NLP • LLM Context Length Extension
- Overview
- NTK-Aware Method
- Dynamic NTK Method
- Extending Context Window of Large Language Models via Position Interpolation
- LongLora: Efficient Fine-tuning of long-context Large Language Models
- MEGALODON
- Infini-attention
- Conclusion
- Citation
Overview
- The increasing application of Large Language Models (LLMs) across sectors has highlighted a significant challenge: their predefined context lengths. This limitation impacts efficiency, especially when applications require the processing of extensive documents or large-scale conversations. While directly training LLMs on longer contexts is a potential solution, it is not always efficient and can be resource-intensive.
- This article will discuss various methods aimed at enhancing the context length of LLMs.
- Context length serves as a vital parameter determining the efficacy of LLMs. Achieving a context length of up to 100K is notable. The value of such an achievement, however, might be perceived differently with the progression of time and technology.
- One primary use-case for LLMs is to analyze a large set of custom data, such as company-specific documents or problem-related texts, and to answer queries specific to this dataset, rather than the generalized training data.
- Let’s take a look at existing Solutions to Address Context Length Limitations:
- Summarization & Chained Prompts: Current approaches often involve the use of sophisticated summarization methods coupled with chained prompts.
- Vector Databases: These are used to store embeddings of custom documents, which can then be queried based on similarity metrics.
- Fine-Tuning with Custom Data: This method, while effective, is not universally accessible due to restrictions on certain commercial LLMs and complexities with open-source LLMs.
-
Customized LLMs: Developing smaller, data-centric LLMs is another solution, though it presents its own set of challenges.
- Advantages of Extended Context Length:
-
An LLM with an expanded context length can offer more tailored and efficient interactions by processing user-specific data without the need for model recalibration. This on-the-fly learning approach, leveraging in-memory processing, has the potential to enhance accuracy, fluency, and creativity.
- Analogy for Context: Similar to how computer RAM retains the operational context of software applications, an extended context length allows an LLM to maintain and process a broader scope of user data.
- In this article, we aim to present a detailed examination of methods focused on increasing the context length, emphasizing their practical implications and benefits.
NTK-Aware Method
- This method addresses the issue of extending the context window by considering the impact on the model’s ability to handle high-frequency components in the data.
- In neural networks, especially those used in language processing, high-frequency components are crucial for capturing fine-grained details and nuances in the text.
- The “NTK” in “NTK-Aware” refers to the Neural Tangent Kernel, a theoretical framework that describes how the output of a neural network changes in response to small changes in its parameters.
- When extending the context window, the NTK-Aware method makes adjustments to the model to ensure it doesn’t lose its sensitivity to these high-frequency components. This could involve tweaking the weights or architecture of the network in a way that compensates for the potential loss of detail that could occur when processing longer sequences.
Dynamic NTK Method
- While the NTK-Aware method makes static adjustments based on NTK theory, the Dynamic NTK method takes this a step further by making these adjustments adaptable to the length of the input sequence.
- This means that the model doesn’t just have a fixed setting for extended contexts; instead, it dynamically alters its processing based on the actual length of the sequence it’s dealing with at any given moment.
- For instance, if the model is handling a sequence close to its original training length, the adjustments might be minimal. But as the sequence length increases, the Dynamic NTK method scales the adjustments accordingly.
- This dynamic scaling is likely achieved by altering the model’s internal parameters, such as attention weights or other factors that influence how it processes different parts of the input.
- The NTK-Aware method is about making specific adjustments to preserve the model’s ability to process high-frequency information in extended contexts, while the Dynamic NTK method allows these adjustments to vary depending on the length of the input, providing a more flexible and efficient way to handle varying context sizes.
Extending Context Window of Large Language Models via Position Interpolation
- This paper introduces a technique called Position Interpolation (PI) to extend the context length of large language models (LLMs) like LLaMA without compromising their performance.
- LLMS use positional encodings, such as RoPE, to represent the order of tokens in a sequence. However, naively fine-tuning these models on longer contexts can be slow and ineffective, especially when extending the context length by a large factor (e.g., 8 times).
- The key insight behind PI is that extrapolating positional encodings beyond the trained range can result in unstable and out-of-distribution attention scores. Instead, PI interpolates between the trained integer steps to create smooth and stable positional encodings.
- To do this, PI downscales the positional indices before computing the positional encodings. For instance, if the original context length is 4096, PI rescales the indices from [0, 4096] to [0, 2048], matching the original length. This effectively interpolates the positional encodings between the original integer steps, reducing the maximum relative distance and making the attention scores more stable.
- During fine-tuning, the model adapts quickly to the interpolated positional encodings, which are more stable than extrapolated ones. The authors prove that the interpolated attention score has a much smaller upper bound than the extrapolated attention score, ensuring that the model’s behavior remains consistent and predictable.
- Experiments demonstrate that PI successfully extends models like LLaMA-7B to handle context lengths of up to 32768 with only 1000 training steps. Evaluations on various tasks, such as language modeling, question answering, and retrieval, confirm that the extended models effectively leverage long contexts without sacrificing performance on shorter contexts.
- Thus, Position Interpolation offers a simple yet effective way to extend the context length of LLMs like LLaMA. By downscaling positional indices and interpolating between trained integer steps, PI creates smooth and stable positional encodings, enabling models to adapt to longer contexts without losing stability or performance.
- The technique was originally proposed by u/emozilla on Reddit as “Dynamically Scaled RoPE further increases performance of long context LLaMA with zero fine-tuning” and allows us to scale out the context length of models without fine-tuning by dynamically interpolating RoPE to represent longer sequences while preserving performance.
- While it works well out of the box, performance can be further improved by additional fine-tuning. With RoPE scaling, companies can now easily extend open-source LLMs to the context lengths which work for their given use case.
- From the Reddit post:
- “When u/kaiokendev first posted about linearly interpolating RoPE for longer sequences, I (and a few others) had wondered if it was possible to pick the correct scale parameter dynamically based on the sequence length rather than having to settle for the fixed tradeoff of maximum sequence length vs. performance on shorter sequences. My idea was to use the exact position values for the first 2k context (after all, why mess with a good thing?) and then re-calculate the position vector for every new sequence length as the model generates token by token. Essentially, set scale to original model context length / current sequence length. This has the effect of slowly increasing scale as the sequence length increases.
- I did some experiments and found that this has very strong performance, much better than simple linear interpolation. When u/bloc97 posted his NTK-Aware method, it was much closer to this dynamic linear scaling in terms of performance. Compared to dynamic linear scaling, NTK-Aware has higher perplexity for shorter sequences, but better perplexity at the tail end of the sequence lengths. Unfortunately, it also suffers from catastrophic perplexity blowup, just like regular RoPE and static linear scaling.
- The main hyperparamter of NTK-Aware is \(\alpha\). Like static linear scaling, it represents a tradeoff between short/long sequence performance. So I thought, why not use the same dynamic scaling method with NTK-Aware? For Dynamic NTK, the scaling of \(\alpha\) is set to (\(\alpha\) * current sequence length / original model context length) - (\(\alpha\) - 1). The idea again is to dynamically scale the hyperparameter as the sequence length increases.
- This uses the same methodology as NTK-Aware (perplexity on GovReport test). You can check out all the code on GitHub.”
- Hugging Face Transformers now supports RoPE-scaling (rotary position embeddings) to extend the context length of large language models like LLaMA, GPT-NeoX, or Falcon.
- So in essence, RoPE scaling dynamically rescales relative position differences based on the input length, analogous to a rope stretching and contracting.
Deeper Dive into how LLama 2’s context window increased
- Why LLama 2 is a Preferred Choice for Large Context Windows:
- LLama 2, despite initially appearing to have a smaller context window size (4096 tokens or approximately 3000 words) compared to models like ChatGPT, GPT-4, and Claude 2, offers significant advantages due to its open-source nature and the innovative use of Rotary Positional Embeddings (RoPE).
- Understanding the Typical Transformer Architecture:
- Most transformer models, including LLama 2, consist of:
- Embeddings: Used to encode the text input.
- Transformer Blocks: Execute the primary processing tasks.
- Prediction Head: Tailored to the learning task at hand.
-
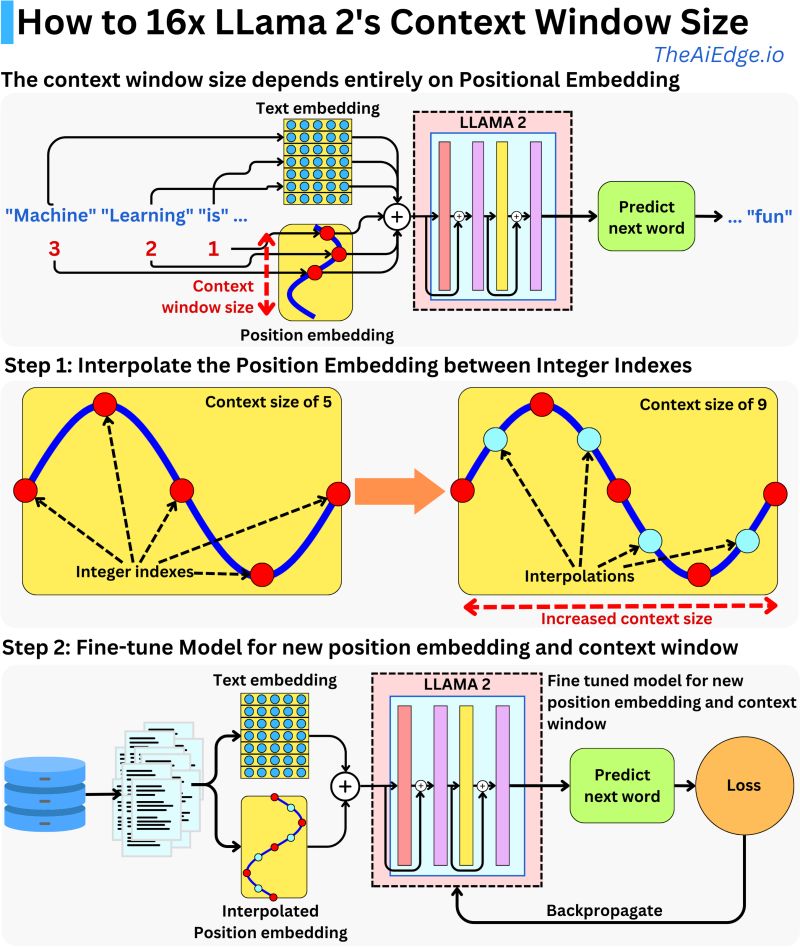
The context size, or the amount of text the model can consider at once, is defined by the size of the positional embedding, which combines with the text embedding matrix to encode text.
- Rotary Positional Embeddings (RoPE) in LLama 2:
- LLama 2 uses Rotary Positional Embeddings (RoPE), distinguishing it from models that use typical sine function encoding. This method modifies each attention layer in such a way that the computed attention between input tokens is solely dependent on their distance from each other, rather than their absolute positions in the sequence. This relative positioning allows for more flexible handling of context windows.
- Extending the Context Window with Interpolation:
- Meta, the developer of LLama 2, employs a technique to extend the context window by interpolating at non-integer positions, allowing the model to process text inputs much larger than its original window size, maintaining its performance level.
- Implementation:
- The practical implementation of extending the context window involves rescaling the integer positions, and a minor modification in the model’s code can accomplish this. Despite the model not being initially trained for extended position embedding, it can be fine-tuned to adapt to the new context window and can dynamically adjust to the user’s needs, especially when it’s used to fine-tune on private data.
- LLama 2’s approach to positional embeddings and its open-source nature make it a versatile choice for tasks requiring large context windows. With simple modifications and fine-tuning, it can adapt to varying needs while maintaining optimal performance, proving to be a highly flexible and efficient model. The research and methodology involved can be further explored in the provided method link.
Interpolation and how it increases context length
- What is interpolation at non-integer positions?
- Interpolation is a mathematical method to determine unknown values between two known values. In the context of the LLama 2 model, “interpolating at non-integer positions” refers to a technique where the positions of tokens (pieces of data or text) are adjusted to fit within the model’s original context window, even if the data extends beyond it.
- Instead of using whole numbers (integers) for positions, this method utilizes values between whole numbers (non-integers).
- Why do they do this?
- By using this interpolation method, LLama 2 can process text inputs that are much larger than its designed capacity or its original window size.
- What is the benefit?
- The advantage of this technique is that despite processing larger chunks of data, the model doesn’t suffer in performance. It can handle more data while still operating effectively.
- In simpler terms: Meta has used a clever method to let LLama 2 handle more data at once without slowing it down or reducing its effectiveness. They achieve this by adjusting the way data positions are calculated, using values between whole numbers.
- The image below by Damien Benveniste illustrates the interpolation concept in detail.
LongLora: Efficient Fine-tuning of long-context Large Language Models
- The paper proposes an efficient method called LongLoRA to fine-tune large pre-trained language models like LLaMA2 to much longer context lengths, while retaining their original architectures. The key ideas are:
- Shift Short Attention (S2-Attn): During fine-tuning, standard full self-attention is very costly for long contexts. S2-Attn approximates the full attention using short sparse attention within groups of tokens. It splits the sequence into groups, computes attention in each group, and shifts the groups in half the heads to allow information flow. This is inspired by Swin Transformers. S2-Attn enables efficient training while allowing full attention at inference.
- Improved LoRA: Original LoRA only adapts attention weights. For long contexts, the gap to full fine-tuning is large. LongLoRA shows embedding and normalization layers are key. Though small, making them trainable bridges the gap.
- Compatibility with optimizations like FlashAttention-2: As S2-Attn resembles pre-training attention, optimizations like FlashAttention-2 still work at both train and inference. But many efficient attention mechanisms have large gaps to pre-training attention, making fine-tuning infeasible.
- Evaluation: LongLoRA extends the context of LLaMA2 7B to 100k tokens, 13B to 64k tokens, and 70B to 32k tokens on one 8x A100 machine. It achieves strong perplexity compared to full fine-tuning baselines, while being much more efficient. For example, for LLaMA2 7B with 32k context, LongLoRA reduces training time from 52 GPU hours to 24 hours.
- The image below from the original paper displays shift short attention in action.
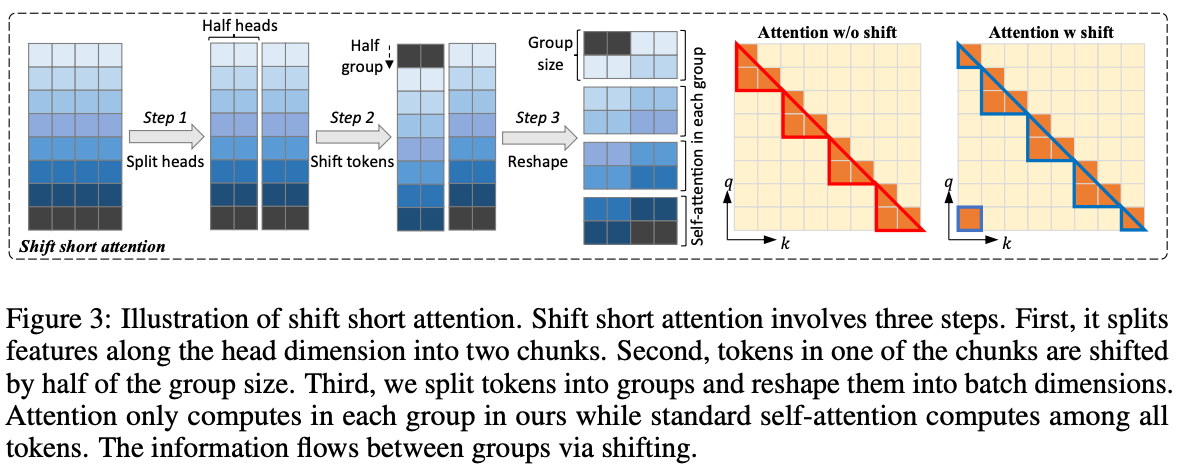
- In summary, the key novelty is using shift short attention to enable efficient long context fine-tuning of pre-trained LLMs, while retaining their full attention at inference. Making select small parameter layers trainable is also an important finding. LongLoRA provides an efficient way for researchers to extend LLMs to longer contexts without extensive resources. The compatibility with optimizations is also a notable advantage.
MEGALODON
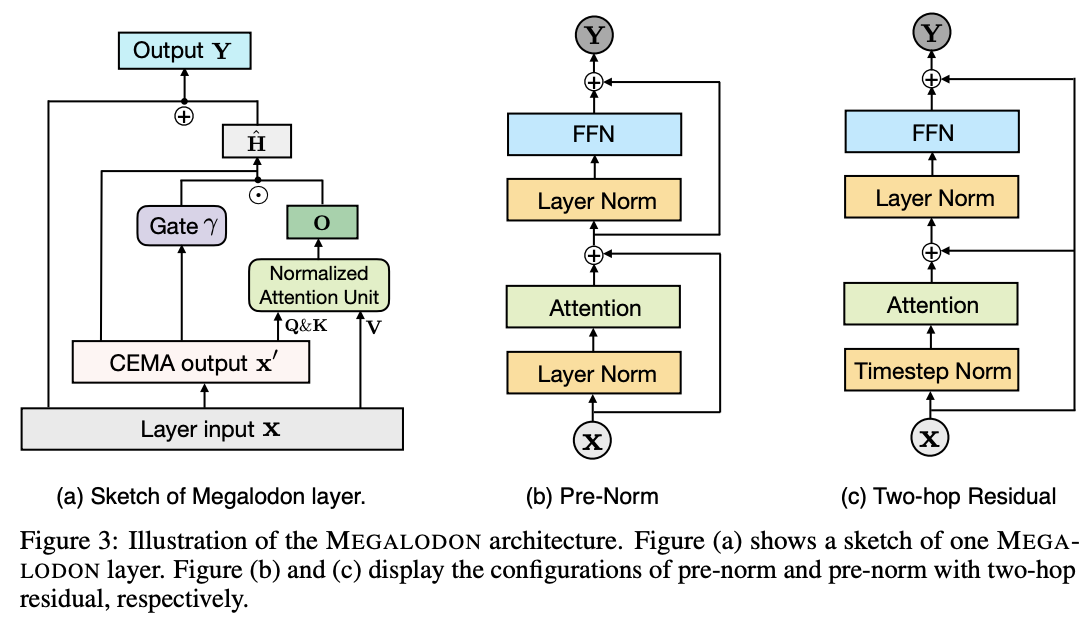
- MEGALODON by Meta introduces a new neural architecture designed to handle unlimited context length efficiently, addressing the limitations of traditional Transformer models which struggle with quadratic complexity and length extrapolation.
- The architecture incorporates Complex Exponential Moving Average (CEMA), which extends the exponential moving average to the complex domain. This allows for more nuanced and detailed processing of sequential data over long periods.
- Timestep Normalization Layer is a generalization of the group normalization layer for autoregressive sequence modeling. It normalizes along the sequential dimension, which helps manage internal covariate shifts during long sequence processing.
- MEGALODON uses a modified attention mechanism that includes normalization processes to improve the model’s stability and performance across long sequences.
- Pre-Norm with Two-Hop Residual Configuration component alters the typical pre-and post-normalization approaches, helping to stabilize training and enhance the model’s ability to learn from complex, lengthy inputs.
- By chunking input sequences into fixed blocks (as in MEGA-chunk), MEGALODON achieves linear computational and memory complexity, both in model training and inference, which is a significant improvement over traditional models.
- These technical innovations allow MEGALODON to surpass other large language models in efficiency and effectiveness, particularly in tasks that involve extensive data sequences.
- MEGALODON is a neural architecture designed for efficient sequence modeling with unlimited context length, utilizing advancements like Complex Exponential Moving Average (CEMA) and normalized attention mechanisms to handle long sequences more effectively than traditional Transformer models.
- Innovations Introduced:
- Timestep normalization layer to manage internal covariate shifts during sequence processing.
- Normalized attention mechanism to improve model stability and performance.
- Pre-norm layer with a two-hop residual configuration for enhanced learning from complex inputs.
- Computational Efficiency: Achieves linear computational and memory complexity by chunking input sequences into fixed blocks.
- Performance Evaluations:
- Superior at handling long-context modeling and QA tasks, demonstrating capability with context lengths up to 2M tokens.
- Outperforms traditional Transformer models, including LLAMA2-7B, across various benchmarks and tasks.
- Broad Applicability: Shows robust improvements across both large-scale and small/medium-scale benchmarks, confirming its effectiveness in diverse settings.
Infini-attention
-
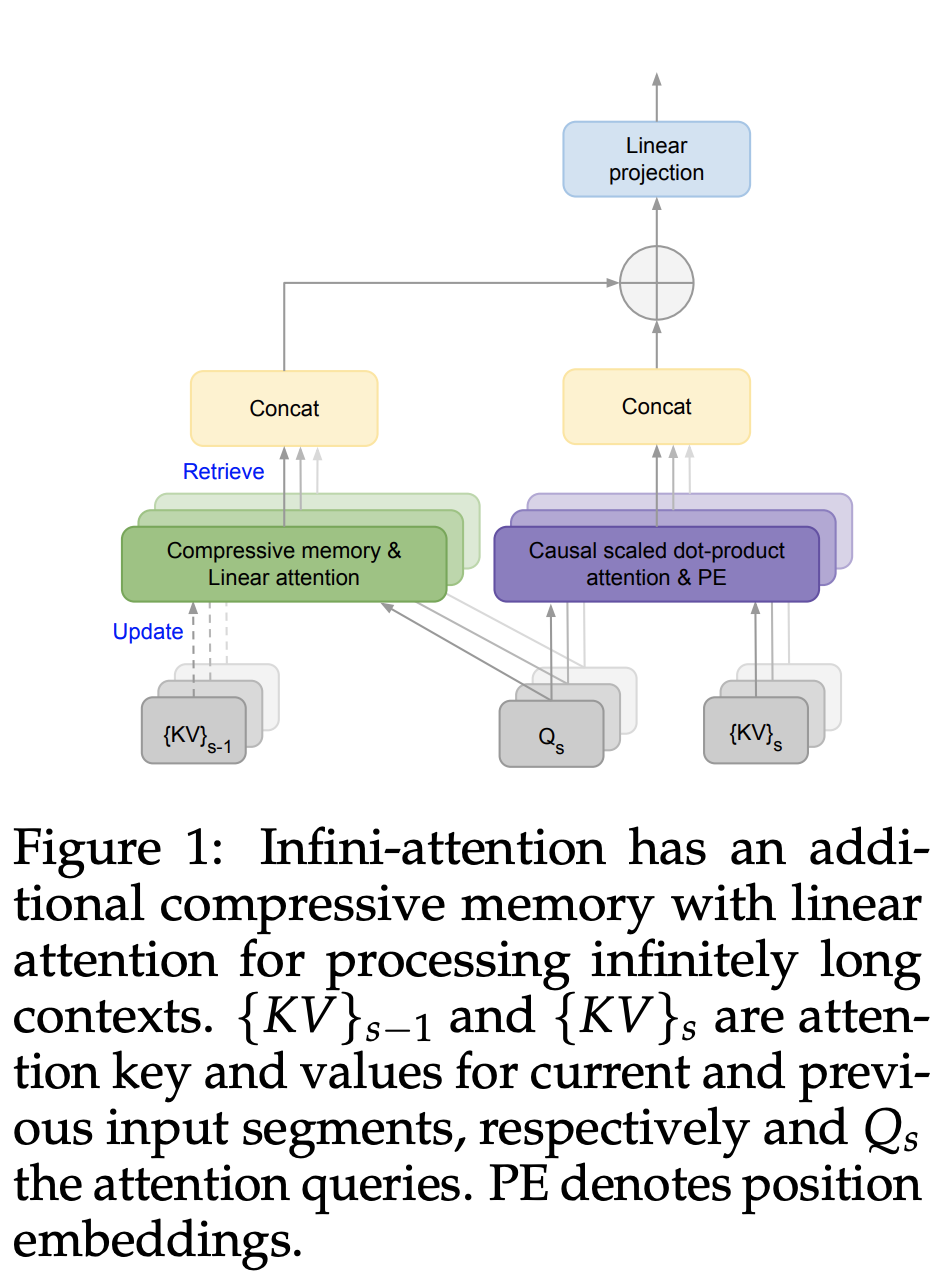
“Infini-attention,” by Google integrates a compressive memory within the standard attention framework, enabling the model to manage extensive sequences without increasing computational demands. This technique not only maintains a bounded memory footprint but also incorporates both masked local attention and long-term linear attention in a single Transformer block, facilitating more dynamic and extensive data processing capabilities
-
Efficient Infinite Context Handling: Utilizes a novel attention mechanism called Infini-attention that incorporates a compressive memory system within the vanilla attention framework, enabling efficient management of unlimited input lengths.
-
Compressive Memory Storage: Unlike standard attention that discards old key-value (KV) states, Infini-attention stores these states, allowing the system to access historical data for future queries.
-
Retrieval and Aggregation: Retrieves long-term memory values using attention queries and combines them with local attention contexts to produce the final output, enhancing both depth and accuracy of context understanding.
-
Speculation on Influence: There is community speculation that this approach might have influenced the development of extended context capabilities in models like Gemini 1.5 Pro, given the timing and the innovative promise of Infini-attention.
- Benefits:
- Contextual Modeling: Efficiently models both long and short-range contexts.
- Integration Ease: Minimal changes to the standard scaled dot-product attention make it easy to integrate with existing LLMs.
- Scalability and Performance: Capable of handling infinitely long contexts with bounded memory and computation. Outperforms baseline models in long-context tasks and achieves new benchmarks in tasks like 500K length book summarization.
- Critical Perspective:
- Theoretical vs. Practical: The term “infinite length” is more theoretical, emphasizing the model’s capability to handle very long contexts rather than truly unbounded sequences.
- Need for Further Research: While promising, the architecture requires further testing across more diverse and extensive tasks to fully validate its capabilities.
- Exciting Progress: Represents a significant leap in context handling capabilities, moving from the 32K context length of earlier models to the 1M length in Gemini and potentially beyond.
Conclusion
- So far we’ve seen quite a few methodologies to help extend the context-length of our LLMs. As more research prevails in this domain, we will keep this article updated with its findings!
Citation
@article{Chadha2020DistilledContextLengthExtension,
title = {LLM Context Length Extension},
author = {Chadha, Aman and Jain, Vinija},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}