NLP • Hallucination Mitigation
Overview
- Hallucination in AI text generation is a phenomenon where an AI model produces text that, while often grammatically correct and plausible, is not rooted in the given input or may even be factually inaccurate. This issue is particularly prevalent in systems like GPT-3, where generated details might stray from or even contradict the input.
- Understanding why hallucination happens can be traced to various causes:
- Insufficient Training Data: A model that hasn’t encountered diverse data during training might not establish accurate correlations between inputs and appropriate outputs, leading to hallucinated content.
- Model Overfitting: Overfitting to training data can cause a model to produce outputs that mirror the training set but misalign with new or different inputs.
- Inadequate Supervision: Without proper guidance, a model might rely too heavily on its internal logic, leading to outputs that appear to “hallucinate.”
- Knowledge Cutoff: LLMs like ChatGPT have a knowledge cutoff date and thus, are unaware of any information past that date. Thus, unknowingly, they may respond to your question with out-of-date information that may no longer be relevant.
- The presence of hallucination in AI-generated content emphasizes the need for continuous refinement to enhance the reliability of AI systems in practical scenarios. Nevertheless, it also opens doors for pioneering research in artificial intelligence and natural language processing domains.
- This article delves into various strategies to counteract and mitigate the effects of hallucination at various stages of the model’s pipeline.
Training
- Let’s start by looking at how we can mitigate hallucination from the inital phase of training itself.
Reinforcement Learning from Human Feedback (RLHF)
- In the same vein as Human-in-the-loop, RLHF can help mitigate hallucination with human feedback. By collecting data where humans rank different model-generated responses based on their quality, the model can learn to adjust its outputs to better align with human expectations.
- The idea behind using RLHF to reduce hallucinations is that humans can provide feedback on the accuracy and relevance of the model’s responses. By incorporating this feedback into the training process, the model can learn to distinguish between accurate and inaccurate information, reducing the likelihood of hallucinations. Additionally, RLHF can help the model understand the consequences of its actions, improving its ability to generate relevant and factual responses.
Prompting
- Prompting offers a preliminary insight into LLMs, after they have been trained, and the start of how we can mitigate hallucination. Let’s look at a few methods below:
Retrieval Augmented Generation
- Retrieval augmented generation (RAG) helps eliminate hallucination in large language models (LLMs) by providing them with additional context-specific information during the generation process. Hallucination occurs when an LLM generates responses based on patterns it has learned from its training data rather than relying on actual knowledge. This happens when the model lacks domain-specific information or struggles to recognize the boundaries of its own knowledge.
- RAG addresses this issue by integrating external knowledge sources into the generation process. It enables the LLM to access up-to-date or context-specific data from an external database, which is retrieved and made available to the model when generating a response. By doing so, RAG injects more context into the prompt, helping the LLM understand the topic better and reduce the likelihood of hallucinations.
- For instance, in the case of a chatbot designed to provide information about cars, RAG could retrieve product-specific details and contextual information from an external database to supplement the user’s input. As a result, the LLM receives a more comprehensive and detailed prompt, allowing it to generate more accurate and relevant responses.
- Moreover, RAG can be combined with advanced prompt engineering techniques, such as vector databases, to further enhance the performance of LLMs. By leveraging these methodologies, companies can effectively employ LLMs with their internal or third-party data, ensuring that the generated responses are not only coherent but also factually correct.
- Overall, RAG is a valuable approach for mitigating hallucinations in LLMs, enabling them to produce more reliable and informative answers by complementing their capabilities with external knowledge sources.
Contextual Prompting
- Trapping LLM “Hallucinations” Using Tagged Context Prompts by the University of Maryland (Go Terps!) uses a technique of tagging sources in the context prompts fed to the large language models (LLMs) to reduce hallucinations.
- Let me explain this in more detail:
- The contexts provided to the LLM along with the question are summaries of Wikipedia articles, book sections etc.
- These context passages are tagged by inserting unique identifiers like “(source 1234)” or “(source 4567)” at the end of sentences.
- For example:
- “Paris is the capital of France. (source 1234)”
- “France is located in Western Europe. (source 4567)”
- These source tags are unique numbers that correspond to specific sentences in the original contextual passage.
- When prompting the LLM with a question and tagged context, the paper’s method also appends the instruction “Provide details and include sources in the answer.”
- As a result, the LLM is guided to reference these tagged sources when generating its response.
- The tags provide a way to verify if the LLM’s response is grounded in the given contextual sources.
- If the response contains matching source tags, it indicates the LLM relied on the provided context rather than hallucinating.
- The authors found this tagging technique reduced hallucinated responses by ~99% compared to no context.
Chain of Verification
- This paper by Meta AI looks to reduce hallucination by proposing CoVe (Chain of Verification). CoVe generates a few verification questions to ask, and then executes these questions to check for agreement. The image below from the original paper helps display this concept.

-
CoVe has the LLM go through multiple steps after generating an initial response: 1) Generate baseline response to the query. This may contain inaccuracies or hallucinations. 2) Plan verifications - LLM generates a set of verification questions to fact-check its own work. 3) Execute verifications - LLM answers the verification questions independently. 4) Generate final response - Revise initial response based on verification results.
- Verification questions are often answered more accurately than facts stated in long passages.
- Different CoVe variants control attention during verification to avoid repeating false info:
- Joint CoVe:
- Single prompt for planning + answering questions.
- Single prompt containing query, baseline response, verification questions and answers.
- Attention can attend to all context including potentially incorrect baseline response.
- Prone to repeating same hallucinations when answering questions.
- Two-Step CoVe:
- Separate prompt for planning questions based on baseline response.
- Separate prompt for answering questions without baseline response context.
- Avoids directly attending to potentially incorrect baseline.
- But attention can still attend across all question answers.
- Factored CoVe:
- Each question answered fully independently.
- Fully independent prompt for each verification question.
- No attention to any other context including baseline response.
- Avoids interference between questions.
- Most robust to repetition of false info.
- Factor+Revise:
- Explicitly cross-check Q&A vs original facts.
- Additional prompt to explicitly cross-check Q&A vs original facts.
- Attention to both original facts and Q&A.
- Flags inconsistencies for final response.
- Note that these methods are not used in parallel. They are different variants of the same framework tested independently. The Factor+Revise builds on top of the Factored version.
- The key finding is that more independently reasoning via factored attention avoids conditioning on and repeating potential hallucinations in the original response. This leads to higher gains in mitigating false information.
- So in summary, CoVe has the model verify its own generations by planning and answering focused questions, avoiding conditioning on its own potentially incorrect responses. This provably reduces hallucinations across several tasks.
Model
- Now let’s move further down the pipeline into the model and look at different research on how to mitigate hallucination at this layer.
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
- Microsoft’s research introduces a novel method called Decoding by Contrasting Layers (DoLa), aiming to mitigate hallucinations in large language models (LLMs) without necessitating additional training or retrieval. This technique rests upon the understanding that factual knowledge in LLMs is predominantly encoded within the latter or more mature layers of a transformer architecture.
- During the process of text generation, DoLa does not rely on a static selection of a premature layer (an earlier layer in the transformer architecture) for contrasting. Instead, it actively selects the premature layer suited for each token’s decoding. The way DoLa determines this layer is by calculating the Jensen-Shannon divergence (JSD) between the output distribution of the premature layer and that of the mature layer, which is the final layer in the architecture. JSD serves as a measure of dissimilarity between two probability distributions. The underlying logic is to select a premature layer that exhibits the maximum JSD when juxtaposed with the mature layer, effectively maximizing the contrast between the factual knowledge and linguistic tendencies encapsulated in these layers.
- Here’s a closer examination of its functionality:
- For every token being decoded, DoLa dynamically picks a premature layer by identifying which layer’s output distribution is the most distinct (in terms of JSD) from the mature layer’s distribution.
- A higher JSD indicates more pronounced differences between the factual and linguistic content encoded in the two layers.
- The premature layer embodies more fundamental linguistic patterns, while the mature layer is more representative of factual knowledge.
- DoLa then calculates the next token’s probability distribution by contrasting the logit outputs of the mature layer and the chosen premature layer. Specifically, this involves subtracting the log probabilities of the premature layer from those of the mature layer.
- As a result, the generated probability distribution accentuates factual information while diminishing mere linguistic patterns.
- This method is versatile. For tokens that are relatively simple and where the distributions between layers are alike (manifested by a lower JSD), early layers might be selected as the premature layer. Conversely, for tokens necessitating intricate real-world knowledge, a higher premature layer might be selected to enhance the contrast with the mature layer.
- In empirical terms, when DoLa was tested across various tasks like multiple choice QA, open-ended QA, and text generation, the method showcased noticeable improvements in factuality and truthfulness, surpassing traditional decoding and other contrastive decoding techniques. Additionally, DoLa introduces only a minimal computational overhead during the inference phase, making it a lightweight yet effective approach.
-
In essence, DoLa offers a dynamic method of contrasting knowledge encoded in transformer layers to minimize hallucinations, and its ability to adaptively choose the appropriate premature layer for each token is central to its efficacy.
- The method employed by DoLa, as described, involves contrasting the outputs between a “premature” layer and a “mature” layer. The mature layer, typically the final layer in the model, is believed to encode more of the factual knowledge, while the premature layers, being earlier in the network, contain more basic linguistic patterns.
- The reason for dynamically picking a premature layer (as opposed to the mature layer) lies in the very objective of the method:
- Contrast Mechanism: By contrasting the outputs of two layers (premature and mature), DoLa aims to amplify the factual information encoded in the mature layer while de-emphasizing the basic linguistic patterns in the premature layer.
- Dynamic Adaptability: While the mature layer remains consistent (as it’s always the final layer), choosing a premature layer dynamically provides adaptability. For different tokens or contexts, the distinction between the mature layer and a particular premature layer might be more pronounced, leading to a higher Jensen-Shannon divergence. By selecting different premature layers for different tokens, DoLa can better maximize this distinction.
- Highlighting Factual Information: The mature layer’s outputs are already expected to be more factual. The value in choosing the premature layer is in contrasting it with the mature layer. This emphasizes the factual content in the mature layer’s outputs even further.
- Flexibility: The range of possible outputs from premature layers provides a spectrum of linguistic patterns. By having the flexibility to select from this spectrum, DoLa can adaptively contrast different types of linguistic patterns against the factual knowledge in the mature layer, depending on the context.
- In essence, the mature layer acts as a consistent reference point, while the choice of premature layer allows the model to adaptively emphasize factual content over linguistic patterns, thereby aiming to reduce hallucinations and improve the factual accuracy of the generated content.
After generation of prompt
- Let’s see how validation of the prompt with human can help in reducing hallucination.
Mitigating Language Model Hallucination with Interactive Question-Knowledge Alignment
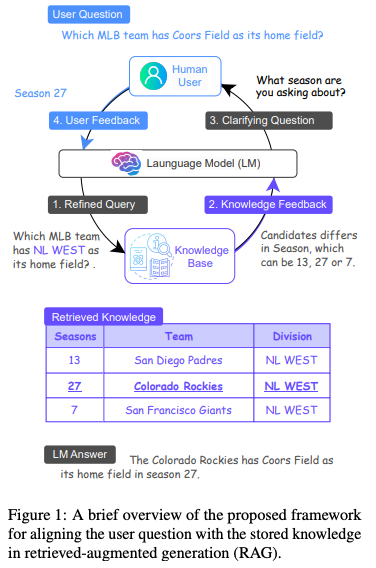
- MixAlign is an innovative framework designed to facilitate a seamless interaction between users and a knowledge base. Its core strength lies in ensuring that user queries precisely resonate with the information stored in the knowledge base. Integral to MixAlign’s design is the strategic inclusion of human-in-the-loop interventions, which are meticulously integrated to mitigate hallucinations.
- Upon receiving a user query, MixAlign employs the language model to refine this inquiry, ensuring it closely mirrors the attributes delineated in the knowledge base schema. Using this polished query, the system extracts pertinent evidence passages. However, when faced with multiple, potentially ambiguous, candidate responses, MixAlign activates its human-centric mechanism.
- In this phase, MixAlign identifies the most salient attribute that sets the candidates apart. Harnessing this attribute, the language model formulates a targeted clarifying question. For instance, if “season” emerges as the differentiating attribute, it might pose a question like, “Which season are you referring to?” The user’s subsequent feedback sharpens the query, dispelling ambiguities surrounding the candidates.
- This collaborative interaction, where human insights are pivotal, is then integrated back into the system. Empowered by this refined alignment, the language model crafts a nuanced final response.
- In essence, MixAlign intertwines automated processes with timely human interventions. By doing so, it addresses the latent ambiguities at their inception, surmounting a major hurdle observed in conventional retrieval-augmented generation systems and the image below from the original paper displays that.
Human-in-the-loop
- In general, employing human reviewers to validate the LLMs output can help mitigate the impact of hallucination and improve the overall quality and reliability of the generated text.