Kimi K2
- Overview
- What is Kimi K2?
- Architecture
- Pre-Training
- Post-Training
- Evaluations
- Optimization with MuonClip
- Agentic Intelligence as a Paradigm
- References
Overview
-
Kimi K2 marks a shift from traditional static LLMs toward agentic intelligence, where models actively learn by interacting with dynamic environments rather than relying solely on pre-collected datasets. This paradigm aims to capture autonomous perception, planning, reasoning, and action capabilities that allow an LLM to extend beyond its training distribution. The implications are profound: instead of being limited to imitating human-written corpora, an agentic LLM can develop novel competencies by synthesizing data, exploring environments, and adapting in real time. This opens pathways for superhuman reasoning, tool orchestration, software development, and autonomy in real-world settings.
-
Agentic intelligence also reframes training challenges. Pre-training must not only instill broad priors efficiently, but also mitigate instability at trillion-scale. Post-training must generate actionable, verifiable behaviors even when agentic trajectories are rare in natural corpora. K2 addresses these challenges by combining MuonClip-stabilized training, large-scale agentic data synthesis, and multi-signal reinforcement learning (RL), producing one of the strongest open-source non-thinking models available today.
-
You can try it online here: kimi.com
-
Below is the overview of the flow from Kimi K2.
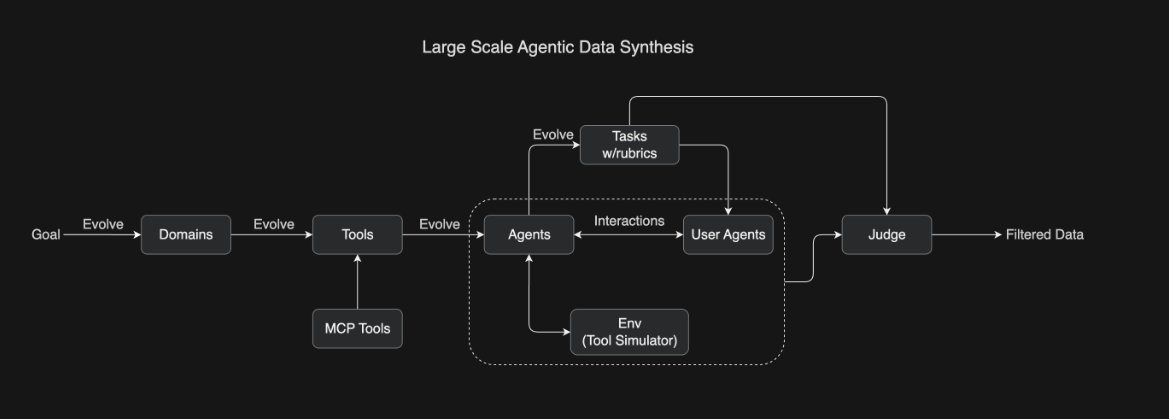
What is Kimi K2?
-
Kimi K2 is a Mixture-of-Experts (MoE) model with a total of 1 trillion parameters, but activates only 32 billion of them per forward pass. That makes it compute-efficient while still benefiting from massive scale.
-
The bigger story, though, is that Kimi K2 isn’t just a chat model. It’s designed for agentic behavior—planning, reasoning, using tools, and executing multi-step tasks autonomously.
-
Moonshot AI released two open-source variants:
Kimi-K2-Base: the raw pre-trained model, ideal for research and fine-tuningKimi-K2-Instruct: the post-trained, instruction-following model optimized for reflexive tasks
Architecture
-
Kimi K2 follows a similar Mixture-of-Experts setup as models like DeepSeek V3, but with some notable differences: more experts, fewer attention heads, and better load-balancing mechanisms to prevent collapse (where only a few experts dominate).
-
The model uses a 32-of-1024 MoE structure—meaning that only 32 experts are activated at any step. Despite this aggressive sparsity (just over 3% of the model is active during inference), performance remains strong across a wide range of tasks.
-
Here’s a simplified visual comparison (via Sebastian Raschka):
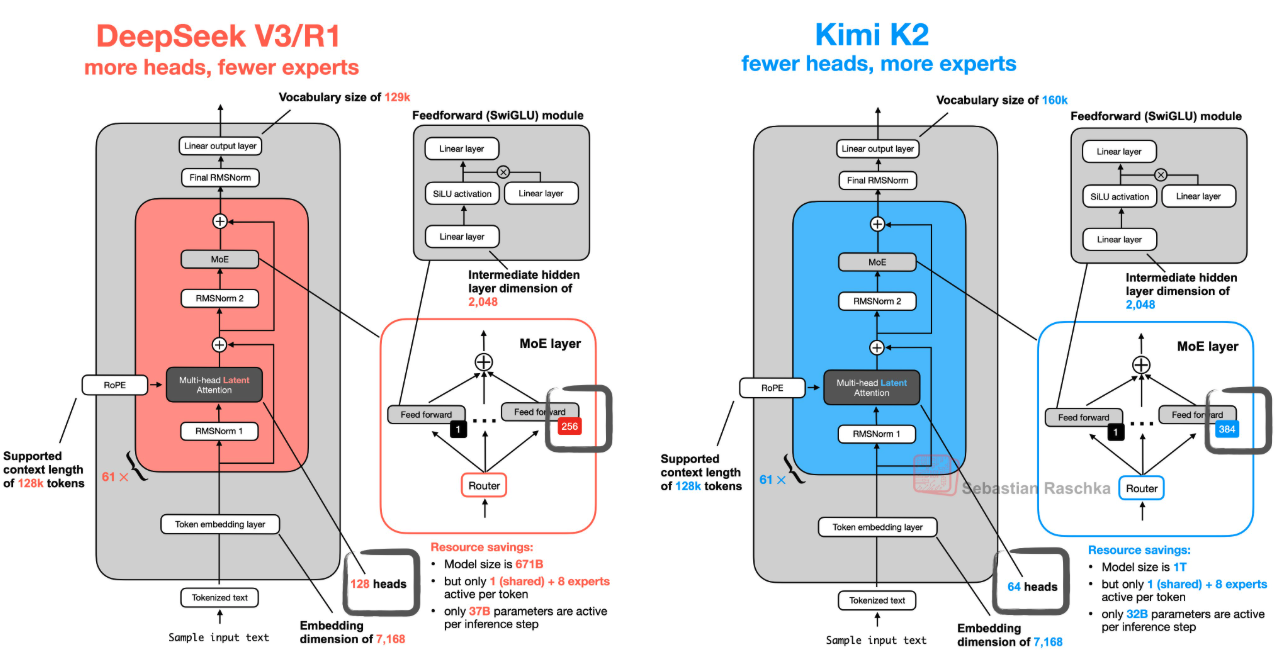
- This architecture helps Kimi K2 scale to a trillion parameters without becoming computationally impractical. The routing logic ensures that different parts of the model specialize, while training dynamics ensure no expert is left behind.
Pre-Training
MuonClip Optimizer
- Integration of token efficiency and stability: K2 introduces MuonClip, which combines the token-efficient Muon optimizer with a QK-Clip mechanism. While Muon improves learning signal per token, it suffers from unstable growth in attention logits at scale. QK-Clip constrains this growth by rescaling query and key weights whenever logits exceed a set threshold. Importantly, this rescaling does not alter forward/backward computations of the current step, ensuring that optimization dynamics are preserved. This mechanism prevents catastrophic loss spikes, enabling smooth training over 15.5T tokens without divergence【7†source】.
- Equation-driven clipping: For each attention head ( h ), the maximum attention logit is
[ S^{h}{\max} = \frac{1}{\sqrt{d}} \max{X \in B} \max_{i,j} Q^{h}i {K^h_j}^\top ]
and when ( S^{h}{\max} > \tau ), weights are rescaled using
[ W^h_q \leftarrow W^h_q \cdot \sqrt{\gamma_h}, \quad W^h_k \leftarrow W^h_k \cdot \sqrt{\gamma_h} ]
with ( \gamma_h = \min(1, \tau/S^{h}_{\max}) ). This per-head clipping minimizes unnecessary interventions while guaranteeing bounded logits.
Token Utility and Synthetic Rephrasing
- Knowledge rephrasing: Instead of multi-epoch repetition, which risks overfitting, K2 employs synthetic rephrasing pipelines. These include style- and perspective-diverse prompting for linguistic variety, chunk-wise autoregressive rewriting to maintain global coherence, and semantic fidelity checks to ensure alignment. Rephrasing amplifies knowledge tokens without sacrificing accuracy, with SimpleQA accuracy rising from 23.8% (multi-epoch) to 28.9% with 10× rephrasing.
- Mathematics augmentation: Mathematical corpora were rewritten into step-by-step learning notes, a technique inspired by SwallowMath. This reframing forces the model to internalize reasoning steps, improving downstream competition-level performance. Additionally, multilingual math sources were translated to English, increasing diversity and reasoning robustness.
Model Architecture
- Sparse scaling for trillion-parameter MoE: K2 uses 384 experts with sparsity 48 (8 active per token). Empirical scaling laws show higher sparsity reduces validation loss at constant FLOPs, yielding a 1.69× FLOP reduction versus sparsity 8 at equal performance.
- Attention head trade-off: Instead of doubling attention heads relative to layers (as in DeepSeek-V3), K2 halves this to 64 heads. Experiments revealed only marginal loss improvements (0.5–1.2%) but severe inference FLOP overhead (up to +83% at 128k tokens). Thus, K2 prioritizes long-context efficiency over minor gains.
Training Infrastructure
- Cluster and parallelism: Training ran on NVIDIA H800 clusters with 2 TB RAM per node, using 16-way pipeline parallelism, 16-way expert parallelism, and ZeRO-1 data parallelism.
- Memory optimizations: FP8-E4M3 activation compression, selective recomputation of SwiGLU/LayerNorm, and CPU activation offloading enabled stable trillion-scale training under limited GPU memory budgets.
- Training recipe: 15.5T tokens processed with a constant 2e-4 learning rate for 10T tokens, cosine decay for 5.5T, and a late-stage annealing phase. Context length was extended from 4k → 32k → 128k via YaRN. The training curve shows zero instability across all steps.
Post-Training
Supervised Fine-Tuning with Agentic Data
- Instruction diversity: Instruction-tuning datasets were synthesized using human annotations, prompt-engineered rephrasings, and automatic filtering via judge models.
- Agentic synthesis pipeline: Inspired by ACEBench, K2 built a hybrid pipeline that combined simulated environments with real execution sandboxes (e.g., coding tasks with unit tests). The process included (1) generating synthetic and real tool specifications (20k+ tools, 3k+ MCP), (2) creating diverse agents with toolsets, (3) generating rubric-verified tasks, and (4) simulating multi-turn trajectories judged against rubrics. This ensures both coverage and authenticity【7†source】.
Reinforcement Learning
- Dual reward signals: RL is scaled with verifiable tasks (math, logic, coding with executable judges) and self-critique rubric rewards (subjective domains like creativity and safety). The critic model continuously refines its rubric weights, grounding subjective judgments in verifiable performance.
- Training innovations: Budget control mechanisms penalize bloated outputs, PTX-loss integration preserves high-quality pre-training knowledge, and temperature decay schedules balance exploration versus convergence. This combination ensures that RL improves not just accuracy but also alignment with nuanced human values.
RL Infrastructure
- Checkpoint engine: Instead of parameter reshuffling via NFS, a distributed checkpoint system broadcasts full parameter states across nodes, reducing synchronization overhead and achieving sub-30s updates at trillion scale.
- Agentic rollout: Long-horizon tasks are accelerated with partial rollouts, environment parallelization, and latency amortization. The RL framework resembles a Gym-like interface, enabling integration of arbitrary new environments without overhead.
Evaluations
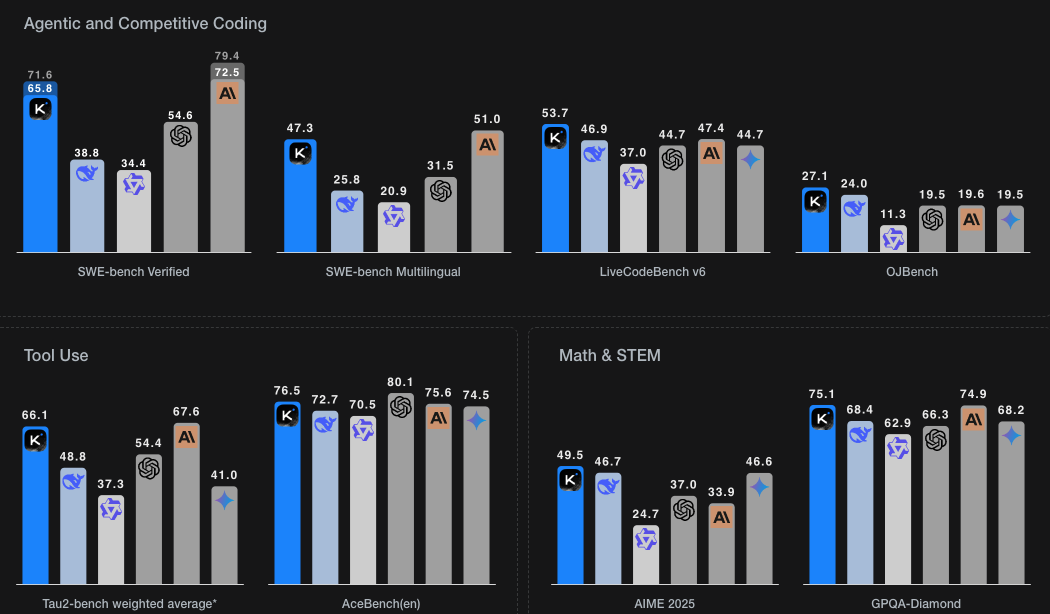
Coding & Engineering
- SWE-bench Verified (Agentic Single Attempt): 65.8%, closing in on Claude 4 Opus (72.5%).
- LiveCodeBench v6: 53.7%, surpassing GPT-4.1 and Claude Sonnet.
- OJBench: 27.1%, outperforming Gemini 2.5 Flash (19.5%).
These results make K2 the strongest open-source model for real-world and competitive coding.
Agentic Tool Use
- Tau2-Bench (multi-turn tool orchestration): 66.1 Pass@1.
- AceBench: 76.5 Accuracy, beating both DeepSeek-V3 and Claude Sonnet.
Demonstrates robust grounded tool-use reasoning, a central pillar of agentic intelligence.
Math & STEM
- AIME 2025: 49.5%, a leap over Qwen3 (24.7%).
- GPQA-Diamond: 75.1%, competitive with Claude Opus.
- HMMT 2025: 38.8%, best open-source score.
Confirms effectiveness of learning-note rephrasing and RL-verifiable task integration.
General and Long-Context
- MMLU: 89.5%, on par with proprietary models.
- MMLU-Redux: 92.7%, best among open-source.
- LongBench v2: 49.1%, competitive with GPT-4.1.
-
DROP: 93.5% factual reasoning accuracy.
K2 is not just specialized but a robust generalist across reasoning, factuality, and long-context domains. - We can see its performance below on different tasks as compared to DeepSeek V3 , Anthropic’s Claude 4 Opus, OpenAI’s GPT 4.1, Google’s Gemini 2.5, and Qwen3.
Optimization with MuonClip
-
Training trillion-scale models is hard. Most fall apart due to instability in attention mechanisms—particularly exploding logits during optimization.
-
Kimi K2 introduces a custom optimizer called MuonClip. It’s a refined version of the Muon optimizer, built specifically to handle these large MoE setups.
-
The key innovation is qk-clip, which dynamically rescales attention queries and keys at each training step to keep logits within safe bounds.
Agentic Intelligence as a Paradigm
Agentic intelligence shifts the operational foundation of LLMs from passive completion engines into adaptive, autonomous systems. With mechanisms like tool discovery, self-evaluation, rubric-based alignment, and hybrid real/synthetic environments, models like K2 point toward a new generation of AI that can continuously expand its competence frontier.
Instead of exhausting the diminishing returns of static pre-training data, agentic models generate their own trajectories of action and error-driven improvements, effectively becoming self-sustaining learners. This has implications not just for research (where scaling laws may plateau without agentic data), but also for real-world deployment, where autonomy, reliability, and grounded tool use are indispensable.
K2 demonstrates that building such systems requires innovations across optimization (MuonClip), data curation (synthetic rephrasing and tool pipelines), reinforcement (RLVR + rubric rewards), and infrastructure (checkpoint engines, agentic rollouts). It is not merely a model, but a framework for future AI systems that blur the line between static foundation models and interactive, evolving agents.