Paper Reviews
- Overview
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- BEiT: BERT Pre-Training of Image Transformers
- Patches Are All You Need?
- DiT: Self-supervised Pre-training for Document Image Transformer
- Donut: OCR-free Document Understanding Transformer
Overview
- This section will include summaries of a few seminal papers in the field.
- Just want to note that the first few sections are inspired by Elvis Saravia’s post on DAIR that can be found here
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- Inspired by DAIR.ai
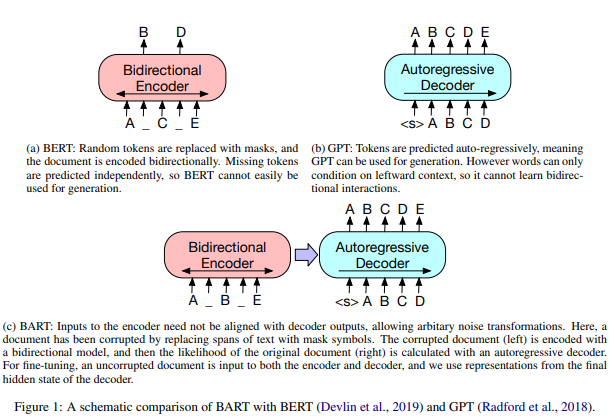
- Bidirectional Encoder Representations from Transformers (BART) is a pre-trained transformer based neural network architecture for NLP tasks.
- BART was developed by researchers at Facebook AI and it uses a technique called denoising autoencoding, which involves training the model to reconstruct the original input text from a corrupted version of the input.
- (You could say its the text equivalent of Stable Diffusion which denoises for image genration)
- BART was trained with cross-entropy loss and optimized with the Adam optimizer and is able to achieve stat of the art performance on a variety of NLP tasks.
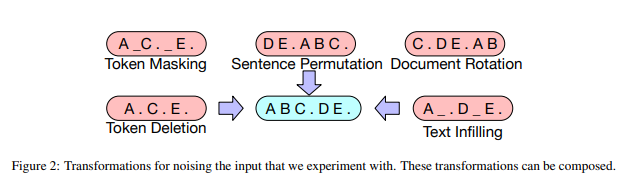
- Pretraining in BART is done in 2 stages:
- 1) the text is corrupted with noising function
- 2) a sequence-to-sequence model works on reconstructing the text by taking and optimizing the cross-entropy loss between the decoder output and the original document
- With these two steps, BART is able to learn contextual information about the text.
- Below are the transformations used as seen in DAIR.AI and Ritvig Rastogi’s post

- Additionally, BART much like BERT, can be fine tuned for anly NLP task such as text generation or machine translation.
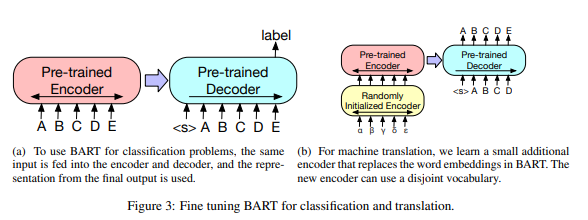
BEiT: BERT Pre-Training of Image Transformers
- Inspired by DAIR.ai and Kaggle discussion
- Bidirectional Encoder with Image Refinement (BEiT) that was developed by Facebook AI and is a variant of BERT used for images.
- Applying BERT style encoding is challenging when we try to transfer it for images as we do not have a set vocabulary for context.
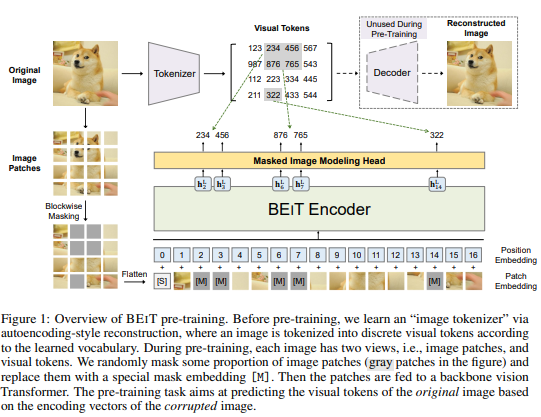
- What BEiT does is it gives a solution for pretraining visions with Transformers.
- As we can see in the image above, there are two paths the original image takes: Image Patches and Visual Tokens.
Image Patches
- The input 2D image is split into a sequence of patches for the Transformer to serve as input.
- These image patches are flattened into vector representations and are linearly projected, just like BERT does with word vectors in embedding space.
- The image patches vectors still preserve the raw pixel data just as the word vectors in BERT preserve the word’s meaning.
Visual Tokens
- Here, the image is represented as a sequence of discrete tokens generated by an image tokenizer instead of from raw pixels.
-
“There are two modules during visual token learning namely, tokenizer and decoder the Tokenizer maps image pixels into discrete tokens according to a visual codebook (vocabulary). The decoder learns to reconstruct the input image based on visual tokens.”Kaggle post
- Similar to BERT, BEiT uses masked-image-modeling, where certain regions of an image are obscured or masked and the model’s goal is to predict the content of the masked region.
Patches Are All You Need?
- Work in progress
DiT: Self-supervised Pre-training for Document Image Transformer
- Inspired by Hugging Face
- According to the paper, DiT is “a self-supervised pre-trained Document Image Transformer model using large-scale unlabeled text images for Document AI tasks, which is essential since no supervised counterparts ever exist due to the lack of human labeled document images.” original paper
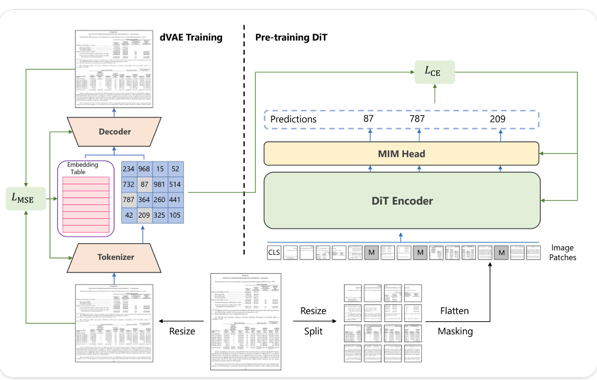
- DiT was created to solve several vision based Document AI tasks such as document image classification, document layout analysis, as well as table detection.
- DiT has the ability to classify the category of a document with just a picture of it.
- For DiT, the architecture includes ViT (Vision Transformer) as its foundation that it uses over patch embeddings it has created.
- “After adding the 1d position embedding, these image patches are passed into a stack of Transformer blocks with multi-head attention.
- Finally, we take the output of the Transformer encoder as the representation of image patches.
- To effectively pre-train the DiT model, we randomly mask a subset of inputs with a special token [MASK] given a sequence of image patches. The DiT encoder embeds the masked patch sequence by a linear projection with added positional embeddings, and then contextualizes it with a stack of Transformer blocks. “Kaggle post
Donut: OCR-free Document Understanding Transformer
- Inspired by Kaggle post
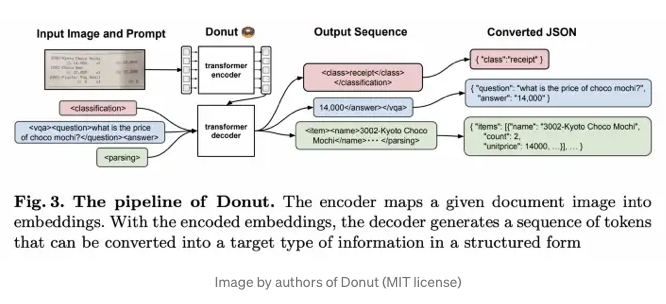
- Donut is a visual document understanding (VDU) , end to end model that takes in an image and produces the output, thus bypassing the need for Optical Character Recognition (OCR).
- Donut leverages the Transformer architecture with a visual encoder and textual decoder as it takes images as inputs and can transform them to json, or other format as output.
- Encoder: Converts the input document image into a set of embeddings with the use of Swim Transformer which is a type of Vision Transformer.
- Swin Transformer will take the image, split it into patches and make sure they are not overlapping.
- “Swin Transformer blocks, consist of a shifted window-based multi-head self-attention module and a two-layer MLP, are applied to the patches. Then, patch merging layers are applied to the patch tokens at each stage.
- The output of the final Swin Transformer block {z} is fed into the following textual decoder.”Kaggle post
- Decoder: BART is used for the decoder architecture.
- Tasks: Document classification, Document information extraction, document visual question answering