Recommendation Systems • LLM
- Overview
- 1. Foundation & Generative Models in Recsys
- Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations
- Bridging Search and Recommendation in Generative Retrieval: Does One Task Help the Other?
- EmbSum: Leveraging the Summarization Capabilities of Large Language Models for Content-Based Recommendations
- Transforming the LLM: Recommender Systems with Generative Retrieval (NeurIPS 2023)**
- Better Generalization with Semantic IDs: A Case Study in Ranking for Recommendations
- CALRec: Contrastive Alignment of Generative LLMs for Sequential Recommendation
- Sliding Window Training - Utilizing Historical Recommender Systems Data for Foundation Models
- 2. Knowledge Distillation for LLM-Based Recsys
- 3. Cross-Domain & Multi-Domain CTR
- 4. Advanced/Unified Architectures (Embedding, GNN, Multi-Task, Search Synergy)
- Unified Embedding-Based Personalized Retrieval in Etsy Search
- beeFormer: Bridging the Gap Between Semantic and Interaction Similarity in Recommender Systems
- FLIP: Fine-grained Alignment between ID-based Models and Pretrained Language Models for CTR Prediction
- Recommendations and Results Organization in Netflix Search
- Augmenting Netflix Search with In-Session Adapted Recommendations
- Synergistic Signals: Exploiting Co-Engagement and Semantic Links via Graph Neural Networks
- IntentRec: Predicting User Session Intent with Hierarchical Multi-Task Learning
- Joint Modeling of Search and Recommendations Via an Unified Contextual Recommender (UniCoRn)
- 5. Transformers & Next-Item Prediction
- References
Overview
- Generative AI and LLMs in particular are taking over the industry. Foundation models specifically are becoming increasingly popular in recommendation systems for either learning user and item representations for downstream tasks, or to be leveraged to make predictions of the next item to recommend. In this primer, I want to dive into how they can be leveraged for recommender systems by going through some of industries’ leading papers showcasing how they are doing just that.
- I have divided the papers here in their relevant subsections below.
1. Foundation & Generative Models in Recsys
Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations
-
Authors: Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Michael He, Yinghai Lu, Yu Shi
-
This paper introduces Hierarchical Sequential Transduction Units (HSTU) and a new Generative Recommender (GR) paradigm, demonstrating that sequential transduction models can replace Deep Learning Recommendation Models (DLRMs) and scale to trillion-parameter sizes while maintaining 5.3x-15.2x faster performance than FlashAttention2-based Transformers. Let’s dig into what this paper has to offer below.
1. Reformulating Recommendation as a Sequential Transduction Task (Generative Recommenders, GRs)
- Traditional DLRMs rely on explicit feature engineering, requiring categorical embeddings, numerical features, and manually crafted interactions.
- The paper proposes a purely sequential transduction approach, unifying heterogeneous features (e.g., categorical, numerical) into a single time-series format.
- Ranking and retrieval tasks are redefined as generative modeling problems, where a model predicts user actions sequentially given historical interactions.
- Demonstrates that scaling laws similar to LLMs apply to recommendation systems, enabling large models to generalize better without excessive feature engineering.
2. Introducing HSTU: A Trillion-Parameter Sequential Transducer for Large-Scale Recommendations
- HSTU (Hierarchical Sequential Transduction Unit) replaces Transformers as the main encoder for large-scale recommendation tasks.
- Unlike standard Transformers, HSTU introduces pointwise aggregated attention, avoiding softmax-based normalization that poorly handles high-cardinality, non-stationary vocabularies.
- Features:
- Pointwise Projection Layer: MLP-based feature extractor replacing traditional categorical embedding lookups.
- Spatial Aggregation via Pointwise Attention: Computes interactions without requiring O(n²) self-attention, improving efficiency.
- Pointwise Transformation with Elementwise Gating: Replaces Transformer-based feature interactions with gated cross-attention, preserving computational efficiency.
3. Computational Optimizations for Large-Scale Sequential Models
- M-FALCON: Microbatched-Fast Attention Leveraging Cacheable Operations
- Allows batch processing of tens of thousands of candidates in ranking tasks without increasing inference cost.
- Reduces attention computation from O(bmn²d) → O(n²d), amortizing computational cost over multiple ranking candidates.
- Stochastic Length (SL): Efficient Sequence Processing
- Observes that user interaction histories are highly redundant and stochastically selects a subset of sequence elements for training.
- Reduces training cost from O(N³d) to O(N²d) while maintaining near-identical performance.
- Optimizer Memory Reduction (Rowwise AdamW, DRAM Placement)
- Large-scale recommendation models require terabytes of memory for embeddings.
- Uses rowwise AdamW with DRAM placement, reducing memory requirements from 60TB to ~10TB for a 10B vocabulary model.
- Key Takeaways:
- Generative Recommenders (GRs) outperform DLRMs in both efficiency and accuracy, replacing manual feature engineering with pure sequential transduction.
- HSTU achieves state-of-the-art efficiency for large-scale sequential models, making trillion-parameter recommenders feasible.
- Scaling laws similar to LLMs apply to recommendation systems, indicating that increasing compute alone can improve recommender quality.
Bridging Search and Recommendation in Generative Retrieval: Does One Task Help the Other?
-
Authors: Gustavo Penha, Ali Vardasbi, Enrico Palumbo, Marco de Nadai, Hugues Bouchard (Spotify)
-
This paper explores whether a unified generative retrieval model that jointly trains on both search and recommendation tasks can outperform task-specific models. The authors provide theoretical and empirical evidence that multi-task training regularizes popularity biases and item representations, leading to improved performance in retrieval-based recommendation systems.
-
Key Technical Contributions:
- 1. Generative Retrieval as a Unification of Search & Recommendation
- Traditional retrieval approaches rely on nearest-neighbor searches and external indexes.
- Generative retrieval (GR) models, powered by Large Language Models (LLMs), directly map queries/user interactions to item IDs, enabling end-to-end retrieval without external indexing.
- The authors propose a multi-task generative model that handles both search and recommendation, learning a unified latent space for item representation.
- 2. Core Hypotheses for Multi-Task Learning
- Popularity Regularization
- GR models are biased towards popular items.
- Training jointly across search and recommendation helps stabilize item popularity estimations.
- Effective when the popularity distributions of search and recommendation have low Kullback–Leibler (KL) divergence.
- Latent Representation Regularization
- Items have dual roles:
- Search captures content-based item properties.
- Recommendation captures collaborative filtering signals.
- A joint model can enhance representation learning, particularly when item co-occurrences in search & recommendation align well.
- Items have dual roles:
- Popularity Regularization
- 3. Model Architecture & Training
- The generative model, Gen𝑅+𝑆, is based on a T5 Transformer (FLAN-T5).
- Item IDs are treated as learnable tokens within the LLM vocabulary.
- Training tasks:
- Generative Recommendation (Gen𝑅): Predict next item given user history.
- Generative Search (Gen𝑆): Predict relevant item given a query.
- Joint Model (Gen𝑅+𝑆): Trained on both datasets simultaneously.
- 4. Experiments & Findings
- Simulated & real-world datasets (MovieLens, Million Playlist Dataset, Spotify Podcasts).
- Evaluated using Recall@K metrics.
- Results:
- Gen𝑅+𝑆 improves R@30 by 16% on average compared to single-task models.
- Popularity regularization occurs, but effectiveness depends on how closely popularity distributions align.
- Latent representation improvements are most significant when item co-occurrences match across tasks.
- 5. Additional Insights
- Effect of removing popularity bias: When artificially limiting item appearances in training, model performance drops, confirming [H1].
- Effect of data redundancy: Items appearing in both search & recommendation training data reinforce model learning, while unique items improve diversity.
EmbSum: Leveraging the Summarization Capabilities of Large Language Models for Content-Based Recommendations
-
Authors: Chiyu Zhang, Yifei Sun, Minghao Wu, Jun Chen, Jie Lei, Muhammad Abdul-Mageed, Rong Jin, Angli Liu, Ji Zhu, Sem Park, Ning Yao, Bo Long
-
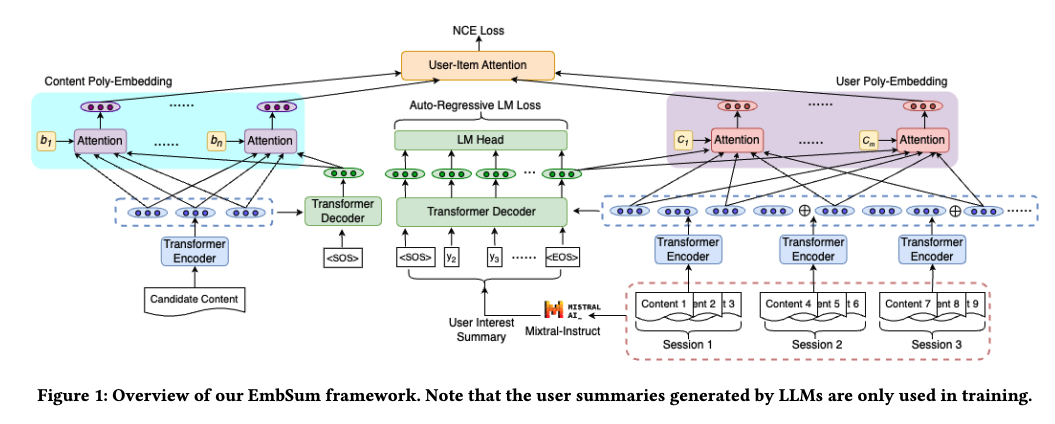
EmbSum is a novel content-based recommendation framework that utilizes an encoder-decoder architecture with poly-attention mechanisms to precompute user and content embeddings while integrating user-interest summaries generated via large language models (LLMs) for improved recommendation accuracy and efficiency.
-
Technical Contributions and Novelty
- 1. EmbSum Framework for Offline Precomputation in Recommendation Systems
- Proposes EmbSum, a framework that allows offline precomputation of user and candidate item embeddings, significantly improving inference efficiency compared to online real-time models.
- This eliminates the need for expensive real-time computations, making the system more scalable.
- 2. Novel User Poly-Embedding (UPE) and Content Poly-Embedding (CPE) Representations
- Introduces User Poly-Embedding (UPE) and Content Poly-Embedding (CPE) to encode multiple fine-grained representations of users and candidate items using poly-attention mechanisms.
- UPE is obtained by independently encoding user engagement sessions using a T5 encoder, then aggregating multiple embeddings via poly-attention to capture nuanced user interests.
- CPE applies a context-aware multi-embedding approach for candidate items, enhancing item representations beyond single-vector embeddings.
- Introduces User Poly-Embedding (UPE) and Content Poly-Embedding (CPE) to encode multiple fine-grained representations of users and candidate items using poly-attention mechanisms.
- 3. Large Language Model (LLM)-Supervised User Interest Summarization
- Uses a pretrained LLM (Mixtral-8x22B-Instruct) to generate summaries of user interests from long user engagement histories, mitigating the limitations of Transformer-based models struggling with long sequences.
- The generated summary is incorporated into the T5 decoder to create a global representation of the user’s interests.
- Uses a pretrained LLM (Mixtral-8x22B-Instruct) to generate summaries of user interests from long user engagement histories, mitigating the limitations of Transformer-based models struggling with long sequences.
-
Introduces a novel summarization loss function (Lsum) to align user representations with LLM-generated interest summaries.
- 4. Click-Through Rate (CTR) Prediction Using Noisy Contrastive Estimation (NCE) Loss
- Defines the recommendation task as a CTR prediction problem, where relevance scores between users and items are computed via the inner product of UPE and CPE embeddings.
- Implements a Noisy Contrastive Estimation (NCE) loss to improve training efficiency and model robustness.
- Defines the recommendation task as a CTR prediction problem, where relevance scores between users and items are computed via the inner product of UPE and CPE embeddings.
- 5. Empirical Validation on Benchmark Datasets
- Evaluates EmbSum on two datasets:
- MIND (Microsoft News): News article recommendation.
- Goodreads: Book recommendation based on user ratings.
- Outperforms state-of-the-art (SoTA) methods such as UNBERT, MINER, and UniTRec across multiple ranking metrics (AUC, MRR, nDCG@5, nDCG@10), while using fewer parameters.
- Evaluates EmbSum on two datasets:
- This paper presents a significant advancement in content-based recommendation systems, leveraging LLMs to generate user-interest summaries while maintaining computational efficiency through offline precomputation and poly-embedding mechanisms. 🚀
Transforming the LLM: Recommender Systems with Generative Retrieval (NeurIPS 2023)**
- Authors: Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, Maheswaran Sathiamoorthy.
-
This paper introduces Transformer Index for GEnerative Recommenders (TIGER), a generative retrieval framework for recommender systems, which replaces traditional query-candidate matching with autoregressive prediction of Semantic IDs, significantly improving retrieval performance, cold-start recommendations, and recommendation diversity.
-
Key Technical Contributions
- 1. Problem: Limitations of Traditional Retrieval in Recommendation Systems
- Modern retrieval models use dual-encoder architectures to map queries and item candidates to a common embedding space, followed by Approximate Nearest Neighbor (ANN) search.
- Challenges:
- Embedding explosion: Large-scale recommender systems require indexing billions of items.
- Cold-start issue: New or rarely interacted items struggle with representation.
- Feedback loop bias: Learning from past interactions can reinforce existing biases.
- 2. Solution: Generative Retrieval via Semantic IDs
- TIGER framework: Transforms item retrieval into a generative task using Transformer-based sequence-to-sequence models.
- Semantic IDs: Items are represented as sequences of learned discrete tokens instead of raw identifiers, capturing hierarchical and meaningful structure.
- 3. Semantic ID Generation via Residual-Quantized VAE (RQ-VAE)
- Compression of content embeddings into structured, discrete representations.
- Multi-level quantization: Captures semantic hierarchy using an iterative encoding-decoding process:
- Step 1: Content embeddings are encoded via a pre-trained model (e.g., Sentence-T5).
- Step 2: RQ-VAE recursively quantizes the embedding, generating an ordered sequence of discrete tokens (Semantic ID).
- Step 3: A decoder reconstructs the original embedding, ensuring semantic integrity.
- Advantages:
- Hierarchical encoding: Items with similar semantics share common prefixes in their Semantic IDs.
- Compact representation: Reduces memory overhead compared to full embeddings.
- 4. Generative Retrieval with Transformers
- Sequence-to-sequence modeling:
- Input: User interaction history represented as a sequence of Semantic IDs.
- Model: Transformer-based encoder-decoder predicts the Semantic ID of the next item.
- Output: Autoregressively generated Semantic ID, decoded into the target item.
- Improved cold-start handling: The model generalizes across items with similar content, mitigating reliance on historical interactions.
- Efficient tokenization: Uses a structured vocabulary of discrete codes rather than storing full embeddings.
- Sequence-to-sequence modeling:
- 5. Large-Scale Evaluation on Public Datasets
- Benchmarks: Amazon Product Reviews datasets (Beauty, Sports & Outdoors, Toys & Games).
- Metrics: Recall@K, NDCG@K.
- Key Findings:
- TIGER outperforms SOTA recommendation models (SASRec, BERT4Rec, S3-Rec, P5) across all datasets.
- RQ-VAE outperforms alternative ID representations (Locality Sensitive Hashing, Random IDs).
- Semantic ID-based retrieval improves cold-start recommendation performance over KNN-based retrieval.
- 6. Additional Capabilities: Cold-Start & Recommendation Diversity
- Cold-start recommendation:
- Semantic ID-based retrieval enables generalization to unseen items.
- Experiment: Removing 5% of test items from training → TIGER retrieves these items better than KNN-based methods.
- Diverse recommendations:
- Tunable diversity via temperature-based sampling during decoding.
- Higher entropy in retrieved item categories, mitigating repetitive recommendations.
- Cold-start recommendation:
- 7. Scalability & Efficiency Considerations
- Compact lookup tables: Semantic ID storage requires significantly less memory than full embedding-based indexing.
- Efficiency trade-offs: Generative retrieval incurs higher inference cost than ANN search but improves retrieval accuracy and diversity.
- Robust to dataset scale: Performance remains stable even when trained on combined datasets.
- This paper revolutionizes recommendation retrieval by shifting from fixed embedding-based ANN search to generative retrieval with Semantic IDs, leveraging RQ-VAE for hierarchical encoding and Transformer models for sequence prediction. TIGER significantly enhances retrieval accuracy, adaptability, and diversity, making it a strong candidate for next-generation recommender systems.
Better Generalization with Semantic IDs: A Case Study in Ranking for Recommendations
-
Authors: Anima Singh, Trung Vu, Nikhil Mehta, Raghunandan Keshavan, Maheswaran Sathiamoorthy, Yilin Zheng, Lichan Hong, Lukasz Heldt, Li Wei, Devansh Tandon, Ed H. Chi, Xinyang Yi (Google DeepMind & Google)
-
This paper proposes Semantic IDs—a compact, content-derived item representation based on Residual-Quantized Variational Autoencoder (RQ-VAE)—as an alternative to random-hashed item IDs for improving generalization in large-scale recommendation ranking models while preserving memorization. We will list this papers key contributions below:
- 1. Problem: Random Item IDs Limit Generalization
- Industry-scale recommender systems typically use randomly hashed item IDs, which allow for memorization but prevent generalization across semantically similar items.
- This limits performance on long-tail and unseen items, which are prevalent in power-law distributed content, such as in YouTube recommendations.
- Replacing IDs with content embeddings degrades performance due to loss of memorization.
- 2. Solution: Semantic IDs (SIDs) for Content-Based Hashing
- SIDs replace random item IDs with a structured, hierarchical, and discrete representation derived from content embeddings.
- Learned using RQ-VAE to encode content embeddings into a sequence of discrete tokens, capturing hierarchical relationships between items.
- This approach allows controlled generalization and memorization, striking a balance between item uniqueness and similarity.
- 3. Semantic IDs via Residual-Quantized VAE (RQ-VAE)
- Compression of content embeddings into discrete tokens while preserving semantic structure.
- Hierarchical multi-level quantization:
- Encoder maps input embeddings to latent space.
- Multi-level residual quantization maps latent vectors to a sequence of discrete codes.
- Decoder reconstructs the original embeddings from quantized representations.
- Loss function combines reconstruction loss (L_recon) and quantization loss (L_rqvae) to ensure high fidelity.
- 4. Adaptation of Semantic IDs for Ranking Models
- Directly replacing IDs with content embeddings causes quality degradation.
- Two adaptation methods are proposed for integrating SIDs into ranking models:
- N-Gram Representation:
- Groups SID codes into fixed-length n-grams (e.g., bigrams) and assigns learnable embeddings to them.
- Limitation: Exponentially increasing embedding table size.
- SentencePiece Model (SPM) Representation:
- Learns variable-length subwords from SIDs based on item distribution.
- More memory-efficient than n-grams while improving generalization and cold-start handling.
- N-Gram Representation:
- 5. Large-Scale Evaluation on YouTube Recommendation System
- Experiments on YouTube’s real-world ranking model (used for recommending the next video).
- Metrics Evaluated:
- CTR AUC (overall ranking quality).
- CTR/1D AUC (cold-start performance on newly introduced items).
- Results:
- SIDs outperform content embeddings and random hashing in both generalization and memorization.
- SPM-based SID representations outperform N-gram approaches, especially for large-scale ranking models.
- SID-based models significantly improve cold-start recommendation performance.
- 6. Stability & Efficiency of Semantic IDs
- SID representations remain stable over time, even when trained on older data, demonstrating robustness.
- SPM-based adaptation provides efficiency benefits:
- Reduces lookup costs compared to n-grams.
- Learns an optimal vocabulary based on content distribution.
- This paper presents Semantic IDs as an alternative to traditional item identifiers in large-scale ranking models. By leveraging RQ-VAE for hierarchical quantization, it enables improved generalization and better handling of long-tail recommendations while maintaining memorization via structured discrete representations. SPM-based adaptations further optimize efficiency, making SIDs a viable solution for real-world recommendation engines like YouTube.
CALRec: Contrastive Alignment of Generative LLMs for Sequential Recommendation
- Authors: Yaoyiran Li, Xiang Zhai, Moustafa Alzantot, Keyi Yu, Ivan Vulić, Anna Korhonen, Mohamed Hammad
- The figure below from the original paper, that was published in RecSys 2024, shows the overall architecture.
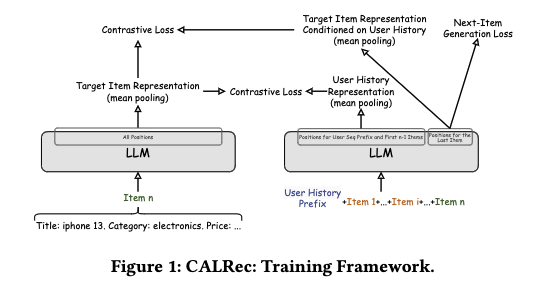
-
CALRec is a novel two-stage fine-tuning framework for generative LLMs in sequential recommendation, leveraging contrastive learning to enhance item alignment while outperforming state-of-the-art (SotA) baselines.
-
Key Technical Contributions
- 1. Two-Stage Fine-Tuning of LLMs for Sequential Recommendation
- Stage I (Multi-Category Joint Fine-Tuning): Fine-tunes an LLM on multiple domains to establish general sequential recommendation capabilities.
- Stage II (Category-Specific Fine-Tuning): Further adapts the model to a specific target domain, leveraging transfer learning from Stage I.
- Ablation studies confirm both stages are crucial, improving recommendation accuracy.
- 2. Generative LLMs for Text-Based Sequential Recommendation
- Items and user sequences are represented entirely as text rather than item IDs.
- The model predicts the next item as a text sequence generation task.
- Prompt Engineering: Introduces structured prompts with per-item prefixes and user-sequence indicators to improve LLM coherence.
- 3. Contrastive Alignment for Improved Next-Item Prediction
- Uses two contrastive losses to improve alignment:
- Item-Item Contrastive Loss ((L_{TT})) aligns target items to their predicted next-item embeddings.
- User-Item Contrastive Loss ((L_{UT})) aligns the user sequence representation with the target item.
- Contrastive losses enhance generalization and mitigate token-level next-item generation errors.
- Uses two contrastive losses to improve alignment:
- 4. Quasi-Round-Robin BM25 Retrieval for Improved Candidate Ranking
- Generative LLMs do not guarantee that predicted items exist in the dataset.
- BM25 retrieval is used to match generated text outputs to the closest items in the item corpus.
- Introduces quasi-round-robin BM25 selection, which modulates BM25 scores with LLM sequence probabilities to improve ranking stability.
- 5. Benchmarking Against State-of-the-Art Baselines
- Compared against ID-based models (SASRec, BERT4Rec), ID+text models (UniSRec, S3-Rec, FDSA), and text-only models (Recformer, LIR).
- Ablation studies confirm that:
- Removing multi-category fine-tuning decreases accuracy significantly.
- Contrastive losses improve recall and ranking performance.
- CALRec outperforms all baselines in NDCG@10, Recall@1, and MRR.
- This work advances LLM-driven recommendation systems, proving that contrastive learning and multi-stage fine-tuning can significantly enhance sequential recommendation quality. 🚀
Sliding Window Training - Utilizing Historical Recommender Systems Data for Foundation Models
- Paper by Netflix, Authors: Swanand Joshi, Yesu Feng, Ko-Jen Hsiao, Zhe Zhang, Sudarshan Lamkhede
-
The paper introduces a sliding window training approach for training Netflix’s foundation model (FM) for recommender systems, efficiently incorporating long user interaction histories without increasing input size, leading to improved long-term preference learning and item representation quality.
-
Key Contributions (Enhanced with More Detail)
- Sliding Window Training for Long Histories
- Instead of truncating older interactions, the method slides a fixed-size (
K) window over different segments of a user’s interaction history across training epochs. - This ensures that the model gradually encodes long-term user preferences without inflating input dimensions.
- Instead of truncating older interactions, the method slides a fixed-size (
- Hybrid Training Strategy for Balanced Learning
- Combines fixed-window epochs (focusing on recent interactions) with sliding-window epochs (sampling from the full history up to 500 or 1000 interactions).
- Uses a mix of sequential and randomized window selection, ensuring exposure to both recent trends and historical behaviors.
- Optimizing Netflix’s Foundation Model Pretraining
- This method is specifically designed to train Netflix’s FM for recommendation tasks, allowing it to leverage long user histories without increasing inference-time costs.
- The pretrained FM can be used for next-item prediction and user/item representation learning for downstream personalization.
- Empirical Performance Gains in Recommendation Quality
- Demonstrates improved recall, mAP, and perplexity over fixed-window baselines.
- Results show that the hybrid sliding window approach (Mixed-500, Mixed-1000) performs best, balancing recency and long-term interest learning.
- By integrating this efficient pretraining technique, Netflix’s FM can achieve better personalization while maintaining low serving latency, leading to higher-quality recommendations at scale.
2. Knowledge Distillation for LLM-Based Recsys
Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Models
- Authors: Yu Cui, Feng Liu, Pengbo Wang, Bohao Wang, Heng Tang, Yi Wan, Jun Wang, Jiawei Chen
-
This paper introduces DLLM2Rec, a novel knowledge distillation framework that transfers knowledge from Large Language Model (LLM)-based recommenders to lightweight sequential recommendation models, overcoming challenges in knowledge reliability, model capacity mismatch, and semantic space divergence.
-
Key Contributions and Technical Innovations
- 1. Addressing the High Latency of LLM-Based Recommenders
- LLM-based models (e.g., BIGRec) achieve state-of-the-art performance but suffer from massive inference times (e.g., 3 hours per inference with LLaMA2-7B on 4x A800 GPUs).
- The challenge is to retain LLM-level accuracy while reducing latency to match conventional sequential models.
-
2. Overcoming Three Major Challenges in LLM-to-Sequential Model Distillation
-
- Teacher Knowledge Reliability:
- LLM-based recommenders do not always outperform conventional models (BIGRec underperforms DROS in 30-60% of cases).
- The distillation method must selectively distill high-confidence knowledge to avoid degrading performance.
- Teacher Knowledge Reliability:
-
- Model Capacity Gap:
- LLMs have billions of parameters, while sequential models are significantly smaller (millions of parameters).
- Direct distillation can lead to overfitting or failure to transfer semantic reasoning to the student model.
- Model Capacity Gap:
-
- Semantic Space Divergence:
- LLM-based models encode items using content semantics, while sequential models rely on collaborative filtering signals.
- A naïve alignment of embeddings can disrupt the student model’s learned collaborative structure.
- Semantic Space Divergence:
-
- 3. DLLM2Rec: A Novel Distillation Framework for LLM-to-Sequential Model Transfer
-
DLLM2Rec introduces two key components:
-
- Importance-Aware Ranking Distillation (IARD)
- Filters reliable and student-friendly knowledge by applying three importance weights to teacher recommendations:
- Position-aware weight: Higher-ranked items in the teacher’s list receive more weight.
- Confidence-aware weight: Teacher recommendations with high semantic similarity to true positive items are prioritized.
- Consistency-aware weight: Items that appear in both teacher and student rankings are weighted more heavily.
- Helps students focus on digestible, high-confidence teacher knowledge instead of blindly mimicking the teacher’s outputs.
- Importance-Aware Ranking Distillation (IARD)
-
- Collaborative Embedding Distillation (CED)
- Uses a learnable projector (MLP) to map teacher embeddings into the student’s space while maintaining the student’s collaborative filtering abilities.
- Introduces a flexible offset term to capture collaborative signals missing in the LLM-based teacher’s embeddings.
- Prevents semantic misalignment that occurs when directly aligning LLM-based and sequential model embeddings.
- Collaborative Embedding Distillation (CED)
-
- This paper pushes the boundaries of knowledge distillation in recommender systems, proving that sequential models can retain LLM-level accuracy without the massive computational burden.
Bridging the Gap: Unpacking the Hidden Challenges in Knowledge Distillation for Online Ranking Systems
- Authors: Nikhil Khani, Shuo Yang, Aniruddh Nath, Yang Liu, Pendo Abbo, Li Wei, Shawn Andrews, Maciej Kula, Jarrod Kahn, Zhe Zhao, Lichan Hong, Ed Chi
- This paper addresses the overlooked challenges of applying knowledge distillation (KD) to large-scale online ranking systems, proposing novel techniques to mitigate data distribution shifts, optimize teacher-student configurations, and efficiently share teacher labels.
-
Key Contributions and Technical Innovations
- 1. Addressing Data Distribution Shifts via Online Distillation and Auxiliary Task-Based Learning
- Traditional KD assumes static data distributions, but online ranking systems experience rapid shifts in user preferences and content availability.
- Introduces a continuous teacher update framework where the teacher model is regularly retrained on fresh data, ensuring its guidance remains relevant to the student.
- Proposes auxiliary task-based distillation, where separate logits are used for hard (observed) and soft (teacher-generated) labels to prevent bias leakage from the teacher to the student.
- Demonstrates a 0.4% reduction in E(LTV) loss, showing improved learning without compounding teacher biases.
- 2. Efficient Teacher Model Selection for Practical Deployment
- Training and evaluating large teachers is costly and time-consuming (can take months).
- Empirical analysis provides heuristics for selecting optimal teacher sizes and objectives:
- 2× student size is recommended as a practical tradeoff between performance gains and computational cost.
- Excessive teacher size (>4× student) can widen the knowledge gap, making it harder for the student to learn effectively.
- Selective distillation of engagement and satisfaction objectives outperforms indiscriminate distillation, avoiding task conflicts.
- 3. Infrastructure Optimization for Cost-Amortized Multi-Student Learning
- In contrast to CV/NLP tasks where teachers are trained infrequently, ranking systems require continuous teacher updates, creating high computational overhead.
- Introduces a shared teacher labeling system, where multiple student models use precomputed teacher inferences stored in a columnar database (e.g., BigQuery, Apache Cassandra) to enable rapid retrieval with minimal latency.
- Ensures high teacher label consistency across students, preventing data sparsity and misalignment issues.
- This work significantly advances the practical application of knowledge distillation in large-scale online ranking systems, addressing real-world challenges that have been largely ignored in prior KD research. 🚀
3. Cross-Domain & Multi-Domain CTR
Efficient Transfer Learning Framework for Cross-Domain Click-Through Rate Prediction (E-CDCTR)
- Authors: Qi Liu, Xingyuan Tang, Jianqiang Huang, Xiangqian Yu, Haoran Jin, Jin Chen, Yuanhao Pu, Defu Lian, Tan Qu, Zhe Wang, Jia Cheng, Jun Lei
- The paper introduces E-CDCTR (Efficient Cross-Domain CTR Prediction), a tri-level asynchronous transfer learning framework designed to efficiently transfer knowledge from a natural content domain to an advertisement domain for Click-Through Rate (CTR) prediction. The framework mitigates data sparsity in advertising by leveraging long-term and short-term user behaviors from natural content while addressing catastrophic forgetting in daily model updates.
-
Key Technical Contributions
- 1. Problem: Cross-Domain CTR Transfer Learning Challenges
- Data Distribution Gap: Natural content has rich user interaction data, while ads suffer from data sparsity.
- Inefficient Pre-training: Training on massive natural data is computationally expensive.
- Catastrophic Forgetting: Daily CTR model updates erase long-term user interest signals.
- 2. E-CDCTR: A Tri-Level Asynchronous CTR Framework
- E-CDCTR consists of three hierarchical models, each updated at different frequencies to balance efficiency, adaptation, and knowledge retention:
- Tiny Pre-training Model (TPM) (Updated Monthly):
- Trains a small CTR model on six months of natural data using only basic features.
- Captures long-term user and item embeddings, reducing forgetting in daily updates.
- Stores three months of historical user/item embeddings for retrieval by downstream models.
- Complete Pre-training Model (CPM) (Updated Weekly):
- Trains a large CTR model with full features on one month of natural data.
- Provides knowledge-rich parameter initialization for the advertising CTR model.
- Advertising CTR Model (A-CTR) (Updated Daily):
- Fine-tunes on recent ad interactions using CPM’s initialized parameters.
- Retrieves historical user/item embeddings from TPM to retain long-term interests.
-
This multi-stage update strategy allows E-CDCTR to transfer long-term knowledge while adapting to fast-changing ad data.
- 3. Model Architecture & Training Strategy
- Lightweight CTR model trained on six months of natural content.
- Stores three-month rolling embeddings for users/items.
- Uses Self-Attention & Mean Pooling to compress embeddings before feeding into downstream models.
-
Key innovation: Preserves long-term user interests efficiently while avoiding high storage & latency costs.
- Complete Pre-training Model (CPM)
- Trained on one month of natural content with full feature interactions.
- Uses feature interaction layers & deep MLP for better personalization modeling.
- Provides richly trained parameters to initialize A-CTR, preventing cold start issues in ad modeling.
- Advertising CTR Model (A-CTR)
- Loads pre-trained parameters from CPM for faster training convergence.
- Fine-tuned on recent ad data while consuming historical embeddings from TPM.
- Excludes Batch Normalization (BN) parameters to avoid mismatched data distributions.
- This modular training avoids negative transfer while efficiently adapting models to new data.
MLoRA: Multi-Domain Low-Rank Adaptive Network for Click-Through Rate Prediction
- Authors: Zhiming Yang, Haining Gao, Dehong Gao, Luwei Yang, Libin Yang, Xiaoyan Cai, Wei Ning, Guannan Zhang
-
This paper introduces MLoRA (Multi-Domain Low-Rank Adaptive Network), a lightweight and scalable deep learning framework for multi-domain Click-Through Rate (CTR) prediction. MLoRA applies Low-Rank Adaptation (LoRA) modules to fine-tune CTR models across multiple domains with minimal additional parameters. Unlike traditional approaches that either train separate models per domain or mix all domains into a single model, MLoRA balances shared and domain-specific learning, improving efficiency and generalization.
-
Key Technical Contributions
- 1. Challenges in Multi-Domain CTR Prediction
- Data Sparsity: Some domains lack enough data to train effective CTR models.
- Domain Disparity: Data distributions differ significantly across domains.
- Parameter Explosion: Existing multi-domain models require many extra parameters for domain-specific adaptations.
- Inefficient Training: Conventional domain-specific fine-tuning often results in underfitting for sparse domains.
- 2. MLoRA: A LoRA-Based Multi-Domain CTR Framework
- LoRA Adaptation for Each Domain:
- Uses low-rank matrix decomposition (LoRA) to fine-tune domain-specific parameters with minimal overhead.
- Each domain has its own LoRA module while sharing a base CTR model across all domains.
- Reduces training inefficiency by learning both shared and domain-specific knowledge efficiently.
- Parameter Efficiency:
- Compared to full fine-tuning, MLoRA adds only 1.76% extra parameters while maintaining high performance.
- Scalability:
- Easily extends to new domains by adding new LoRA modules without retraining the entire model.
- LoRA Adaptation for Each Domain:
- 3. Core Methodology
- CTR Prediction as a Multi-Domain Learning Problem:
- Input consists of user features, item features, context features, and domain ID.
- The predicted CTR is computed as:
\(y_t = F_0(x) + L_t(x)\)
where:
- \(F_0(x)\): Shared base model trained across all domains.
- \(L_t(x)\): Domain-specific LoRA fine-tuning.
- LoRA-Based Parameter Decomposition:
- Instead of updating full-rank weight matrices \(W\), MLoRA **decomposes updates into two low-rank matrices:
\(\Delta W = B_t A_t\)
- \(B_t \in \mathbb{R}^{d_{\text{out}} \times r}\) and \(A_t \in \mathbb{R}^{r \times d_{\text{in}}}\) are trainable domain-specific matrices.
- Ensures efficient adaptation without overfitting.
- Instead of updating full-rank weight matrices \(W\), MLoRA **decomposes updates into two low-rank matrices:
\(\Delta W = B_t A_t\)
- Two-Phase Training:
- Pretraining: Train a shared backbone model on multi-domain data.
- Fine-Tuning: Train only the LoRA modules for each domain while keeping the shared model frozen.
- Dynamic Low-Rank Selection:
- MLoRA introduces a temperature coefficient \(\alpha\) to control the rank \(r\) dynamically: \(r = \max \left(\frac{d_{\text{out}}}{\alpha}, 1 \right)\)
- Prevents excessive parameter growth while maintaining flexibility across layers.
- CTR Prediction as a Multi-Domain Learning Problem:
- 4. Experimental Results
- Datasets:
- Taobao-10, Taobao-20, Taobao-30 (from Taobao APP)
- Amazon-6 (from Amazon product reviews)
- Movielens-gen (from MovieLens dataset, partitioned by gender)
- Baseline Comparisons:
- Single-domain models: MLP, WDL, PNN, AutoInt, NFM, DeepFM, xDeepFM, FiBiNET.
- Multi-domain models: STAR, MMOE, PLE.
- MLoRA outperforms all baselines across multiple datasets.
- Performance Gains (WAUC % Increase):
- Amazon-6: +0.83%
- Taobao-10: +0.49%
- Movielens-gen: +0.18%
- Overall Average Improvement: +0.50% WAUC
- Parameter Efficiency:
- Compared to fully fine-tuned models, MLoRA achieves similar or better performance with only a 1.76% parameter increase.
- Datasets:
- 5. Online A/B Testing on Alibaba
- Deployed on Alibaba.com, integrating 10 core recommendation domains.
- Trained on 13 billion samples (pretraining) and 3.2 billion samples (fine-tuning).
- Results from Live A/B Testing:
- +1.49% CTR increase.
- +3.37% order conversion rate increase.
- +2.71% increase in paid buyers.
- MLoRA is a breakthrough in efficient multi-domain CTR prediction, balancing shared and domain-specific learning.
- Minimal parameter growth (~1.76%) while achieving superior performance makes it highly scalable.
- Successfully deployed in Alibaba’s production system, proving its real-world effectiveness.
- A step forward in scalable, fine-tuned recommendation systems for large-scale e-commerce platforms.
4. Advanced/Unified Architectures (Embedding, GNN, Multi-Task, Search Synergy)
Unified Embedding-Based Personalized Retrieval in Etsy Search
-
Authors: Rishikesh Jha, Siddharth Subramaniyam, Ethan Benjamin, Thrivikrama Taula (Etsy Inc.)
- This paper presents UEPPR (Unified Embedding-Based Personalized Product Retrieval), a two-tower deep learning model for personalized e-commerce search on Etsy. The model integrates transformer-based embeddings, graph-based representations, and term-based embeddings to enhance retrieval quality, addressing both the vocabulary gap in search queries and user personalization at scale.
-
Key Technical Contributions
- 1. Unified Embedding-Based Retrieval Architecture
- Two-Tower Model:
- Product Encoder (P): Learns representations of Etsy products.
- Joint Query-User Encoder (Q): Encodes both query and user features.
- Similarity Function: Cosine similarity between P(p) and Q(q, u).
- Advantages:
- Enables offline indexing for fast serving.
- Personalized retrieval with minimal inference latency.
- Two-Tower Model:
- 2. Product Encoder: Multi-Feature Representation Learning
- Transformer-Based Embeddings:
- Fine-tuning DistilBERT and T5 Encoder did not improve offline performance.
- Pre-training with docT5Query approach: A T5-small model was trained to predict the most likely purchase query for a product.
- Graph-Based Embeddings:
- Constructed from query-product interaction graphs (year-long Etsy search logs).
- Queries sampled as neighbors in a bipartite graph improve retrieval.
- Parameter freezing in shared query-product encoders prevents overfitting.
- Transformer-Based Embeddings:
- 3. Personalized Query-User Encoding
- Lightweight Token Embeddings:
- Extracts n-grams (unigrams, bigrams, trigrams) from queries and product titles/tags.
- Uses categorical embeddings (product attributes, hierarchy categories).
- Location Encoder:
- Multi-scale encoding: Zip codes, latitude-longitude clusters (K-Means: k=50, 100, 500).
- 8% improvement in purchase recall for US users.
- User Interaction History:
- Uses search history, clicked shops, purchased items.
- Transformer-based attention weighting to personalize query-user embeddings.
- Lightweight Token Embeddings:
- 4. Hard Negative Sampling for Contrastive Learning
- Three Negative Sampling Strategies:
- Hard In-Batch Negatives: Uses positives from other queries as negatives.
- Uniform Corpus Negatives: Sampled randomly from the full product catalog.
- Dynamic Hard Negatives:
- Large-batch sampling selects the most similar non-relevant items.
- Prevents the model from overfitting on easy negatives. - Loss Function: Multi-part hinge loss with adaptive weighting of negative sources. - Results: 11% improvement in Recall@100 with dynamic hard negatives.
- Three Negative Sampling Strategies:
- 5. ANN-Based Product Boosting
- Enhances Retrieval by Adjusting for Product Quality:
- Traditional retrieval systems boost products based on quality scores (ratings, freshness, shop conversion rate).
- UEPPR extends this concept to ANN-based retrieval:
- Product vectors concatenated with numerical quality features.
- Query vectors augmented with learned quality weights.
- Black-box Bayesian optimization (using skopt) tunes these weights.
- Results: 5% boost in Recall@100 (head queries improved most).
- Enhances Retrieval by Adjusting for Product Quality:
- 6. Efficient Approximate Nearest Neighbor (ANN) Search
- Indexing & Serving Optimizations:
- Faiss-based ANN retrieval:
- Evaluated HNSW, IVFFlat, IVFPQFastScan.
- Optimal: IVFPQFastScan + re-ranking, achieving <20ms latency at P99.
- Query Cache Optimization:
- Includes session features (location, history) while maintaining cache efficiency.
- Black-Box Tuning for ANN Parameters:
- Google Vizier used to optimize ANN hyperparameters.
- Faiss-based ANN retrieval:
- Indexing & Serving Optimizations:
beeFormer: Bridging the Gap Between Semantic and Interaction Similarity in Recommender Systems
- Authors: Vojtěch Vančura, Pavel Kordík, Milan Straka
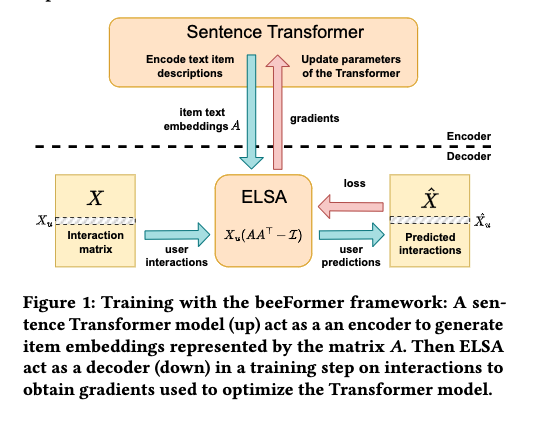
-
beeFormer is a novel training framework for sentence Transformer models that incorporates both textual and interaction data to improve recommendations, outperforming traditional collaborative filtering and semantic similarity-based methods, particularly in cold-start and zero-shot scenarios.
-
Key Technical Contributions
- 1. Bridging Semantic and Interaction Similarity for Recommendations
- Traditional sentence Transformers capture semantic similarity but ignore user interaction patterns.
- beeFormer adapts sentence Transformer training to optimize interaction-based similarity while retaining text-side information.
- The method is particularly effective in cold-start and zero-shot recommendation settings.
- 2. Transformer-Based Item Embeddings Using Interaction Data
- Uses a sentence Transformer model to generate item embeddings instead of traditional matrix factorization.
- The embedding space is optimized via interaction data, unlike standard sentence Transformers trained only for semantic similarity.
- 3. Training Strategy: Transformer + ELSA Integration
- The model combines sentence Transformer encoders with ELSA (Efficient Linear Shallow Autoencoder), which acts as a decoder.
- Training pipeline:
- Sentence Transformer encodes item descriptions → Generates item embedding matrix A.
- ELSA uses A to predict interactions, producing gradients for Transformer optimization.
-
Loss Function: $$ L = \text{norm}(X_u) - \text{norm}(X_u (AA^T - I)) ^2_F $$ - \(X_u\): User-item interaction matrix.
- \(AA^T\): Low-rank approximation of the item-to-item weight matrix.
- 4. Efficient Optimization for Large-Scale Datasets
- Challenge: Every training step requires generating embeddings for all items, making batch sizes impractically large.
- Solution:
- Gradient Checkpointing: Saves memory by recomputing intermediate activations on-the-fly.
- Gradient Accumulation: Splits backpropagation across smaller steps.
- Negative Sampling: Only encodes a sampled subset of items instead of the full catalog.
-5. Transfer Learning & Universal Recommender Model
- beeFormer enables cross-domain learning, showing strong knowledge transfer across datasets.
- Trained models outperform domain-specific baselines and generalize well to unseen items.
-
Training on multiple datasets improves performance, opening the door for universal, domain-agnostic recommendation models.
- This work pushes the boundary on Transformer-based recommendation models, making them more practical and scalable for real-world systems. 🚀
FLIP: Fine-grained Alignment between ID-based Models and Pretrained Language Models for CTR Prediction
- Authors: Hangyu Wang, Jianghao Lin, Xiangyang Li, Bo Chen, Chenxu Zhu, Ruiming Tang, Weinan Zhang, Yong Yu
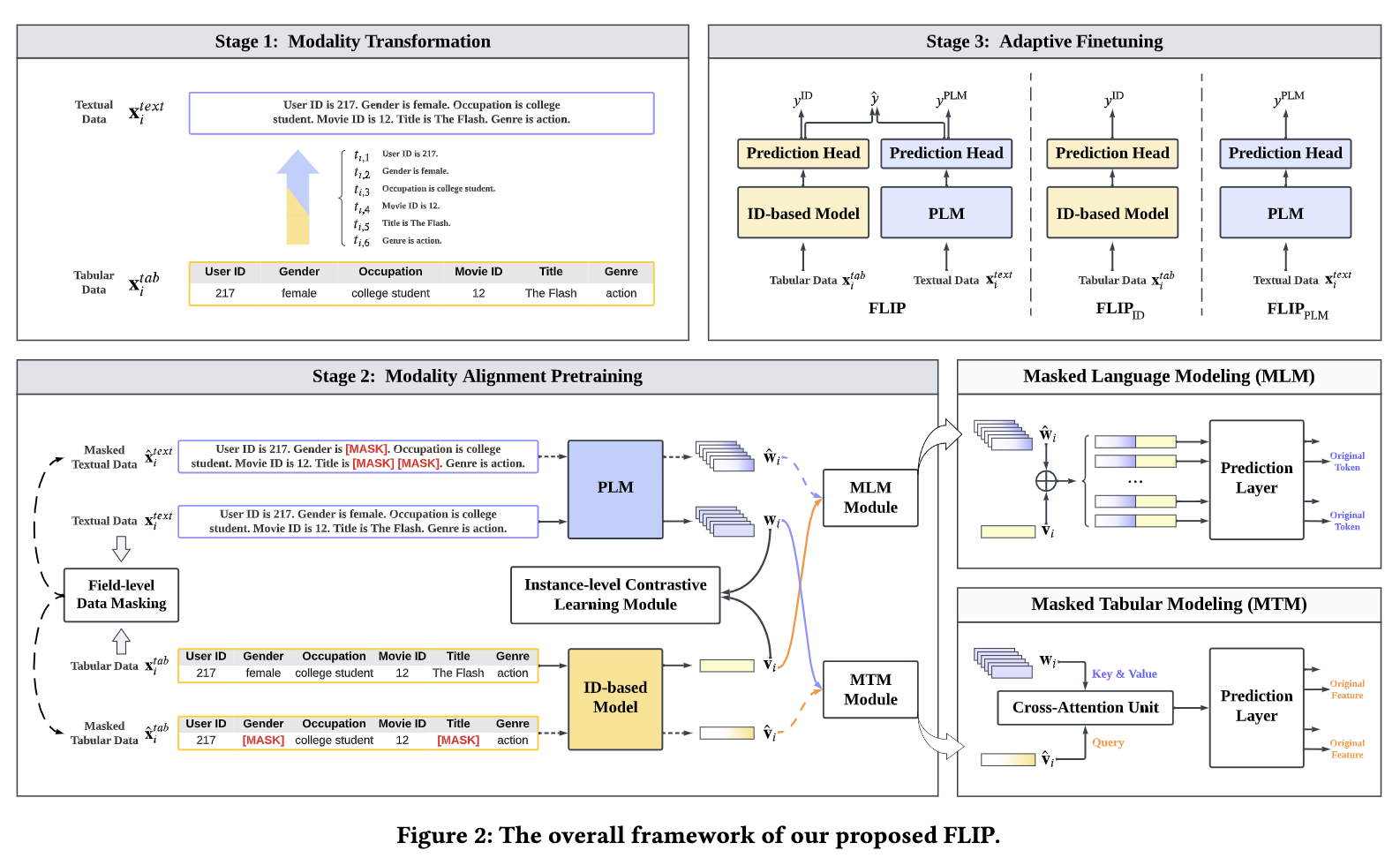
-
FLIP proposes a novel fine-grained feature-level alignment framework that integrates ID-based models with Pretrained Language Models (PLMs) for Click-Through Rate (CTR) prediction, achieving superior performance via jointly masked tabular/language modeling and adaptive fine-tuning.
-
Key Technical Contributions
- 1. Motivation: Bridging the Gap Between ID-based and PLM-based CTR Models
- Traditional ID-based models use one-hot encoded categorical data and capture collaborative signals via feature interaction but discard semantic information.
- PLMs, on the other hand, extract semantic meaning from textual data but struggle with field-wise collaborative signals and subtle text variations.
- FLIP aims to bridge these paradigms by aligning ID-based models and PLMs at a fine-grained feature level, extracting mutual information from both modalities.
- 2. Fine-Grained Feature-Level Alignment via Jointly Masked Modality Modeling
- FLIP introduces a jointly masked tabular/language modeling strategy that forces each modality to reconstruct missing features using the other, enabling fine-grained cross-modal interaction:
- Feature-level Masked Language Modeling (MLM)
- Text tokens corresponding to categorical features are masked and reconstructed using the PLM with guidance from tabular data.
- Feature-level Masked Tabular Modeling (MTM)
- Certain tabular ID features are masked and reconstructed using the ID-based model with help from the PLM.
- Instance-level Contrastive Learning (ICL)
- Ensures that the textual and tabular representations of the same instance remain closely aligned while being distinct from unrelated samples.
- 3. Field-level Data Masking Strategy for Robust Pretraining
- Unlike random token masking in PLMs (e.g., BERT), FLIP masks entire feature fields (e.g., “movie genre” → “[MASK]”) to encourage meaningful feature recovery.
- Prevents trivial token-level inference and enhances cross-modal knowledge transfer.
- 4. Adaptive Fine-Tuning Strategy for Joint Optimization
- Instead of training separate models, FLIP jointly fine-tunes the ID-based model and PLM, combining their outputs adaptively:
\(y = \sigma(\alpha \cdot \text{ID-based output} + (1-\alpha) \cdot \text{PLM output})\)- α is a learnable parameter, ensuring the model balances contributions from both paradigms dynamically.
- Instead of training separate models, FLIP jointly fine-tunes the ID-based model and PLM, combining their outputs adaptively:
- 5. Model-Agnostic Framework with Broad Compatibility
- FLIP is not restricted to a specific PLM or ID-based model and can work with various architectures such as:
- PLMs: TinyBERT, RoBERTa-Base, RoBERTa-Large
- ID-based Models: DCNv2, DeepFM, AutoInt
- This flexibility enables FLIP to be integrated into a variety of recommender systems.
- FLIP is not restricted to a specific PLM or ID-based model and can work with various architectures such as:
- FLIP establishes fine-grained cross-modal alignment between ID-based CTR models and PLMs, leveraging mutual information extraction through joint masked modeling and adaptive fine-tuning, significantly improving recommendation performance while remaining flexible and model-agnostic.
Recommendations and Results Organization in Netflix Search
-
Authors: Sudarshan Lamkhede, Christoph Kofler (Netflix Inc., USA)
-
This paper explores how Netflix Search integrates recommendation systems to augment search results, balancing exact matches with recommendations, while optimizing result organization to enhance user experience and engagement.
-
Key Technical Contributions
- 1. Problem Definition: Enhancing Search with Recommendations
- Traditional Search Limitation: Standard keyword-based retrieval only works for exact matches, failing for:
- Unavailable videos (due to licensing restrictions).
- Ambiguous searches (e.g., partial queries).
- Exploratory intent (users seeking suggestions).
- Solution: Integrate recommendations into search results to satisfy both “fetch” and “explore” intents.
- Traditional Search Limitation: Standard keyword-based retrieval only works for exact matches, failing for:
- 2. Search Intents and Query Facets in Netflix Search
- Users have different intents when searching, which fall on a spectrum:
- Fetch Intent: Looking for a specific title (e.g., typing “Stranger Things”).
- Explore Intent: Looking for recommendations based on a theme (e.g., searching for “sci-fi thrillers”).
- Query Facets (Categories of search terms):
- Exact matches (titles)
- Talent (actors, directors)
- Collections (genres, themes)
- Key Challenge: Infer user intent from short/ambiguous queries.
- Users have different intents when searching, which fall on a spectrum:
- 3. Merging Search with Recommendations
- Traditional Search vs. Search Recommendations:
- Search Matches: Exact keyword-based retrieval.
- Search Recommendations: Collaborative filtering and personalized ranking to surface related content.
- Why Include Recommendations?
- Handles unavailable content (suggesting similar content when a title isn’t in the catalog).
- Aids discovery (reduces “dead ends” in search).
- Supports vague queries (e.g., “Tom Cruise movies” returns a curated set).
- Encourages serendipitous discovery (e.g., searching “Bruce Lee” may surface Jackie Chan films).
- Traditional Search vs. Search Recommendations:
- 4. Organizing Search Results for Explainability and Usability
- Problem: A mix of exact matches and recommendations can be overwhelming.
- Solution: Grouping results into labeled categories (e.g., “Based on a Video Game”, “Goofy Movies”).
- Challenges:
- Grouping Mechanism: How to cluster similar content.
- Labeling Groups: Generating descriptive, user-friendly labels.
- Ranking within Groups: Prioritizing relevance and engagement potential.
- 5. Technical Challenges & Solutions
- (1) Handling Short and Ambiguous Queries
- Problem: Many Netflix searches are short and incomplete (due to typing constraints on TVs/remotes).
- Solution:
- Instant Search: Updates results with each keystroke.
- Behavioral Signals: Uses historical interactions to infer intent (e.g., if a user frequently watches horror, “conj…” likely refers to The Conjuring).
- (2) Low-Latency Search & Scalability
- Problem: Netflix search must scale to 200M+ users globally, requiring instant response times.
- Solution:
- Precomputed ranking models for faster retrieval.
- Efficient indexing of search and recommendation results.
- (3) Preventing Popularity Bias in Recommendations
- Problem: Collaborative filtering over-emphasizes popular titles, reducing result diversity.
- Solution:
- Personalized ranking models adjust weights dynamically.
- Diversity constraints ensure exposure to lesser-known titles.
- (1) Handling Short and Ambiguous Queries
- 6. Implementation: End-to-End Search Pipeline
- Retrieve Matches & Recommendations
- Keyword-based retrieval for exact matches.
- Collaborative filtering for recommended content.
- Rank the Results
- Machine learning model estimates contextual relevance.
- Organize into Groups
- Editorial constraints ensure structured presentation.
- Optimize for Device Constraints
- Different layouts for TVs, mobile, web.
- Retrieve Matches & Recommendations
- Netflix Search goes beyond exact retrieval by integrating recommendations, improving search intent modeling, and organizing results intuitively—making search a powerful discovery tool, not just a lookup function. 🚀
Augmenting Netflix Search with In-Session Adapted Recommendations
- Authors: Moumita Bhattacharya, Sudarshan Lamkhede (Netflix Research, USA)
- This paper introduces a real-time, in-session adaptive recommendation system for Netflix Search, leveraging deep learning-based ranking models that integrate long-term user preferences with short-term session signals, significantly improving pre-query recommendation relevance.
-
Key Technical Contributions
- 1. Problem Definition: The Need for In-Session Adaptation
- Traditional recommendation models rely on long-term user preferences derived from historical viewing habits.
- However, user intent changes dynamically—what a user searches for right now may be different from their usual preferences.
- Netflix Search serves two main intents:
- Fetch and Find Intent: Users search for specific known titles.
- Explore Intent: Users discover new content.
- Challenge: Pre-query recommendations should anticipate user intent before they start typing.
- Proposed Solution: An adaptive recommender that integrates long-term user preferences with real-time session signals.
- 2. In-Session Adaptive Recommendation System
- Core Idea: Use short-term browsing signals from the current session to generate real-time personalized rankings.
- Key Infrastructure Requirements:
- Just-In-Time (JIT) Server Calls: Recommendations must be generated live, avoiding stale, cached results.
- Client-Side & Server-Side Logging: Capturing member interactions in real time.
- Low Latency Model Inference: Must generate recommendations within milliseconds.
- 3. Machine Learning Approach: Multi-Task Learning for Personalized Ranking
- Stage 1: Feature Engineering for In-Session Signals
- Extract features from the current session, such as:
- Recent genres & titles interacted with.
- Navigation patterns before arriving at search.
- Browsing behavior on the homepage.
- Extract features from the current session, such as:
- Stage 1: Feature Engineering for In-Session Signals
- Stage 2: Personalized Ranking Model
- Jointly optimizes for both:
- Long-term user preferences (historical engagement).
- Short-term session-based interactions.
- Two-Step Architecture:
- Feature Engineering Model: Uses user interaction history to create structured features.
- Sequential Deep Learning Model: Learns representations from raw interaction sequences.
- Jointly optimizes for both:
- Stage 3: Sequential Modeling for Session Context
- Hypothesis: Raw interaction sequences may contain latent behavioral signals not captured in engineered features.
- Experimented Models:
- Recurrent Neural Networks (RNNs)
- Long Short-Term Memory (LSTM)
- Bi-Directional LSTM
- Transformers
- Best Approach: Transformer-based models outperform traditional RNNs in capturing session-based intent.
- 4. System Deployment Challenges & Engineering Solutions
- (1) Real-Time Computation Constraints
- Problem: Recommendations cannot be precomputed or cached.
- Solution: Optimize server request frequency to minimize infrastructure load.
- (2) Dynamic vs. Stable Recommendations
- Problem: Constant adaptation could make rankings too volatile, harming user experience.
- Solution: Apply stability constraints to prevent extreme ranking fluctuations.
- (3) Sparse Feature Space from Ongoing Sessions
- Problem: Many users generate very few session signals.
- Solution: Use data augmentation techniques to fill missing session features.
- (1) Real-Time Computation Constraints
- 5. Results & Impact
- Offline evaluation: The in-session adaptation model improves ranking accuracy by 6% over Netflix’s existing search model.
- Live deployment: Enhances pre-query recommendations, significantly reducing user search effort.
- Cold-Start Benefits: Helps users with insufficient historical data by using recent session interactions.
- 6. Future Directions
- Avoiding Popularity Bias: Prevent over-recommendation of highly ranked but generic content.
- Improving Session Awareness: Explore reinforcement learning to refine session-based adaptation.
- This paper presents a scalable real-time ranking model for Netflix Search, demonstrating how in-session signals can enhance search-based recommendations, balancing short-term user intent with long-term personalization. 🚀
Synergistic Signals: Exploiting Co-Engagement and Semantic Links via Graph Neural Networks
-
Authors: Zijie Huang, Baolin Li, Hafez Asgharzadeh, Anne Cocos, Lingyi Liu, Evan Cox, Colby Wise, Sudarshan Lamkhede
-
This paper introduces SemanticGNN, a novel graph neural network (GNN)-based approach that integrates co-engagement signals and semantic metadata into a large-scale knowledge graph, significantly improving entity similarity modeling in Netflix’s recommender system.
-
Key Technical Contributions
- 1. Problem Formulation: Entity Similarity with Hybrid Signals
- Traditional collaborative filtering (CF)-based methods rely on co-engagement data, which suffers from popularity bias and cold-start issues (poor performance for new/unpopular entities).
- The semantic attributes (genre, themes, maturity level) provide additional structured information but are underutilized in entity embeddings.
- Goal: Jointly leverage user co-engagement and semantic metadata to learn more robust and interpretable entity representations.
- 2. Graph Neural Network (GNN)-Based Approach: SemanticGNN
- SemanticGNN learns entity embeddings over a heterogeneous knowledge graph (KG) that integrates:
- Entities (e.g., movies, actors, games)
- Semantic concepts (e.g., genre, storyline, IP, maturity level)
- Entity-entity links (EEL) from co-engagement data
- Entity-concept links (ECL) representing semantic attributes
- Key Innovations:
- Relation-Aware Attention GNN: Handles imbalanced relation types (dense semantic edges, sparse co-engagement links).
- Knowledge Graph Pretraining: Uses TransE for semantic node embeddings, addressing limited feature availability for concept nodes.
- Scalable Multi-GPU Distributed Training: A novel HASP (Heterogeneity-Aware and Semantic-Preserving) subgraph partitioning scheme enables training over millions of nodes and billions of edges.
- SemanticGNN learns entity embeddings over a heterogeneous knowledge graph (KG) that integrates:
- 3. Relation-Aware Attention Mechanism
- Standard GNNs treat all edges equally, but in this setting:
- Co-engagement edges are sparse but strong indicators of similarity.
- Semantic edges are dense but contextually diverse.
- Solution:
- A scaled dot-product attention mechanism assigns learnable importance weights per relation type (e.g., has_genre, has_maturity_level).
- This allows the model to prioritize co-engagement edges where available, but fallback on semantic edges when necessary.
- Residual connections ensure stability and prevent noisy edges from dominating embeddings.
- Standard GNNs treat all edges equally, but in this setting:
- 4. Heterogeneity-Aware and Semantic-Preserving (HASP) Subgraph Generation
- Challenge: Netflix’s entity graph is too large for traditional GNN training (millions of nodes, billions of edges).
- HASP Solution:
- Entity nodes are partitioned while preserving dense co-engagement edges.
- Semantic nodes are duplicated across all subgraphs (since they are relatively few but crucial for preserving meaning).
- Enables efficient distributed training across multiple GPUs, with 50× speedup over naive full-graph training.
- 5. Empirical Results & Deployment
- Performance Improvement:
- 35% better on human-curated semantic similarity (HC-Sim) tasks.
- 21% better on co-engagement-based similarity (Co-Sim) tasks.
- Cold-Start & Inductive Generalization:
- Outperforms baselines for new/unpopular entities (crucial for recommendation diversity).
- Excels in the inductive setting: Learns meaningful representations even for unseen entities.
- Scalability:
- Trained on Netflix-scale data (~1M entities, billions of edges).
- Successfully deployed in production at Netflix.
- Performance Improvement:
- 6. Future Directions
- Hierarchical Semantic Structuring: Model fine-grained category hierarchies (e.g., “Person” → “Singer”).
- Dynamic Graph Updates: Incorporate temporal dynamics to handle newly released content.
- SemanticGNN revolutionizes similarity modeling in recommender systems by harmonizing collaborative and semantic signals in a scalable GNN framework, setting new industry benchmarks in cold-start recommendation, interpretability, and efficiency. 🚀
IntentRec: Predicting User Session Intent with Hierarchical Multi-Task Learning
-
Authors: Sejoon Oh, Moumita Bhattacharya, Yesu Feng, Sudarshan Lamkhede (Netflix)
-
IntentRec is a novel hierarchical multi-task learning (H-MTL) framework designed for sequential recommendation systems, which predicts user session intent and leverages it for next-item recommendation, improving accuracy by integrating short- and long-term user interests.
-
Key Contributions and Technical Innovations
- Novel Hierarchical Multi-Task Learning (H-MTL) for Intent and Item Predictions
- Unlike traditional multi-task learning (MTL), which treats intent prediction as an auxiliary task, IntentRec hierarchically integrates intent predictions into next-item recommendation, enhancing personalization.
- Uses Transformer-based encoders to process intent and item predictions separately, with intent features explicitly influencing item recommendations.
- Capturing Both Short-Term and Long-Term User Preferences
- Short-term preferences: Defined using a timestamp-based dynamic window rather than a fixed sequence length.
- Long-term preferences: Modeled using a Transformer encoder with multi-head self-attention.
- Personalized short-term interest aggregation prevents the model from treating all users uniformly, making recommendations more context-aware.
- Intent-Aware Feature Engineering with Implicit Signals
- Intent is inferred from user interaction metadata, including:
- Action type (e.g., “continue watching,” “discover new content”)
- Genre preference
- Movie/TV Show preference
- Time-since-release (e.g., recent vs old content)
- These features are embedded and transformed via projection layers and attention-based aggregation to construct a user intent embedding.
- Intent is inferred from user interaction metadata, including:
- Transformer-Based Architecture for Intent and Next-Item Prediction
- Two separate Transformer encoders:
- Intent Encoder: Captures session intent with causal masking.
- Item Encoder: Incorporates the intent embedding to predict the next-item interaction.
- Positional encoding via timestamps rather than fixed token positions, allowing for better handling of irregular time gaps in user interactions.
- Two separate Transformer encoders:
- Hierarchical Multi-Task Loss Function Optimization
- Loss function combines:
- Cross-entropy loss for next-item prediction (weighted by interaction duration).
- Binary cross-entropy for multi-label intent prediction (for features like multiple genres).
- Intent prediction loss weighted by a hyperparameter (λ) to balance intent and item predictions.
- Loss function combines:
Joint Modeling of Search and Recommendations Via an Unified Contextual Recommender (UniCoRn)
- Paper by Netflix, Authors: Moumita Bhattacharya, Vito Ostuni, Sudarshan Lamkhede
-
The paper presents UniCoRn, a unified deep learning model that jointly optimizes search and recommendation tasks, reducing system complexity while improving performance through shared contextual learning and personalized ranking.
-
Key Technical Contributions:
- Unification of Search and Recommendation Models**
- Traditional search and recommendation systems operate independently, leading to increased complexity and maintenance overhead.
- UniCoRn integrates multiple ranking tasks (Search, Video-to-Video Recommendations, and Pre-Query Recommendations) into a single deep learning model.
- This unified model leverages shared representations, enabling cross-task learning and reducing model proliferation.
- Context-Aware Joint Learning Framework**
- UniCoRn introduces a broader definition of context that encompasses multiple factors:
- User ID, query, country, source entity ID, and task type.
- Different tasks share a common probability-based engagement score as the learning target.
- Missing context imputation:
- For search tasks, missing entity context is set to null.
- For recommendation tasks, missing query context is inferred from entity display name tokens.
- This improves learning across different applications.
- UniCoRn introduces a broader definition of context that encompasses multiple factors:
- Deep Learning Model Architecture**
- Input Features:
- Context-specific features (e.g., query length, source entity embeddings).
- Target-dependent features (e.g., past engagement signals like clicks).
- Model Design:
- Uses residual connections and feature crossing for better learning across tasks.
- Trained with binary cross-entropy loss using the Adam optimizer.
- The model produces ranked lists optimized for different applications based on the given context.
- Input Features:
- Personalization Strategy for Search and Recommendations**
- Balancing Relevance vs. Personalization:
- Search traditionally prioritizes query relevance, while recommendations focus on user preferences.
- A fully personalized search experience may degrade relevance or introduce latency.
- Incremental Personalization Approach:
- Stage 1: User-cluster-based personalization (allows caching and efficiency).
- Stage 2: Personalization through auxiliary recommendation model outputs.
- Stage 3: End-to-end fine-tuned user and item representations incorporated into UniCoRn.
- Balancing Relevance vs. Personalization:
- Unification of Search and Recommendation Models**
- Performance Impact:
- Transitioning from a non-personalized to a fully personalized UniCoRn led to:
- 7% performance improvement for search.
- 10% improvement for recommendations.
- Transitioning from a non-personalized to a fully personalized UniCoRn led to:
- Technical Novelty & Impact
- Model unification reduces technical debt and simplifies system architecture for search and recommendations.
- Shared contextual learning improves generalization across ranking tasks.
- Efficient missing context imputation enables better data utilization across applications.
- Personalization enhances search quality without compromising latency constraints.
5. Transformers & Next-Item Prediction
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
- BERT4Rec is a method that adapts the BERT (Bidirectional Encoder Representations from Transformers) model for sequential recommendation tasks. The idea is to leverage the bidirectional context-capturing power of BERT for recommending items to users in an e-commerce or any other sequential recommendation scenario.
- How BERT4Rec works:
- Sequential Data Representation:
- Traditional recommendation systems often focus on user-item interaction without taking into account the sequence in which these interactions happen.
- BERT4Rec models user-item interactions as sequences, similar to how BERT models sentences in natural language processing.
- Masked Language Model Pre-training:
- BERT is pretrained using a masked language model (MLM) objective, where random tokens in a sentence are masked and the model is trained to predict these masked tokens.
- Similarly, in BERT4Rec, random items in a user’s interaction sequence are masked, and the model is trained to predict these masked items.
- This approach enables the model to learn bidirectional interactions, i.e., the context from both past and future interactions in a sequence.
- Capturing Bidirectional Context:
- Traditional methods like RNNs and LSTMs usually capture the context in a unidirectional manner (either forward or backward).
- However, in scenarios like e-commerce, both past and future interactions can influence a recommendation. For instance, if a user looked at item A, then item B, then item C, both items A and C could influence a recommendation after item B.
- BERT4Rec uses the Transformer architecture to capture both past and future interactions for every item in the sequence, providing a richer context for recommendations.
- Model Training:
- The input sequence of items is passed through BERT’s transformer layers.
- At the output, for the masked positions, the model predicts the items.
- The model is trained using a cross-entropy loss, comparing the predicted items with the actual masked items.
- Recommendation:
- Once trained, for a given user’s sequence of interactions, BERT4Rec can be used to predict the next likely item(s) the user might be interested in.
- The model’s output can be further refined with top-k sampling to provide the top k recommendations.
- Advantages:
- BERT4Rec captures complex and non-linear patterns in user behavior.
- The model is particularly suited for scenarios where the sequence of interactions provides valuable context for making recommendations, such as e-commerce, music, and video streaming platforms.
- Sequential Data Representation:
- In essence, BERT4Rec adapts the powerful bidirectional context modeling capability of BERT for sequential recommendation tasks, offering improvements over traditional unidirectional models.
Transformers4Rec: Bridging the Gap between NLP and Sequential / Session-Based Recommendation
- Transformers4Rec provides an open-source library that extends Hugging Face’s Transformers to sequential and session-based recommendation, providing a modular and configurable framework for integrating Transformer-based architectures into recommendation pipelines.
-
Key Contributions and Technical Details
- Bridging NLP and Recommendation Systems
- Recommender systems often rely on sequential modeling, akin to NLP tasks where word sequences are processed. This work systematically adapts Transformer-based NLP models to the recommendation domain.
- The library enables researchers and practitioners to leverage state-of-the-art (SOTA) NLP techniques, including different pre-training approaches (Causal Language Modeling, Masked Language Modeling, etc.), side information integration, and optimization strategies tailored for RecSys.
- Comprehensive Empirical Analysis of Transformer Architectures
- Evaluates multiple Transformer variants (GPT-2, Transformer-XL, XLNet, Electra) under different training regimes for session-based recommendation.
- Finds that XLNet trained with Replacement Token Detection (RTD) consistently outperforms other models across multiple datasets.
- Demonstrates that Transformer-based methods outperform traditional session-based recommendation models on e-commerce datasets but show comparable performance on news recommendation tasks.
- Transformer-based Meta-Architecture for Recommendation
- Feature Processing Module:
- Handles categorical and numerical input features.
- Implements feature normalization and embeddings for sparse categorical features.
- Sequence Masking Module:
- Supports multiple training paradigms (e.g., Causal LM, Masked LM, and Permutation LM).
- Enables training with different masking strategies tailored to recommendation tasks.
- Sequence Processing Module:
- Stacked Transformer blocks handle sequential dependencies.
- Configurable Transformer architectures (GPT-2, XLNet, etc.), enabling comparison across multiple models.
- Outputs sequence embeddings for each interaction in a session.
- Prediction Head Module:
- Implements tying embeddings between input and output layers to reduce parameters and enhance generalization.
- Supports classification, regression, and item prediction tasks.
- Uses softmax over item embeddings for ranking candidates in recommendation.
- Feature Processing Module:
- Integration of Side Information for Enhanced Recommendations
- Incorporates user and item context features to improve accuracy.
- Two aggregation functions: concatenation merge and element-wise merge.
- Demonstrates that including side information significantly boosts performance, especially in sparse data scenarios.
- Regularization and Optimization Strategies
- Implements techniques like Dropout, Weight Decay, Softmax Temperature Scaling, Layer Normalization, Stochastic Shared Embeddings, and Label Smoothing.
- Supports cross-entropy and pairwise losses, allowing flexibility in training objectives.
- Enables multi-task learning and hybrid models by integrating multiple sequence inputs.