Natural Language Processing • Finetuning
- Overview
- LLM Finetuning
- Encoder Finetuning
- Continual pre-training vs Finetuning
- Fine Tuning vs. Retrieval Augmented Generation for Less Popular Knowledge
- References
Overview
- Finetuning involves taking a pre-trained model and further training it on a new, typically smaller and more specific dataset. This process adjusts and optimizes the model’s parameters to make it better suited for a particular task or to adapt it to new data while preserving the knowledge it gained during its initial training. Thus,in this process, the weights of the pre-trained model are slightly adjusted to improve performance on the specific task.
- Let’s look at how finetuning is done as illustrated in the image below (source).
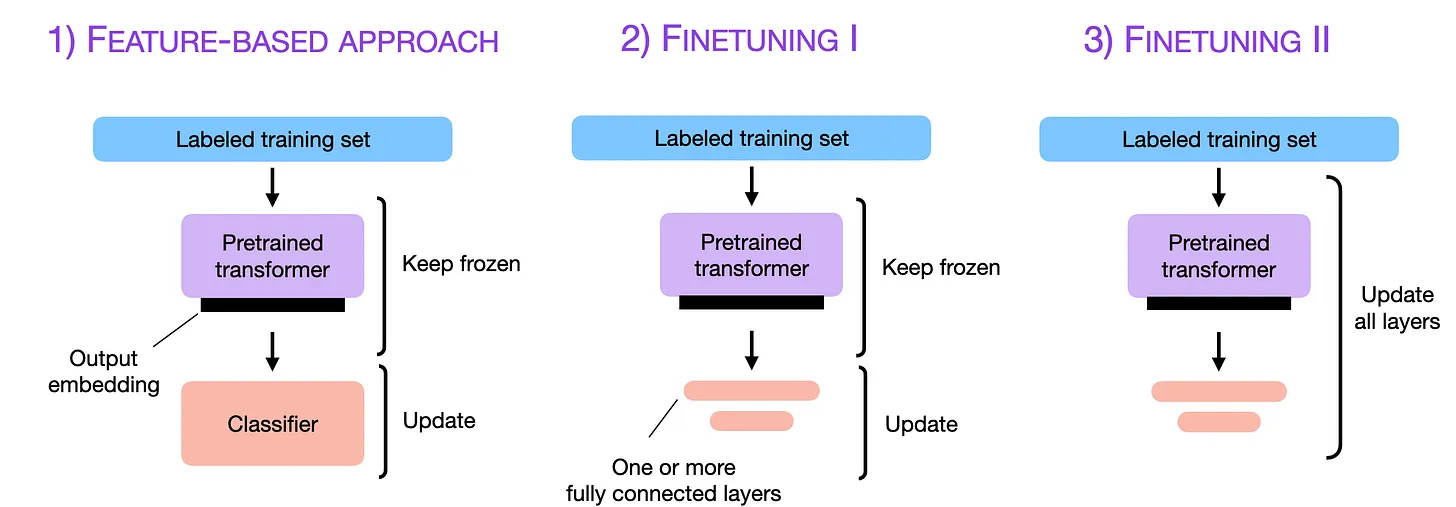
- We will look at different options of how to finetune both encoder and decoder models below.
LLM Finetuning
- Decoders like LLMs are inherently generative and function in an autoregressive manner, predicting each subsequent element in a sequence based on the preceding elements.
- These decoder models can be effectively finetuned to specialize in various tasks. A notable example is the fine-tuning of the GPT model to create ChatGPT, where the model was adapted to excel in conversational contexts and interactive tasks, showcasing the versatility and adaptability of LLMs in learning task-specific nuances.
- Since LLMs can take prompts as input, they don’t necessarily require an additional classification layer (as encoders do) to help guide their formulation of the output.
- There are two methods in which LLMs are generally used for new tasks, in-context learning (teaching new tasks without finetuning) and finetuning. We will talk about both below.
In-Context Learning (Prompting)
- In-context learning can be used as an alternative to finetuning, especially when direct access to the model is not provided. The image below (source), shows in-context learning.
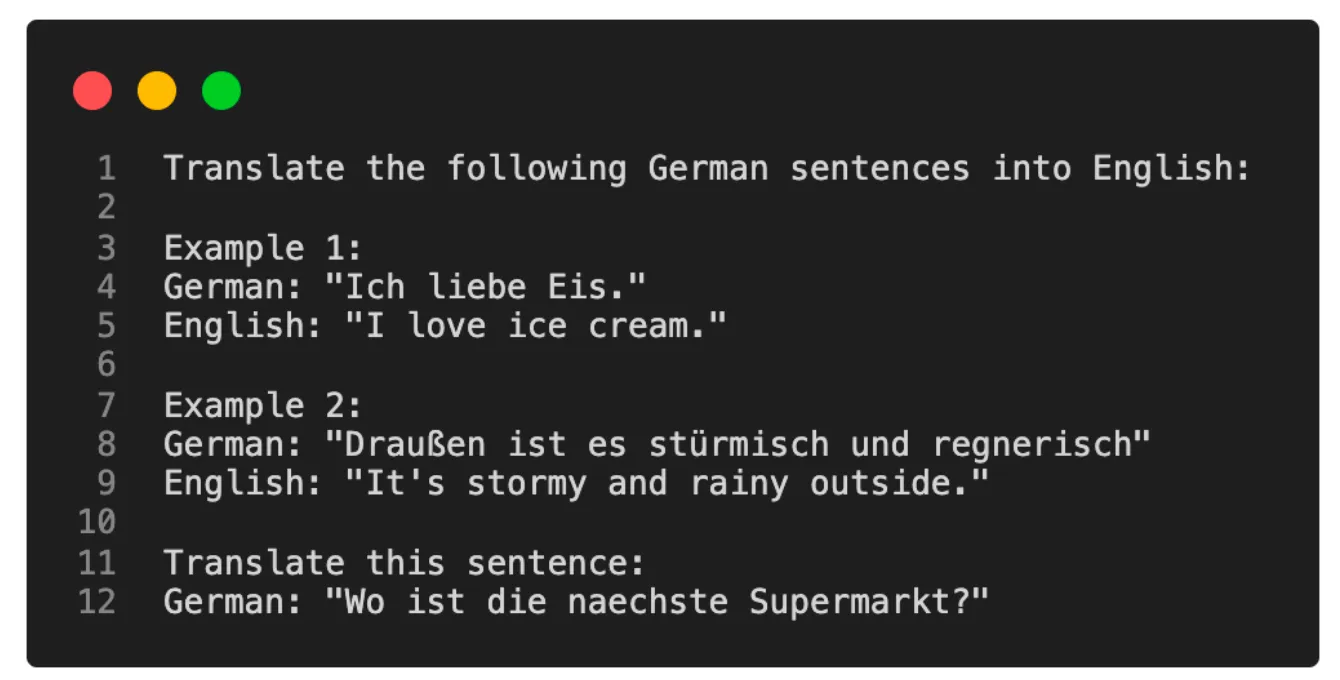
- This approach involves providing a few task-specific examples within the input prompt, enabling the model to generate relevant responses based on this contextual information. For example, feeding the model with sample sentences of a certain type allows it to produce similar sentences, drawing on its extensive training on diverse datasets.
- Hard Prompt Tuning is a strategy related to in-context learning. Here, we modify the inputs with the goal of getting better outputs. This is known as ‘hard’ prompt tuning because it involves directly changing the input words or tokens. Although this method is more resource-efficient compared to parameter finetuning (where the model’s parameters are updated to better perform a task), it often falls short in performance, as it doesn’t adapt the model’s parameters to the specific nuances of a task. This can limit its adaptability. Also, the process of hard prompt tuning can require significant human involvement to compare the quality of different prompts and decide which works best.
- The image below (source), shows hard prompting.
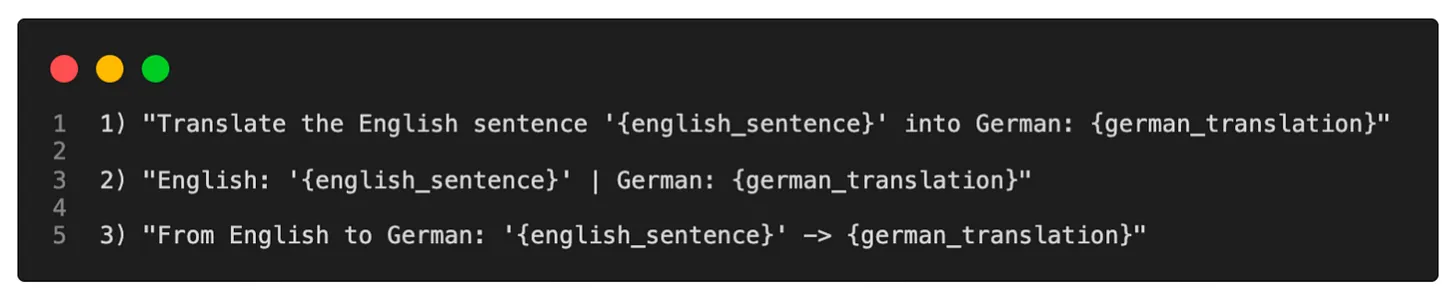
- Soft Prompt Tuning is a differentiable version of prompt tuning, which allows for adjustments and optimization of prompts in a more automated manner. However, this is not covered in detail in your original text.
Parameter Efficient Finetuning
- Parameter-Efficient Finetuning (PEFT) is a method for adapting LLMs to specific tasks in a parameter efficient way. This technique allows for reusing pretrained models while minimizing the computational and resource footprints. Some of the key advantages of PEFT include:
- Reduced computational costs: PEFT methods require fewer GPUs and less GPU time.
- Faster training times: PEFT methods complete training more quickly than methods that involve training all layers.
- Lower hardware requirements: PEFT methods work with smaller GPUs and require less memory.
- Better modeling performance: By limiting the number of parameters that need to be adjusted, PEFT methods can reduce the risk of overfitting.
- Less storage: Majority of the model weights can be shared across different tasks.
- Let’s give a brief overview of a few PEFT techniques:
- Prefix Tuning: It involves training a small network that processes the input before it’s fed into the pretrained model. This allows the input to be dynamically adapted for each task.
- Adapters: In this method, small feed-forward neural networks (adapters) are added to each layer of the pretrained model. These adapters are trained while the main parameters of the model are frozen.
- Low-rank Adaptation: This technique involves adding a low-rank matrix to the weight matrix of each layer. This matrix is finetuned while the main parameters of the model are kept frozen.
- PEFT can be an order of magnitude cheaper than performing full-finetuning. More information can be found here: peft article
- Let’s give a brief overview of a few PEFT techniques:
Supervised Finetuning (SFT)
- Given access to a model, full fine-tuning, which involves adjusting all the model’s weights for a new task, is a viable approach.
- However, this method can be resource-intensive and may pose risks such as overfitting, especially with smaller datasets, or catastrophic forgetting, where the model loses its ability to perform the tasks it was originally trained on.
- Supervised finetuning of LLMs involves training the model with instruction-output pairs, where the instruction serves as the input and the output is the model’s desired response.
- For example, given the instruction “Write a limerick about a pelican,” the model predicts the next tokens to generate a relevant limerick.
- This stage uses smaller datasets compared to pretraining, as creating instruction-output pairs requires significant effort, often involving humans or another high-quality LLM.
- The process focuses on refining the model’s ability to produce specific outputs based on given instructions.
Instruction Tuning
- Instruction fine-tuning (IFT) is a type of SFT leveraged in LLMs to improve their ability to follow instructions and generate more accurate and relevant responses. This technique involves training the model on a dataset of prompts followed by ideal responses, guiding the model to better understand and execute various types of instructions.
- (FLAN) was the first to introduce instruction tuning which finetunes the model on a large set of varied instructions that use a simple and intuitive description of the task, such as “Classify this movie review as positive or negative,” or “Translate this sentence to Danish.”
- “Creating a dataset of instructions from scratch to fine-tune the model would take a considerable amount of resources. Therefore, we instead make use of templates to transform existing datasets into an instructional format.” (source)
- The image below shows a representation of how the instruction dataset is generated via templates from the original FLAN paper:

- The image below (source) represents the difference between supervised finetuning and instruction tuning.
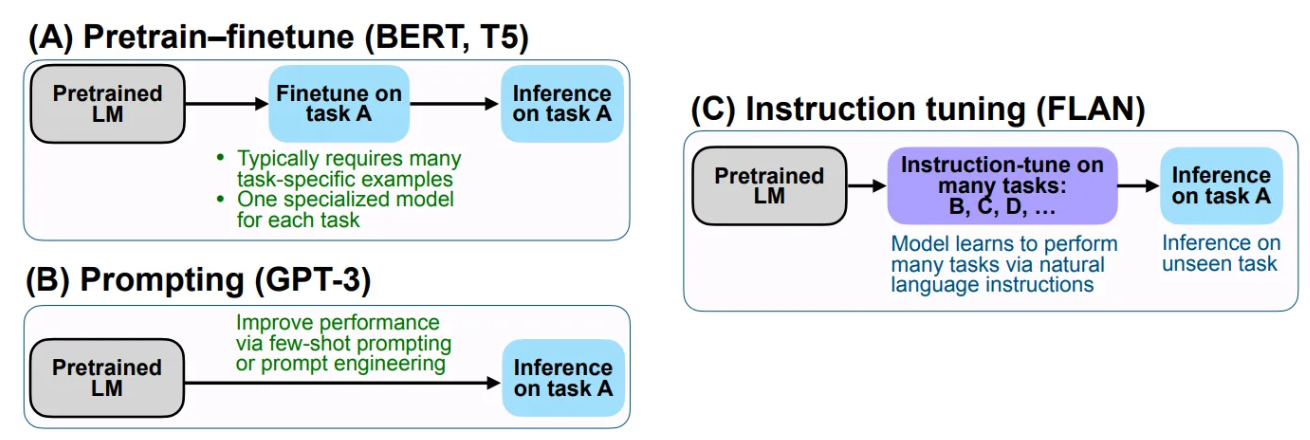
Alignment
- Lastly, we would be remiss if we didn’t mention alignment after supervised finetuning of LLMs.
- Alignment aims to align the model with human preferences, often employing techniques like Reinforcement Learning from Human Feedback (RLHF) or Reinforcement Learning from AI Feedback (RLAIF).
- More information on this can be found in our RLHF article
REFT: Reasoning with REinforced Fine-Tuning
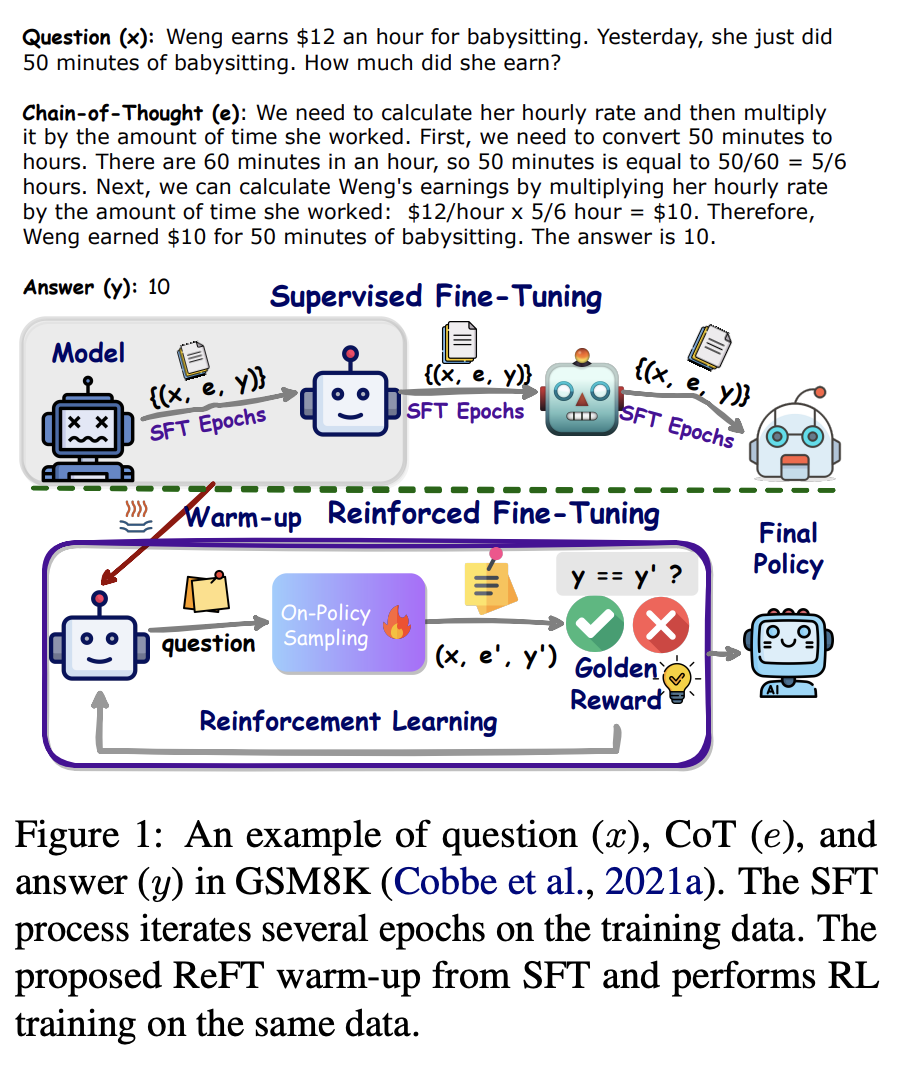
- REFT by ByteDance presents several key technical contributions to the field of fine-tuning language models for reasoning tasks.
- ReFT combines Supervised Fine-Tuning (SFT) with reinforcement learning (RL) to improve the generalization capabilities of language models. This method is particularly applied to solve math problems by learning from multiple correct reasoning paths or Chain-of-Thought (CoT) annotations.
- ReFT starts with a warm-up phase using SFT to establish a basic ability to solve problems. It then progresses to RL where the model refines its reasoning by exploring various valid CoTs, learning from this richer context without requiring extra training data.
- The reinforcement learning component uses PPO, an on-policy learning algorithm, which enables the model to sample different reasoning paths, thus enhancing the model’s ability to generalize from the training data.
- ReFT is tested with both natural language and program-based CoT representations, offering flexibility and robustness in handling different types of reasoning tasks.
- The effectiveness of ReFT is validated through extensive experiments on mathematical datasets like GSM8K, MathQA, and SVAMP, demonstrating its superior performance over traditional SFT.
- Techniques like majority voting and re-ranking are applied during inference, leveraging ensemble methods and reward model re-ranking to further boost the model’s performance.
- While the current focus is on math problem-solving, the authors note that ReFT’s approach could be adapted to other reasoning tasks, suggesting a broad applicability of the technique.
- These features mark significant advancements in the way language models are fine-tuned for specialized tasks, particularly in improving their problem-solving capabilities and generalization across similar tasks.
- ReFT, or Reinforced Fine-Tuning, is a technique that enhances the generalization capabilities of language models, particularly for complex reasoning tasks like math problem-solving. It combines Supervised Fine-Tuning (SFT) with reinforcement learning, using Proximal Policy Optimization (PPO) to enable the model to explore and learn from multiple correct reasoning paths. This approach not only improves the model’s problem-solving accuracy but also its ability to adapt to similar tasks beyond the training data.
ReFT should be used when:
- There is a need to improve a model’s reasoning capabilities and generalization on complex cognitive tasks.
- Existing models struggle with robustness and flexibility in generating solutions across varying contexts within specialized domains such as mathematics.
-
There is a benefit in training models to develop a deep understanding of a task by exploring various possible solutions and learning from their outcomes.
- This method is particularly useful in academic and research settings where enhancing the depth and breadth of understanding and reasoning is crucial.
Encoder Finetuning
- Let’s briefly talk about what the encoder does before we delve into how to finetune it.
- The encoder processes input sequences (like text) by computing attention scores that determine how each word in the sequence relates to every other word. This mechanism allows the model to capture complex word relationships and contextual information, making it highly effective for tasks like language understanding and translation. The transformer encoder’s output can then be used as input for a transformer decoder in sequence-to-sequence tasks, or directly in tasks like text classification.
- BERT (Bidirectional Encoder Representations from Transformers), an encoder only model, is specifically pre-trained on two tasks: Masked Language Model (MLM) and Next Sentence Prediction (NSP).
- Masked Language Model (MLM):
- In MLM, a certain percentage of the input tokens are masked randomly, and the model is trained to predict these masked tokens. This task helps BERT understand the context of words in a sentence, enabling it to capture bidirectional context effectively.
- Next Sentence Prediction (NSP):
- In NSP, the model is given pairs of sentences and learns to predict if the second sentence is the subsequent sentence in the original document. This task helps BERT understand the relationships between consecutive sentences, which is crucial for tasks that require understanding of sentence relationships like question answering and natural language inference.
- BERT’s pre-training on MLM and NSP tasks with just the encoder component of the Transformer model is what makes it particularly effective for a wide range of downstream NLP tasks that require understanding of sentence and document context.
Finetuning BERT
- Fine-tuning BERT usually involves adding a task-specific layer on top of the BERT encoder, and training the whole model end-to-end with a suitable loss function and optimizer.
- For many tasks, you’ll need to add a task-specific layer on top of BERT. For instance, for classification tasks, add a classification layer on top of BERT’s output for the [CLS] token.
- Adding a task-specific layer to a pre-trained model like BERT is necessary for adapting the model to perform a particular task effectively. Here’s why this layer is important:
- Different tasks require different types of outputs. For instance, a classification task needs a probability distribution over classes, while a token tagging task (like named entity recognition) requires a label for each token. A task-specific layer is designed to produce outputs in the required format for the task at hand.
- BERT and similar models are pre-trained to understand language generally, capturing features like context, semantics, and syntax. However, they’re not trained to output information in a format specific to a particular task. The task-specific layer transforms the rich, general features learned during pre-training into a format that directly addresses the specific requirements of the task.
- Unlike LLMs, encoder only models like BERT do not have a mechanism to take in prompts so we can not instruct them to process the output in a certain way, therefore, they rely on the additional output layer to help them understand the correct output required for the given task.
-
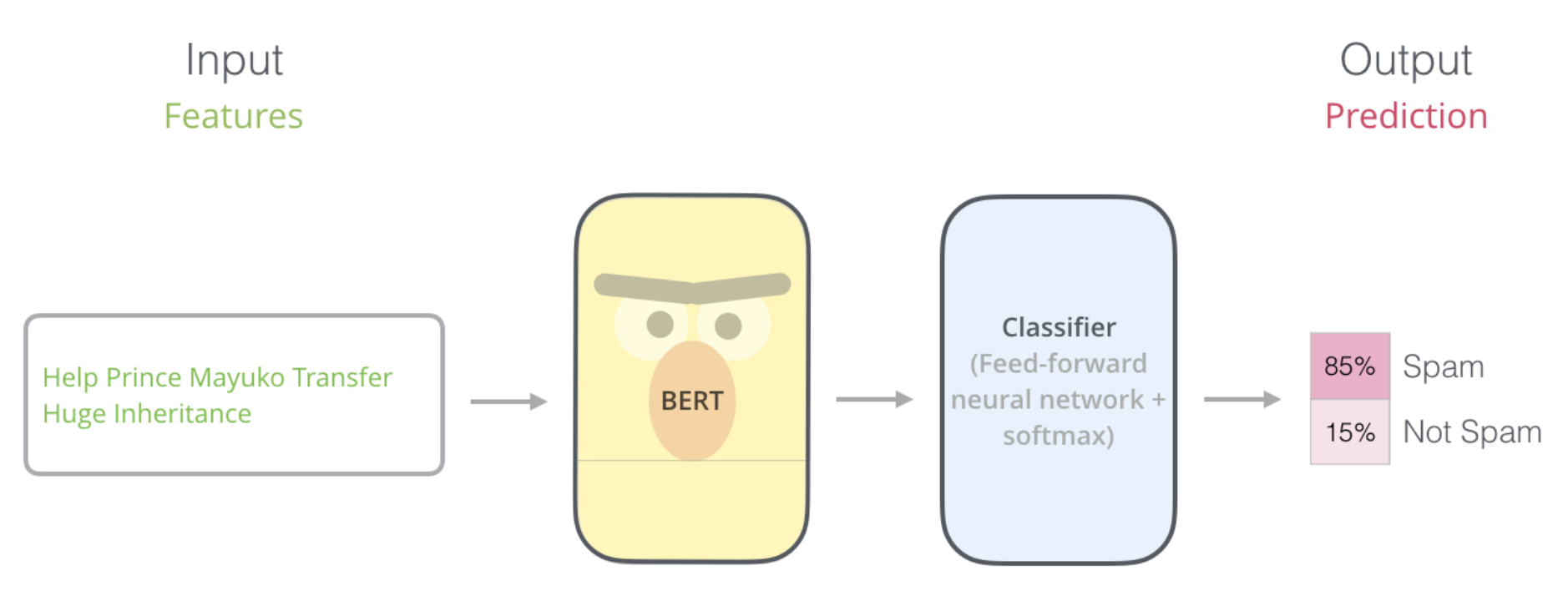
As you can see in illustrated in the image below (source), for spam classification, BERT just needs a classification layer (made of feed forward layers and softmax) to output the correct class probabilities.
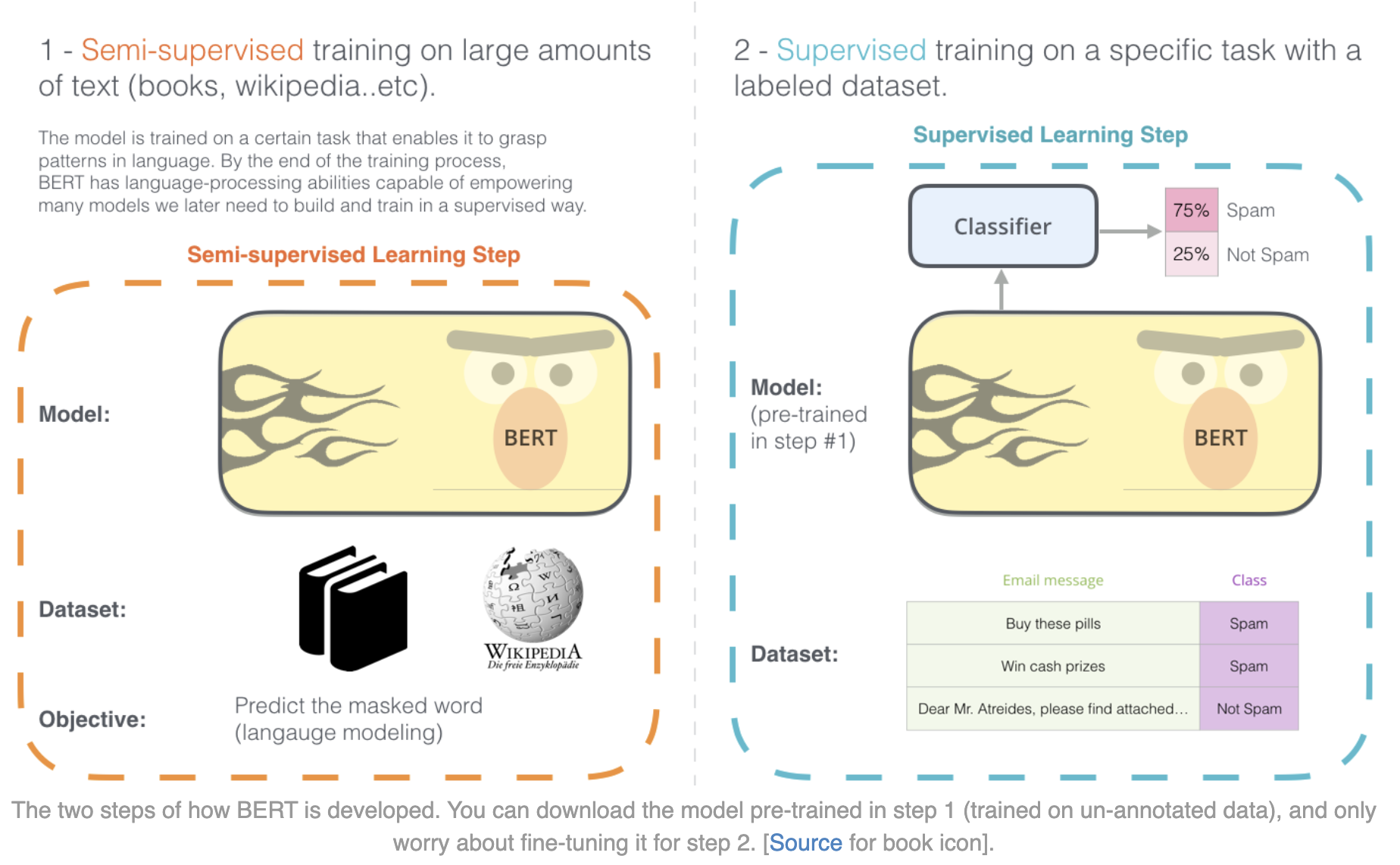
- The illustration below (source) shows how BERT was pretrained in step 1 and how it is finetuned in step 2.
Continual pre-training vs Finetuning
- Further pre-training, also known as continued pre-training or domain-specific pre-training, involves taking an already pre-trained model and training it further on new, often more specialized data.
- This approach leverages transfer learning. Instead of starting from scratch, it uses the weights and knowledge from the previously trained model.
- The model is then trained (or finetuned) on a new dataset that is usually more specific or domain-focused, allowing it to adapt its previously learned knowledge to this new context.
- This is beneficial when the new domain’s data is not as extensive as the original training set. For instance, a model initially trained on general English text might be further pre-trained on legal documents to specialize in legal language.
Fine Tuning vs. Retrieval Augmented Generation for Less Popular Knowledge
- This paper by Soudani et al. from Radboud University and the University of Amsterdam investigates the efficacy of Retrieval Augmented Generation (RAG) and fine-tuning (FT) on enhancing the performance of large language models (LLMs) for question answering (QA) tasks involving low-frequency factual knowledge.
- Key Findings:
- Effectiveness of Fine-Tuning and RAG:
- Fine-Tuning (FT): The paper highlights that fine-tuning, particularly when using synthetic data, significantly enhances the model’s performance across entities of varying popularity. The improvement is especially notable in the most and least popular categories. This suggests that fine-tuning helps the model better adapt to both common and rare entities by directly altering the model weights to better recall and process the information related to these entities.
- Retrieval-Augmented Generation (RAG): RAG consistently outperforms fine-tuning alone. This approach involves dynamically retrieving relevant external information during the model’s inference phase, thus supplementing the model’s knowledge base. RAG is particularly useful for less frequent entities where the model’s internal knowledge (from pre-training) is limited.
- Combinatorial Effects of FT and RAG:
- The study finds that combining both RAG and fine-tuning yields the best overall performance. The synergy between RAG’s dynamic retrieval capability and FT’s enhanced recall ability allows the model to effectively handle a wider range of query complexities and entity frequencies.
- Impact Across Entity Popularity:
- Most Popular Entities: For entities that are frequently encountered, both RAG and FT significantly improve accuracy. This improvement is likely due to both approaches enhancing the model’s ability to leverage its pre-existing knowledge more effectively.
- Least Popular Entities: For rare entities, the improvements are crucial as these entities are underrepresented in the training data. FT helps by tailoring the model to remember these rare instances better, while RAG provides a direct method to pull in external context, thus compensating for the inherent data deficiencies.
- Dependency on Model and Data Enhancements:
- The effectiveness of both FT and RAG is further amplified by advances in retrieval mechanisms and the quality of synthetic data used for training. Improved retrieval technologies enhance RAG’s ability to fetch relevant and high-quality external content, while better-quality synthetic data makes FT more effective by providing richer and more accurate training examples.
- Model Size Variability:
- The paper also notes that the benefits of FT and RAG vary by model size. Smaller models benefit more from the combination of FT and RAG, possibly due to their limited capacity to encapsulate knowledge. In contrast, larger models, which inherently possess more extensive pre-trained knowledge, show diminishing returns from these enhancements, particularly in the context of RAG.
Conclusion and Implications:
The paper concludes that both fine-tuning and Retrieval-Augmented Generation significantly enhance the performance of language models on question answering tasks, especially in handling less popular knowledge entities. These findings underscore the importance of targeted model enhancements for improving AI performance in specialized and niche domains, where accuracy and depth of knowledge are critical. The study advocates for continued advancement in data augmentation and retrieval technologies to further leverage these techniques.
These detailed findings highlight the strategic importance of model customization in improving the breadth and depth of AI systems, ensuring they are robust across a spectrum of real-world applications, from general knowledge to specialized domains.