Motivation
- Amazon music’s biggest use case is when people use Alexa devices, such as echo, and ask Alexa to play them music. Hard Samples in music, such as “Alexa play good music”, is something we struggle with.
- We leverage/finetune Amazon Alexa’s Foundation model to help with understanding intent and output correct API calls to our downstream recommender system models that can help generate these recommendations.
Intent Identification
- Mood-Based Requests: “Play something upbeat,” “I need a relaxing playlist.”
- “Play something upbeat” → API Call: GET /songs?mood=upbeat
- “I need a relaxing playlist” → API Call: GET /playlists?mood=relaxing
- Genre-Based Requests: “Put on some classic rock,” “Can you play jazz music?”
- “Put on some classic rock” → API Call: GET /songs?genre=classic_rock
- “Can you play jazz music?” → API Call: GET /songs?genre=jazz
- Data Collection:
- Gather labeled data: Assemble a dataset where each input represents a user’s music-related query, and the corresponding output is the appropriate API function
- Data augmentation: Increase the variety of your dataset by rephrasing music requests, introducing typical misspellings, or using diverse ways to request music.
- Fine-tuning Titan to emit the APIs
Architecture
- Options:
- Prompting:
- Lost in the middle: not all regions in the prompt are treated differently
- RAG: Ingestion, Retrieval, Synthesis
- Chain of Verification,
- Chain of Thought (let’s think step by step),
- Tree of Thought (ToT): Used to solve complex problems, the ToT approach could be exemplified by breaking down a math problem into a tree of possible step-by-step solutions, evaluating each ‘branch’ for its validity, and selecting the most promising path to reach the correct answer.
- Context length extension: Interpolation on Positional embedding b/w each integer index
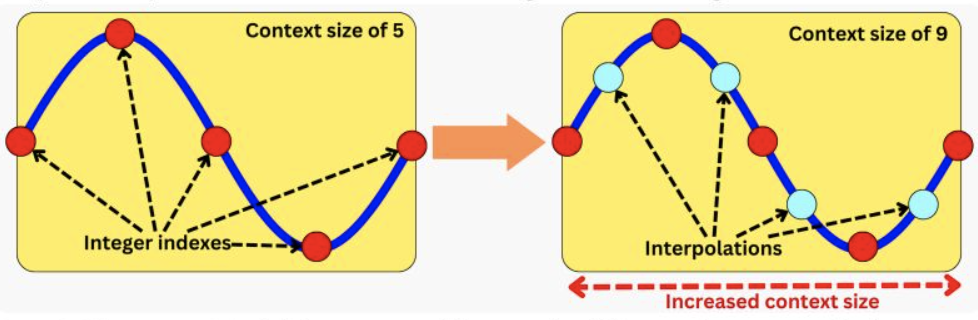
- Supervised Fine-tuning:
- Full Finetuning off the table: cost-benefit analysis
- Instruction Tuning:
- (FLAN) was the first to introduce instruction tuning which finetunes the model on a large set of varied instructions that use a simple and intuitive description of the task, such as “Classify this movie review as positive or negative,” or “Translate this sentence to Danish.”
- “Creating a dataset of instructions from scratch to fine-tune the model would take a considerable amount of resources. Therefore, we instead make use of templates to transform existing datasets into an instructional format.” (source)
- PEFT:
- LoRA:low-rank matrices into the model’s layers. This approach reduces the number of trainable parameters, making the process more memory-efficient and faster.
- QLoRA: Quantized LoRA
Evaluation
- Quantitative Metrics:
- Accuracy: Calculate the percentage of user queries that the model classifies correctly into the intended API functions
- Precision, Recall, and F1-score: Especially important if there’s a class imbalance in the API functions. For instance, if users more frequently request to play by mood than to play the genre.
- Confusion Matrix: Understand which categories or intents are commonly misinterpreted.
- Qualitative Analysis:
- User Testing: Engage a diverse group of users to interact with the model in a real-world setting. Gather feedback regarding its accuracy, relevance of music choices, and overall user satisfaction.
- Error Analysis: Manually review a subset of mis-classifications to identify common themes or patterns. This might reveal, for instance, that the model struggles with recognizing certain genres or artists.
- Real-world Performance Metrics:
- Engagement Metrics: Monitor how often users engage with the music played. A decrease in skips or an increase in full song plays can be indicators of good recommendations.
- Retention Rate: Measure how often users return to use the recommendation feature. A higher return rate can indicate user satisfaction.
- Feedback Collection: Allow users to provide feedback directly (e.g., “this wasn’t what I was looking for”) and use this feedback to iteratively improve the model.
- Guardrail metrics