Recommendation Systems • Transformers
Overview
- Transformers are a power house and have revolutionized the way NLP works today with it’s self attention layer that is able to store a vast amount of context.
- This powerful architecture of Transformers can be leveraged in recommender systems to capture intricate user/item patterns and dependencies.
- The self-attention mechanism in Transformers enables the model to consider the entire context of user-item interactions, resulting in more accurate and personalized recommendations.
- Transformers can effectively handle long-range dependencies and capture complex relationships in user-item interactions, leading to improved recommendation quality.
- With the ability to store and utilize a vast amount of context, Transformers can enhance the understanding of user preferences and item features, leading to more precise and tailored recommendations.
- By leveraging the power of Transformers in recommender systems, businesses can provide users with highly relevant and engaging recommendations, improving user satisfaction and engagement.
- In this article, we will look at the current research and use cases of Transformers in Recommender Systems.
Use Cases
- Pinterest has been ahead of the curve leveraging recent architectures such as the Transformer. “They recently completely rethought their approach to personalized recommendation by encoding long-term user behaviors with Transformers. Considering the amount of data that a platform like Pinterest sees every day, it is common that the training data for a ML model doesn’t spam longer than 30 days, in which case we learn a user behavior which only captures the last 30 days. Whatever behavior the user had prior to that is forgotten and any short term interests (the past hour let’s say) are not understood by the model. In typical model development, the problem is a classification problem where we try to predict if a user will interact with an item or not.” (source)
- They build features to capture past actions but we don’t take into account the intrinsic time-series structure of the problem” (source)
ItemSage: Learning Product Embeddings for Shopping Recommendations at Pinterest
- ItemSage, developed at Pinterest, uses a single set of product embeddings for user, image, and search-based recommendations, resulting in improved engagement, conversion metrics, and reduced infrastructure and maintenance costs.
- Unlike previous approaches that focus on building embeddings from a single modality, ItemSage utilizes a transformer-based architecture capable of aggregating information from both text and image modalities.
- The transformer-based architecture in ItemSage outperforms single modality baselines, demonstrating the effectiveness of integrating multiple modalities for enhanced recommendation quality.
- Multi-task learning is employed in ItemSage to optimize the model for various engagement types, enabling an efficient candidate generation system that caters to the objectives of the end-to-end recommendation system.
-
Extensive offline experiments validate the effectiveness of the proposed approach, and online A/B experiments show significant gains in key business metrics, including up to +7% gross merchandise value per user and +11% click volume.
- ItemSage is Pinterest’s learned embedding representation for products in recommendation systems, which offers versatility and has been successfully used for various purposes.
- ItemSage embeddings are utilized for generating candidates, ranking models, and classification models, enabling approximate nearest neighbor search, determining product ordering, and inferring missing information from the shopping catalog.
- ItemSage distinguishes itself from previous approaches in several aspects, including the incorporation of multi-modal features that capture information from both text and image modalities.
- The transformer-based architecture of ItemSage combines features from different modalities, allowing for more nuanced and relevant recommendations, especially considering Pinterest’s visually dominant platform.
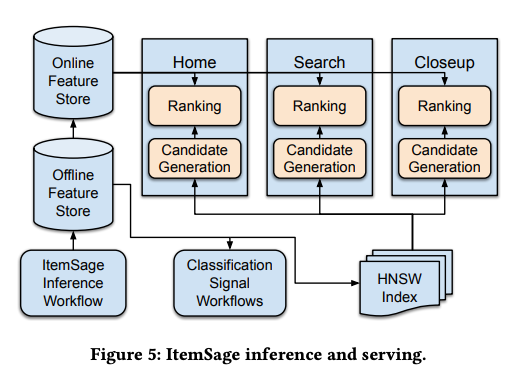
- ItemSage is capable of providing multi-modal vertical recommendations across different surfaces, such as Home, Closeup, and Search, responding to queries from various modalities.
- Multi-task learning is employed in ItemSage to optimize for multiple objectives, including purchases, add-to-cart actions, saves, and clicks, resulting in an efficient recommendation funnel.
- By optimizing embeddings for multiple objectives, ItemSage achieves improved results and can adapt to new objectives without sacrificing performance on existing objectives, even in cases with sparse labeled data.
- PinSage is an implementation of the GraphSage GCN (Graph Convolutional Network) algorithm deployed at Pinterest for generating image embeddings of billions of pins.
- It combines visual and textual features with graph information to create a compact representation for tasks such as retrieval, ranking, and classification.
- ItemSage, a learned embedding representation for products, leverages PinSage and SearchSage models to generate embeddings for feature images of products and query images, as well as the search query string.
- The PinSage model provides embeddings for both product and query images, while the SearchSage model embeds the search query string.
- During ItemSage training, the PinSage and SearchSage models are frozen to maintain development velocity and ease of adoption.
- PinSage and SearchSage models have multiple applications in production, leading to their freezing during ItemSage training.
- ItemSage aims to create product embeddings that are compatible with PinSage embeddings for images and SearchSage embeddings for search queries.
- Compatibility means that the distance between a query embedding (image or text) and a product embedding should indicate the relevance of the product as a result for the query.
- Cosine similarity is used as a measure of the embedding distance due to its simplicity and efficiency.
- The compatibility requirement is driven by the need to support candidate generation using approximate nearest neighbor (ANN) search techniques like HNSW (Hierarchical Navigable Small Worlds).
- To maintain low retrieval latency, expensive transformations to achieve compatibility are avoided.
- For ranking and classification applications, compatibility plays a less important role as deep learning models operating on pretrained embeddings can learn MLP transformations to map embeddings into a shared latent space.
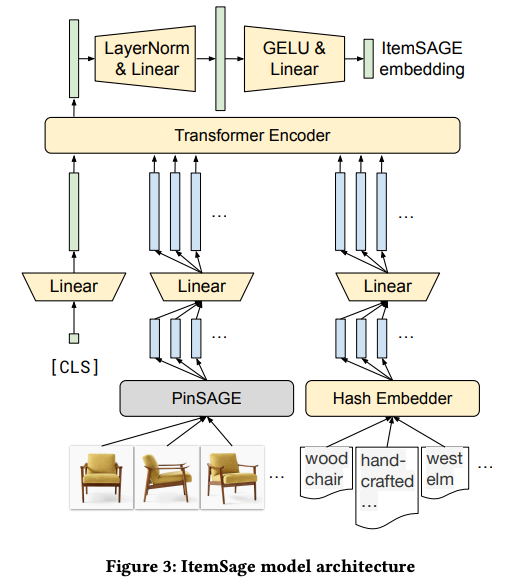
- The model architecture for learning product embeddings is based on a transformer encoder.
- The encoder takes a sequence of 32 embeddings as input, representing the image and text features of each product.
- Image embeddings are generated using the pretrained PinSage model, while text embeddings are learned jointly with the encoder.
- To handle the large vocabulary size, the hash embedding trick is applied, which consists of an embedding table and an importance weight table.
- Two hashing functions are used to map each token ID to two slots in the embedding table, and the token embedding is computed as a weighted interpolation of the two embeddings.
- The final embedding of a feature string is obtained by summing all its token embeddings.
- A linear transformation is applied to each group of feature embeddings, allowing for flexibility in input feature dimensions.
- A global token [CLS] is used to aggregate information from the input sequence.
- The transformed embeddings, along with the global token, are concatenated and passed through a one-layer transformer block with self-attention and feed-forward modules.
- The output corresponding to the global token is then processed by a two-layer MLP head to produce the 256-dimensional product embedding.
- The final ItemSage embedding is L2-normalized to facilitate cosine similarity computation with query embeddings during ANN search.
- Deeper transformer encoders were experimented with but did not yield improvements in offline metrics.
- The loss function for learning product embeddings is framed as an extreme classification problem, aiming to predict the next engaged product given a query entity.
- The softmax loss is used, with the dot product (cosine similarity) between query and product embeddings as the logits.
- To compute the softmax loss, the normalization step involving the entire catalog is approximated by treating other positive examples in the training batch as negatives, while applying the logQ correction to address sampling bias.
- The count-min sketch data structure is used to estimate the probabilities of positive and negative examples.
- A mixed negative sampling approach is employed, where random negatives are selected in addition to in-batch negatives, to reduce the negative contribution of popular products.
- The loss terms for in-batch positives (LSpos) and mixed negatives (LSneg) are computed separately, and the optimization objective is to minimize the sum of these two loss terms.
- The approach differs from a similar method in [31], which calculates the normalization term using both in-batch positives and mixed negatives.
- The ItemSage approach focuses on learning product embeddings for shopping recommendations at Pinterest.
- The embeddings are designed to extract information from both text and image features, leveraging the visual component of Pinterest and improving relevance in search results.
- The embeddings are made compatible with other entities in the Pinterest ecosystem, allowing a single embedding version to be deployed for different applications, resulting in reduced infrastructure costs and a more efficient upgrade and deprecation process.
- Multi-task learning is applied to optimize the embeddings for multiple engagement types, improving performance for objectives with sparse labels without penalizing objectives with sufficient training labels.
- The effectiveness of the approach is demonstrated through offline ablation studies and online A/B experiments.
- Future work may involve replacing the bag of words model for text features with a pretrained Transformer model and incorporating neighborhood sampling to extract additional multi-modal features from the Pinterest entity graph.
PinnerFormer
- PinnerFormer is a user representation model designed for personalized recommendation systems.
- It addresses the challenges of deploying sequential models in production by adapting the modeling approach to a batch infrastructure.
- It uses a dense all-action loss to predict a user’s long-term future engagement instead of just their next action.
- By modeling long-term actions, PinnerFormer bridges the gap between batch user embeddings generated daily and real-time user embeddings generated with each user action.
- The model’s design decisions were made based on extensive offline experimentation and ablations.
- In A/B experiments, PinnerFormer demonstrated substantial improvements in user retention and engagement compared to the previous user representation.
- PinnerFormer has been deployed in production at Pinterest since Fall 2021.
- PinnerFormer is a user representation model deployed at Pinterest since Fall 2021.
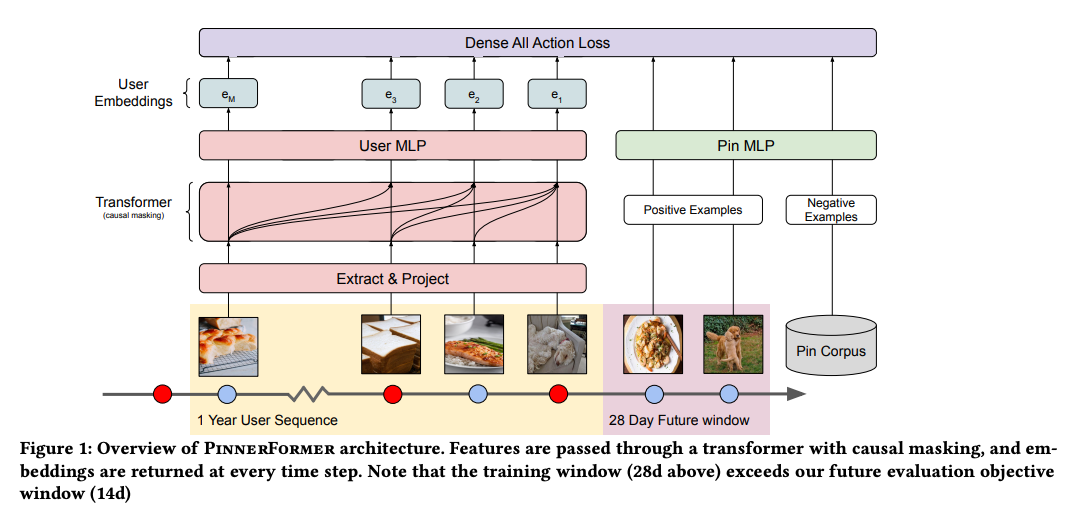
- It takes a corpus of pins and a sequence of user actions as input.
- Each pin is represented by a PinSage embedding, which aggregates visual, text, and engagement information.
- The model aims to learn a user representation that is compatible with the pin representation under cosine similarity.
- It focuses on predicting positive engagements such as Pin saves, long clickthroughs, and Pin close-ups.
- The objective is to predict a user’s positive future engagement over a 14-day time window, rather than just the next action.
- The model jointly learns the user and pin embeddings using the sequence of actions as input.
- The embeddings are generated based on the most recent actions, and the model can handle large action sequences.
- The goal is to learn embeddings that prioritize pins with closer distances to the user’s representation for positive engagement.
- Feature Encoding:
- Each action in a user’s sequence has a PinSage embedding (256-dimensional) and metadata features such as action type, surface, timestamp, and action duration.
- Categorical features (action type and surface) are encoded using small, learnable embedding tables.
- Action duration is encoded with a single scalar value (log(duration)).
- Time features are represented using sine and cosine transformations with fixed periods and a logarithmic transformation of time.
- All features are concatenated into a single vector, resulting in an input vector of dimension D_in.
- Model Architecture:
- PinnerFormer uses a transformer model architecture to model the sequence of user actions.
- PreNorm residual connections with Layer Normalization are applied before each block to improve training stability.
- The input matrix is constructed using the M most recent actions leading up to the current action.
- The input is projected to the transformer’s hidden dimension, a positional encoding is added, and a standard transformer consisting of feedforward network (FFN) and multi-head self-attention (MHSA) blocks is applied.
- The output of the transformer is passed through an MLP and L2 normalized to obtain the embeddings.
- Metric Learning:
- Positive and negative pairs of user embeddings and target Pin embeddings are used for training.
- Negative examples are obtained from in-batch negatives (positive examples within the batch) and random negatives (uniformly sampled from the corpus of all Pins).
- In-batch negatives are efficiently chosen but may demote popular Pins, while random negatives can lead to model collapse.
- The approach of combining in-batch and random negatives is considered to leverage the strengths of both.
- The loss function used is sampled softmax with a logQ correction.
- A correction term is applied to account for the probability of a given negative appearing in the batch.
- The loss is computed for each pair and weighted average is taken to ensure equal weight for each user in the batch on a given GPU.
- The softmax loss with sample probability correction is approximated using a count-min sketch for simplicity.
- A/B experiments are conducted to evaluate the performance of PinnerFormer in online ranking models.
- The first experiment focuses on the Homefeed ranking model, which determines the content order shown to users. PinnerFormer is compared to the previous PinnerSage aggregation approach.
- In the experiment, the aggregation of PinnerSage embeddings is replaced with a single PinnerFormer embedding in the enabled group.
- PinnerFormer significantly improves engagement on Homefeed and leads to an increase in daily and weekly active users.
- There is no observed regression in the improvements over several months after shipping the experiment.
- Another A/B experiment is conducted in Ads ranking models, where PinnerFormer is added as a feature without replacing PinnerSage.
- Each primary surface (Homefeed, Related Pins, and Search) has a separate model for ad ranking, and experiments are performed independently for each surface.
- The addition of PinnerFormer results in significant gains in ad engagement, specifically in clickthrough rate (CTR) and long clickthrough rate (gCTR).
- PinnerFormer is introduced as a single, end-to-end learned embedding designed for offline inference, aiming to capture a user’s interests over a multi-day time horizon.
- Unlike other approaches focused on predicting a user’s next engagement, PinnerFormer utilizes a novel loss function to capture a user’s interests over several days.
- The training objective of PinnerFormer reduces the performance gap between real-time and daily inference models.
- Detailed experiments are conducted to analyze the contributions of each component of the model, highlighting the effectiveness of multi-task learning and sampled softmax.
- Future plans involve further exploration of PinnerFormer’s performance as a candidate generator and incorporating actions beyond Pin engagement to create a more comprehensive user representation.