Recommendation Systems • Introduction
- Overview
- Funnel Architecture
- References
Overview
- Recommendation Systems (RecSys) are pivotal in Machine Learning, forming an essential component of product offerings from major tech companies such as Google, Facebook, Amazon, Netflix and several other online services/platforms.
- These systems are integral across industries, from food delivery to e-commerce, driven by the recommendations generated by these models. They not only foster business growth but also enhance user experience by helping individuals discover items they may not have encountered otherwise.
- The following figure illustrates results from pilot customer A/B experiments, showcasing improvements in business metrics (such as revenue, conversions, and click-through rates) compared to previous recommendation systems:

- Recommendation systems utilize machine learning models to determine user preferences based on their past history or by analyzing the preferences of similar users.
-
These systems typically involve documents (entities a system recommends, like movies or videos), queries (information needed to make recommendations, such as user data or location), and embeddings (mappings of queries or documents to a vector space called embedding space).
-
Below is a common architecture for a recommendation system model:

- Candidate Generation: The process begins here, starting with a vast corpus and generating a smaller subset of candidates.
- For example, Netflix has thousands of movies but must decide which ones to display on your homepage.
- Candidate generation evaluates queries at high speed over a large corpus. Models may provide multiple candidate generators, each producing different subsets.
- Scoring: In this step, the model ranks the candidates to select a smaller, more refined set of documents.
- Operating on a smaller subset of documents allows for higher precision in ranking.
- Re-ranking: This final step refines the recommendations.
- For example, if a Netflix user explicitly dislikes certain movies, those will be deprioritized or removed from the main page.
- Candidate Generation: The process begins here, starting with a vast corpus and generating a smaller subset of candidates.
- Many large-scale recommendation systems implement these processes in two main stages: retrieval and ranking.
Funnel Architecture
- Funnel architectures in recommendation systems are designed to progressively refine a vast pool of potential candidates into a smaller, more relevant set of recommendations through multiple stages. These stages are commonly referred to as retrieval and ranking in a 2-Stage (2x2 framework; illustrated below in Eugene Yan’s 2-Stage (2x2) Model of a Recommender System), and as retrieval, filtering, scoring, and ranking (or ordering) in a 4-Stage (2x4 framework; illustrated below in Nvidia’s 4-Stage (2x4) Model of a Recommender System).
- Indeed.com offers a visual overview of their funnel architecture in the slide below. Note that the numbers are approximate and for illustrative purposes.

2-Stage (2x2) Recommender Systems
-
The 2-Stage (2x2) model involves two main stages:
- Retrieval: Quickly narrows down the vast candidate pool (e.g., millions of items) to a smaller subset using scalable models such as matrix factorization or two-tower architectures.
- Ranking: Applies sophisticated models incorporating richer feature sets, such as user context or item-specific details, to assign relevance scores and generate a personalized, ranked list.
4-Stage (2x4) Recommender Systems
-
The 4-Stage (2x4) model extends the 2x2 framework with two intermediary stages for greater precision and flexibility:
- Retrieval: Identifies an initial set of candidates, emphasizing efficiency and broad coverage.
- Filtering: Applies business rules to exclude ineligible or irrelevant items (e.g., out-of-stock products or regionally restricted content).
- Scoring: Uses advanced algorithms, such as deep learning models, to predict interaction likelihood by analyzing user-item interactions and contextual features.
- Ranking (or Ordering): Finalizes the recommendation list, balancing relevance, diversity, novelty, and business goals.
-
These frameworks allow recommender systems to balance computational efficiency in early stages with precision and personalization in later stages. They are widely used in large-scale systems like Netflix, YouTube, and Amazon.
Visualization of 2-Stage and 4-Stage Recommender Systems
Eugene Yan’s 2-Stage (2x2) Model of a Recommender System
- Eugene Yan’s 2x2 model (source) identifies two main dimensions within discovery systems:
- Environment: Offline vs. Online.
- Process: Candidate Retrieval vs. Ranking.
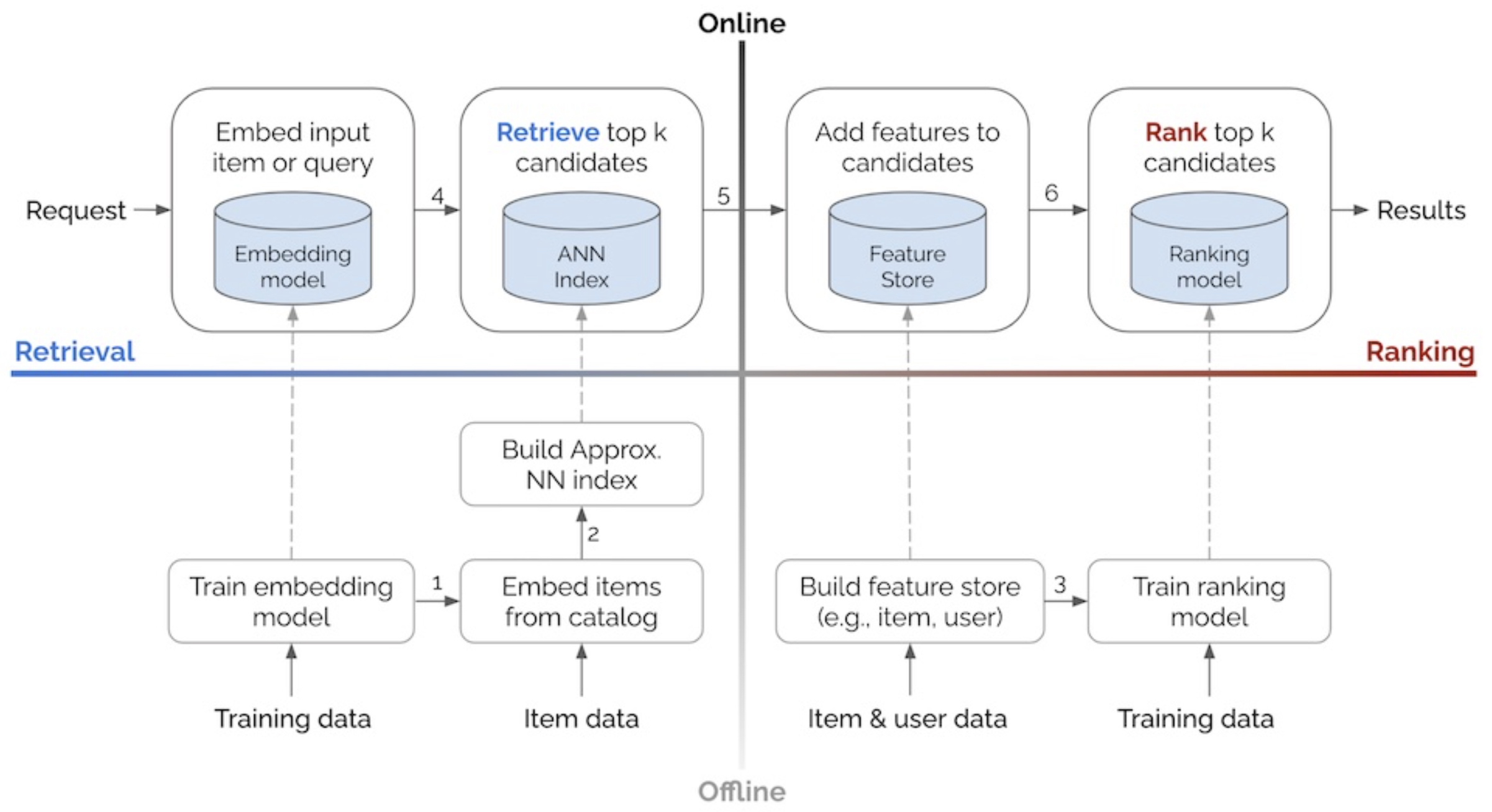
- The offline stage flows bottom-up, producing the necessary artifacts for the online environment, while the online stage processes requests left-to-right, following retrieval and ranking steps to return a final set of recommendations or search results.
Offline Environment
- In the offline environment, batch processes handle tasks such as model training, creating embeddings for catalog items, and developing structures like approximate nearest neighbors (ANN) indices or knowledge graphs to identify item similarity. The offline stage may also involve loading item and user data into a feature store, which helps augment input data during ranking.
Online Environment
-
The online environment serves individual user requests in real-time, utilizing artifacts generated offline (e.g., ANN indices, knowledge graphs, models). Here, input items or queries are transformed into embeddings, followed by two main steps:
- Candidate Retrieval: Quickly narrows down millions of items to a more manageable set of candidates, trading precision for speed.
- Ranking: Ranks the reduced set of items by relevance. This stage enables the inclusion of additional features such as item and user data or contextual information, which are computationally intensive but feasible due to the smaller candidate set.
Nvidia’s 4-Stage (2x4) Model of a Recommender System
-
Expanding on the 2x2 model, the 4-stage (2x4) recommender system (below; source) adds additional stages to address more nuanced requirements commonly encountered in real-world applications. This approach involves the following four stages:
- Retrieval
- Filtering
- Scoring
- Ordering
-
Each stage has a unique role in refining and tailoring recommendations to meet both user and business requirements.
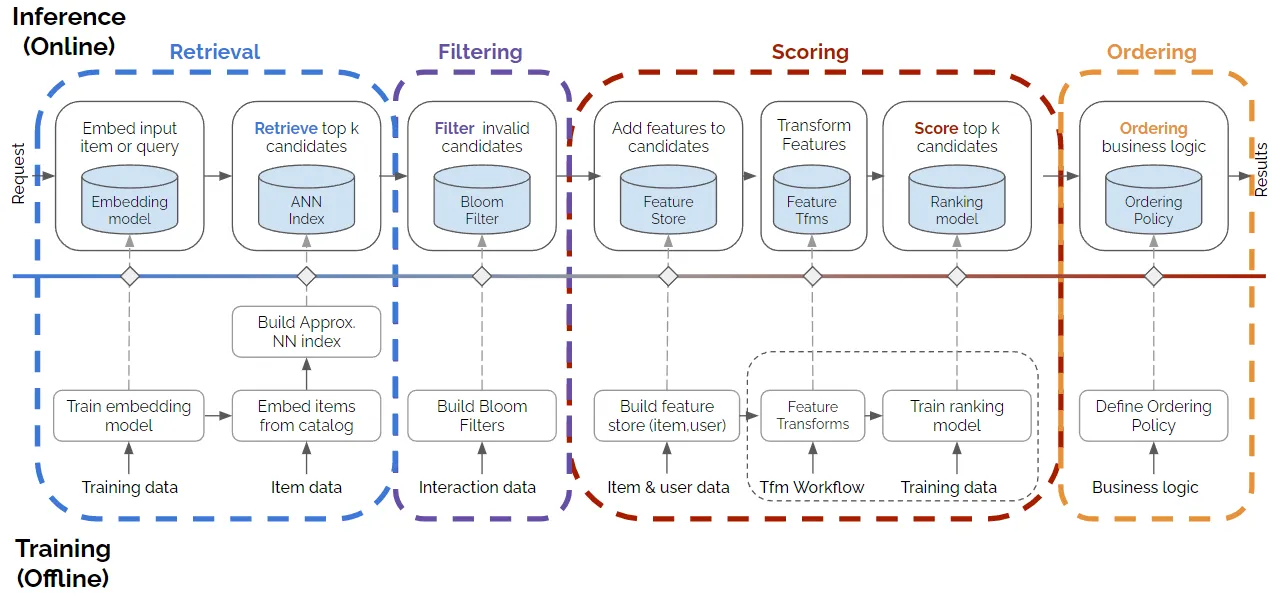
Retrieval
- The retrieval stage serves to generate a pool of candidates, using methods such as matrix factorization, two-tower models, or ANN. Retrieval is computationally efficient, ensuring the model can quickly handle a large number of items and narrow them down to a set of potential candidates for scoring.
Filtering
- Following retrieval, the filtering stage applies business rules to refine the candidate pool further. Items may be excluded if they are out of stock, inappropriate for the user, or unavailable due to regional restrictions. Filtering ensures that the system does not rely on retrieval or scoring models to handle business-specific logic, allowing for more precise control over item eligibility.
Scoring
- The scoring stage involves a detailed analysis of the remaining candidates, using models that factor in additional features (e.g., user data, contextual information) to predict user interest. Scoring can leverage sophisticated models, such as deep learning architectures, to assign interaction likelihoods (e.g., click, purchase probability) to each candidate.
Ordering
- In the final stage, the system arranges items into an ordered list for the user. Although scoring assigns relevance scores to each item, the ordering stage allows further adjustments to ensure a diverse mix of recommendations or to meet additional criteria like novelty. This stage addresses the challenge of filter bubbles by promoting item diversity and enhancing user exploration.
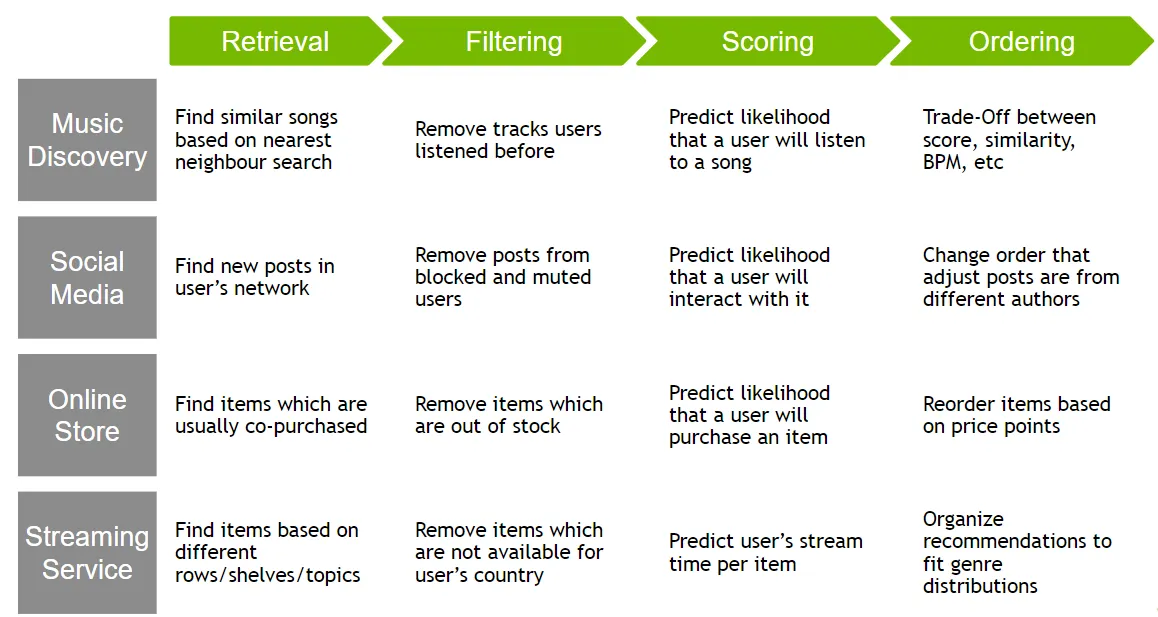
Examples of the 4-Stage System in Practice
- Real-world examples (source) demonstrate how this four-stage architecture supports diverse recommendation tasks. In practice, this design pattern has been widely adopted to build scalable, efficient, and responsive recommendation systems, meeting complex needs across various domains.
References
- Google’s Recommendation Systems Developer Course
- Coursera: Music Recommender System Project
- Coursera: DeepLearning.AI’s specialization.
- Recommender system from learned embeddings
- Google’s Recommendation Systems Developer Crash Course: Embeddings Video Lecture
- ALS introduction by Sophie Wats
- Matrix Factorization
- Recommendation System for E-commerce using Alternating Least Squares (ALS) on Apache Spark