Natural Language Processing • NLP Tasks
- Overview
- Named Entity Recognition (NER)
- Dependency Parsing
- Sentiment Analysis
- Text Summarization
- Question Answering
- Text Classification
- Citation
Overview
- This primer examines several tasks that can be effectively addressed using Natural Language Processing (NLP).
Named Entity Recognition (NER)
- Named Entity Recognition (NER) is a crucial component of NLP that plays a vital role in information extraction and data - analysis. It focuses on identifying and categorizing named entities within text into predefined categories, which can significantly enhance the understanding and interpretation of large volumes of text.
- In other words, NER stands as a cornerstone in the realm of NLP, offering a pathway to transform unstructured text into structured, actionable data. Its ability to identify and categorize entities accurately opens doors to a myriad of applications across various industries, making it an indispensable tool in the age of information.
- Here is a detailed look at NER, including its process, applications, methodologies, and advancements.
Definition and Purpose
- Primary Goal: NER aims to locate and classify named entities mentioned in text into specific categories such as names of individuals, organizations, locations, expressions of times, quantities, monetary values, percentages, etc.
- Importance in NLP: As a fundamental task in NLP, NER helps in structuring and categorizing unstructured text, making it a critical component for tasks like data retrieval, analysis, and understanding.
Process and Techniques
- NER operates in two stages: (i) detection of a named entity, followed by its (ii) categorization/classification. The following slide, sourced from the Stanford CS224n course, illustrates this:

- Entity Identification: The first step in NER is to identify a potential named entity within a body of text. This can be a single word or a sequence of words forming a name.
- Classification: Once an entity is identified, it’s classified into predefined categories like ‘Person’, ‘Organization’, ‘Location’, etc.
- Contextual Analysis: NER systems use the context around each identified entity for accurate classification. This involves analyzing the surrounding words and understanding the entity’s role within the sentence.
- Word Vector Analysis: Modern NER systems often use word vectors, representations of words in a multidimensional space, to capture semantic and syntactic meanings.
Common Architectures and Models
- Bidirectional LSTM (BiLSTM) with CRF: BiLSTM processes text data in both forward and backward directions, capturing context more effectively. The Conditional Random Field (CRF) layer then uses this context to classify entities more accurately.
- Transformer-based Models: With the advent of Transformer models like BERT, NER systems have significantly improved. These models capture a deeper and more nuanced understanding of context, which is essential for accurate entity recognition and classification.
Sub-types of NER
- Fine-Grained NER: This involves categorizing entities into more specific sub-categories, offering a more detailed analysis. For example, instead of just ‘Person’, it might classify entities as ‘Artist’, ‘Politician’, etc.
- Cross-Lingual NER: Identifies and categorizes named entities in multiple languages, crucial for global applications and multilingual data sets.
- Real-Time NER: Designed for immediate processing of text data, such as in live news feeds or social media streams.
Applications of NER
- Information Retrieval: Enhances the accuracy of search engines and databases in finding relevant information based on named entities.
- Content Classification: Helps in categorizing text data for better content management systems.
- Customer Support and CRM: Identifies key entities in customer communications, aiding in efficient and personalized responses.
- Business Intelligence: Extracts useful information from business documents for market analysis, competitor analysis, etc.
- Healthcare Data Analysis: In medical records, NER can identify and classify terms related to diseases, treatments, medications, etc., aiding in better patient care and research.
Challenges and Considerations
- Ambiguity in Entity Classification: Differentiating between entities with similar names or those that can fall into multiple categories.
- Adaptation to Different Domains: Customizing NER systems to work effectively across various domains like legal, medical, or technical fields, each with its unique terminology.
- Dealing with Slang and Neologisms: Especially in social media texts, where new words and informal language are common.
Future Directions
- Integration with Deep Learning: Leveraging more advanced deep learning techniques to enhance the accuracy and adaptability of NER systems.
- Greater Contextual Understanding: Improving the ability of NER systems to understand entities in a wider context, particularly in complex sentences or documents.
- Multimodal NER: Incorporating other data types like audio and video for a more comprehensive entity recognition process.
Dependency Parsing
- Dependency Parsing is a critical task in NLP that involves analyzing the grammatical structure of a sentence. It identifies the dependencies between words, determining how each word relates to others in a sentence. This analysis is pivotal in understanding the meaning and context of sentences in natural language texts.
- In other words, Dependency Parsing is a foundational element in NLP, essential for understanding the syntactic structure of language. Its ability to dissect sentences and analyze the grammatical relationships between words is fundamental in various advanced NLP applications. As the field of NLP evolves, dependency parsing continues to adapt and advance, integrating new methodologies and technologies to meet the increasing complexity of human language processing.
- Here’s a detailed look at Dependency Parsing, its methodologies, applications, challenges, and advancements.
Definition and Purpose
- Primary Objective: Dependency parsing aims to establish the grammatical structure of sentences by elucidating the relationships between ‘head’ words and words that modify or are dependent on these heads.
- Importance in NLP: It plays a crucial role in understanding the syntactic structure of sentences, which is fundamental for various NLP tasks like machine translation, sentiment analysis, and information extraction.
Process and Techniques
- Parsing Structure: The process involves breaking down a sentence into its constituent parts and identifying the type of dependency relations among them, such as subject, object, modifier, etc.
- Dependency Trees: The outcome of dependency parsing is often represented as a tree structure, where nodes represent words, and edges represent the dependencies between them.
- Dependency Labels: Each dependency is labeled with the type of grammatical relation it represents, like ‘nsubj’ for nominal subject, ‘dobj’ for direct object, etc. The following slide, sourced from the Stanford CS224n course, illustrate this:
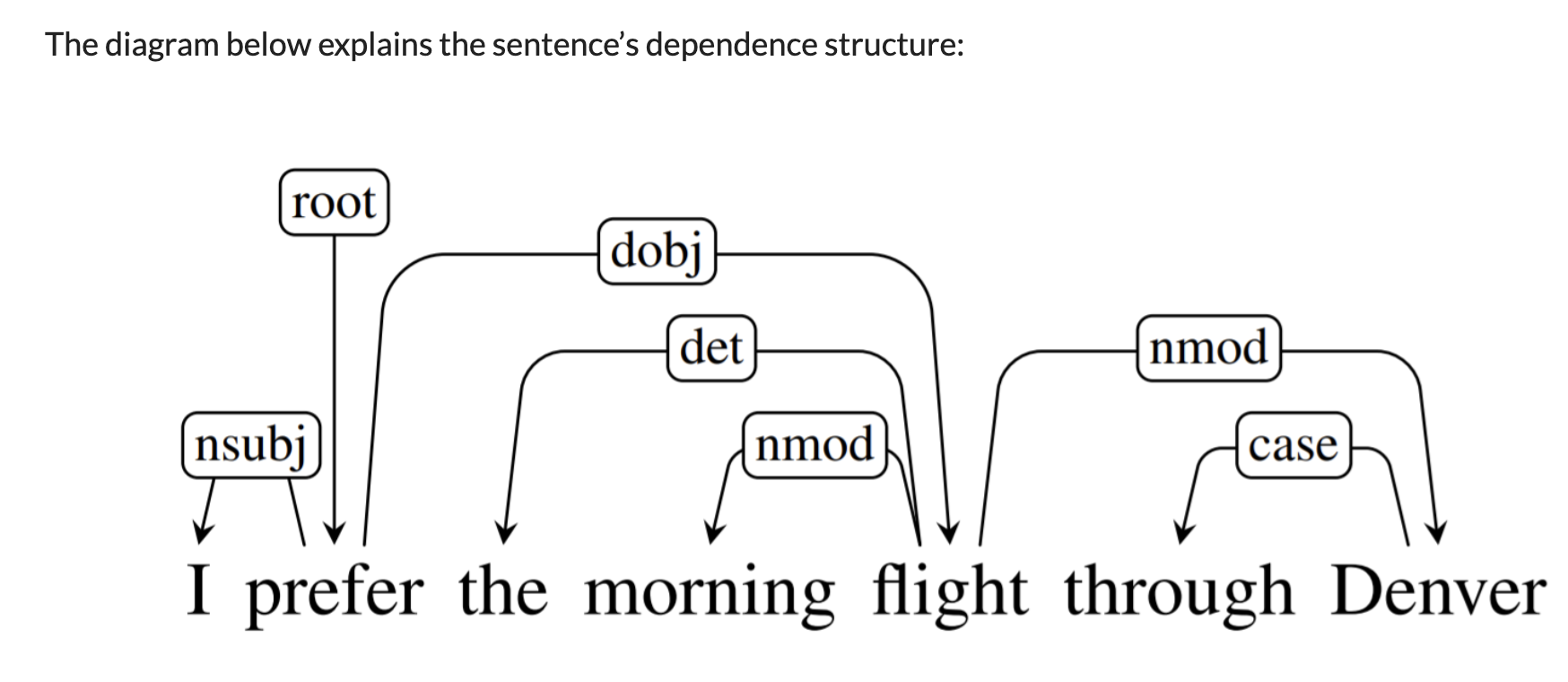
Common Architectures and Models
- Transition-Based Parsers: These parsers process the sentence in a linear fashion, typically from left to right, using a stack to hold words that are waiting to be processed.
- Graph-Based Parsers: These consider all possible relationships between words in a sentence and select the highest scoring dependency tree based on a scoring function.
- Neural Network Models: With advances in deep learning, neural network models like BiLSTM have been used to capture the context of the entire sentence, improving the accuracy of dependency parsing. A neural dependency parser, such as the one proposed by Chen and Manning in 2014, inputs parts of speech tags and dependency labels, yielding a structured representation of a sentence’s grammatical dependencies.
- Transformer-Based Models: Models like BERT encode sentences and then use separate parsers to predict dependencies. They excel at capturing wider sentence context, enhancing parsing accuracy.
Sub-types of Dependency Parsing
- Projective Parsing: Deals with dependencies that can be represented without crossing lines in a 2D plane. Suitable for languages with a more straightforward grammatical structure.
- Non-Projective Parsing: Addresses complex dependencies, including those with crossing lines, often required in languages with freer word order.
Applications of Dependency Parsing
- Machine Translation: Helps in understanding the grammatical structure of the source language for accurate translation.
- Information Extraction: Essential for extracting structured information from unstructured text.
- Text Summarization: Enables identifying key grammatical structures to extract meaningful sentences for summaries.
- Sentiment Analysis: Helps in understanding the grammatical constructs to accurately determine sentiment.
Challenges and Considerations
- Handling Complex Sentences: Parsing sentences with intricate structures or ambiguous grammatical relationships can be challenging.
- Language Variability: Different languages exhibit varied and complex grammatical patterns, which poses a challenge for creating universal parsing models.
- Computational Efficiency: Balancing accuracy with computational efficiency, especially for real-time applications.
Future Directions
- Cross-Lingual Dependency Parsing: Developing models that can accurately parse sentences in multiple languages without language-specific training.
- Integration with Semantic Analysis: Combining syntactic parsing with semantic analysis for a more comprehensive understanding of text.
- Enhanced Deep Learning Techniques: Leveraging advancements in deep learning to improve the accuracy and efficiency of dependency parsers.
Sentiment Analysis
- Sentiment Analysis, also known as opinion mining, is a fascinating and vital aspect of NLP that focuses on identifying and categorizing opinions expressed in text. It aims to discern the sentiment or emotional tone behind a series of words, providing insights into the attitudes, emotions, and opinions embedded within text data.
- In other words, Sentiment Analysis represents a dynamic and rapidly evolving field in NLP. By harnessing the power of sentiment analysis, businesses, researchers, and individuals can gain deeper insights into the vast and ever-growing world of text data, from social media posts and customer reviews to news articles and beyond. As technology continues to advance, sentiment analysis will undoubtedly become even more sophisticated, providing richer and more nuanced understandings of human emotions and opinions.
- Here is a detailed exploration of Sentiment Analysis, covering its methodologies, applications, challenges, and advancements.
Definition and Purpose
- Core Objective: Sentiment Analysis involves the computational study of opinions, sentiments, and emotions expressed in text, aiming to determine the attitude of a speaker or writer towards a particular topic, product, or the overall sentiment of a document.
- Importance in NLP: It is crucial for understanding the subjective aspects of language, going beyond mere word recognition to comprehend the nuances of emotional expression.
Process and Techniques
- Levels of Analysis:
- Document Level: Determines the overall sentiment of an entire document.
- Sentence Level: Assesses the sentiment of individual sentences.
- Aspect Level: Focuses on specific aspects or attributes within the text, like analyzing sentiments about different features of a product.
- Sentiment Scoring: Often involves assigning a polarity score to the text, indicating positive, negative, or neutral sentiments.
- Contextual and Linguistic Nuances: Recognizing that the same word can have different sentiment implications based on context, and dealing with linguistic nuances like sarcasm and irony.
Common Architectures and Models
- Rule-Based Systems: Utilize a set of manually crafted rules and lexicons (lists of words and their sentiment scores) to assess sentiment.
- Machine Learning Approaches:
- Supervised Learning: Uses labeled datasets to train models on recognizing sentiment-laden text.
- Unsupervised Learning: Relies on algorithms to identify sentiment patterns without pre-labeled data.
- Deep Learning Models:
- Convolutional Neural Networks (CNNs): Efficient in extracting local and position-invariant features.
- Recurrent Neural Networks (RNNs) and LSTM (Long Short-Term Memory): Effective for capturing long-range dependencies in text.
- Transformer-Based Models: Models like BERT, GPT, or RoBERTa offer superior performance in capturing complex contextual relationships.
Applications of Sentiment Analysis
- Brand Monitoring and Product Analysis: Companies use sentiment analysis to monitor brand reputation and understand consumer reactions to products and services.
- Market Research: Helps in analyzing public sentiment towards market trends, political events, or social issues.
- Customer Service: Automates the process of sorting customer feedback and complaints based on their sentiment.
- Social Media Monitoring: Tracks public sentiment on social media platforms about various topics, events, or products.
Challenges and Considerations
- Sarcasm and Irony: Detecting and correctly interpreting sarcasm and irony remains a significant challenge.
- Contextual Variability: The sentiment value of words can change drastically depending on the context.
- Cross-Lingual Sentiment Analysis: Developing models that can accurately analyze sentiment in multiple languages.
- Real-Time Analysis: Providing accurate sentiment analysis in real-time, especially for live data streams like social media.
Future Directions
- Emotion Detection: Extending beyond polarity (positive/negative) to detect a range of emotions like joy, anger, or sadness.
- Multimodal Sentiment Analysis: Incorporating audio, visual, and textual data to provide a more holistic sentiment analysis.
- Deep Learning Advancements: Leveraging the advancements in deep learning for more accurate and context-aware sentiment analysis.
- Domain-Specific Models: Tailoring sentiment analysis models for specific industries or sectors for more precise analysis.
Text Summarization
- Text Summarization in NLP refers to the process of creating a concise and coherent summary of a larger text while retaining the key information and overall meaning. It’s a challenging task, as it requires understanding the content, context, and structure of the text, and then producing a summary that is both accurate and informative.
- Put simply, Text Summarization in NLP is a vital tool for digesting large volumes of text data, providing users with quick and efficient access to key information. As the field evolves, we can expect more advanced models capable of producing summaries that are not only accurate and concise but also nuanced and tailored to specific user needs.
- Here’s a detailed exploration of Text Summarization.
Definition and Purpose
- Core Objective: The primary goal of text summarization is to produce a condensed version of a text, which captures its essential information, making it easier for readers to grasp the main points quickly.
- Importance in NLP: With the ever-growing amount of textual data, summarization aids in managing information overload by providing succinct versions of longer documents, enhancing accessibility and comprehension.
Types of Text Summarization
- Extractive Summarization: This involves identifying and extracting key phrases and sentences from the original text to create a summary. Essentially, it involves creating a subset of the original content that represents the most important points.
- Abstractive Summarization: This approach generates a new summary, potentially using words and phrases not present in the original text. It involves understanding the text and then rephrasing and rewriting to create a coherent summary, much like how a human would summarize a document.
Methodologies and Models
- Rule-Based Systems: Early approaches to summarization were based on rule-based systems, which relied on manually crafted rules to identify key sentences or phrases.
- Machine Learning Approaches:
- Supervised Learning: Uses labeled datasets to train models to identify important parts of the text for summarization.
- Unsupervised Learning: Employs algorithms to find patterns in the text that signify importance without the need for labeled data.
- Deep Learning Models:
- Sequence-to-Sequence Models: Such as LSTM (Long Short-Term Memory) or GRU (Gated Recurrent Units) networks, read the input text as a sequence and generate the summary as another sequence.
- Transformer-Based Models: Models like T5 (Text-To-Text Transfer Transformer) or BART (Bidirectional and Auto-Regressive Transformers) have shown strong performance in abstractive summarization due to their capacity for understanding and generating complex text.
Applications of Text Summarization
- News Aggregation: Summarizing news articles for quick and concise updates.
- Academic Research: Summarizing research papers or academic articles for faster literature review and analysis.
- Business Intelligence: Generating summaries of business documents, reports, or emails for efficient information processing and decision-making.
- Legal and Medical Document Summarization: Condensing legal cases or medical reports for quick reference.
Challenges and Considerations
- Maintaining Context and Coherence: Ensuring that the summary maintains the original context and flows coherently.
- Dealing with Redundancy: Avoiding redundant information in the summary, especially in extractive summarization.
- Bias in Source Text: Ensuring that the summarization process does not amplify any inherent biases present in the source text.
- Evaluation of Summaries: Assessing the quality of summaries, as the task can be subjective and context-dependent.
Future Directions
- Cross-Language Summarization: Developing systems capable of summarizing text in one language and generating summaries in another.
- Personalized Summarization: Creating summaries tailored to the specific interests or requirements of the user.
- Integration with Other NLP Tasks: Combining summarization with tasks like sentiment analysis or question answering for more context-aware summarization.
- Improving Abstraction Capabilities: Advancing the ability of models to generate more human-like, coherent, and contextually relevant abstractive summaries.
Question Answering
- Question Answering (QA) is a specialized domain within NLP focused on building systems that automatically answer questions posed by humans in natural language. It’s a complex task that combines understanding human language, context interpretation, and often retrieving information from various sources.
- Here’s a detailed exploration of Question Answering in NLP.
Definition and Purpose
- Core Objective: The primary goal of QA systems is to provide accurate, concise, and relevant answers to questions posed in natural language.
- Importance in NLP: QA systems are at the forefront of making information accessible and understandable to users, bridging the gap between human queries and the vast amount of data available in text form.
Types of Question Answering Systems
- Factoid QA: Answers simple, fact-based questions like “What is the capital of France?”. These require direct retrieval of facts from a database or text.
- List QA: Involves questions expecting a list of items as answers, such as “List the novels written by Jane Austen.”
- Definition QA: Provides definitions or explanations for terms or concepts.
- Reasoning QA: Requires logical reasoning, inference, and understanding of context. These are more complex, for example, “Why does the Earth experience seasons?”
- Conversational QA: Involves answering questions in a conversational context, where each question might relate to previous ones in the conversation.
Methodologies and Models
- Retrieval-Based QA: Involves retrieving an answer from a structured database or a set of documents. This is more common in factoid QA.
- Generative QA: Generates answers based on understanding and processing the question, often used in more complex QA tasks.
- Neural Network Models: Deep learning models, particularly those based on Transformer architecture like BERT, GPT, or T5, have significantly advanced the field of QA. These models are pre-trained on a large corpus of text and fine-tuned for specific QA tasks.
- End-to-End Learning: Recent approaches involve training models that can handle the entire QA process in a single step, from understanding the question to providing the answer.
Applications of Question Answering
- Customer Support: Automated systems provide quick responses to customer queries, improving efficiency and customer satisfaction.
- Educational Tools: Assisting students in learning by providing instant answers to academic queries.
- Search Engines: Enhancing search engine capabilities by directly answering queries instead of just listing relevant documents.
- Healthcare Assistance: Providing quick answers to common medical queries, aiding both patients and healthcare professionals.
Challenges and Considerations
- Understanding Context: QA systems must understand the context within which a question is asked, especially in conversational QA.
- Ambiguity and Vagueness: Handling ambiguous or vague questions that might have multiple valid answers.
- Domain-Specific Knowledge: Specialized domains like law or medicine require the system to have domain-specific knowledge for accurate answers.
- Language Variety and Slang: Effectively interpreting questions phrased in different dialects, colloquial language, or slang.
Future Directions
- Improved Contextual Understanding: Enhancing the ability of QA systems to understand and remember context over longer conversations.
- Cross-Lingual QA: Developing systems that can answer questions in multiple languages.
- Integration with Voice-Based Systems: Combining QA with speech recognition for voice-activated systems, like digital assistants.
- Personalized QA: Tailoring answers based on the user’s profile, previous queries, and preferences.
FAQs
What are the types of Question Answering systems?
-
Question Answering (QA) systems come in various types, each designed to handle specific kinds of queries or data sources. Here’s a detailed look at five notable types: Closed-Book QA, Open-Book QA, Closed-Domain QA, Open-Domain QA, and Visual QA.
- Closed-Book QA:
- Description: In Closed-Book QA, the system answers questions based on knowledge it has internalized during its training. It does not access any external information sources or databases while answering.
- Operation: The system relies on what it has ‘learned’ and stored in its parameters through extensive training on a wide range of data.
- Applications: Ideal for scenarios where quick, factual responses are needed, and the range of expected questions is within the scope of the model’s training.
- Limitations: The accuracy and depth of answers are limited to the content and quality of its training data. It might not be current or comprehensive for all possible questions.
- Open-Book QA:
- Description: Open-Book QA systems answer questions by referring to external data sources such as the internet, databases, or specific documents.
- Operation: When posed with a question, these systems search for relevant information in external sources, process it, and then generate an answer.
- Applications: Useful for questions requiring up-to-date information or topics that are too broad or current to be covered entirely in the training data.
- Limitations: The effectiveness depends on the system’s ability to access, search, and understand relevant external information.
- Closed-Domain QA:
- Description: This type of system specializes in answering questions within a specific field or domain, such as medicine, law, or a particular set of literature.
- Operation: It is trained with domain-specific data, enabling it to understand and process queries relevant to that domain deeply.
- Applications: Particularly useful in professional or academic fields where expertise in a specific subject matter is required.
- Limitations: Its scope is limited to the predefined domain, and it may not perform well on questions outside of that domain.
- Open-Domain QA:
- Description: Open-Domain QA systems are designed to answer questions across a wide range of topics, not limited to any specific subject area.
- Operation: These systems are typically trained on a diverse set of data from various fields and may use both closed-book and open-book methods to generate answers.
- Applications: Ideal for general-purpose question answering where the queries can span a wide array of subjects.
- Limitations: While versatile, they might not have the depth of knowledge in specific areas compared to closed-domain systems.
- Visual QA:
- Description: Visual QA involves answering questions based on visual content such as images or videos.
- Operation: These systems analyze visual input, understand the context, and then answer questions related to that input.
- Applications: Useful in scenarios where the query is about the content or context of a visual input, like identifying objects, actions, or explaining scenes in an image or video.
- Limitations: The accuracy depends heavily on the system’s ability to interpret visual data correctly, which can be challenging due to the complexity and variability of visual content.
- Closed-Book QA:
-
Each of these QA systems has its unique strengths and is suited for different applications. The development and improvement of these systems are ongoing, driven by advances in machine learning, natural language processing, and computer vision.
What is the difference between open- and closed-book QA?
- The difference between open-book and closed-book question answering (QA) lies primarily in how information is accessed and utilized to answer questions.
- Closed-Book QA: In closed-book qQA, the system answers questions based solely on information it has been pre-trained on. It doesn’t have access to external sources or databases during the answering process. The knowledge is, in a sense, “memorized” or encoded in the model’s parameters through its training data. This method requires the model to have a large and comprehensive training dataset so that it can cover a wide range of topics. The model’s ability to answer questions is limited to what it has been trained on. Closed-book QA, unlike open-book QA, does not typically involve providing a specific context or passage with the question. The system relies on its pre-trained knowledge to answer questions, without external text references. In this model, the answers are generated based on the information encoded in the system’s parameters, without the need for external text for reference.
- Open-Book QA: Open-book question answering, on the other hand, involves the system actively retrieving information from external sources or databases to answer questions. This can include looking up information on the internet, accessing specific databases, or referring to external documents. In this approach, a specific context or passage is provided along with the question. The system uses this context this external information in real-time to formulate an answer. The context can be a paragraph, a document, or a set of documents from which the system retrieves information relevant to the question. This approach is particularly useful for complex questions where the answer depends heavily on understanding and analyzing a given text, allowing the system to access the most current and detailed information available, even if it wasn’t included in its original training data.
- In summary, closed-book QA relies on a model’s internal knowledge gained during training, while open-book QA involves external information retrieval to supplement the model’s knowledge base. Open-book QA tends to be more dynamic and up-to-date, whereas closed-book QA depends heavily on the breadth and quality of the training data.
How are open-book and open-domain QA different?
-
Open-book QA and open-domain QA are not the same, though they might sound similar. Each term refers to different aspects of question answering systems:
-
Open-Book QA: Open-book question answering involves the use of external information sources to answer questions. In this approach, the system actively retrieves information from external documents, databases, or the internet to respond to queries. The focus is on the system’s ability to look up and synthesize information from outside its pre-trained knowledge base.
-
Open-Domain QA: Open-domain question answering, on the other hand, refers to the system’s ability to answer questions across a wide range of topics or domains, without being restricted to a specific subject area. This can be achieved either through closed-book methods (where the model relies on its internal knowledge acquired during training) or open-book methods (where it looks up information externally). The key aspect of open-domain QA is its versatility and breadth in handling questions from various fields, be it science, history, popular culture, etc.
-
-
In summary, open-book QA is about the source of the information (external resources), while open-domain QA is about the scope of the topics (broad and unrestricted). A question answering system can be both open-book and open-domain if it uses external resources to answer questions on a wide range of topics.
Text Classification
- Text Classification, also known as text categorization, is a fundamental task in NLP that involves assigning predefined categories or labels to text. It’s widely used to organize, structure, and make sense of large volumes of unstructured textual data. This process enables efficient handling and analysis of text for various applications.
- Put simply, Text Classification is a critical aspect of NLP, playing a pivotal role in structuring and understanding textual data. As the field advances, text classification methods are becoming more sophisticated, moving towards more accurate, context-aware, and language-agnostic systems. These advancements are making it increasingly possible to harness the full potential of textual data across various domains.
- Here’s a detailed exploration of Text Classification.
Definition and Purpose
- Core Objective: Text Classification aims to automatically classify or categorize text into one or more predefined categories or classes based on its content.
- Importance in NLP: It’s essential for organizing and structuring large datasets of text, making it easier to process and analyze information efficiently.
Types of Text Classification
- Binary Classification: Involves categorizing text into two categories (e.g., spam or not spam).
- Multi-Class Classification: Classifies text into one of multiple categories (e.g., classifying news articles into categories like sports, politics, entertainment).
- Multi-Label Classification: Each text can belong to multiple categories simultaneously (e.g., a news article that is categorized as both technology and business).
Methodologies and Models
- Rule-Based Systems: Early text classification systems used manually crafted rules based on keywords or phrases.
- Machine Learning Approaches:
- Supervised Learning: Uses labeled datasets to train models to classify texts. Common algorithms include Naive Bayes, Support Vector Machines (SVM), and Decision Trees.
- Unsupervised Learning: Identifies patterns or clusters in the data without using pre-labeled examples.
- Deep Learning Models:
- Convolutional Neural Networks (CNNs): Effective for capturing local and position-invariant features in text.
- Recurrent Neural Networks (RNNs) and their variants like LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Units): Suitable for capturing the sequential nature of text.
- Transformer-Based Models: Such as BERT (Bidirectional Encoder Representations from Transformers) and XLNet, these models have revolutionized text classification with their ability to capture the context of each word in a sentence.
Applications of Text Classification
- Spam Detection: Identifying and filtering out spam emails.
- Sentiment Analysis: Categorizing text by sentiment, such as positive, negative, or neutral.
- Topic Labeling: Automatically labeling topics of articles or posts.
- Language Detection: Classifying text by the language it’s written in.
Challenges and Considerations
- Imbalanced Data: Often, datasets are imbalanced, with some classes having significantly more examples than others, leading to biased models.
- Contextual Ambiguity: Words or phrases can have different meanings in different contexts, posing a challenge for accurate classification.
- Handling Slang and Abbreviations: Particularly in social media text, where unconventional language is common.
- Multilingual and Cross-Lingual Classification: Classifying text written in different languages or developing models that can classify text across languages.
Future Directions
- Transfer Learning and Pre-Trained Models: Leveraging models trained on large datasets to improve performance on specific classification tasks, even with smaller datasets.
- Fine-Tuning and Domain Adaptation: Adapting pre-trained models to specific domains or topics for more accurate classification.
- Cross-Lingual Learning: Building models that can understand and classify text in multiple languages.
- Integrating Contextual Information: Incorporating additional contextual information for more nuanced classification, such as the author’s profile or related metadata.
Citation
If you found our work useful, please cite it as:
@article{Chadha2021Distilled,
title = {NLP Tasks},
author = {Jain, Vinija and Chadha, Aman},
journal = {Distilled AI},
year = {2021},
note = {\url{https://aman.ai}}
}