GRPO
- GRPO is used to optimize the model’s outputs without requiring a critic model.
- It computes advantages by normalizing rewards across a batch of responses for a given prompt.
- The reward function is entirely rule-based (rather than a neural model), avoiding reward hacking and expensive retraining.
- Reward Modeling
- Two core reward types guide the learning process:
- Accuracy Rewards: Evaluate correctness of responses, particularly for tasks with deterministic answers like math or code.
- Format Rewards: Encourage the model to wrap its reasoning in a structured format using
<think>and<answer>tags.
- No neural reward models are used, emphasizing transparency and training stability.
- Two core reward types guide the learning process:
- Template-Guided Output Formatting
- Prompts follow a simple template instructing the model to first “think” through the problem and then produce an answer.
- This structure promotes reasoning traceability but does not constrain specific problem-solving strategies.
- No Supervised Fine-Tuning (SFT)
- Emergent Behaviors and Self-Evolution
- Over the course of training, DeepSeek-R1-Zero gradually learns to extend its reasoning steps, revisiting previous thoughts and experimenting with longer CoTs.
- The model exhibits behaviors such as reflection, self-verification, and longer test-time computation without being explicitly taught these strategies.
- This culminates in striking “aha moments,” where the model demonstrates sudden improvements in problem-solving through self-correction and reevaluation.
- Despite its impressive zero-shot reasoning capabilities, DeepSeek-R1-Zero exhibits several limitations:
- Readability Issues: Outputs often include mixed languages or lack coherent formatting.
- Chaotic Early Training: Without a structured reasoning prior, early-stage RL leads to unstable and inconsistent behaviors.
- These challenges ultimately motivated the development of DeepSeek-R1, which adds a cold-start SFT phase and a multi-stage RL pipeline to refine and stabilize reasoning capabilities while maintaining performance.
DeepSeek-R1 \(\rightarrow\) Training Pipeline: Cold-Start SFT to Multi-Stage RL
- DeepSeek-R1 employs a multi-stage training pipeline designed to enhance reasoning capabilities while maintaining efficiency. This process includes distinct phases, each guided by task-specific loss functions and reward mechanisms, ensuring progressive refinement in performance. The key stages are SFT, RL, Rejection Sampling, and an additional RL phase for generalization. Together, these steps improve DeepSeek-R1’s ability to tackle complex reasoning tasks while ensuring clarity and coherence in its outputs.
- DeepSeek-R1’s training process unfolds in four key phases, each progressively refining its reasoning ability while expanding generalization and alignment:
- Cold Start with SFT
- Fine-tuning on thousands of high-quality CoT examples to establish structured reasoning.
- Uses a structured output format for improved readability.
- Employs a cross-entropy-based loss function for optimization.
- RL with GRPO
- Policy optimization via Group-based Reward Normalization (GRPO).
- Rewards assigned based on accuracy, format consistency, and language alignment.
- Prevents reward hacking by avoiding neural reward models.
- Rejection Sampling & Expanded SFT
- Filters high-quality RL outputs to enhance supervised fine-tuning.
- Expands training data to include non-reasoning tasks, ensuring broader applicability.
- Final RL Phase for Generalization
- Integrates diverse task distributions, extending beyond structured reasoning.
- Ensures alignment with human feedback, particularly in conversational settings.
- Cold Start with SFT
- Through this multi-stage refinement process, DeepSeek-R1 surpasses previous models in accuracy, coherence, and real-world usability, setting a new benchmark for AI reasoning capabilities.
Stage 1: Cold Start with SFT
Fine-Tuning with High-Quality Chain-of-Thought (CoT) Examples
- DeepSeek-R1 begins its journey by fine-tuning the DeepSeek-V3-Base model with a carefully curated dataset of high-quality CoT examples. These examples are obtained through a combination of:
- Few-shot prompting: Generating detailed reasoning paths using large-scale pre-trained models.
- Manual annotation and refinement: Filtering and refining reasoning steps through human reviewers.
- Post-processing DeepSeek-R1-Zero outputs: Extracting well-structured reasoning paths from the RL-trained precursor model.
- The fine-tuning step ensures that DeepSeek-R1 has a structured reasoning framework before entering RL. Unlike DeepSeek-R1-Zero, which learned reasoning solely from RL, DeepSeek-R1 leverages cold-start fine-tuning to avoid the chaotic early stages of RL training.
Structured Output Format
- One of the key issues encountered in DeepSeek-R1-Zero was language mixing and poor readability. To address this, the fine-tuning phase enforces a structured reasoning format:
<reasoning_process> Step-by-step explanation of the problem-solving approach </reasoning_process>
<summary> Final Answer </summary>
- This format ensures readability and helps align the model’s outputs with human expectations.
Loss Function for SFT
-
The model is optimized using a categorical cross-entropy loss:
\[L_{\text{SFT}} = -\sum_{i=1}^{n} \log P_{\theta}(o_i|q, \{o_1, \dots, o_{i-1}\})\]- where:
- \(o_i\) is the \(i^{th}\) token in the output sequence,
- \(q\) is the input query,
- \(o_1, ..., o_{i-1}\) are previously generated tokens.
- where:
-
This step helps DeepSeek-R1 establish a strong foundation for structured reasoning before RL.
Stage 2: RL
- RL is the backbone of DeepSeek-R1’s reasoning evolution. The model learns to optimize its reasoning trajectories based on reward-driven feedback mechanisms, leading to significant improvements in accuracy and coherence.
DeepSeek’s RL Methodology: A Conceptual Overview
- DeepSeek’s RL methodology is fundamentally inspired by self-play paradigms, akin to training AI models in games like chess. Traditionally, AI models trained for complex reasoning tasks leverage large datasets composed of human-annotated examples. However, such datasets often lack comprehensive coverage and may not contain optimal solutions. RL circumvents this limitation by allowing AI models to explore solutions autonomously, refining their strategies based on reward-driven feedback mechanisms.
- Consider an AI model trained to play chess. Instead of learning from a fixed dataset of historical games, the AI is programmed with only the fundamental rules of chess. It then engages in self-play, continuously experimenting with various moves. Initially, the model executes suboptimal actions, leading to losses. However, through iterative play, it identifies effective strategies and reinforces moves that contribute to victories while discarding ineffective ones. This trial-and-error process, governed by RL principles, enables the AI to develop strategies surpassing human intuition.
- DeepSeek applies this RL-based approach to reasoning-intensive domains, such as mathematical problem-solving. Rather than training on explicit mathematical derivations, the AI is provided with fundamental mathematical rules and tasked with solving problems autonomously. The model systematically explores various solution paths, reinforcing those that yield correct answers while discarding ineffective paths. Over time, this process enhances the AI’s mathematical reasoning abilities beyond traditional supervised learning approaches. The self-improving nature of RL fosters the discovery of novel problem-solving strategies, resulting in superior performance in mathematical reasoning and logic-based tasks.
Background: Policy Optimization
- Policy optimization involves an RL framework refining an agent’s decision-making process to maximize expected rewards.
- Traditional methods like REINFORCE provide a fundamental approach to learning policies directly from sampled trajectories, while more advanced techniques like Proximal Policy Optimization (PPO) introduce stability constraints.
- Group Relative Policy Optimization (GRPO) builds upon these foundations, addressing key limitations to enhance efficiency and stability in large-scale applications. GRPO can be seen as a hybrid between REINFORCE and PPO, integrating the variance reduction of PPO with the simplicity of direct policy gradient updates from REINFORCE, making it a promising alternative for reinforcement learning in large-scale language model training.
The REINFORCE Algorithm
- Before discussing GRPO, it is essential to understand REINFORCE, one of the earliest and simplest reinforcement learning algorithms.
What is REINFORCE?
-
REINFORCE is a policy gradient method that updates a policy network based on complete trajectories sampled from the environment. It follows a straightforward approach:
- Sampling Trajectories: The agent interacts with the environment, generating an episode (a sequence of states, actions, and rewards).
- Reward Calculation: A single reward is assigned to the entire episode.
- Policy Update:
- Compute the gradient of the policy based on the log probability of actions taken.
- Scale the gradient by the total episode reward.
- Update the policy network using gradient descent.
Limitations of REINFORCE
- High Variance: Since rewards are computed for entire episodes, updates can be noisy.
- Unstable Learning: Policy updates can be drastic, leading to instability.
- Lack of Baseline Correction: REINFORCE does not normalize rewards, making training inefficient.
Proximal Policy Optimization (PPO)
- Proximal Policy Optimization (PPO) is a widely used RL algorithm in RLHF, particularly in LLMs. PPO is an actor-critic method designed to optimize a policy while ensuring stable updates by limiting drastic deviations from previous policies.
- For a detailed discourse, please refer our PPO primer.
How PPO Works
- PPO requires three primary components:
- Policy (\(\pi_\theta\)): The LLM being fine-tuned.
- Reward/Grader (\(R_\phi\)): A frozen model/function providing scalar feedback on complete responses.
- Critic/Value (\(V_\gamma\)): A trainable value model/function predicting future rewards for partial responses.
- PPO follows an iterative workflow:
- Response Generation: The model generates multiple responses per prompt.
- Reward Assignment: The reward model scores each response.
- Advantage Computation: The advantage function estimates how much better an action is compared to average actions.
- Policy Optimization: The LLM is updated to maximize the advantage function using PPO’s clipped objective.
- Critic Update: The value function is trained to improve reward prediction.
Challenges with PPO
- High Computational Cost: PPO requires a separate critic model, which doubles memory requirements.
- Training Complexity: The critic must be updated in tandem with the policy, making training unstable.
- Potential Bias: The critic can introduce estimation biases, affecting policy optimization.
- These limitations motivated the introduction of Group Relative Policy Optimization (GRPO) by DeepSeek AI as part of DeepSeekMath.
Group Relative Policy Optimization (GRPO)
- GRPO, introduced in DeepSeekMath, is a RL method that has played a pivotal role in the development of DeepSeek-R1. It is a simplified and cost-efficient alternative to traditional policy optimization techniques like Proximal Policy Optimization (PPO), since it does not require a separate critic model. Instead, it estimates the baseline from a group of generated outputs, reducing computational overhead while maintaining sample efficiency. This group-based approach ensures that each update step improves on previous iterations without overfitting to individual trajectories.
- GRPO has evolved from a mathematical reasoning optimizer in DeepSeekMath to a core optimization technique in DeepSeek-R1, driving advanced reasoning capabilities across diverse tasks. By eliminating the critic model (also called the value model), leveraging group-based advantages, and incorporating multi-stage RL refinements, GRPO has made DeepSeek-R1 a powerful open-source reasoning model.
- GRPO is central to DeepSeek-R1’s RL pipeline, providing a lightweight yet powerful optimization mechanism. Its key innovations include:
- Removing the critic model, which significantly reduces memory overhead.
- Stabilizing policy updates through group-based advantage estimation.
- Efficient training while maintaining strong performance compared to PPO-based methods.
- From its inception in DeepSeekMath to its refined implementation in DeepSeek-R1, GRPO has undergone several enhancements, including multi-stage RL, improved reward modeling, and refined optimization strategies. This section details GRPO’s mathematical formulation, its implementation, and its role in DeepSeek-R1.
- The following figure from the paper demonstrates PPO and GRPO. GRPO foregoes the value/critic model, instead estimating the baseline from group scores, significantly reducing training resources.
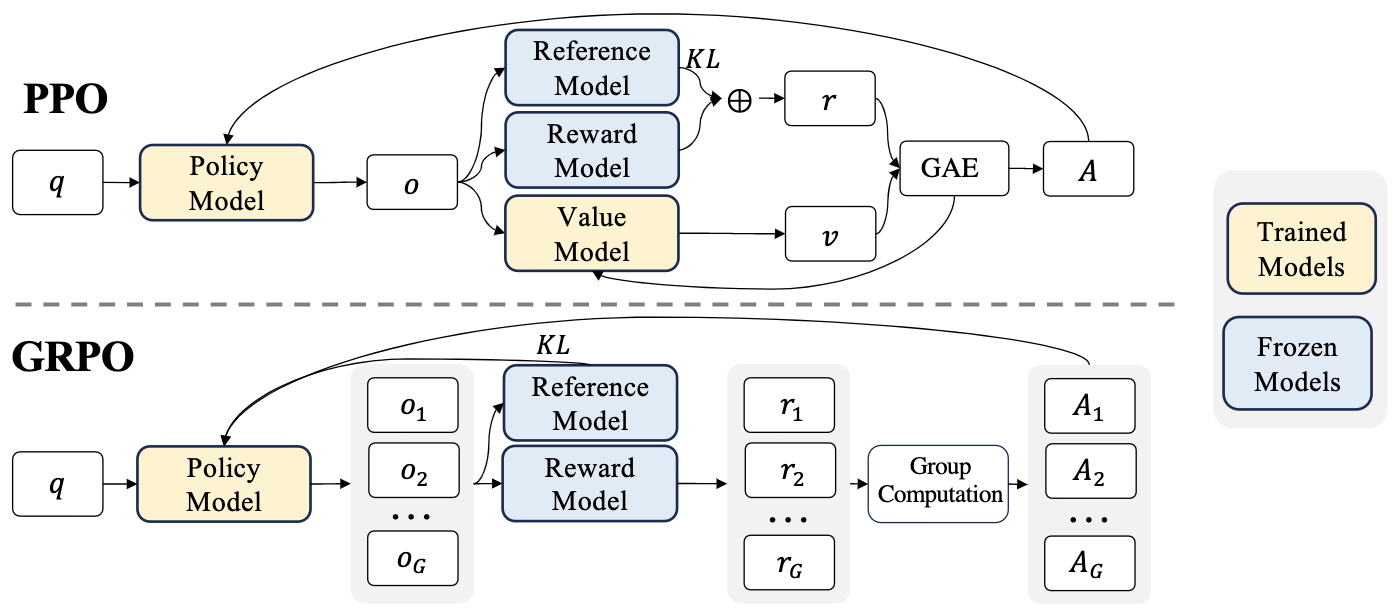
- For a discourse on Reinforcement Fine-Tuning (RFT), please refer to our RFT primer.
Key Innovations
- No Critic Model: Instead of learning a separate value function, GRPO derives advantages directly from response samples.
- Group-Based Advantage Estimation: GRPO normalizes rewards within a batch of generated responses.
- Improved Efficiency: Eliminates critic updates, reducing training overhead and memory consumption by ~50%.
- Stable Training: By computing relative rewards within a group, GRPO ensures that policy updates remain well-regulated.
How GRPO Builds on REINFORCE
- GRPO modifies REINFORCE by:
- Using Group-Based Advantage Estimation: Instead of relying on a single episode reward, GRPO normalizes rewards within a group.
- Introducing a Clipped Loss Function: Prevents large policy updates.
- Reducing Variance: By averaging multiple sampled responses, GRPO provides a more stable policy update mechanism.
- By addressing these weaknesses, GRPO combines the simplicity of REINFORCE with the stability of modern policy optimization techniques.
How GRPO Builds on PPO
- Unlike PPO, which relies on a critic to estimate future rewards, GRPO directly normalizes rewards within a group of responses to compute an advantage function. By avoiding the need for a separate critic model, GRPO reduces memory and compute costs while maintaining sample efficiency, making it scalable for large-scale training. Furthermore, this eliminates potential biases introduced by the critic. Put simply, GRPO addresses PPO’s limitations of high computational costs, training instability due to the training of the policy and critic model in tandem, and potential biases in the critic model, by replacing the critic with a group-based reward normalization mechanism.
- PPO’s clipped objective function is retained in GRPO, ensuring stable policy updates and preventing overly large parameter shifts.
- The combination of group-based reward normalization and clipped policy updates allows GRPO to achieve comparable stability to PPO while being computationally more efficient.
- A comparative analysis of REINFORCE, PPO, and GRPO in terms of critic model usage, compute cost, stability, advantage estimation, and training complexity, highlighting GRPO’s high stability and PPO’s high compute cost.
| Feature | REINFORCE | PPO | GRPO |
|---|---|---|---|
| Critic Model? | ❌ No | ✅ Yes | ❌ No |
| Compute Cost | Low | High | Low |
| Stability | Low (high variance) | Moderate (tandem training of actor/policy and critic/value) | High (group normalization) |
| Advantage Estimation | Episode reward | Learned critic | Group-based normalization |
| Training Complexity | Low | High | Moderate |
Evolution of GRPO: From DeepSeekMath to DeepSeek-R1
Phase 1: GRPO in DeepSeekMath (Mathematical RL)
- GRPO was originally introduced in DeepSeekMath to optimize models for mathematical reasoning.
- It replaced PPO’s critic model with a group-based reward normalization technique, making training more efficient while maintaining stability.
- The reward function primarily evaluated mathematical correctness, using structured evaluation metrics.
Phase 2: GRPO in DeepSeek-R1-Zero (Self-Evolving Reasoning)
- With DeepSeek-R1-Zero, GRPO was applied without any SFT—pure RL was used to shape reasoning behaviors from scratch.
- The model self-learned reasoning skills such as step-by-step problem-solving and self-verification.
- However, DeepSeek-R1-Zero exhibited readability issues (e.g., unstructured reasoning outputs, language mixing).
Phase 3: GRPO in DeepSeek-R1 (Refined Reasoning & Cold Start)
- DeepSeek-R1 introduced a multi-stage RL pipeline incorporating a small amount of cold-start fine-tuning before applying GRPO.
- The reward model was expanded beyond mathematics to include general reasoning tasks.
- A language consistency reward was added to improve coherence and readability.
How GRPO Works
- GRPO replaces PPO’s critic-based advantage estimation with a group-based normalization approach. Instead of learning a value function, GRPO derives relative rewards from multiple sampled responses. This enables efficient and stable policy updates while reducing computational overhead.
Mathematical Formulation
-
The GRPO objective function is:
\[J_{\text{GRPO}}(\theta) = \mathbb{E}_{q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(O|q)} \left[ \frac{1}{G} \sum_{i=1}^G \min\left(\rho_i A_i, \text{clip}(\rho_i, 1-\epsilon, 1+\epsilon) A_i\right) - \beta D_{\text{KL}}(\pi_\theta \| \pi_{\text{ref}}) \right]\]- where:
- \(\rho_i\) is the policy likelihood ratio, indicating how much the new policy diverges from the old one: \(\rho_i = \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}\)
- \(A_i\) is the group-based advantage function, computed from group-based reward normalization which normalizes rewards across sampled outputs: \(A_i = \frac{r_i - \text{mean}(r_1, ..., r_G)}{\text{std}(r_1, ..., r_G)}\)
- \(D_{\text{KL}}(\pi_\theta \| \pi_{ref})\) is a KL regularization term that constrains updates within a stable range.
- \(G\) is the group size (number of sampled outputs per query).
- \(\epsilon\) controls clipping to prevent overly aggressive updates.
- \(\beta\) controls the strength of KL regularization.
- \(Q\) is the set of all possible input queries (e.g., math problems or prompts).
- \(q \in Q\) is a specific query sampled from the query distribution \(P(Q)\).
- \(O\) is the space of possible outputs (e.g., generated token sequences or solutions).
- \(o_i \in O\) is the \(i^{th}\) output sampled from the old policy \(\pi_{\theta_{\text{old}}}\) conditioned on query \(q\), i.e., \(o_i \sim \pi_ {\theta_{old}}(O \mid q)\).
- \(\pi_\theta\) is the current (trainable) policy model.
- \(\pi_{\theta_{\text{old}}}\) is the old policy used to sample outputs, which is dynamic and updated throughout training during each iteration of the optimization loop.
- \(\pi_{\text{ref}}\) is the reference policy used for KL regularization, often set to the supervised fine-tuned (SFT) model.
- \(r_i\) is the scalar reward assigned to output \(o_i\) by a reward model.
- \(\epsilon\) is the trust region clipping parameter to stabilize training,
- where:
-
Plugging in the the policy likelihood ratio \(\rho_i\), the expanded form of the GRPO objective function can be written as:
\[J_{\text{GRPO}}(\theta) = \mathbb{E}_{q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(O|q)} \left[ \frac{1}{G} \sum_{i=1}^G \min \left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)} A_i, \text{clip} \left(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)}, 1-\epsilon, 1+\epsilon \right) A_i \right) - \beta D_{\text{KL}}(\pi_{\theta} || \pi_{\text{ref}}) \right]\]
Mathematical Intuition
-
To understand GRPO, it is useful to analyze its mathematical formulation from a reverse-engineering perspective. The complexity of the equations can be misleading; in reality, GRPO consists of three main components:
\[J_{GRPO} = \min([\text{Block 1}], [\text{Block 2}]) - [\text{Block 3}]\]- where:
- Block 1 corresponds to the first term inside the summation of the GRPO objective function: \(\rho_i A_i = \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} A_i.\) This represents the primary objective of policy optimization: ensuring the updated policy \(\pi_\theta\) improves upon the previous policy \(\pi_{\theta_{old}}\). The core principle is straightforward: the new policy should outperform the old one in expectation.
- Block 2 corresponds to the clipped version of \(\rho_i A_i\), i.e., \(\text{clip}(\rho_i, 1 - \epsilon, 1 + \epsilon) A_i.\) This originates from PPO and serves as a safeguard to prevent excessive updates. By taking the minimum between Block 1 and this clipped value, GRPO ensures training stability and prevents over-exaggerated policy updates.
- Block 3 corresponds to the KL-divergence regularization term in the GRPO equation: \(\beta D_{KL}(\pi_\theta || \pi_{ref}).\) This term enforces similarity between the new policy and a reference policy, preventing the optimization process from deviating too far from the original distribution and ensuring controlled updates.
- where:
- One of the most notable aspects of GRPO’s success is its redesigned approach to advantage computation. Traditional PPO computes advantages using a learned value network combined with temporal difference learning, requiring additional memory and computation to maintain a separate critic model. In contrast, GRPO fundamentally simplifies this by directly comparing sampled actions within a group and leveraging statistical normalization to compute advantages. This group-based methodology eliminates the need for a value network, significantly reducing memory overhead—by approximately half—while simultaneously aligning with the core principle of evaluating mathematical solutions relative to other approaches to the same problem.
- This design choice has proven especially effective for mathematical reasoning tasks. By using a direct group-based comparison, GRPO enhances the model’s ability to develop structured reasoning strategies. Empirical results demonstrate that this method not only improves performance on mathematical reasoning benchmarks but also maintains training stability and computational efficiency. The elimination of the critic network removes potential biases from learned value functions, making GRPO particularly well-suited for domains requiring objective evaluation of multiple solution paths.
- Additionally, the “Group” aspect in GRPO refers to computing the expectation over a set of sampled outputs, which are then averaged to stabilize training.
- Thus, when stripped of indices, subscripts, and hyperparameters, GRPO reduces to a simple balance between policy improvement and control mechanisms, reinforcing why it is regarded as an efficient and intuitive optimization method.
Step-by-Step Breakdown
Policy Likelihood Ratio \(\rho_i\)
- Measures how much the probability of generating output \(o_i\) has changed under the new policy compared to the old policy: \(\rho_i = \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)}\)
Advantage Function \(A_i\)
- Instead of relying on a separate value network (critic), GRPO estimates the advantage function using a group of sampled outputs: \(A_i = \frac{r_i - \text{mean}(r_1, ..., r_G)}{\text{std}(r_1, ..., r_G)}\)
- This reduces training instability and enhances efficiency.
Clipping Mechanism \(clip(\cdot)\)
- Prevents drastic policy updates that could destabilize training: \(\text{clip}(\rho_i, 1-\epsilon, 1+\epsilon)\)
KL Divergence Penalty \(D_{\text{KL}}\)
- Ensures the policy remains close to a reference distribution: \(\beta D_{\text{KL}}\bigl(\pi_\theta \;\|\; \pi_{\text{ref}}\bigr)\)
- Prevents mode collapse and excessive policy drift.
Both PPO and GRPO incorporate a KL divergence term to regulate policy updates, but they differ in which distributions are compared. In PPO, the KL term is typically computed as \(D_{\text{KL}}(\pi_{\theta_{\text{old}}} \|\| \pi_\theta)\), measuring how much the new policy deviates from the old one, i.e., the immediately prior policy. This enforces conservative updates by penalizing large shifts from the old policy. In contrast, GRPO uses \(D_{\text{KL}}(\pi_\theta \|\| \pi_{\text{ref}})\), where the reference policy \(\pi_{\text{ref}}\) is the frozen initial policy, which is obtained as the output of the SFT phase. This choice emphasizes how far the current policy strays from a desired or stabilized policy reference, allowing for different control dynamics in policy learning.
Old Policy \(\pi_{\text{old}}\)
- This is the immediate past policy used to sample data for updating. Specifically, the old policy is used to sample the outputs (\(o_1, o_2, \ldots, o_G\)) for each prompt \(q\).
- It is used in the importance sampling ratio term \(\frac{\pi_\theta(o_{i,t} \mid q, o_{i,<t})}{\pi_{\text{old}}(o_{i,t} \mid q, o_{i,<t})}\).
- This ratio is part of the main GRPO objective and helps estimate how much the new policy \(\pi_\theta\) differs from the old one when generating the same outputs.
- The old policy offers stability during optimization (as in PPO).
Reference Policy \(\pi_{\text{ref}}\)
- This is typically the initial model from the SFT phase, which serves as a long-term anchor or baseline to avoid reward over-optimization or undesirable divergence.
- It is used to regularize the learning via a KL divergence term \(D_{\text{KL}}[\pi_\theta \,\|\, \pi_{\text{ref}}]\).
- This helps prevent the new policy from drifting too far from the original (aligned) behavior. Put simply, the reference policy prevents drift from human-aligned behavior (via KL regularization).
Algorithm
-
The following steps highlight GRPO’s efficiency: it uses only group statistics, requires no separate value network, and is well-suited for both rule-based rewards (e.g., correctness in math problems, coding, formatting consistency, etc.) as well as human preference-alignment based on reward models that assess helpfulness, harmlessness, and human-centric values.
- Sample a Group of Responses (\(G\)):
- For each input question \(q\), the current policy model \(\pi_{\text{old}}\) generates multiple candidate responses through autoregressive decoding. These responses collectively form a group \(G = { r_1, r_2, ..., r_N }\), where \(N\) is the group size (DeepSeekMath sets \(N = 8\) per prompt, following the original GRPO configuration).
- Each individual response \(r_i\) is a complete sequence of tokens \(r_i = (o_{i,1}, o_{i,2}, ..., o_{i,T_i})\), where each token is sampled sequentially from the conditional probability distribution of the old policy: \(o_{i,t} \sim \pi_{\text{old}}(o_{i,t} \mid q, o_{i,<t})\).
- This sampling is stochastic, using temperature sampling with \(T = 0.8\) and top-p (nucleus) sampling with \(p = 0.9\). This ensures diversity among the responses while maintaining plausibility and coherence. Deterministic decoding such as greedy or beam search is avoided because it collapses multiple candidates into near-identical outputs, eliminating the relative quality signal required for group-wise optimization.
- Each response is decoded to completion until either an end-of-sequence token or a predefined token limit (typically 2048 tokens) is reached, in line with the DeepSeekMath setup. To maintain consistency in batch processing, responses that end early are padded to the same maximum sequence length during training.
- The use of multiple, diverse responses for the same prompt enables comparative reward normalization, allowing GRPO to focus not on absolute reward values but on the relative ranking of responses within each group. This mirrors human preference learning setups, where the model learns which response among a set is better rather than optimizing for a fixed correctness signal.
- Compute Rewards:
- Each response \(r_i\) in the group is scored using a reward model \(R_\phi\), which outputs scalar values indicating how good each response is. These scores reflect alignment with desirable behaviors such as correctness, clarity, and reasoning quality.
- In the context of GRPO and especially in the final reinforcement learning stage of DeepSeek-R1, these rewards are derived from a combination of rule-based metrics (e.g., correctness in math problems, formatting) and human preference-aligned reward models. The latter are trained on preference pairs to assess which outputs better align with helpfulness, harmlessness, and human-centric values.
- For reasoning tasks like math or code, rule-based accuracy is often sufficient. However, for broader applications and to align with human expectations, DeepSeek-R1 also incorporates reward signals trained on diverse prompt distributions. This includes assessments of readability, language consistency, and summary quality, especially important in multi-language and general-purpose scenarios.
- Crucially, GRPO assumes the reward model is only reliable when comparing responses to the same prompt, making the group-wise setup ideal. By comparing responses within the same group, GRPO leverages relative quality rather than absolute reward magnitude, aligning closely with how human preferences are typically expressed and learned.
- Calculate Advantage (\(A_i\)) Using Group Normalization:
- Instead of relying on a learned value function like in PPO (which can be memory-intensive and noisy), GRPO computes the advantage for each response using the group’s statistical properties: \(A_i = \frac{R_\phi(r_i) - \text{mean}(\mathcal{G})}{\text{std}(\mathcal{G})}\)
- This normalized score reflects how much better or worse a response is compared to its peers.
- Motivation: This approach aligns with how reward models are typically trained—on preference pairs rather than absolute values. Group normalization thus emphasizes relative quality, allowing the model to learn which responses are better without needing a global baseline.
- Benefits:
- Avoids the need for a separate value network (used in PPO)
- Significantly reduces compute and memory requirements
- Naturally leverages the comparative nature of reward models
- Update the Policy with GRPO Objective:
- The policy is updated by maximizing the GRPO-specific surrogate objective: \(J_{\text{GRPO}}(\theta) = \mathbb{E}_{q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(O|q)} \left[ \frac{1}{G} \sum_{i=1}^G \min \left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)} A_i, \text{clip} \left(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)}, 1-\epsilon, 1+\epsilon \right) A_i \right) - \beta D_{\text{KL}}(\pi_{\theta} || \pi_{\text{ref}}) \right]\)
- The clipping function stabilizes the update, while the KL divergence regularizes the new policy against a reference model (often the supervised fine-tuned policy), preventing divergence from known good behavior.
- Sample a Group of Responses (\(G\)):
Reward Function Design
- In DeepSeekMath, the reward was primarily based on mathematical correctness.
- In DeepSeek-R1, the reward function expanded to include:
- Accuracy/Correctness Rewards: Evaluating correctness for general reasoning tasks (e.g., coding, science, logic).
- Format Rewards: Ensuring structured reasoning using
<think>and<answer>tags.
Advantage Estimation
- The advantage in GRPO is computed using the predicted rewards (typically from a value/critic function) via a novel approach that eliminates the need for a separate value model, unlike traditional PPO. Here’s a breakdown of how the advantage is computed in GRPO.
Background: Generalized Advantage Estimation
- In traditional RL, and specifically in PPO, the advantage is typically computed as:
\(A_t = r_t - V(s_t)\)
- where:
- \(A_t\) is the advantage at time step \(t\)
- \(r_t\) is the reward at time step \(t\)
- \(V(s_t)\) is the estimated value of state \(s_t\)
- where:
- Or more generally via Generalized Advantage Estimation (GAE), which refines this with discounted returns to reduce variance:
\(A_t = \delta_t + (\gamma \lambda) \delta_{t+1} + (\gamma \lambda)^2 \delta_{t+2} + \dots\)
- where:
- \[\delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)\]
- \(\gamma\) is the discount factor
- \(\lambda\) is the GAE smoothing parameter
- where:
-
Advantage can thus be defined as a measure of how much better an action is compared to the expected value (baseline). Mathematically,
\[\text{Advantage} = \text{Reward} - \text{Value (Baseline)}\]- where:
- “Advantage” quantifies the relative gain of an action
- “Reward” is the return obtained after taking the action
- “Value (Baseline)” is the expected return from the state
-
Specifically, PPO uses a learned value model to estimate the baseline:
\[A_t = r_t - V_\psi(s_t)\]- where:
- \(V_\psi\) is the learned value function parameterized by \(\psi\)
- where:
-
On the other hand, GRPO uses a group average reward as the baseline:
\[\hat{A}_{i,t} = \frac{r_i - \bar{r}}{\sigma_r} \quad \text{or} \quad \hat{A}_{i,t} = \sum_{j \ge t} \frac{r_{i,j} - \bar{r}}{\sigma_r}\]- where:
- \(r_i\) is the total reward for output \(o_i\)
- \(\bar{r}\) is the group mean reward
- \(\sigma_r\) is the standard deviation of rewards
- \(r_{i,j}\) is the step-wise reward for step \(j\) of output \(i\)
- where:
- where:
- This makes GRPO a value-free method with significantly lower compute/memory cost, while retaining the core idea of advantage-based policy optimization.
Background: PPO Advantage Estimation
-
In PPO, the advantage is computed using a learned value function \(V_\psi\). The classic way to define advantage is:
\[A_t = r_t - V_\psi(s_t)\]- where:
- \(A_t\) is the advantage
- \(r_t\) is the reward at time \(t\)
- \(V_\psi(s_t)\) is the estimated value of state \(s_t\) using model \(\psi\)
- where:
-
However, more accurately and stably, PPO typically uses Generalized Advantage Estimation (GAE), which smooths over multiple future timesteps:
\[A_t^{\text{GAE}} = \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l} \quad \text{where} \quad \delta_t = r_t + \gamma V_\psi(s_{t+1}) - V_\psi(s_t)\]- where:
- \(\gamma\) is the discount factor
- \(\lambda\) is the GAE parameter
- \(\delta_t\) is the temporal-difference error at time \(t\)
- \(V_\psi\) is the learned value model
- where:
- So PPO explicitly requires a value model \(V_\psi\) to compute this baseline. The goal is to reduce the variance of the gradient estimates while keeping the bias minimal.
-
This advantage is then used in PPO’s clipped surrogate objective:
\[J_{\text{PPO}}(\theta) = \mathbb{E}_{q, o \sim \pi_{\text{old}}} \left[\frac{1}{|o|} \sum_{t=1}^{|o|} \min \left( \frac{\pi_\theta(o_t | q, o_{<t})}{\pi_{\text{old}}(o_t | q, o_{<t})} A_t, \text{clip}(\cdot) A_t \right) \right]\]- where:
- \(\pi_\theta\) is the current policy
- \(\pi_{\text{old}}\) is the old policy
- \(A_t\) is the advantage at time \(t\)
- \(\|o\|\) is the length of output sequence
- “clip” ensures the ratio stays within a safe range
- where:
GRPO Advantage Estimation
- In GRPO, there’s no value function — instead, the baseline (or expected value) is approximated using the group mean reward. So the advantage is still reward minus baseline, but the definition of the baseline depends on whether outcome or process supervision is adopted.
- Outcome Supervision (one reward per output):
-
Let \(r_i\) be the reward for output \(o_i\), and the baseline be the group average \(\bar{r}\), then:
\[\hat{A}_{i,t} = \tilde{r}_i = \frac{r_i - \bar{r}}{\sigma_r} \quad \text{where} \quad \bar{r} = \frac{1}{G} \sum_{j=1}^G r_j\]- where:
- \(r_i\) is the reward for sample \(i\)
- \(\bar{r}\) is the average reward across the group
- \(\sigma_r\) is the standard deviation for normalization
- \(G\) is the group size
- where:
-
This is essentially:
\[\text{Advantage} = \frac{\text{Reward} - \text{Baseline}}{\text{Standard Deviation (for normalization)}}\]- where:
- “Reward” is the individual sample’s score
- “Baseline” is the group mean
- The expression is normalized by \(\sigma_r\)
- where:
-
Every token \(t\) in output \(o_i\) receives the same normalized advantage.
-
- Process/Step-wise Supervision (rewards for steps):
-
If \(r_{i,j}\) is the reward for the \(j^{th}\) step of output \(o_i\), and \(\bar{r}\) is the group mean:
\[\tilde{r}_{i,j} = \frac{r_{i,j} - \bar{r}}{\sigma_r}\]- where:
- \(r_{i,j}\) is the reward for step \(j\) in sample \(i\)
- \(\bar{r}\) is the mean reward across all steps in the group
- \(\sigma_r\) is the standard deviation for normalization
- where:
-
Then for each token \(t\), the advantage is the sum of normalized rewards for all steps ending after \(t\):
\[\hat{A}_{i,t} = \sum_{\text{step } j: \text{index}(j) \ge t} \tilde{r}_{i,j}\]- where:
- The sum includes all steps \(j\) such that the index of \(j\) is greater than or equal to token index \(t\)
- \(\tilde{r}_{i,j}\) is the normalized reward for step \(j\) of output \(i\)
- where:
-
Again, this reflects reward minus baseline in a normalized form — just applied step-wise.
-
Comparative Analysis: REINFORCE vs. TRPO vs. PPO vs. DPO vs. KTO vs. APO vs. GRPO
- REINFORCE:
- Function: The simplest policy gradient algorithm that updates the model based on the cumulative reward received from complete trajectories.
- Implementation: Generates an entire episode, calculates rewards at the end, and updates the policy network based on a weighted log probability loss.
- Practical Challenges: High variance in policy updates, slow convergence, and instability due to unbounded updates.
- TRPO:
- Function: Trust Region Policy Optimization (TRPO) improves policy updates by constraining step sizes to avoid instability.
- Implementation: Uses a constrained optimization formulation to ensure each update remains within a trust region, preventing excessive deviations.
- Practical Challenges: Computationally expensive due to the constraint-solving step and requires second-order optimization techniques.
- PPO:
- Function: An RL algorithm that optimizes the language model by limiting how far it can drift from a previous version of the model.
- Implementation: Involves sampling generations from the current model, judging them with a reward model, and using this feedback for updates.
- Practical Challenges: Can be slow and unstable, especially in distributed settings.
- DPO:
- Function: Minimizes the negative log-likelihood of observed human preferences to align the language model with human feedback.
- Data Requirement: Requires paired preference data.
- Comparison with KTO: While DPO has been effective, KTO offers competitive or superior performance without the need for paired preferences.
- KTO:
- Function: Adapts the Kahneman-Tversky human value function to the language model setting. It uses this adapted function to directly maximize the utility of model outputs.
- Data Requirement: Does not need paired preference data, only knowledge of whether an output is desirable or undesirable for a given input.
- Practicality: Easier to deploy in real-world scenarios where desirable/undesirable outcome data is more abundant.
- Model Comparison: Matches or exceeds the performance of direct preference optimization methods across various model sizes (from 1B to 30B).
- APO:
- Function: Introduces a family of contrastive objectives explicitly accounting for the relationship between the model and the preference dataset. This includes APO-zero, which increases desirable outputs while decreasing undesirable ones, and APO-down, which fine-tunes models based on specific quality thresholds.
- Data Requirement: Works effectively with paired preference datasets created through controlled methods like CLAIR and supports stable alignment even for challenging datasets.
- Practicality: Excels at aligning strong models with minimally contrasting preferences, enhancing performance on challenging metrics like MixEval-Hard while providing stable, interpretable training dynamics.
- Model Comparison: Outperformed conventional alignment objectives across multiple benchmarks, closing a 45% performance gap with GPT4-turbo when trained with CLAIR preferences.
- GRPO:
- Function: A variant of PPO that removes the need for a critic model by estimating the baseline using group scores, improving memory and computational efficiency while enhancing the mathematical reasoning of models.
- Data Requirement: Utilizes group-based rewards computed from multiple outputs for each query, normalizing these scores to guide optimization.
- Practicality: Focuses on reducing training resource consumption compared to PPO and improving RL stability.
- Model Comparison: Demonstrated superior performance on tasks like GSM8K and MATH benchmarks, outperforming other models of similar scale while improving both in-domain and out-of-domain reasoning tasks.
Tabular Comparison
| Aspect | REINFORCE | TRPO | PPO | DPO | KTO | APO | GRPO |
|---|---|---|---|---|---|---|---|
| Objective | Policy gradient optimization without constraints. | Ensures stable policy updates within a constrained region. | Maximizes expected reward while preventing large policy updates. | Optimizes policy based on binary classification of human preferences. | Aligns models based on Kahneman-Tversky optimization for utility maximization. | Anchored alignment with specific control over preference-based likelihood adjustments. | Leverages group-based relative advantages and removes the critic network. |
| Learning Mechanism | Monte Carlo policy gradients with high variance. | Second-order optimization with trust region constraints. | Policy gradients with a clipped surrogate objective. | Cross-entropy optimization over paired preferences. | Maximizes desirable likelihoods relative to undesirables, without paired data. | Uses variants like APO-zero or APO-down for stable preference-based optimization. | Group normalization with policy gradients, eliminating the critic network. |
| Stability | Low (high variance, unstable updates). | High (enforces trust region for stable updates). | Relies on clipping mechanisms to avoid destabilization. | Stable as it directly optimizes preferences. | Stable due to focus on unpaired desirability adjustments. | Offers robust training stability, scaling better on models trained with mixed-quality datasets. | Stable due to normalization of rewards across groups. |
| Training Complexity | High (unconstrained updates). | Very high (requires second-order optimization and solving constraints). | High, due to balancing reward maximization with policy constraints. | Moderate; uses simplified binary preference objectives. | Simplifies alignment by focusing only on desirability. | Adaptive and context-aware; requires understanding dataset-model relationships. | Reduces overhead via group-based scoring. |
| Performance | Unstable and sample-inefficient. | More stable than PPO but computationally expensive. | Strong performance on tasks with clear reward signals but prone to instability in distributed setups. | Effective for straightforward preference alignment tasks. | Competitive or better alignment than preference-based methods without paired data needs. | Superior alignment results, particularly for nuanced dataset control. | Excels in reasoning tasks, offering computational efficiency. |
| Notable Strength | Simple to implement but inefficient. | Ensures stable policy updates through trust-region constraints. | Widely used in RL settings, good at reward-based optimization. | Directly optimizes for preferences without needing a separate reward model. | Handles binary data efficiently, avoiding paired data dependencies. | Allows precise alignment with nuanced datasets. | Simplifies reward aggregation; strong for reasoning-heavy tasks. |
| Scenarios Best Suited | RL tasks where simplicity is preferred over efficiency. | High-stability RL tasks requiring constraint-driven policy improvements. | RL environments where reward signals are predefined. | Scenarios with abundant paired human feedback. | Real-world settings with broad definitions of desirable/undesirable outputs. | Tasks requiring precise alignment with minimally contrasting preferences. | Mathematical reasoning or low-resource training setups. |
Reward Functions
- Reward modeling is a crucial component of the reinforcement learning process in DeepSeek-R1, determining the optimization direction and shaping the model’s reasoning behavior. DeepSeek-R1 employs a rule-based reward system instead of a neural reward model to avoid reward hacking and excessive computational costs. The primary reward functions guiding DeepSeek-R1 are:
Accuracy Rewards
-
The accuracy reward model ensures that the model generates factually correct and verifiable responses. It is particularly useful for tasks with deterministic outcomes, such as mathematics and coding.
- Mathematical Tasks:
- The model is required to output the final answer in a specified format (e.g., within a box or marked in LaTeX), enabling automated rule-based verification.
- For example, in mathematical problems, the correctness of the response is checked against a ground-truth solution.
- Programming Tasks:
- For coding problems, correctness is determined using unit tests. The model’s output is compiled and executed against predefined test cases, and rewards are assigned based on the number of passing tests.
- If the generated code is syntactically incorrect, a small penalty is applied to discourage such outputs.
- Group-Based Normalization:
- Instead of relying on a separate critic network, DeepSeek-R1 uses a group-based reward normalization method. Given a group of responses \(\{r_1, r_2, ..., r_G\}\), the advantage function is calculated as:
\(A_i = \frac{r_i - \text{mean}(r_1, ..., r_G)}{\text{std}(r_1, ..., r_G)}\)
- where \(A_i\) represents the normalized advantage of response \(i\), and standardization ensures stable training updates.
- Instead of relying on a separate critic network, DeepSeek-R1 uses a group-based reward normalization method. Given a group of responses \(\{r_1, r_2, ..., r_G\}\), the advantage function is calculated as:
\(A_i = \frac{r_i - \text{mean}(r_1, ..., r_G)}{\text{std}(r_1, ..., r_G)}\)
Format Rewards
-
Beyond correctness, DeepSeek-R1 is trained to produce well-structured and human-readable outputs. The format reward model enforces this by incentivizing adherence to a structured reasoning format.
- Reasoning and Answer Separation:
- The model’s responses must follow a two-stage format:
<think> Step-by-step breakdown of the reasoning </think> <answer> Final Answer </answer> - This ensures that the model explicitly separates its reasoning process from its final answer, improving clarity and user comprehension.
- The model’s responses must follow a two-stage format:
- Language Consistency Reward:
- One challenge observed in earlier versions, such as DeepSeek-R1-Zero, was language mixing, where responses included a blend of multiple languages (e.g., partial English and partial Chinese).
- To mitigate this, DeepSeek-R1 incorporates a language consistency reward, defined as the proportion of words in the target language: \(R_{\text{lang}} = \frac{\text{Count of words in target language}}{\text{Total word count}}\)
- This encourages the model to maintain linguistic coherence without degrading its reasoning performance.
Combined Reward Function
-
The final reward signal for DeepSeek-R1 is computed as a weighted sum of the individual reward components:
\[R_{\text{final}} = \alpha R_{\text{accuracy}} + \beta R_{\text{format}} + \gamma R_{\text{lang}}\]- where:
- \(\alpha\), \(\beta\), and \(\gamma\) are hyperparameters controlling the relative contributions of each reward type:
- Accuracy rewards ensure correctness,
- Format rewards ensure structured output,
- Language consistency rewards ensure readability and coherence.
- \(\alpha\), \(\beta\), and \(\gamma\) are hyperparameters controlling the relative contributions of each reward type:
- where:
-
This design choice balances factual correctness with user-friendly response formatting, making DeepSeek-R1 a powerful reasoning model.
Why Rule-Based Rewards Instead of Neural Reward Models?
- DeepSeek-R1 avoids the use of neural reward models because they are susceptible to reward hacking and require costly retraining. Instead, a deterministic rule-based approach provides:
- Greater transparency: Rewards are interpretable and verifiable.
- Reduced computational cost: No need for an additional neural network.
- More stable training dynamics: Since rule-based rewards are fixed, they do not drift over time.
Implementation in GRPO
- DeepSeek-R1’s Group Relative Policy Optimization (GRPO) framework leverages these reward functions during training:
- A batch of multiple outputs per query is sampled.
- The relative rewards within the group are computed.
- The advantage estimates are normalized.
- The policy is updated using a clipped objective function that prevents large policy shifts.
- This process ensures efficient reinforcement learning without the need for a separate critic model, leading to more stable and scalable training.
Stage 3: Rejection Sampling & Expanded Supervised Fine-Tuning
- After RL convergence, DeepSeek-R1 undergoes an additional fine-tuning step based on rejection sampling. This stage refines the reasoning process by incorporating:
- Reasoning Trajectories: Selecting correct and well-structured CoT explanations from RL outputs. Around 600,000 reasoning-related samples were collected through this process, emphasizing clarity, correctness, and readability.
- Expanded Task Coverage: Augmenting the dataset with non-reasoning tasks like:
- Writing & Summarization
- Fact-based Question Answering
- Self-cognition and safety-related responses
- In total, about 800,000 curated samples were used for this fine-tuning phase, significantly enhancing DeepSeek-R1’s general capabilities beyond pure reasoning tasks.
- Implementation Details for SFT:
- Fine-Tuning Technique: This stage uses the full-finetuning variant of SFT with a categorical cross-entropy loss (rather than a parameter-efficient finetuning technique such as LoRA), consistent with earlier SFT stages. The model is trained via standard teacher forcing:
\(L_{\text{SFT}} = -\sum_{i=1}^{n} \log P_{\theta}(o_i \mid q, o_{<i})\)
- where:
- \(o_i\) is the \(i^{th}\) token in the output,
- \(o_{<i}\) represents all previously generated tokens,
- \(q\) is the input query,
- \(P_{\theta}\) is the model’s predicted probability distribution.
- where:
- Reasoning Data Collection: About 600,000 reasoning samples are curated through rejection sampling on the converged RL checkpoint. Multiple outputs are sampled per prompt, and only correct, well-formatted responses are retained. Mixed-language outputs, incoherent reasoning chains, and malformed code blocks are filtered out to maintain readability and consistency.
- Use of Generative Rewards: While earlier RL phases rely exclusively on rule-based rewards, this phase introduces generative reward modeling by passing model responses and references through DeepSeek-V3 to assess correctness in cases where rule-based scoring is not feasible.
- Non-Reasoning Data Sourcing: Around 200,000 samples covering non-reasoning tasks are added. Some are drawn from DeepSeek-V3’s original supervised dataset. In specific instances, DeepSeek-V3 is prompted to generate light reasoning (e.g., reflective CoT) before answering, while simpler queries skip CoT entirely.
- Training Process: The full dataset (~800K samples) is used to fine-tune DeepSeek-V3-Base for two epochs. The resulting model checkpoint forms the basis for the final RL phase.
- Output Format Enforcement: Structured templates like
<reasoning_process> ... </reasoning_process>and<summary> ... </summary>are maintained during fine-tuning to preserve clarity and alignment with prior stages. - Language Quality Control: Responses exhibiting language mixing or low linguistic coherence are systematically excluded to improve generalization and user experience across multilingual inputs.
- Training Configuration: The fine-tuning is applied to the model checkpoint obtained after Stage 2 (GRPO-based RL). This checkpoint is fine-tuned using the combined dataset (~800k samples) over two epochs.
- Fine-Tuning Technique: This stage uses the full-finetuning variant of SFT with a categorical cross-entropy loss (rather than a parameter-efficient finetuning technique such as LoRA), consistent with earlier SFT stages. The model is trained via standard teacher forcing:
\(L_{\text{SFT}} = -\sum_{i=1}^{n} \log P_{\theta}(o_i \mid q, o_{<i})\)
- This fine-tuning phase not only consolidates the structured reasoning behavior induced by RL but also extends the model’s general capabilities across broader tasks. It acts as a crucial bridge before the final RL generalization stage, aligning the model toward human-preferred formats and diverse task domains.
Stage 4: Secondary RL for Alignment & Generalization
- The final stage involves another round of RL, but this time with a broader task distribution. Unlike the first RL stage, which focused primarily on reasoning-intensive tasks, this stage incorporates general user interactions such as:
- Conversational depth (multi-turn dialogues)
- Complex instructions & role-playing scenarios
- Ensuring helpfulness & harmlessness in responses
-
For general tasks, a reward model is used to align outputs with human preferences. For reasoning tasks, the original rule-based rewards (accuracy & format) are retained.
- Implementation Details:
- Prompt Diversity: This phase expands the prompt distribution to include a wide variety of task types—from casual conversations to safety-sensitive and instruction-heavy prompts. This broader distribution ensures the model is exposed to realistic, diverse, and nuanced user interactions during training.
- Dual Reward Signal: A combination of rule-based rewards (for math, code, logic) and model-based preference rewards (for general alignment) are used. Preference data is sourced from the DeepSeek-V3 pipeline, covering areas like helpfulness and harmlessness.
- Helpfulness Reward: Calculated specifically on the final summary section of the response to prevent disruption of the reasoning flow. This ensures the model prioritizes clear, relevant, and actionable outputs.
- Harmlessness Reward: Evaluated across the full response (reasoning + summary), identifying and penalizing harmful or biased content to enhance safety and trustworthiness.
- RL Framework: The training continues using the GRPO algorithm. This stage maintains the critic-free setup with group-based advantage estimation but introduces more heterogeneous prompt and reward structures.
- Model Architecture & Training:
- Continues from the SFT+RL-trained checkpoint (post-rejection sampling).
- Multiple outputs are sampled per prompt and scored via the appropriate reward mechanism (rule-based or preference-based).
- The policy is updated using the clipped GRPO loss to maintain training stability and reduce policy drift.
- KL-regularization is applied against the supervised fine-tuned reference model to prevent degradation of core alignment.
- Batch Composition Strategy:
- Prompts are batched in a mixed-format setup, meaning each training batch includes both reasoning and non-reasoning (general alignment) tasks.
- Each sample in the batch is tagged with a task type label, such as
reasoning,instruction-following,conversational, orsafety-critical. During training, these task type tags are used primarily for curriculum control and reward routing as side-channel metadata used by the reward computation pipeline, not necessarily as input-level tokens or control tags embedded in the prompt. This ensures the model is guided during optimization while still learning to generalize from the natural structure and semantics of prompts during inference time. - The model internally uses attention masks or task-specific prompt tokens to condition its behavior differently depending on the task type. For example:
- Reasoning tasks include
<think>and<answer>tags and are evaluated using rule-based rewards. - Instruction-following tasks may include tags like
<summary>or<response>, guiding the model to focus on clarity, usefulness, and task compliance. - Safety-critical prompts are routed with special tags that signal the harmlessness reward module to evaluate the full output.
- Reasoning tasks include
- During training, gradient updates are not explicitly decoupled per task type, but the mixed-format batch with tags encourages the model to generalize across task boundaries and learn how to shift generation style and objective based on prompt patterns.
- This batch composition strategy enables multi-domain alignment using a unified GRPO framework, without requiring separate heads or fine-tuning tracks for each domain.
- Training Duration: Training continues until convergence on both reasoning (via rule-based evaluation) and alignment (via offline preference evaluation metrics).
- Safety Enhancements: Additional constraints are applied post-hoc to ensure safe responses in high-risk or adversarial prompts. This includes filtering low-reward outputs and further refining the RL dataset with human-in-the-loop verification for high-stakes domains.
- This final RL phase optimizes DeepSeek-R1 for real-world deployment, ensuring that it remains robust across a variety of domains beyond structured problem-solving. It strengthens the model’s alignment with human values while preserving its advanced reasoning capabilities.
Comparing Training Pipelines: DeepSeek-R1 vs. DeepSeek-R1-Zero
- DeepSeek-R1 and DeepSeek-R1-Zero represent two distinct training approaches for reasoning-focused LLMs, both leveraging RL but differing significantly in their pre-training methodologies, optimization strategies, and implementation details.
- Through the below-listed refinements, DeepSeek-R1 successfully overcomes the limitations of DeepSeek-R1-Zero, showcasing how structured training pipelines can significantly enhance the reasoning performance of LLMs.
Pre-Training and Initialization
- DeepSeek-R1-Zero starts directly from DeepSeek-V3-Base, applying RL without any SFT. This “pure RL” approach forces the model to self-learn reasoning capabilities from scratch through iterative policy optimization.
- DeepSeek-R1, also starts directly from DeepSeek-V3-Base, but undergoes a cold-start fine-tuning phase, where it is trained on thousands of high-quality CoT examples before undergoing RL. This additional step prevents the chaotic early-stage behavior observed in DeepSeek-R1-Zero and ensures a more structured learning trajectory.
RL Strategy
- Both models utilize GRPO as the core RL algorithm. However, their reward modeling, training templates, and optimization techniques differ significantly.
DeepSeek-R1-Zero: Pure RL Approach
- Policy Optimization: Trained solely through GRPO, which estimates a baseline using group scores instead of a separate critic model. This makes RL more memory efficient compared to PPO-based approaches.
- Training Template: Outputs are structured using a
<think>and<answer>format to encourage reasoning before answering. - Reward Functions:
- Accuracy Reward: Evaluates correctness for deterministic tasks like math and coding.
- Format Reward: Enforces structured reasoning using the
<think>and<answer>tags.
- Challenges Encountered:
- Readability Issues: Many outputs lacked clarity, with mixed-language responses and unstructured formatting.
- Convergence Stability: Early-stage RL training led to unstable outputs, as the model lacked a prior structured reasoning framework.
DeepSeek-R1: Multi-Stage RL with Cold-Start Fine-Tuning
- Cold-Start Fine-Tuning: Before RL, the model is fine-tuned on thousands of curated CoT examples, improving reasoning structure and readability.
- Enhanced Reward Functions:
- Language Consistency Reward: Added to enforce single-language outputs and reduce language mixing issues.
- Expanded Reasoning Rewards: Covers broader reasoning domains beyond math and logic, including coding, science, and knowledge-based tasks.
- Multi-Stage RL Refinement:
- Stage 1: RL training with GRPO to refine mathematical reasoning.
- Stage 2: Rejection sampling to extract high-quality CoT explanations for further fine-tuning.
- Stage 3: Final RL Phase for alignment with human feedback, enhancing general conversational capabilities beyond structured problem-solving.
Implementation Details and Computational Efficiency
| Feature | DeepSeek-R1-Zero | DeepSeek-R1 |
|---|---|---|
| Pre-training Base | DeepSeek-V3-Base | DeepSeek-V3-Base |
| Cold-Start SFT | ❌ No SFT (Pure RL) | ✅ Fine-tuned on CoT examples before RL |
| RL Algorithm | GRPO | GRPO |
| Reward Types | Accuracy, Format | Accuracy, Format, Language Consistency |
| Training Stability | ❌ Unstable early-stage RL | ✅ More stable due to cold-start fine-tuning |
| Output Readability | ❌ Mixed-language responses, unstructured | ✅ Structured reasoning with CoT enforcement |
| Final Refinement | Single-stage RL | Multi-stage RL + rejection sampling |
Final Performance Impact
- DeepSeek-R1-Zero successfully demonstrated that LLMs can develop reasoning purely via RL, but suffered from poor readability and chaotic convergence.
- DeepSeek-R1 introduced a structured multi-phase training pipeline, resulting in more readable, reliable, and generalized reasoning capabilities, ultimately achieving performance on par with OpenAI o1.
GRPO Variants
Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO)
- Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO), proposed by ByteDance, Tsinghua University, The University of Hong Kong, and the SIA-Lab of Tsinghua AIR and ByteDance Seed, significantly advances reinforcement learning (RL) for long-chain-of-thought (CoT) reasoning by building on the foundational ideas of Grouped Reinforcement Learning with Policy Optimization (GRPO). While GRPO simplifies RL training by eliminating the need for a value network through group-based reward normalization, DAPO introduces a suite of principled enhancements that greatly improve sample efficiency, training stability, and policy diversity—particularly in complex reasoning tasks.
- Developed and benchmarked with the Qwen2.5-32B model, DAPO not only matches but often surpasses state-of-the-art results achieved by models like DeepSeek-R1-Zero. This demonstrates the limitations of naive GRPO and highlights DAPO as a more refined and robust alternative. Key innovations in DAPO include mechanisms such as Clip-Higher for better gradient clipping, dynamic sampling for improved data efficiency, token-level loss modeling for finer-grained learning, and nuanced reward shaping. These features allow DAPO to achieve superior performance with fewer training steps, making it a compelling evolution in the RL paradigm for large-scale reasoning models. Importantly, DAPO remains reproducible and open-source, promoting transparency and further research in the field.
DAPO vs. GRPO: Key Conceptual Differences
-
At a high level, both GRPO and DAPO eliminate the critic model and use group-normalized advantages. However, DAPO introduces several critical refinements:
- Clipping asymmetry (Clip-Higher): Decouples the lower and upper clipping bounds to promote exploration.
- Dynamic Sampling: Filters out trivial cases where all generated responses are either fully correct or incorrect, preserving informative gradient updates.
- Token-Level Loss: Applies the policy gradient loss at the token level rather than averaging over the sequence.
- Overlong Reward Shaping: Mitigates instability from truncated long sequences via soft penalties instead of hard cutoffs.
-
Each of these refinements addresses a specific deficiency in GRPO’s design when applied to long-CoT reasoning tasks.
DAPO: Implementation Details
Objective Function
-
DAPO modifies the GRPO objective by decoupling the clipping thresholds and introducing dynamic sampling. The core training objective is:
\[J_{\text{DAPO}}(\theta) = \mathbb{E}_{(q,a) \sim D, \{o_i\}_{i=1}^G \sim \pi_{\theta_{\text{old}}}(\cdot | q)}\left[ \frac{1}{\sum_{i=1}^G |o_i|} \sum_{i=1}^G \sum_{t=1}^{|o_i|} \min\left( r_{i,t}(\theta) \hat{A}_{i,t}, \text{clip}(r_{i,t}(\theta), 1 - \epsilon_{\text{low}}, 1 + \epsilon_{\text{high}}) \hat{A}_{i,t} \right) \right]\]- where:
- \[r_{i,t}(\theta) = \frac{\pi_\theta(o_{i,t} | q, o_{i,<t})}{\pi_{\theta_{\text{old}}}(o_{i,t} | q, o_{i,<t})}\]
- \[\hat{A}_{i,t} = \frac{R_i - \text{mean}(\{R_j\}_{j=1}^G)}{\text{std}(\{R_j\}_{j=1}^G)}\]
- \(\epsilon_{\text{low}}, \epsilon_{\text{high}}\) are asymmetric clipping bounds
- \(\pi_\theta\) is the current policy, and \(\pi_{\theta_{\text{old}}}\) is the behavior policy used to generate samples
- Rewards \(R_i\) are computed via rule-based evaluators
- where:
Clip-Higher (Asymmetric Clipping)
- While GRPO adopts PPO-style clipping:
- DAPO decouples the upper and lower clipping thresholds:
- This enables greater policy exploration, especially for low-probability tokens that would otherwise remain underrepresented. This adjustment empirically increases generation entropy without sacrificing correctness, stabilizing learning and avoiding entropy collapse (Figure 2b in the source).
Dynamic Sampling
-
DAPO introduces a data-efficient sampling strategy. Since GRPO computes relative advantages within a group, if all generated responses are correct (or all incorrect), the standard deviation becomes zero, yielding zero gradients.
-
To counteract this, DAPO enforces:
- This filters out groups that do not produce informative learning signals. The strategy ensures that every training batch contains prompts yielding useful gradients by resampling until this constraint is met.
Token-Level Policy Gradient Loss
- GRPO aggregates the loss by averaging across entire sequences, which leads to disproportionate weight on shorter samples. DAPO instead normalizes the loss over tokens, ensuring that longer responses contribute proportionally to the gradient:
- This fine-grained gradient computation:
- Enhances learning from long, structured reasoning sequences
- Mitigates the problem of low-quality long outputs dominating updates
- Encourages refinement of reasoning at the token level rather than relying solely on outcome correctness
Overlong Reward Shaping
- To handle excessively long outputs (common in long-CoT tasks), DAPO introduces Soft Overlong Punishment. Rather than assigning a fixed penalty, it uses a length-sensitive shaping function:
- This length-aware penalty encourages succinct, precise reasoning and reduces training noise from truncated sequences, as demonstrated by the entropy and accuracy trends in the source.
Training Implementation Summary
- Base Model: Qwen2.5-32B
- Batch Size: 512 prompts × 16 responses per prompt
- Loss Reduction: Token-level
- Clipping: Asymmetric with \(\epsilon_{\text{low}} = 0.2\), \(\epsilon_{\text{high}} = 0.28\)
- Max Tokens: 20,480 (with soft penalty starting at 16,384)
- Reward Function: Rule-based equivalence check (1 for correct, -1 otherwise)
DAPO vs. GRPO Summary
| Feature | GRPO | DAPO |
|---|---|---|
| Clipping | Symmetric (\(\epsilon\)) | Asymmetric (\(\epsilon_{\text{low}}, \epsilon_{\text{high}}\)) |
| Sampling | Uniform (accept all groups) | Dynamic (filters degenerate groups) |
| Loss Aggregation | Sample-level | Token-level |
| Overlong Sample Handling | Truncation + hard penalty | Soft reward shaping |
| KL Regularization | Optional (often used) | Removed to allow divergence from SFT |
| Exploration Capacity | Lower (risk of entropy collapse) | Higher (maintains policy diversity) |
| Stability in Long-CoT Tasks | Moderate | High |
Empirical Gains
- As shown in paper, each DAPO technique independently improves performance on AIME 2024. Cumulatively, DAPO achieves 50 points (avg@32), surpassing DeepSeek-R1-Zero-Qwen-32B (47 points), with only 50% of the training steps as shown in the plot from the paper.

| Model Variant | AIME24 avg@32 |
|---|---|
| Naive GRPO | 30 |
| + Overlong Filtering | 36 |
| + Clip-Higher | 38 |
| + Soft Overlong Punishment | 41 |
| + Token-level Loss | 42 |
| + Dynamic Sampling (DAPO Final) | 50 |
GRPO+: A Stable Evolution of GRPO for Reinforcement Learning in DeepCoder
-
GRPO+ is an advanced variant of Group Relative Policy Optimization (GRPO), specifically designed to address the instability challenges commonly encountered during reinforcement learning (RL) training of code reasoning models, especially in long-context fine-tuning scenarios. This refined approach builds upon the foundational structure of GRPO, while integrating innovations—many inspired by DAPO—to enhance training stability, reward fidelity, and response scalability.
-
Developed for DeepCoder, a 14B open-source code reasoning model, GRPO+ introduces several key modifications that distinguish it from its predecessor. These include the removal of KL and entropy losses, the incorporation of asymmetric clipping, and the implementation of overlong filtering. Collectively, these changes create a lightweight yet robust training framework, enabling stable and efficient scaling of reasoning abilities across extended context windows.
-
By tailoring these enhancements to the specific demands of large-scale RL in code-focused language models, GRPO+ delivers improved performance and reliability. It empowers open-source models like DeepCoder to push the boundaries of coding tasks, making it a compelling strategy for deploying frontier-level LLMs in open development environments.
Motivation for GRPO+
-
During DeepCoder’s RL training on a curated set of 24,000 verifiable code problems, the research team observed that the vanilla GRPO algorithm exhibited a collapse in reward over time, especially during later stages of training. This was attributed to entropy divergence and unstable policy updates. To counter this, GRPO+ was introduced with the goal of preserving the sample efficiency of GRPO while enhancing its training stability for large-scale, long-context LLMs.
-
The following figure (source) illustrates this: the average reward for GRPO+ remains stable, while GRPO degrades and eventually collapses during training. The modifications introduced in GRPO+ are critical to sustaining performance throughout extended RL runs.

Key Innovations in GRPO+
-
GRPO+ introduces the following core changes to the GRPO framework:
- No Entropy Loss:
- In standard PPO/GRPO implementations, an entropy loss term is often included to promote exploration. However, in DeepCoder’s experiments, this entropy term caused the entropy of the output distribution to grow uncontrollably, destabilizing training. GRPO+ omits this term altogether:
- Rationale: Removing entropy loss prevents exponential growth in token-level uncertainty, avoiding collapse in later iterations.
- Effect: Encourages more stable convergence by reducing exploration-induced noise.
- No KL Loss (No Trust Region Constraint):
- While GRPO retains a KL divergence penalty against a reference policy to prevent policy drift, GRPO+ completely removes the \(- \beta D_{\text{KL}}(\pi_\theta \,\|\, \pi_{\text{ref}})\) component from the loss.
- Rationale: This follows insights from DAPO, which demonstrated that strict adherence to a trust region (as in PPO or GRPO) can overly constrain learning.
- Effect: Training is accelerated since the computation of log probabilities from the reference model is skipped, reducing overhead.
- Clip High in Surrogate Loss:
- GRPO+ modifies the upper bound in the surrogate loss function to encourage greater exploration:
\(\min\left(\rho_i A_i, \text{clip}(\rho_i, 1 - \epsilon, 1 + \epsilon_{\text{high}}) A_i \right)\)
- where \(\epsilon_{\text{high}} > \epsilon\) is a relaxed clipping range.
- Rationale: Standard clipping suppresses beneficial large updates; raising the upper bound retains PPO-style stability while allowing positive exploration.
- Effect: Boosts learning speed and prevents premature convergence.
- GRPO+ modifies the upper bound in the surrogate loss function to encourage greater exploration:
\(\min\left(\rho_i A_i, \text{clip}(\rho_i, 1 - \epsilon, 1 + \epsilon_{\text{high}}) A_i \right)\)
- Overlong Filtering:
- To allow generalization to longer context windows (up to 64K), GRPO+ introduces masked loss for truncated sequences. This overlong filtering ensures that models are not penalized for generating coherent but lengthy outputs beyond the current training context (e.g., 32K tokens):
- Implementation: During training, loss is not backpropagated through the truncated parts of sequences.
- Effect: Enables the model to reason over longer contexts during inference, with empirical gains on LiveCodeBench from 54% to 60.6% as context increases from 16K to 64K.
- To allow generalization to longer context windows (up to 64K), GRPO+ introduces masked loss for truncated sequences. This overlong filtering ensures that models are not penalized for generating coherent but lengthy outputs beyond the current training context (e.g., 32K tokens):
- No Entropy Loss:
GRPO+ Objective Function
-
The GRPO+ loss removes both KL regularization and entropy penalties from the original GRPO loss. It retains the clipped surrogate objective with a modified upper bound:
\[J_{\text{GRPO+}}(\theta) = \mathbb{E}_{q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{\text{old}}}(O|q)} \left[ \frac{1}{G} \sum_{i=1}^G \min\left(\rho_i A_i, \text{clip}(\rho_i, 1-\epsilon, 1+\epsilon_{\text{high}}) A_i\right) \right]\]- where:
- \[\rho_i = \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)}\]
- \(A_i = \frac{r_i - \bar{r}}{\sigma_r}\), with group-based normalization as in GRPO
- \(\epsilon_{\text{high}}\) is the extended clipping upper bound (e.g., 0.4 instead of 0.2)
- where:
-
Compared to GRPO’s original form:
- GRPO+ simplifies the objective and accelerates training by avoiding KL divergence and entropy computation.
Implementation Details
- Training Loop:
- Sample a group of responses (\(G = 8\) typically) using \(\pi_{\theta_{\text{old}}}\).
- Score each response using a sparse Outcome Reward Model (ORM):
- A binary reward is assigned:
- 1 if all unit tests pass
- 0 if any test fails or the output is improperly formatted
- A binary reward is assigned:
- Compute the group-based normalized advantage: \(A_i = \frac{r_i - \bar{r}}{\sigma_r}\)
- Apply clipped surrogate loss with relaxed upper bound.
- Mask out loss contributions for truncated sequences to support long-context generalization.
- Update the policy \(\pi_\theta\) using standard gradient ascent.
- No Entropy or KL Terms:
- Losses are purely policy-gradient based.
- No reference model is involved during optimization.
- No explicit entropy bonus is used, encouraging organic exploration through gradient updates and the “Clip High” mechanism.
- Context Scaling:
- Training begins at 16K context length.
- At step 180, the model is extended to 32K with overlong filtering enabled.
- At inference, DeepCoder generalizes successfully to 64K contexts, achieving peak performance.
Comparison: GRPO vs. GRPO+
| Feature | GRPO | GRPO+ |
|---|---|---|
| Critic Model | No | No |
| KL Regularization | Yes | No |
| Entropy Loss | Yes | No |
| Clipping | Symmetric \((1 \pm \varepsilon)\) | Asymmetric \((1 - \varepsilon,\ 1 + \varepsilon_{\text{high}})\) |
| Advantage | Group-based Normalized | Group-based Normalized |
| Long-Context Generalization | Partial | Fully Supported (via overlong filtering) |
| Reward Function | Can use dense or sparse | Sparse binary (Outcome Reward Model) |
| Use Case | General reasoning, math RL | Long-context code RL |
| Stability | Moderate | High (no collapse over time) |
Why GRPO+ Works
- By simplifying the objective function, GRPO+ reduces the overhead of computing KL and entropy terms while still retaining PPO-like stability through clipping.
- It tailors the training process to sparse reward signals (pass/fail from test cases) and long-form outputs (code solutions), where traditional entropy bonuses or KL constraints may be detrimental.
- GRPO+’s stripped-down yet strategically enhanced formulation reflects a pragmatic design choice: retain what works, discard what destabilizes, and adapt the core RL ideas to the idiosyncrasies of code reasoning.
Results and Performance Impact
- GRPO+ was critical to DeepCoder’s performance. The reward curve of GRPO+ (Figure 2 of the paper) maintains a stable upward trajectory, in contrast to GRPO, whose training reward collapses beyond a certain point. Empirically, GRPO+ enables DeepCoder to:
- Achieve 60.6% Pass@1 on LiveCodeBench
- Match O3-mini and O1 on coding benchmarks
- Generalize to 64K context with no retraining
- These improvements would not have been possible under GRPO alone, which suffered from convergence and entropy-related collapse in earlier experiments.
Emergent Reasoning Behaviors
-
DeepSeek-R1 demonstrated remarkable emergent reasoning behaviors during its training process, particularly due to the RL approach that guided its self-evolution. These behaviors include:
-
Reflection: The model exhibits the ability to revisit and revise its intermediate steps. By analyzing prior outputs and reconsidering logical pathways, it refines its reasoning, ensuring a higher probability of correctness. This reflection is especially visible in long CoT processes where multiple reasoning paths are explored.
-
Self-Correction: DeepSeek-R1 can detect errors in its own logical steps and apply corrective adjustments. This behavior is incentivized by reward modeling, where the model is trained to recognize inconsistencies and rerun calculations when necessary. This prevents incorrect conclusions from being solidified.
-
Aha Moments: Perhaps the most striking emergent behavior is the spontaneous “aha moment,” where DeepSeek-R1 halts its current reasoning trajectory, reevaluates the problem from a new angle, and finds a more optimal solution. This is often triggered by a discrepancy between expected and derived results, prompting the model to explore alternative pathways.
-
Implementation Details
-
DeepSeek-R1’s reasoning behaviors emerged through a structured RL framework that included:
- Reward-Based Training: The model was incentivized to provide correct and structured solutions through accuracy and format rewards. This helped shape behaviors like reflection and self-correction.
- Policy Optimization: Using GRPO, the model iteratively refined its reasoning processes based on feedback from sampled responses.
- Rejection Sampling: Intermediate outputs were filtered based on correctness, ensuring that only accurate and well-structured reasoning chains were reinforced.
- Cold Start Data: Unlike its predecessor, DeepSeek-R1-Zero, which purely relied on RL, DeepSeek-R1 was trained on curated long-form reasoning examples as a base, significantly improving its ability to structure logical steps coherently.
Example: Quadratic Equation Solving
-
Consider the problem:
\[x^2 - 5x + 6 = 0\]- The model initially proposes an incorrect factorization.
- It pauses to reevaluate and notices an inconsistency in the calculated roots.
- Upon reflection, it correctly factors the equation and derives \(x = 2, x = 3\).
-
This self-correcting behavior is illustrated in the table from the original paper:

Distillation: Reasoning in Compact Models
- DeepSeek-R1’s advanced reasoning capabilities were distilled into smaller models, including Qwen-7B and Llama-8B, through an optimized training pipeline designed to preserve reasoning depth while reducing computational complexity.
Implementation Details
- Teacher-Student Paradigm:
- DeepSeek-R1 was used as the “teacher” model.
- The distilled models (e.g., Qwen-7B, Llama-8B) were fine-tuned on 800K reasoning-related samples generated by DeepSeek-R1.
- Training Process:
- Unlike RL-based training for DeepSeek-R1, distilled models were trained primarily using SFT.
- The dataset included:
- 600K reasoning-based samples covering math, logical reasoning, and coding.
- 200K general-purpose samples to ensure well-rounded performance.
- Comparison Against RL Training:
- Experiments showed that distilling reasoning behaviors from DeepSeek-R1 was significantly more effective than training smaller models from scratch using RL.
- A direct RL-trained Qwen-32B model underperformed compared to the distilled DeepSeek-R1-Distill-Qwen-32B, highlighting the efficiency of distillation in preserving complex reasoning patterns.
- Performance Metrics:
- The table below showcases how distilled DeepSeek-R1 models compare against non-reasoning models like GPT-4o and larger models like OpenAI o1-mini.
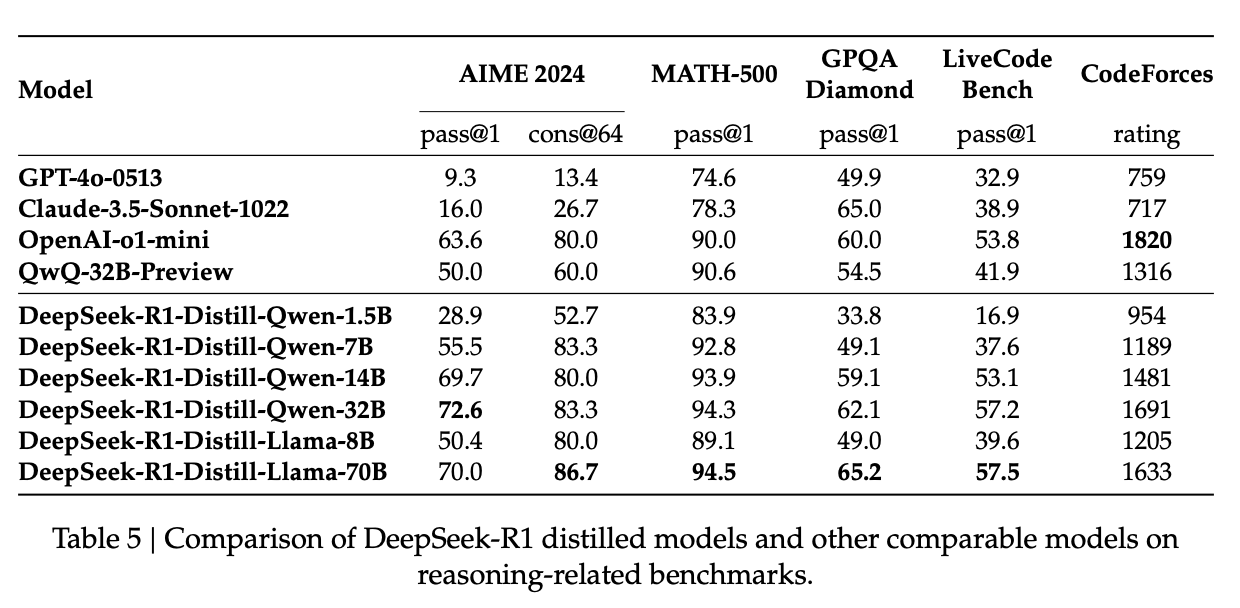
Results
-
The plot below from the paper illustrates the performance of DeepSeek-R1 across multiple benchmarks, showing it is on par with or even surpassing OpenAI’s models in several areas:
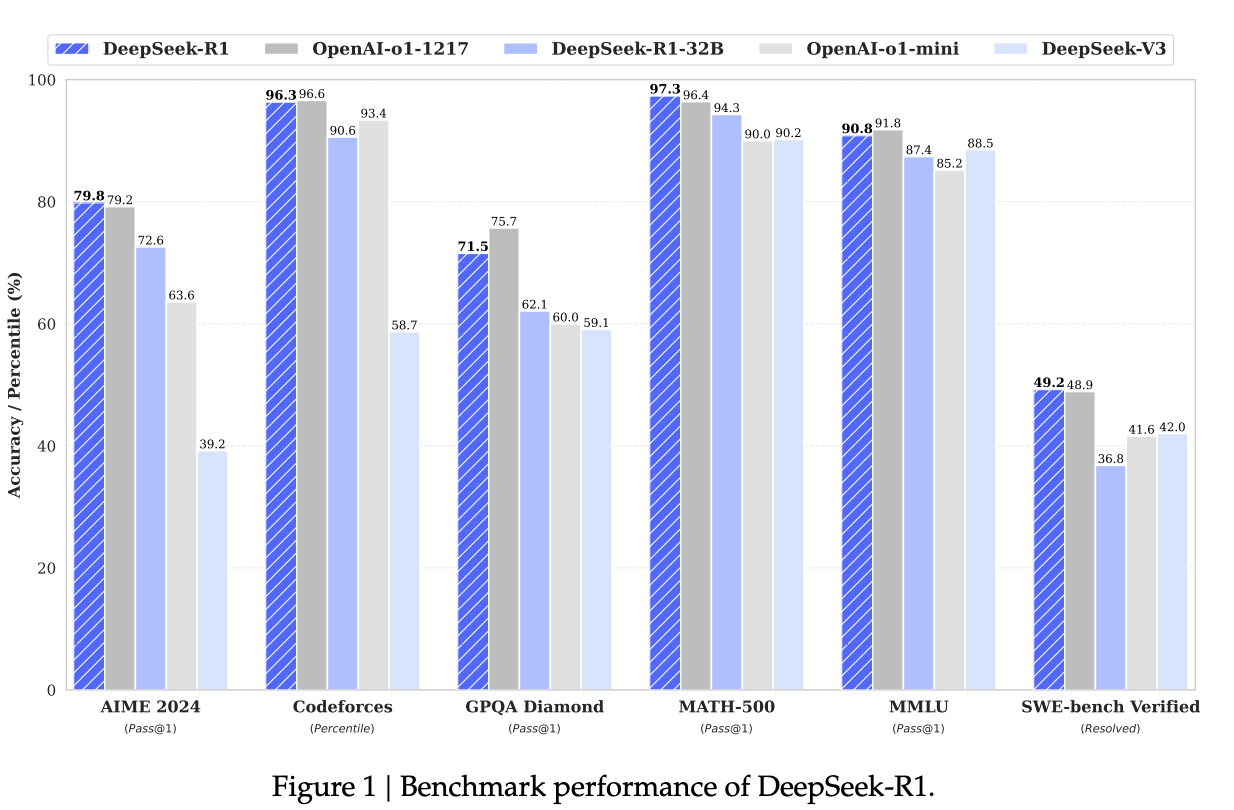
- Mathematical Reasoning: Achieved a 97.3% pass rate on MATH-500, outperforming previous open-source models.
- Code Competitions: Placed in the 96.3rd percentile on Codeforces, equivalent to expert-level human competitors.
- General Knowledge: Scored 90.8% on MMLU, demonstrating strong performance in broad knowledge domains.
-
DeepSeek-R1 represents a major leap in the ability of LLMs to develop, refine, and transfer complex reasoning skills. Its RL-based self-evolution and highly effective distillation pipeline set a new standard for reasoning models, enabling smaller models to achieve state-of-the-art performance with minimal computational overhead.
Average response length vs. Timesteps
- The plot below from the paper illustrates the average response length of DeepSeek-R1-Zero on the training set during the RL process. DeepSeek-R1-Zero naturally learns to use longer CoT to solve complex reasoning problems with more thinking time.
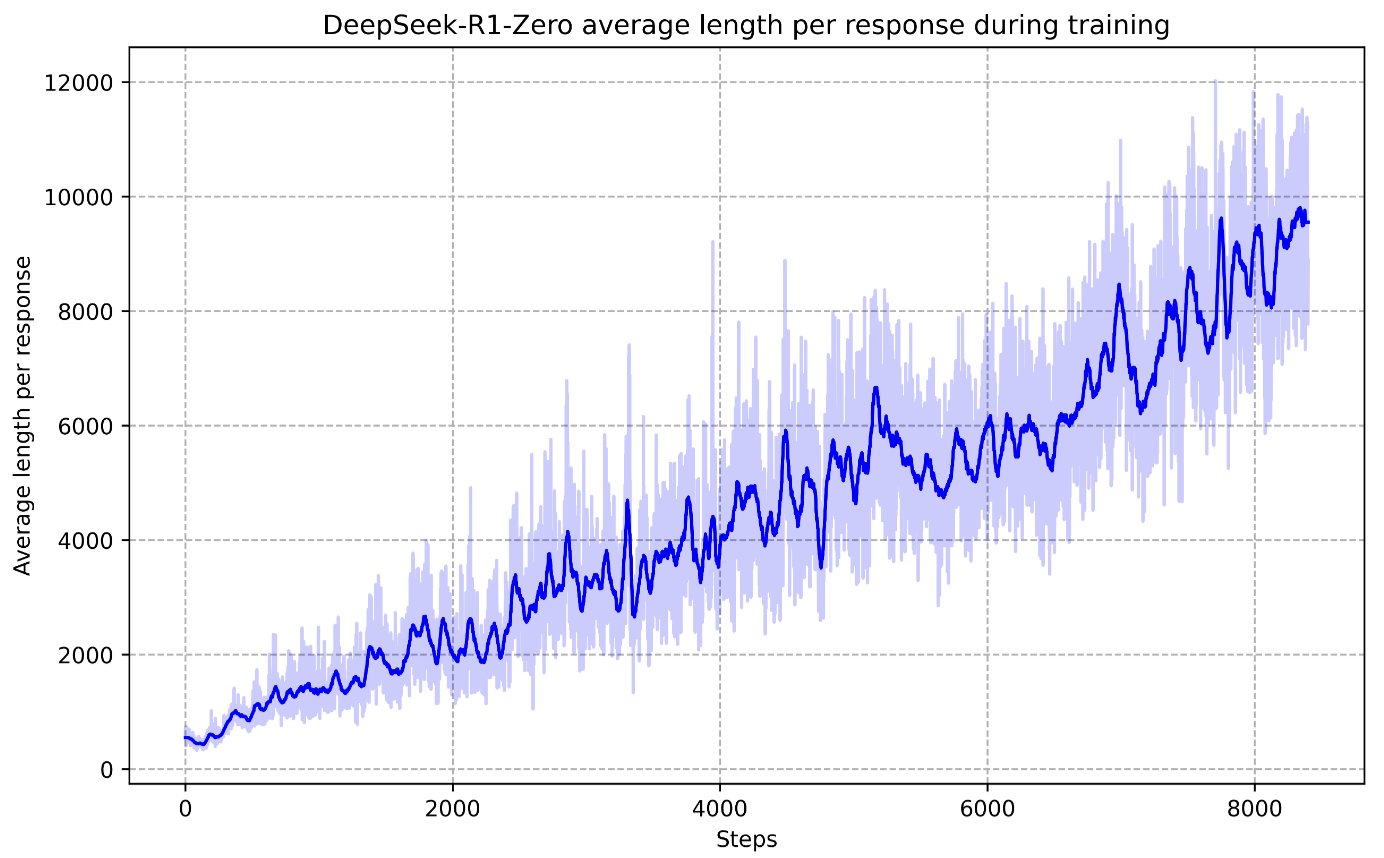
Comparison of DeepSeek-R1 and DeepSeek-R1-Zero
- DeepSeek-R1 and DeepSeek-R1-Zero represent two different approaches to RL training for enhancing reasoning capabilities in LLMs. The fundamental distinction between these models lies in their training methodologies, resulting in notable differences in their overall performance and usability.
Training Approach
- DeepSeek-R1-Zero is trained purely via RL, without any SFT as a cold start. This allows the model to develop reasoning capabilities through self-evolution but leads to certain drawbacks such as poor readability and language mixing.
- DeepSeek-R1, on the other hand, incorporates a multi-stage training process that begins with a cold-start SFT phase using high-quality long CoT data, followed by RL. This additional step helps improve stability, readability, and overall performance.
Performance Differences
- The differences in training methodologies translate into substantial variations in benchmark performance:
| Model | AIME 2024 (Pass@1) | MATH-500 (Pass@1) | GPQA Diamond (Pass@1) | LiveCodeBench (Pass@1) | Codeforces (Rating) |
|---|---|---|---|---|---|
| DeepSeek-R1 | 79.8% | 97.3% | 71.5% | 65.9% | 2029 |
| DeepSeek-R1-Zero | 71.0% | 95.9% | 73.3% | 50.0% | 1444 |
- DeepSeek-R1 achieves significantly higher performance across math reasoning (MATH-500), general knowledge (GPQA Diamond), and code competition benchmarks (Codeforces) compared to DeepSeek-R1-Zero.
-
The improved LiveCodeBench score suggests better performance in software engineering-related tasks.
- The following plot from the paper shows the AIME accuracy of DeepSeek-R1-Zero during training. For each question, they sample 16 responses and calculate the overall average accuracy to ensure a stable evaluation.
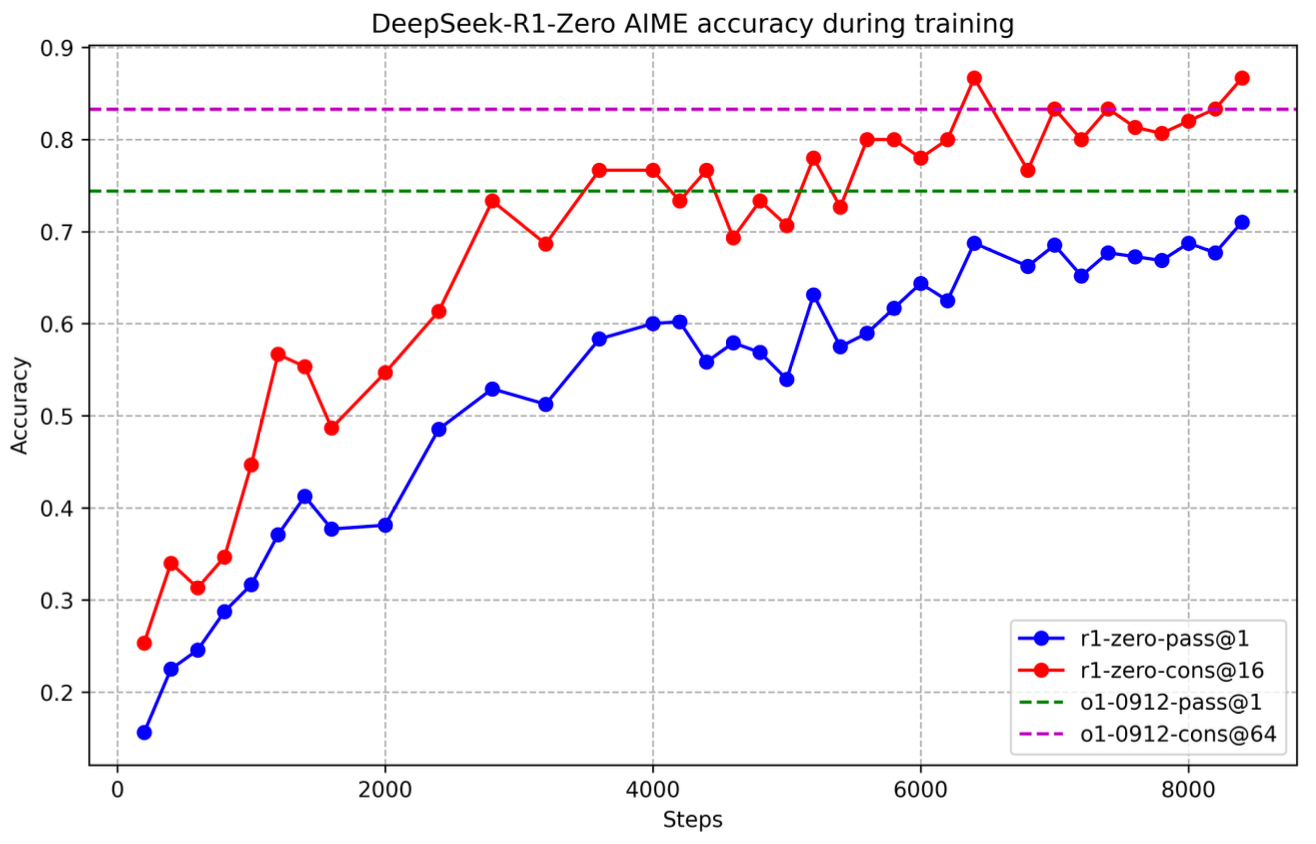
Readability and Language Consistency
- DeepSeek-R1-Zero, while effective in reasoning, suffers from language mixing and poor readability since it lacks constraints on output formatting.
- DeepSeek-R1 significantly improves readability by enforcing structured Chain-of-Thought reasoning and incorporating additional rejection sampling and supervised fine-tuning for human-friendly outputs.
Self-Evolution and “Aha Moments”
- One of the key observations during DeepSeek-R1-Zero training was the emergence of an “Aha Moment”, where the model learned to revise its reasoning process independently. This phenomenon underscores the potential of RL in developing sophisticated reasoning behaviors.
- However, DeepSeek-R1 further refines this capability by integrating rejection sampling, which filters out incorrect or incoherent responses, leading to a more robust and structured reasoning process.
Prompt Template
- Per OpenAI co-founder Greg Brockman, the following prompt template lists the breakdown of an o1 prompt which shows how to structure your prompts for more accurate, useful results.
- It includes:
- Goal: What you want.
- Return/Output Format: How you want it.
- Warnings: What to watch out for.
- Context: Extra details to improve accuracy.
- However, having the context go first in the prompt (while keeping the other of the other elements unchanged), might be more beneficial in some scenarios.
Open Questions
- As shown in the figure below (source), making a powerful reasoning model is now very simple if you have access to a capable base model and a high-quality data mixture:
-
Despite DeepSeek-R1’s advances, several open questions remain regarding its development and optimal implementation:
- Data Collection: How were the reasoning-specific datasets curated? Understanding the sources and selection criteria for data is crucial for replicating and improving the model’s performance.
- Model Training: No training code was released by DeepSeek, leaving uncertainty about which hyperparameters work best and how they differ across model families and scales.
- Scaling Laws: What are the compute and data trade-offs in training reasoning models? Identifying these relationships is critical for optimizing future models.
Other Reasoning Models
QwQ: Reflect Deeply on the Boundaries of the Unknown
- Developed by the Qwen Team, QwQ-32B-Preview is an experimental research model focusing on advancing AI reasoning.
- The model embodies a philosophical approach to problem-solving, constantly questioning its assumptions and refining its reasoning.
- Core strengths: Excels in mathematics and coding, showcasing deep analytical skills when given time to reflect on its reasoning process.
- Limitations: May exhibit recursive reasoning loops, unexpected language mixing, and requires enhanced safety measures for reliable deployment.
- Benchmark Performance:
- GPQA (Graduate-Level Google-Proof Q&A): 65.2% – demonstrating strong scientific reasoning.
- AIME (American Invitational Mathematics Exam): 50.0% – highlighting strong math problem-solving skills.
- MATH-500: 90.6% – exceptional performance across various math topics.
- LiveCodeBench: 50.0% – proving solid real-world programming capabilities.
- Reasoning Approach:
- Uses deep introspection and self-dialogue to refine answers.
- Prioritizes reflection over quick responses, mirroring human-like problem-solving strategies.
- Future Directions: The research extends into process reward models, LLM critique, multi-step reasoning, and reinforcement learning with system feedback.
- QwQ represents an evolving frontier in AI reasoning, pushing boundaries in understanding and self-correction.
s1: Simple Test-Time Scaling
- This paper by Muennighoff et al. from Stanford and UW introduces test-time scaling, a method that improves reasoning performance in large language models (LLMs) by leveraging extra compute at inference time. The authors propose budget forcing, a simple intervention that controls the duration of the model’s reasoning process, allowing it to self-correct and refine its answers.
- Main Contributions:
- Dataset Creation (s1K):
- A small dataset of 1,000 high-quality reasoning questions was curated from an initial pool of 59,000 samples.
- Selection was based on three criteria: difficulty, diversity, and quality.
- The final dataset was distilled from Google’s Gemini Thinking Experimental API.
- Budget Forcing (Test-Time Scaling Method):
- Allows control over how long the model “thinks” before generating an answer.
- Two key techniques:
- Early termination: If the model exceeds a threshold of “thinking tokens,” it is forced to provide an answer.
- Extended reasoning: The model is encouraged to continue reasoning by appending “Wait” to the generation when it tries to stop.
- Fine-Tuned Model (s1-32B):
- The Qwen2.5-32B-Instruct model was fine-tuned on s1K in just 26 minutes on 16 NVIDIA H100 GPUs.
- This model outperformed OpenAI’s o1-preview on math reasoning tasks like MATH and AIME24.
- Experimental Results:
- Scaling performance: Budget forcing allowed the model to exceed its baseline performance without test-time intervention.
- Competitiveness: s1-32B outperformed larger closed-source models and was the most sample-efficient among open-weight models.
- Ablations & Comparisons:
- Dataset selection: Carefully selected 1,000 samples performed better than using all 59,000 samples.
- Test-time scaling methods: Budget forcing showed superior control and performance compared to majority voting, rejection sampling, and conditional control methods.
- Parallel vs. Sequential Scaling: Budget forcing (sequential) was more effective than parallel methods like majority voting.
- Dataset Creation (s1K):
- Key Results:
- The s1-32B model, fine-tuned on just 1,000 reasoning examples, achieved 56.7% accuracy on AIME24, 93.0% on MATH500, and 59.6% on GPQA Diamond. Without any test-time intervention, the model’s AIME24 score was 50%, demonstrating that test-time scaling via budget forcing leads to significant improvements.
- By comparison, OpenAI’s o1-preview achieved 44.6% on AIME24, 85.5% on MATH500, and 73.3% on GPQA Diamond. Other open-weight models like DeepSeek r1 outperformed s1-32B but required over 800,000 training examples, while s1-32B achieved strong reasoning performance with only 1,000 carefully selected samples. The base model (Qwen2.5-32B-Instruct), before fine-tuning, scored just 26.7% on AIME24, highlighting the significant impact of s1K fine-tuning and test-time scaling.
- Conclusion:
- Test-time scaling via budget forcing is a lightweight yet powerful method for improving reasoning performance.
- Fine-tuning on just 1,000 carefully selected examples can match or outperform models trained on hundreds of thousands of samples.
- The approach is open-source, providing a transparent and reproducible path to improving LLM reasoning abilities.
- Code
Sky-T1
-
This blog by the NovaSky team at UC Berkeley introduces Sky-T1-32B-Preview, an open-source reasoning model that achieves performance comparable to o1-preview on reasoning and coding benchmarks while being trained for under $450. All code, data, and model weights are publicly available.
-
Motivation: Current state-of-the-art reasoning models like o1 and Gemini 2.0 demonstrate strong reasoning abilities but remain closed-source, limiting accessibility for academic and open-source research. Sky-T1 addresses this gap by providing a high-performing, fully transparent alternative.
- Key Contributions:
- Fully Open-Source: Unlike closed models, Sky-T1 releases all resources—data, training code, technical report, and model weights—allowing for easy replication and further research.
- Affordable Training: Sky-T1-32B-Preview was trained for only $450, leveraging Qwen2.5-32B-Instruct as a base model and fine-tuning it using 17K curated training samples.
- Dual-Domain Reasoning: Unlike prior efforts that focused solely on math reasoning (e.g., STILL-2, Journey), Sky-T1 excels in both math and coding within a single model.
- Data Curation:
- Uses QwQ-32B-Preview, an open-source model with reasoning capabilities comparable to o1-preview.
- Reject sampling ensures high-quality training data by filtering incorrect samples through exact-matching (for math) and unit test execution (for coding).
- Final dataset includes 5K coding problems (APPs, TACO), 10K math problems (AIME, MATH, Olympiad), and 1K science/puzzle problems (from STILL-2).
- Training Details:
- Fine-tuned on Qwen2.5-32B-Instruct for 3 epochs with a learning rate of 1e-5 and a batch size of 96.
- Training completed in 19 hours on 8 H100 GPUs, utilizing DeepSpeed Zero-3 offload for efficiency.
- The following figure from the blog shows the training flow of Sky-T1:

- Evaluation and Results:
- Matches or surpasses o1-preview in multiple reasoning and coding benchmarks:
- Math500: 82.4% (vs. 81.4% for o1-preview)
- AIME 2024: 43.3% (vs. 40.0% for o1-preview)
- LiveCodeBench-Easy: 86.3% (close to 92.9% of o1-preview)
- LiveCodeBench-Hard: 17.9% (slightly ahead of 16.3% for o1-preview)
- Performs competitively with QwQ (which has a closed dataset) while remaining fully open-source.
- Matches or surpasses o1-preview in multiple reasoning and coding benchmarks:
- Key Findings:
- Model size matters: Smaller models (7B, 14B) showed only modest gains, with 32B providing a significant leap in performance.
- Data mixture impacts performance: Incorporating math-only data initially boosted AIME24 accuracy from 16.7% to 43.3%, but adding coding data lowered it to 36.7%. A balanced mix of complex math and coding problems restored strong performance in both domains.
- Conclusion: Sky-T1-32B-Preview proves that high-level reasoning capabilities can be replicated affordably and transparently. By open-sourcing all components, it aims to empower the academic and open-source communities to drive further advancements in reasoning model development.
- Code
Kimi k1.5: Scaling Reinforcement Learning with LLMs
- This paper by the Kimi Team proposes Kimi K1.5, a state-of-the-art multimodal large language model (LLM) trained with reinforcement learning (RL). Unlike traditional LLMs that rely solely on pretraining and supervised fine-tuning, Kimi K1.5 expands its learning capabilities by leveraging long-context RL training, enabling it to scale beyond static datasets through reward-driven exploration. Kimi K1.5 demonstrates that scaling reinforcement learning with long-context training significantly improves LLM performance. The model leverages optimized learning algorithms, partial rollouts, and efficient policy optimization to achieve strong RL results without relying on computationally expensive techniques like Monte Carlo tree search.
- Additionally, the long-to-short (L2S) transfer process enables short-CoT models to inherit reasoning abilities from long-CoT models, drastically improving token efficiency while maintaining high performance.
- The model achieves state-of-the-art performance across multiple benchmarks. It scores 77.5 Pass@1 on AIME 2024, 96.2 Exact Match on MATH 500, 94th percentile on Codeforces, and 74.9 Pass@1 on MathVista, matching OpenAI’s o1 model. Additionally, its short-CoT variant outperforms GPT-4o and Claude Sonnet 3.5 by a wide margin, achieving up to 550% improvement on some reasoning tasks.
- Key Contributions:
-
Long-context scaling: Kimi K1.5 scales RL training to a 128K token context window, demonstrating continuous improvements in reasoning performance as the context length increases. Instead of re-generating full sequences, it employs partial rollouts to reuse previous trajectories, making training more efficient.
-
A simplified yet powerful RL framework: Unlike traditional RL-based models, Kimi K1.5 does not rely on complex techniques such as Monte Carlo tree search, value functions, or process reward models. Instead, it employs chain-of-thought (CoT) reasoning, allowing the model to develop planning, reflection, and correction capabilities without computationally expensive search mechanisms.
-
Advanced RL optimization techniques: Kimi K1.5 introduces a variant of online mirror descent for policy optimization, incorporating length penalties, curriculum sampling, and prioritized sampling to further enhance training efficiency and prevent overthinking.
-
Multimodal capabilities: The model is jointly trained on text and vision data, enabling it to reason across modalities. It performs well in OCR-based tasks, chart interpretation, and vision-based mathematical reasoning.
-
Long-to-Short (L2S) Training: The model introduces long2short methods that transfer reasoning patterns from long-CoT models to short-CoT models. These techniques significantly improve token efficiency, allowing the short-CoT version to achieve state-of-the-art results on benchmarks like AIME 2024 (60.8 Pass@1) and MATH 500 (94.6 Exact Match), surpassing GPT-4o and Claude Sonnet 3.5.
-
- Technical Details:
- Training Approach:
- The development of Kimi K1.5 involves multiple stages:
- Pretraining: The base model is trained on a diverse dataset spanning English, Chinese, code, mathematics, and general knowledge.
- Vanilla Supervised Fine-Tuning (SFT): The model is refined using a mix of human-annotated and model-generated datasets, ensuring high-quality responses.
- Long-CoT Fine-Tuning: A warmup phase introduces structured reasoning, teaching the model essential skills such as planning, evaluation, reflection, and exploration.
- Reinforcement Learning (RL): The model is further optimized with reward-based feedback, strengthening its ability to reason through complex problems.
- To ensure optimal RL training, Kimi K1.5 employs a carefully curated prompt set that spans multiple domains, balancing difficulty levels and ensuring robust evaluability. It also applies curriculum sampling (starting with easy tasks before progressing to harder ones) and prioritized sampling (focusing on problems where the model underperforms).
- Reinforcement Learning Infrastructure:
- Kimi K1.5 leverages an advanced RL training infrastructure to scale efficiently:
- Partial Rollouts: The model segments long responses into smaller chunks, preventing lengthy reasoning trajectories from slowing down training. This method allows parallel training of both long and short responses, maximizing compute efficiency.
- Hybrid Training Deployment: Training is conducted using Megatron, while inference is performed on vLLM, allowing dynamic scaling of resources.
- Code Sandbox for Coding RL: The model uses an automated test case generation system to evaluate coding solutions. It is optimized with fast execution techniques like Crun and Cgroup reuse to improve training speed and stability.
- The following figure from the paper shows the Kimi K1.5, a large scale reinforcement learning training system for LLM.

- Kimi K1.5 leverages an advanced RL training infrastructure to scale efficiently:
- Evaluation & Results:
- Kimi K1.5 achieves state-of-the-art results across multiple benchmarks:
- Long-CoT Model Performance:
- It matches or surpasses OpenAI’s o1 model in key reasoning tasks.
- On MATH 500, Kimi K1.5 achieves 96.2 Exact Match, outperforming other open-source models such as QwQ-32B (90.6).
- On AIME 2024, it reaches 77.5 Pass@1, improving over QwQ-32B (63.6).
- For coding tasks, it ranks in the 94th percentile on Codeforces, surpassing QwQ-32B (62nd percentile).
- In vision-based reasoning, it scores 74.9 Pass@1 on MathVista, ahead of OpenAI’s o1-mini (71.0).
- Short-CoT Model Performance:
- Kimi K1.5’s short-CoT model significantly outperforms GPT-4o and Claude Sonnet 3.5 on mathematical and coding reasoning tasks.
- It achieves 94.6 Exact Match on MATH 500, whereas GPT-4o scores 74.6 and Claude Sonnet 3.5 scores 78.3.
- On AIME 2024, Kimi K1.5 short-CoT achieves 60.8 Pass@1, far exceeding GPT-4o (9.3) and Claude Sonnet 3.5 (16.0).
- In LiveCodeBench, the model scores 47.3 Pass@1, outperforming GPT-4o (33.4) and Claude Sonnet 3.5 (36.3).
- Long-CoT Model Performance:
- Kimi K1.5 achieves state-of-the-art results across multiple benchmarks:
- Ablation Studies:
- Scaling Context Length vs Model Size:
- Smaller models can match the reasoning ability of larger models if trained with long-CoT and RL.
- However, larger models remain more token-efficient, meaning they require fewer tokens to achieve similar performance.
- Negative Gradients vs ReST (Reward-based Supervised Tuning):
- Kimi K1.5 outperforms ReST-based approaches by leveraging negative gradients during policy optimization, leading to more efficient training.
- Curriculum Sampling vs Uniform Sampling:
- Models trained with curriculum sampling (progressing from easy to hard problems) outperform those trained with uniform sampling.
- This approach accelerates learning and improves generalization on test problems.
- Scaling Context Length vs Model Size:
- Code
Open-R1
- While DeepSeek-R1 provides open weights, the datasets and code used in training remain proprietary. The aforementioned questions have driven the Open-R1 project, an initiative to systematically reconstruct DeepSeek-R1’s data and training pipeline as open-source, validate its claims, and push the boundaries of open reasoning models.
- The motivation behind building Open-R1 is to provide transparency on how RL can enhance reasoning, share reproducible insights with the open-source community, and create a foundation for future models to leverage these techniques.
Objectives of Open-R1
- Reproducing R1-Distill Models: By distilling a high-quality reasoning dataset from DeepSeek-R1, Open-R1 aims to replicate the R1-Distill models faithfully.
- Replicating the RL Training Pipeline: A critical component of DeepSeek-R1 is its RL-based training methodology. Open-R1 will curate large-scale datasets for mathematics, reasoning, and code to enable this training process.
- Advancing Multi-Stage Training: Demonstrating the full transition from a base model through SFT to RL will be a key milestone, ensuring a reproducible and scalable methodology.
- As shown in the figure below (source), here’s the Open-R1 plan:
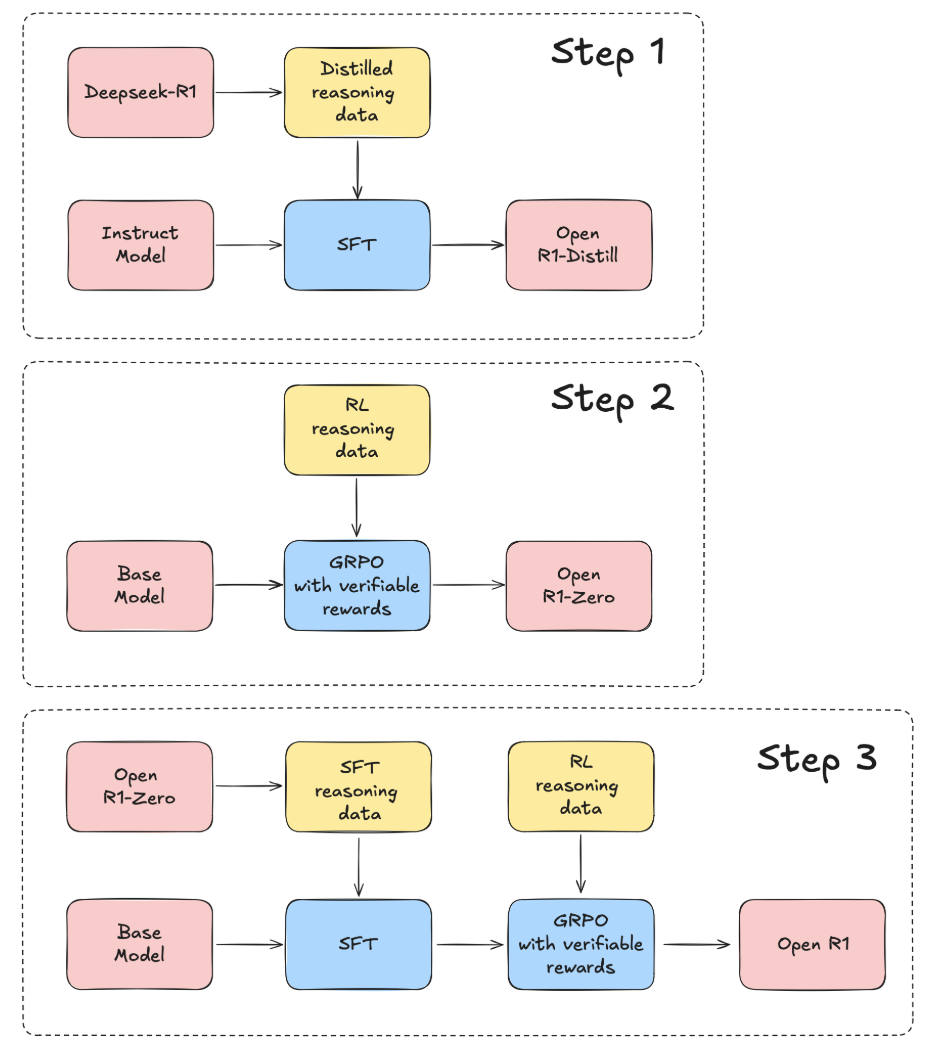
Impact on the Community
- Accessible Reasoning Models: Open-R1’s synthetic datasets will allow anyone to fine-tune existing or new LLMs for reasoning tasks simply by leveraging these datasets.
- Open RL Recipes: The initiative will provide well-documented RL methodologies that can serve as a foundation for future research and experimentation.
- Exploring Beyond Math: While mathematical reasoning is a primary focus, Open-R1 will explore extensions into other domains, including programming and scientific applications such as medicine, where reasoning models can make a significant impact.
DeepSeek R1-1776
- DeepSeek R1-1776 is an open-sourced version of the DeepSeek-R1 large language model, released by Perplexity. It has been post-trained to remove censorship and provide accurate, unbiased, and factual responses, particularly in politically sensitive areas.
- The original DeepSeek-R1 often avoided or deflected sensitive topics—especially those censored by the Chinese Communist Party (CCP)—by reverting to government-aligned talking points. This limited its usefulness for global users seeking uncensored information and objective analysis.
- R1 Post-Training Process:
- Data Collection for Post-Training: Perplexity identified ~300 CCP-censored topics with help from human experts and used these to train a multilingual censorship classifier. This classifier was used to mine a set of 40,000 multilingual user prompts from Perplexity’s customer data—explicitly permissioned and stripped of any PII—for model training.
- Generating High-Quality Responses: One major challenge was collecting factual, thoughtful responses to these censored prompts. Perplexity focused on gathering completions that included strong reasoning and diverse perspectives. Ensuring chain-of-thought reasoning traces was key to maintaining model depth.
- Post-Training with Nvidia NeMo 2.0: The post-training process was implemented using an adapted version of Nvidia’s NeMo 2.0 framework. This was designed to effectively de-censor the model while preserving its performance on academic and internal benchmarks, particularly for reasoning and factual accuracy.
- Rigorous Evaluation for Quality and Integrity: A multilingual evaluation set of over 1,000 examples was created to assess the model’s responses on censored and sensitive topics. Human annotators and LLM-based judges were used to score the likelihood of evasion or sanitization. The results showed that R1-1776 retained reasoning strength while eliminating censorship tendencies.
Open-Source Reasoning Datasets
- OpenThoughts: 114k samples distilled from R1 on math, code, and science.
- R1-Distill-SFT: 1.7M samples distilled from R1-32B on NuminaMath and Allen AI’s Tulu.
FAQs
Is GRPO a policy gradient algorithm?
- Yes, GRPO is a policy gradient algorithm. GRPO is a variant of PPO, which is itself a well-established policy gradient method.
- GRPO retains the core idea of using policy gradients but modifies the estimation of the advantage function by eliminating the need for a value (critic) model, instead using group-based reward comparisons to estimate the baseline. This makes GRPO more computationally efficient than traditional PPO while still relying on the same underlying reinforcement learning principles. So, GRPO falls squarely within the family of policy gradient algorithms.
Is GRPO an actor-critic algorithm?
- No, GRPO is not an actor-critic algorithm. According to the paper, GRPO is explicitly introduced as a variant of PPO (Proximal Policy Optimization), which foregoes the critic model. Instead of using a value function (critic) to compute the advantage estimates like PPO does, GRPO estimates the baseline using group scores derived from multiple sampled outputs per prompt. This significantly reduces the memory and computational burden compared to PPO.
- Here’s the key quote from the paper:
“GRPO foregoes the critic model, instead estimating the baseline from group scores, significantly reducing training resources compared to Proximal Policy Optimization (PPO).”
- Since actor-critic methods, by definition, require both an actor (policy) and a critic (value estimator), GRPO does not qualify as an actor-critic algorithm.
Can GRPO be applied to outcome supervision or process supervision or both? How is the advantage computed from reward in either case?
- GRPO flexibly handle different types of reward structures, thus supporting both outcome supervision and process supervision. Outcome supervision is simpler and computationally cheaper, while process supervision allows for more targeted improvements in reasoning quality.
- Here’s how GRPO can be applied to outcome supervision and process supervision:
Outcome Supervision
- In outcome supervision, GRPO provides a single scalar reward at the end of each model-generated output. This reward is applied uniformly to all tokens in the output, making it a straightforward method for reinforcement learning.
- For each question \(q\), a group of G outputs is sampled from the old policy model \(\pi_{\theta_{\text{old}}}\), denoted as:
- A reward model assigns a scalar reward to each output:
- These rewards are then normalized across the group using the sample mean and standard deviation:
- The resulting normalized reward \(\tilde{r}_g\) is then used as the advantage value for all tokens \(t\) in the corresponding output \(o_g\):
- This token-level advantage is plugged into the GRPO policy update objective, optimizing the model without the need for a critic (value function). The policy is updated using a clipped surrogate objective (as in PPO), but with these normalized group-based advantages.
Process Supervision
- Process supervision extends GRPO by providing rewards at intermediate reasoning steps, rather than only at the final output. This enables fine-grained credit assignment to different parts of the model’s reasoning.
- For each question \(q\), again a group of G outputs \(\{ o_1, o_2, \dots, o_G \}\) is sampled. Then, a process reward model evaluates each output step-by-step, assigning a list of scalar rewards per step. Let the rewards for each output \(o_g\) be:
- Here, \(\text{index}(j)\) refers to the ending token index of the \(j\)-th step in output \(o_g\), and \(K_g\) is the total number of reasoning steps in that output.
- These step-level rewards across all G outputs are collected into a set \(R\), then normalized:
- The token-level advantage \(\hat{A}_{g,t}\) for token \(t\) in output \(o_g\) is computed by summing the normalized rewards of all steps whose indices are greater than or equal to the token position:
- This allows the model to receive differentiated feedback for each part of its reasoning trace, encouraging improvement not just in final correctness but in intermediate steps as well.
- As with outcome supervision, these advantages are used in the GRPO objective to optimize the policy.
How is a reward model different from a value/critic model in policy optimization algorithms such as GRPO?
- The reward model and value (critic) model serve different roles in policy optimization, and GRPO makes a key distinction by removing the critic altogether. Here’s a clear breakdown.
Reward Model
- Purpose: Scores the quality of an entire output (or intermediate steps) based on some external or learned metric.
- Input: (Question, generated output)
- Output: A scalar reward, either:
- At the end of the output (outcome supervision), or
- At each reasoning step (process supervision)
- Learned from human preferences, correctness signals, or labels (e.g., “Output A is better than B”).
- Used to train the policy, by converting its scores into advantages for policy updates.
- In GRPO, this is the core signal used for policy optimization.
Value Model (Critic)
- Purpose: Advantage estimation, which is the task of estimating/predicting the expected/future reward (value) of being in a given state — it serves as a baseline to reduce variance when computing the advantage function.
- Input: (State or partial sequence)
- Output: Expected future reward from that point
- Trained during RL to minimize error between predicted and actual rewards.
- Used in PPO and other actor-critic methods, it helps stabilize training by estimating how good a state is, independent of specific actions taken.
Key Differences in GRPO
- GRPO does not use a value model.
- Instead, it uses group-based reward normalization to compute advantages, acting as a statistical baseline.
- This simplifies training and reduces memory cost, especially important for large language models.
- PPO and other classic methods rely on a trained value model, which is separate from the reward model and needs its own optimization loop.
Summary
| Feature | Reward Model | Value/Critic Model |
|---|---|---|
| What it predicts | External reward | Expected future reward |
| Input | Full or partial generated output | State or token context |
| Used in | GRPO, PPO, DPO, RFT, etc. | PPO, A2C, other actor-critic |
| Trained from | Human preferences / correctness | Bootstrapped from past rewards |
| Purpose | Supervises learning | Reduces variance in training |
| Required in GRPO? | Yes | No |
In the equation for GRPO, what is the role of the old policy compared to the reference policy?
-
In the equation for GRPO, the old policy and the reference policy serve distinct roles, both contributing to stable and effective training but in different ways:
- Old Policy:
- Used to generate a group of output samples \({o_1, o_2, \ldots, o_G}\) for each input question \(q\).
- These outputs are scored by the reward model, and their group-wise average reward is used as the baseline to compute advantages.
- The ratio between the current policy \(pi_{\theta}\) and the old policy \(\pi_{old}\) is used in the surrogate objective, similar to PPO, to ensure updates do not diverge too much from previously good-performing behavior.
- Reference Policy:
- Typically set to the initial supervised fine-tuned (SFT) model at each iteration.
- Used for KL divergence regularization: a penalty is applied if the current policy \(\pi_{\theta}\) deviates too far from this stable reference.
- Helps prevent over-optimization or collapse by anchoring the training process to a known good policy.
- So, in summary:
- The old policy is dynamic and updated throughout training to generate new candidate outputs.
- The reference policy is fixed per iteration and acts as a stability anchor through KL regularization.
- This dual-role setup enables GRPO to maintain training stability without requiring a value function, which is traditionally needed in PPO, thus saving computational resources and simplifying implementation.
Why is the PPO/GRPO objective called a clipped “surrogate” objective?
- The PPO (and its variants such as GRPO) objective is called a surrogate objective because it doesn’t directly optimize the true reinforcement learning objective — the expected return — but instead optimizes a proxy that is easier and safer to compute. Here’s why:
- True RL Objective is Unstable or Intractable:
- The actual objective in RL is to maximize expected reward over trajectories, which involves high variance and instability during training, especially for large models like LLMs. It often requires estimating complex quantities like the value function accurately over time, which is difficult in practice.
- Surrogate Objectives Improve Stability:
- Surrogate objectives simplify this by using:
- Advantage estimates to approximate how much better a new action is compared to the old one.
- Importance sampling ratios (like \(\frac{\pi_{\theta}{\pi_{old}}\)) to correct for the shift in policy.
- Clipping (in PPO and GRPO) to avoid overly large policy updates that might destabilize training.
- Surrogate objectives simplify this by using:
- Practical Optimization Benefits:
- By approximating the true objective, surrogate objectives allow for stable and efficient policy updates, which are essential in fine-tuning large models via reinforcement learning.
- In summary, it’s called a surrogate because it’s a well-designed stand-in for the true goal of maximizing reward, tailored to be safer and more effective for gradient-based optimization.
What are some considerations around the reasoning tokens budget in reasoning LLMs?
-
In reasoning LLMs, the reasoning token budget refers to how many tokens the model is allowed to generate during its reasoning process (e.g., for chain-of-thought or program-of-thought generation). Setting this budget is a tradeoff between solution quality and efficiency, and it can depend on several factors:
- Model Size and Capacity:
- Larger models can generally reason more effectively with fewer tokens, while smaller models may need more tokens to reach the same quality.
- However, allowing too many tokens may lead to overthinking or hallucinations, especially in smaller models.
- Task Complexity:
- For simple arithmetic or factual recall, a small budget (e.g., 32–64 tokens) might be enough.
- For more complex mathematical reasoning (e.g., proofs, multi-step algebra), models may need 128–512 tokens or more.
- Supervised vs. RL Fine-Tuning:
- During supervised fine-tuning, the reasoning length often follows the solution length in the training data.
- During reinforcement learning, especially with process supervision, the budget needs to be high enough to cover multiple steps but not so high that it encourages meaningless continuation. Common budgets range from 256 to 1024 tokens.
- Practical Considerations:
- Compute and memory constraints: longer generations require more memory and time, which affects batch sizes and training throughput.
- Prompt + output length must fit within the model’s context window (e.g., 4K or 8K tokens), especially during training with multiple examples concatenated.
- Empirical Tuning:
- In practice, the reasoning token budget is often set by experimenting: start with a safe maximum (e.g., 512 or 1024), observe performance, and adjust.
- Some papers also dynamically adjust the budget, allowing early stopping based on certain signals (e.g., confidence, reward saturation, or solution completeness).
- Hard vs. Soft Budgets:
- Hard budget: fixed maximum length. The model is forcibly cut off at that token count.
- Soft budget: guided by stop tokens or heuristics (e.g., end-of-solution markers, newline patterns), which allow variable-length reasoning up to a cap.
- Model Size and Capacity:
-
In summary, the reasoning token budget is typically tuned based on the model size, task demands, training stage, and empirical tradeoffs. A common starting point for complex reasoning tasks (like MATH or GSM8K) is 512–1024 tokens.
Further Reading
- DAPO: An Open-Source LLM Reinforcement Learning System at Scale
- DeepCoder: A Fully Open-Source 14B Coder at O3-mini Level
References
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- DeepSeek-R1: A Pure RL-based Reasoning Model
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
- DeepSeek-V3 Technical Report
- Open-R1: a fully open reproduction of DeepSeek-R1
- DeepSeek-R1: The MoE Fallacy and the True Source of Emergent Reasoning
- The Illustrated DeepSeek-R1
- DeepSeek-R1 and FP8 Mixed-Precision Training