Natural Language Processing • Knowledge Graphs
Overview
- Enriching Language Models with Knowledge: Language models, although powerful, can sometimes fail to predict accurately due to several reasons such as encountering unseen facts, the inability to generate new facts, the rarity of certain facts, or model sensitivity to prompt phrasing. Integrating knowledge into language models is a promising way to enhance their performance.
- Standard Language Models: These models work on the principle of predicting the subsequent word in a sequence of text. They are capable of calculating the likelihood of a particular sequence, making them useful in various natural language processing tasks.
- Masked Language Models (BERT): An advancement on standard models, BERT employs bidirectional context for predicting a masked token within a text sequence, resulting in a more nuanced understanding of language context and semantics.
- Limitations of Language Models:
- Unseen Facts: Language models might struggle with facts that haven’t appeared in their training data, limiting their ability to provide accurate predictions.
- Inability to Generate New Facts: Language models are limited by their training data and can’t create or infer new facts about the world independently.
- Rare Facts: If a fact is rarely present in the training data, the model may fail to memorize and subsequently recall it.
- Model Sensitivity: The prediction accuracy of language models can depend heavily on the wording of the prompt. They might miss the correct prediction if the phrasing isn’t similar to what they’ve seen during training.
- Key Challenge: The inability to consistently recall knowledge accurately is a significant obstacle in the current development of language models. Efforts are being made to address this and enhance their reliability.
Knowledge Graphs
- The below image (source), shows a depiction of a traditional knowledge graph.
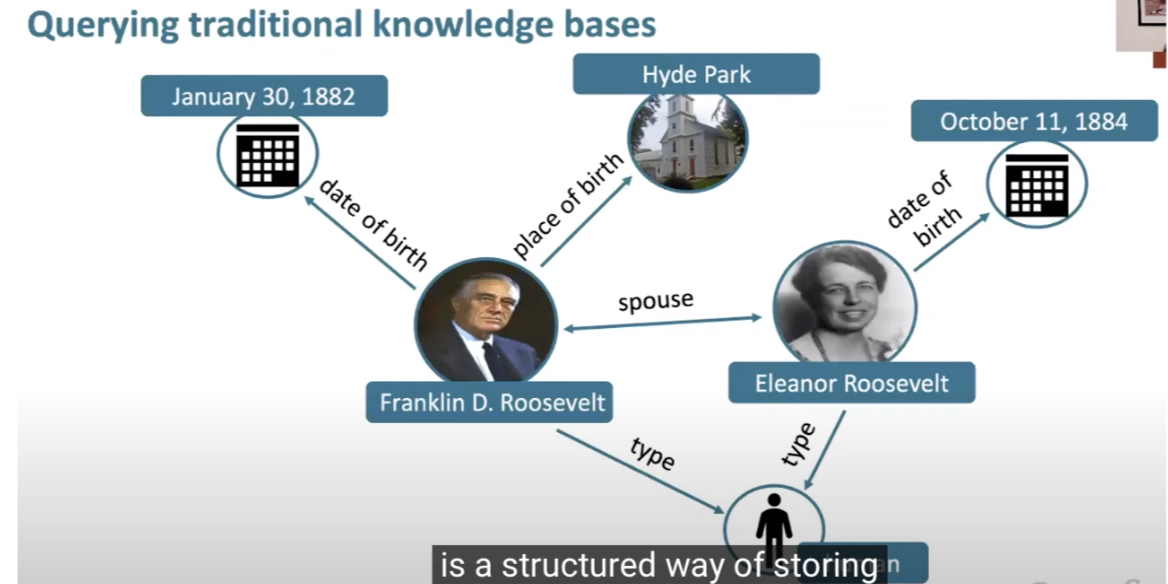
- Natural Language Processing and SQL: The field of knowledge extraction is shifting towards natural language question answering, providing an intuitive alternative to SQL for retrieving information.
- Benefits of Language Models over Traditional Knowledge Bases: Language models, compared to SQL databases, bring several advantages:
- Pre-training on Vast Text Corpora: Language models undergo training on extensive amounts of unstructured and unlabeled text, enabling them to extract and learn a wide range of information.
- Flexibility with Natural Language Queries: Language models can accommodate more natural and varied language queries, enhancing the user’s interaction with the system.
- Drawbacks of Language Models: Despite their benefits, language models also present certain challenges:
- Interpretation Difficulties: Since knowledge is encoded into the model’s parameters, understanding why a particular answer was generated can be complex.
- Trust Issues: Language models can sometimes produce responses that seem plausible but are actually incorrect, raising concerns about their reliability.
- Modification Challenges: Updating or removing knowledge from the language model is not a straightforward process, making their management tricky.
- Techniques for Knowledge Integration: Researchers are exploring several methods to incorporate knowledge into language models, such as pretraining entity embeddings. This process involves representing facts about words in terms of entities, further enhancing the model’s understanding of the context.
- The below slide (source) describes entity embeddings.

Entity Linking
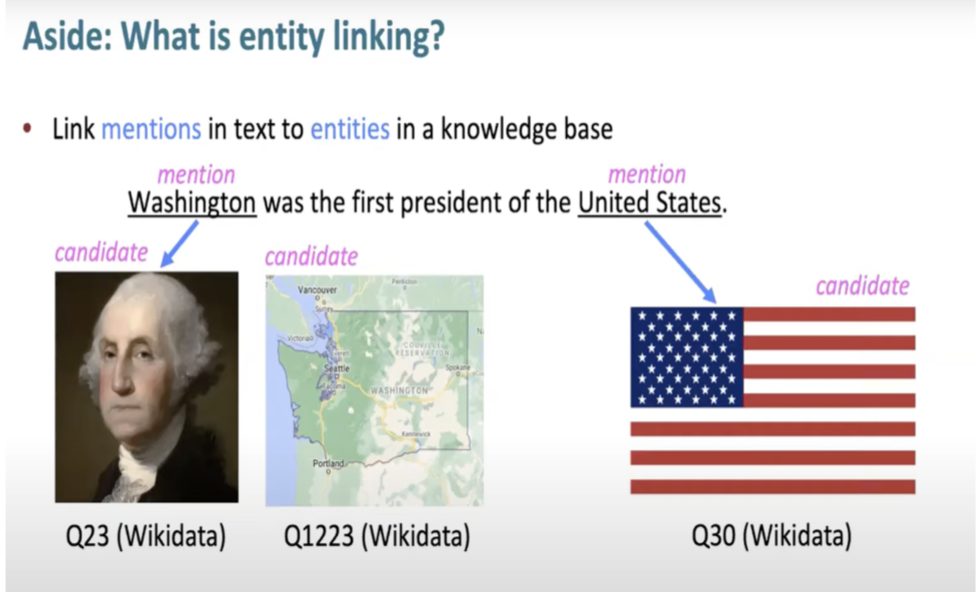
- Connecting Text with Knowledge Bases: Entity linking is the process of associating mentions in a text with their corresponding entities in a knowledge base. This technique helps identify which entity embeddings are relevant to the given text.
-
The below slide (source) describes entity linking.
- Entity Embeddings: Similar to word embeddings, entity embeddings represent entities in a knowledge base in a numerical form. This method provides the models with a deeper understanding of the entities in the context of the text.
- Knowledge Graph Embedding Methods: Various methods exist for creating these embeddings, such as TransE, which is a popular technique for knowledge graph embeddings.
- Wikipedia2Vec: This tool is another example that generates embeddings of words and entities from Wikipedia, enabling efficient handling of both types of semantic units.
- BLINK - Facebook’s Approach: Facebook has introduced BLINK, a large-scale entity linking model that leverages transformer architecture. One of the challenges it faces is the fusion of context and entity information from different embedding spaces. This is often addressed by learning a fusion layer to effectively combine these different sources of information.
ERNIE: Enhanced Language Representation with Informative Entities
- Pretrained Entity Embeddings: ERNIE leverages pretrained embeddings to represent entities.
- Fusion Layer: This layer effectively combines different sources of information.
- Text Encoder: ERNIE uses a multi-layer bidirectional Transformer encoder (BERT) to process the words within a sentence.
- Knowledge Encoder: Consists of stacked blocks, including:
- Two multi-headed attentions (MHAs) over both entity and token embeddings.
- A fusion layer that combines the outputs of the MHAs, creating new word and entity embeddings.
- Pretraining Tasks: ERNIE is pretrained with three tasks:
- Masked language modeling and next sentence prediction (common BERT tasks).
- A knowledge pretraining task, where token-entity alignments are masked randomly, and the model predicts corresponding entities.
- Purpose of Fusion Layer: The fusion layer correlates word and entity embeddings, enabling the model to provide accurate answers.
KnowBert
- Integrating Entity Linking: The key idea is to pretrain an integrated entity linker as an extension to BERT.
- Encoding Knowledge: Learning entity linking may lead to better knowledge encoding.
- Fusion Layer: Similar to ERNIE, KnowBert utilizes a fusion layer to merge entity and context information, adding knowledge pretraining tasks.
KGLM
- Knowledge Graph Integration: LSTMs in KGLM condition the language model on a knowledge graph, predicting the next word using entity information.
- Local Knowledge Graph (KG): KGLM builds a local KG, a subset of the full KG, containing only entities relevant to the sequence.
- Decision Making: The model determines when to use the knowledge graph versus predicting the next word.
-
- The below slide (source) describes KGLM.
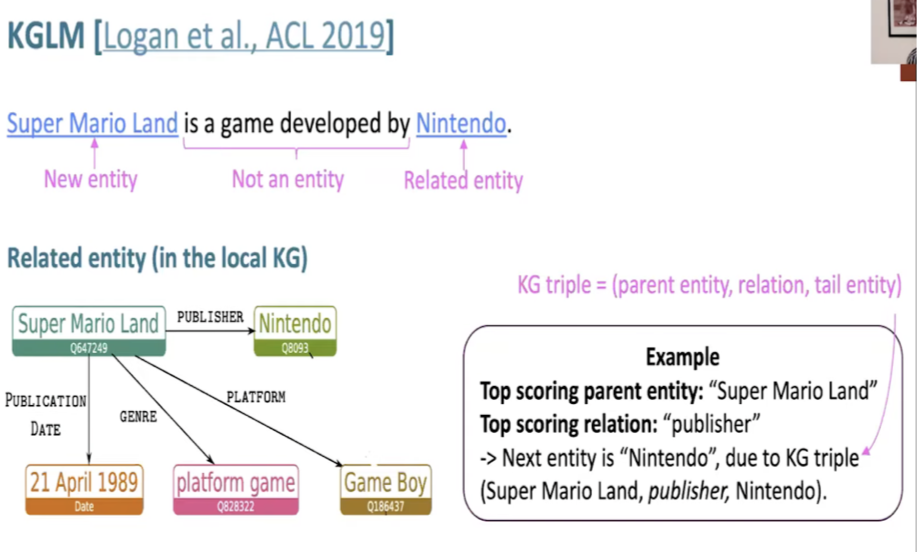
- The below slide (source) describes KGLM.
- Entity Analysis: For new entities, KGLM finds the top scoring entity in the full KG using LSTM hidden states and pretrained entity embeddings.
- Performance: KGLM outperforms GPT-2.
- Nearest Neighbor Language Models (kNN-LM): These focus on learning text sequence similarities, storing all representations in a nearest neighbor datastore.
Evaluating Knowledge in LMs
- Language Model Analysis: LAMA probe assesses relational knowledge (both commonsense and factual) in off-the-shelf language models, without additional training or fine-tuning.
- Limitations of LAMA Probe:
- It’s challenging to understand why models perform well in certain situations.
- Models like BERT large may rely on memorizing co-occurrence patterns rather than truly understanding the context or statements.
Citation
If you found our work useful, please cite it as:
@article{Chadha2021Distilled,
title = {Knowledge Graphs},
author = {Jain, Vinija and Chadha, Aman},
journal = {Distilled Notes for Stanford CS224n: Natural Language Processing with Deep Learning},
year = {2021},
note = {\url{https://aman.ai}}
}