Recommendation Systems • Re-ranking
Overview
-
In the final phase of a recommendation system, the system has the capability to re-rank candidates by taking into account additional criteria or constraints that were not initially considered. This re-ranking stage allows the system to assess factors beyond the initial scoring, such as the diversity of items within the recommended set. For instance, the system may choose to penalize items that are too similar to one another, thereby fostering a more varied set of recommendations.
-
Re-ranking is widely utilized in recommender systems to enhance the quality of recommendations by modifying the sequence in which items are presented to users. There are several methodologies to approach re-ranking, such as through the use of filters, altering the score returned by the ranking algorithm, or by rearranging the recommended items.
-
One method involves utilizing filters to exclude certain candidates from the pool of recommendations. For example, in a video recommendation system, a separate model could be trained to identify clickbait videos, which are subsequently filtered out from the list of initial candidates. Another approach is to manually adjust the scores produced by the ranking algorithm. For instance, a video recommender might modify scores based on the video’s age or duration to prioritize newer or shorter content. These adjustments can be made during or after the initial scoring phase.
-
Both re-ranking strategies enhance the diversity and quality of recommendations, though their efficacy must be measured using appropriate metrics such as precision, recall, or diversity indices. Various re-ranking algorithms and methods are available, including content-based filtering, collaborative filtering, and hybrid techniques that combine multiple approaches. Typically, these strategies operate based on features stored in a database.
Freshness
- An effective method of re-ranking is by promoting the “freshness” of items. This technique emphasizes presenting more recent items at the top of recommendation lists, which is particularly beneficial in scenarios where users prioritize up-to-date information, such as news. Freshness-based re-ranking can be executed using various algorithms, including Bayesian Personalized Ranking (BPR) or Matrix Factorization (MF), and may be supplemented by other techniques, such as content-based filtering, to further diversify recommendations.
Diversity
-
Another significant approach to re-ranking is promoting diversity within recommendations. Users often have a range of preferences, and simply displaying the most popular or highly-rated items may result in a lack of variety. Algorithms aimed at increasing diversity can incorporate techniques such as clustering, wherein similar items are grouped and presented in a balanced manner.
-
If the system consistently recommends items that closely match the query embedding, it may result in a homogenous selection, which could negatively impact the user experience. For instance, if a video platform like YouTube only recommends videos closely related to a user’s current viewing, such as exclusively recommending owl videos, the user may become disengaged.
-
To counter this issue, several viable methods to increase diversity include:
- Training multiple candidate generators based on different sources.
- Training multiple rankers utilizing different objective functions.
- Re-ranking items based on genre or metadata to ensure variety.
Fairness
-
Fairness is an essential element in recommender systems, which must strive to offer equitable opportunities to all users, irrespective of characteristics such as age, gender, or geographical location. Re-ranking algorithms that prioritize fairness may consider factors such as equitable representation across different categories or user demographics, ensuring a balanced coverage of the item space.
-
Fairness also ensures that the model does not inadvertently incorporate biases present in the training data. Methods to promote fairness in re-ranking include:
- Incorporating diverse perspectives during the design and development phases.
- Training machine learning models on comprehensive datasets and augmenting them with additional data when certain categories are underrepresented.
- Monitoring metrics (e.g., accuracy and absolute error) across various demographics to detect biases.
- Developing separate models for underserved groups.
Personalization
- Personalization is another critical component of re-ranking. By analyzing a user’s specific preferences, interests, and behaviors, recommendation systems can deliver highly personalized suggestions that are more relevant and engaging. Personalization-based re-ranking algorithms typically leverage machine learning techniques, such as collaborative filtering or reinforcement learning, to model user preferences and dynamically adjust recommendations.
- Methods for incorporating personalization into re-ranking include:
- Collaborative Filtering: This method uses a user’s historical interactions to recommend items similar to those the user has previously liked. It is frequently employed in re-ranking to tailor recommendations based on individual preferences.
- Content-Based Filtering: This technique relies on the features and attributes of items to recommend content similar to those with which the user has interacted. It can personalize recommendations based on user preferences.
- Contextual Bandits: As a form of reinforcement learning, contextual bandits are used for real-time learning and decision-making. They personalize recommendations by accounting for the user’s context, such as time of day, location, or device.
- Hybrid Recommender Systems: These systems integrate multiple recommendation approaches to enhance personalization. They can combine the strengths of various techniques to deliver more precise and personalized recommendations.
Practical Applications
- Various companies employ these techniques to personalize user experiences. For example:
- Netflix employs a hybrid recommender system that blends collaborative and content-based filtering to offer personalized suggestions based on a user’s viewing history and preferences.
- Amazon utilizes a combination of collaborative filtering and contextual bandits to tailor recommendations based on a user’s previous interactions and current context, such as location or device.
- Spotify combines collaborative filtering and content-based filtering to customize music recommendations based on a user’s listening history and preferences.
- Google uses a mix of collaborative filtering and contextual bandits to personalize search results, considering both previous search history and the user’s current context, such as location and device.
Patterns for Personalizations from Eugene Yan
- Eugene Yan has introduced a few patterns taken from research commonly seen in personalization.
- Bandits – continuously learn via exploration:
- Multi-armed bandits and contextual bandits are approaches that aim to balance exploration and exploitation in decision-making. Multi-armed bandits explore different actions to learn their potential rewards and exploit the best action for maximizing overall reward. Contextual bandits go further by considering the context before each action, incorporating information about the customer and environment to make informed decisions.
- Bandits offer advantages over batch machine learning and A/B testing methods, as they minimize regret by continuously learning and adapting recommendations without the need for extensive data collection or waiting for test results. They can provide better performance in situations with limited data or when dealing with long-tail or cold-start scenarios, where batch recommenders may favor popular items over potentially relevant but lesser-known options.
- Bandit-based approaches allow for continuous exploration and learning, enabling personalized and adaptive decision-making that maximizes the user experience.
- Netflix: Netflix utilizes contextual bandits to personalize images for shows. The bandit algorithm selects images for each show and observes how many minutes users spend watching the show after being presented with the chosen image. The bandit algorithm takes into account various contextual factors such as user attributes (titles played, genres, country, language preferences), day of the week, and time of day.
- For offline evaluation, Netflix employs a technique called replay. They compare the bandit’s predicted image for each user-show pair with the randomly assigned images shown during the exploration phase. If there is a match, it is considered a predicted-random match and can be used for evaluation. The main evaluation metric is the number of quality plays (user watching the show) divided by the number of impressions (images recommended).
- Replay allows for unbiased evaluation by considering the probability of each image shown during exploration. This helps control for biases in image display rates. However, replay requires a significant amount of data, and if there are few matches between predicted and random data, there can be high variance in evaluation metrics. Techniques like doubly robust estimation can be employed to mitigate this issue.
- DoorDash: Doordash implemented a contextual bandit approach for cuisine recommendations, incorporating multiple geolocation levels. The bandit algorithm explores by suggesting new cuisine types to customers to assess their interest and exploits by recommending their most preferred cuisines.
- To capture the average cuisine preference in each location, Doordash introduced multiple levels in their bandit system, such as district, submarket, market, and region. These geolocation levels provide prior knowledge, allowing the bandit to represent cold-start customers based on the location’s prior preferences until sufficient data is collected for personalized recommendations.
- The geolocation priors enable Doordash to strike a balance between a customer’s existing preferences and the popular cuisines specific to each location. For example, if a sushi-lover orders food from a new geolocation, they may be exposed to the local hot favorite (e.g., fried chicken), combining their preferences with the regional popularity.
- Spotify: Spotify utilizes contextual bandits to determine the most effective recommendation explanations, known as “recsplanations,” for its users. The challenge is to personalize music recommendations while considering the associated explanation, with user engagement as the reward. Contextual features, such as user region, device platform, listening history, and more, are taken into account.
- Initially, logistic regression was employed to predict user engagement based on a recsplanation, incorporating data about the recommendation, explanation, and user context. However, regardless of the user context, logistic regression resulted in the same recsplanation that maximized the reward.
- To overcome this limitation, higher-order interactions between the recommendation, explanation, and user context were introduced. This involved embedding these variables and incorporating inner products on the embeddings, representing second-order interactions. The second-order interactions were combined with first-order variables using a weighted sum, creating a second-order factorization machine. Spotify explored both second and third-order factorization machines for their model.
- To train the model, sample reweighting was implemented to account for the non-uniform probability of recommendations in production, as they did not have access to uniform random samples like in the Netflix example. During offline evaluation, the third-order factorization machine outperformed other models. In online evaluation through A/B testing, both the second and third-order factorization machines performed better than logistic regression and the baseline. However, there was no significant difference between the second and third-order models.
- Embedding+MLP: Learning embeddings; pooling them:
- Deep learning has become increasingly popular in recommendation and search systems. One common approach is the embedding + multilayer perceptron (MLP) paradigm. In this paradigm, sparse input features like items, customers, and context are transformed into fixed-size embedding vectors. Variable-length features, such as sequences of user historical behavior, are compressed into fixed-length vectors using techniques like mean pooling. These embeddings and features are then fed into fully connected layers, and the recommendation task is typically treated as a classification problem.
- Various companies have adopted this paradigm in different ways. For example, TripAdvisor uses it to recommend personalized experiences (tours). They train general-purpose item embeddings using StarSpace and fine-tune them for the specific recommendation task. They also apply exponential recency weighted average to compress varying-length browsing histories into fixed-length vectors. The model includes ReLU layers and a final softmax layer for predicting the probability of each experience.
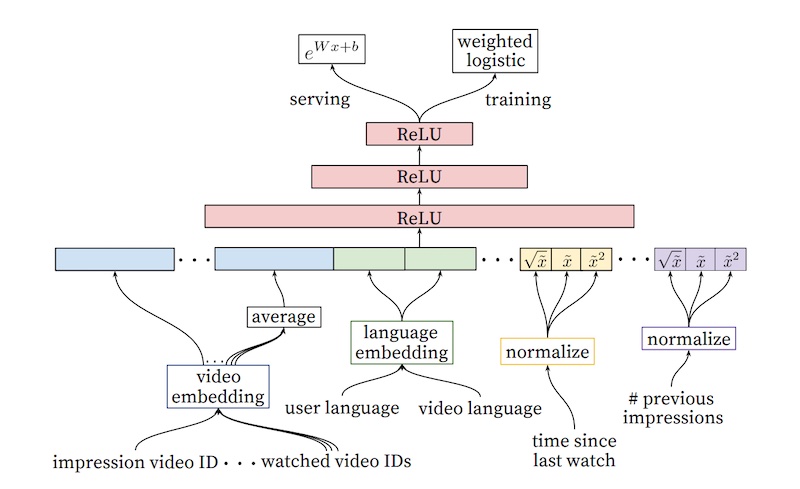
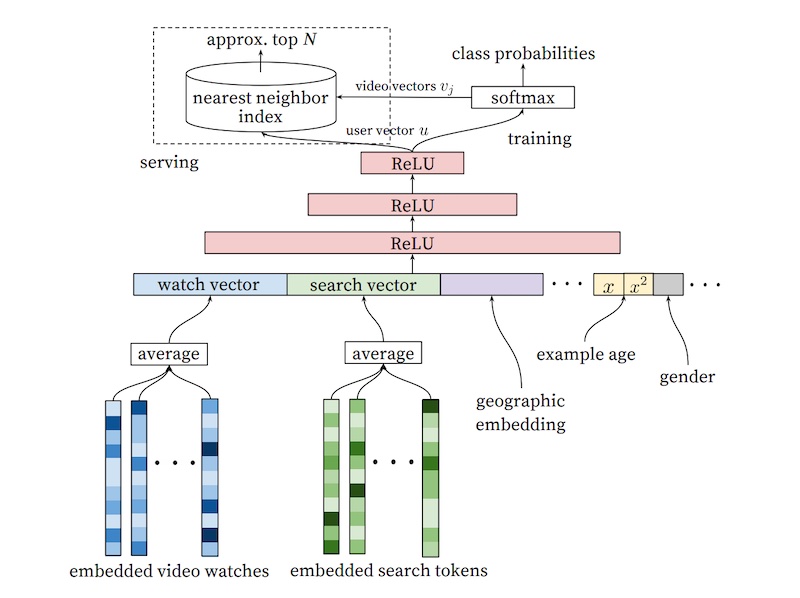
- YouTube applies a similar approach to video recommendations but splits the process into candidate generation and ranking stages. In candidate generation, user interests are represented using past searches and watches, and mean pooling is applied to obtain fixed-size vectors. Several fully connected ReLU layers and a softmax layer are used to predict the probability of each video being watched. Negative sampling is employed to train the model efficiently. Approximate nearest neighbors are used during serving to find video candidates for each user embedding.
- For ranking, video embeddings are averaged and concatenated with other features, including the video candidate from the candidate generation step. ReLU layers and a sigmoid layer weighted by observed watch time are used to predict the probability of each video being watched. The output is a list of candidates and their predicted watch time, which is then used for ranking.
- Alibaba’s Deep Interest Network addresses the challenge of compressing variable-length behaviors into fixed-length vectors by introducing an attention layer. This allows the model to learn different representations of the user’s interests based on the candidate ad. The attention layer weighs historical user behavior, enabling the model to assign importance to different events. The network is an extension of a base model inspired by YouTube’s recommender. In offline and online evaluations, the deep interest network with the attention layer outperformed the base model in terms of AUC, click-through rate, and revenue per mille.
- These examples highlight the application of deep learning in recommendation and search systems, demonstrating the use of embeddings, MLPs, pooling techniques, attention layers, and specific adaptations for different domains.
- Sequential: Learning about item order in a sequence
- An alternative to pooling variable-length user behavior events is to use sequential models like recurrent neural networks (RNNs). However, RNNs have the limitation of sequential processing, where each event in the sequence depends on the hidden state of the previous event. The Transformer, a breakthrough model in natural language processing, introduced positional encodings to overcome this limitation and allow parallel processing of events.
- In the context of session-level recommendations, Telefonica researchers explored the use of Gated Recurrent Units (GRUs). Since many real-world recommendation scenarios only have access to short session-level data, they aimed to model user sessions to provide relevant recommendations. Their model consisted of a single GRU layer followed by multiple fully connected layers. The final layer used softmax to predict the likelihood of each item in the catalog being the next item in the session. One-hot encoding was used to represent the input, and the GRU learned the temporal relationships between events in user behavioral sequences. The GRU-based recommender outperformed item-KNN in offline evaluations.
- Building on their previous work on attention models, Alibaba proposed the Behavioral Sequence Transformer (BST) for modeling variable-length user behavior in the ranking stage of recommendations. BST utilized the Transformer encoder block. Input items were represented by embeddings, and the behavioral sequence included the target item as part of the input. BST aimed to predict the probability of clicking an item given the user’s historical behavior. Due to the computational cost, only a subset of features was included in the behavioral sequence, and the target item was marked with a specific position for the model to learn its significance.
- These approaches demonstrate the use of sequential models like RNNs and Transformers in capturing the temporal dependencies in user behavior. The GRU-based recommender and the BST provide insights into effectively modeling variable-length user behavior for personalized recommendations.
- Graph: Learning from a user or item’s neighbors
- Graph-based representations offer an alternative approach to modeling user behavior by capturing the relationships between users and items as nodes in a graph. This graph can provide valuable insights into user interests and the structural information of the user’s neighborhood. Various techniques exist for learning on graphs, such as DeepWalk, Node2Vec, and graph convolutional networks (GCNs).
- GCNs, specifically, have been applied by Uber in the context of food recommendations. They construct two bipartite graphs: one connecting users and dishes, and the other connecting users and restaurants. The edges in these graphs are weighted based on factors like the number of times a user has ordered a dish and the user’s rating for the dish. GraphSAGE, a GCN variant, is employed, where aggregation functions like mean or max pooling are used after projection. Sampling techniques are also employed to limit the number of nodes considered, reducing computational requirements.
- In this approach, dishes are represented using embeddings derived from descriptions and images, while restaurants are represented by features related to their menus and cuisine offerings. Since users, dishes, and restaurants have different sets of features, the node embeddings for each type differ in dimensions. To address this, a projection layer is utilized to project all node embeddings to a consistent dimension.
- Graph-based approaches like GCNs enable the incorporation of rich structural information and collaborative filtering in recommendation systems, enhancing the understanding of user preferences and improving the quality of recommendations
- User embeddings: Learning a model of the user
- In addition to representing user behavior as sequences or graphs, user embeddings can also be learned directly to capture user preferences and characteristics. Airbnb and Alibaba employ user embeddings in their recommendation systems, while Tencent focuses on user lookalike modeling for long-tail content recommendations.
- Airbnb addresses data sparsity by learning user-type embeddings based on various user attributes such as location, device type, language settings, and past booking behavior. User-type embeddings are learned using a skip-gram model, interleaved with session-level behavioral data. The cosine similarity between user-type embeddings and candidate listings is computed and used as a feature for search ranking.
- Alibaba incorporates user embeddings in the ranking stage by training a fully connected model that takes user behavior history, user features, and candidate items as input. User embeddings are represented by the hidden vector from the penultimate layer and concatenated with candidate item embeddings. Attention layers are then applied to capture personalized user-item interactions and predict the click probability for each candidate item.
- Tencent addresses the lack of behavioral data on long-tail content by developing a user-lookalike model. They identify users who have similar behavior patterns and recommend long-tail content that their lookalikes have viewed. This approach helps diversify recommendations and promote relevant but less popular content.
- Overall, user embeddings provide a compact representation of user preferences and characteristics, enabling personalized recommendations and addressing data sparsity or long-tail content challenges in recommendation systems.
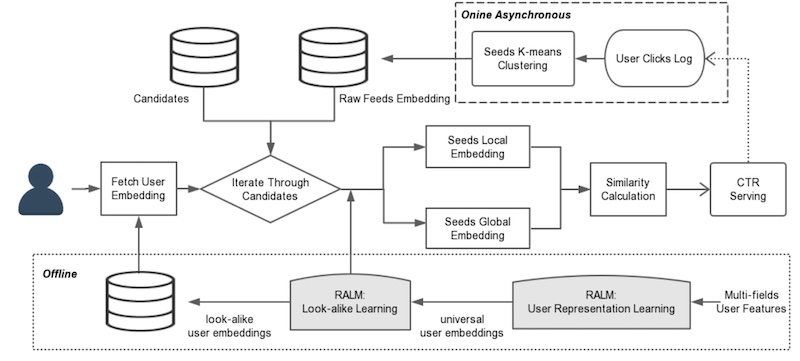
- Tencent adopts an approach similar to YouTube’s ranking model to learn user embeddings and user lookalikes for long-tail content recommendations on WeChat. For learning user embeddings, they use user features and historical behavior as input, and train a model to predict clicks based on user-item embeddings using a dot product and sigmoid function. The resulting user embeddings represent user preferences and characteristics.
- To learn user lookalikes, Tencent employs a two-tower model that compares the target user embedding with the embeddings of lookalike users. Since the number of lookalike users can be large, they use K-means clustering to obtain centroids instead of individual embeddings. The two-tower model incorporates global and local attention mechanisms to weigh the importance of each lookalike based on both global and personalized interests. The similarity between the target user and lookalikes is represented by the dot product of their embeddings.
- In the production system, global and local attention transforms the lookalike embeddings into global and local embeddings, respectively, before being combined. The global embedding has a weight of 0.7, while the local embedding has a weight of 0.3.
- The overall system design involves offline learning of user representations and the lookalike model, which are then used online to compute similarities for recommendations. K-means clustering is applied periodically to obtain the top 20 lookalike candidates.
- In conclusion, the patterns for personalization in recommendations and search discussed in this summary include bandits, embeddings+MLP, sequential models, graphs, and user models. The choice of which pattern to use depends on the specific requirements and characteristics of the recommendation system. Logistic regression with crossed features is a strong baseline for personalization, while real-time recommenders can benefit from word2vec-based item embeddings and approximate nearest neighbor techniques.
- Bandits – continuously learn via exploration:
References
- Google’s Recommendation Systems Developer Course
- Coursera: Music Recommender System Project
- Coursera: DeepLearning.AI’s specialization.
- Recommender system from learned embeddings
- Google’s Recommendation Systems Developer Crash Course: Embeddings Video Lecture
- ALS introduction by Sophie Wats
- Matrix Factorization
- Recommendation System for E-commerce using Alternating Least Squares (ALS) on Apache Spark