Pinterest Homepage
- Overview
- Functional
- Non-functional
- Storage - DB
- High level design
- Load Balancer
- Reverse Proxy
- Web App:
- Mobile App:
- API App:
- Stateless Web and API Tier:
- Service Tier:
- Service Discovery: How services find each other?
- Follower Service
- Feed Service:
- Images Blob Store and CDN:
- Search Service:
- Spam Service
Overview
- Pinterest is a highly scalable photo-sharing service with hundreds of millions of monthly active users. Here are the requirements:
- Private board
- share board to be able to see with friends
- only links
- no limit on links
Functional
- news feed: customers will see a feed of images after login
- one customer follows others to subscribe to their feeds
- Upload photos: they can upload images which will appear in followers feeds
- Eventual consistency (due to CAP theorem): As we know from the CAP theorem, that we can have either high availability or high consistency, thus we will aim for an eventually consistent system.
- Add new board
- list all my boards
- view a board via id
- permission
- no clone, comment, like
Non-functional
- Security, auth
- Row Description (“/” means per) Estimated Number Calculated
- MAU 500 M
- DAU is 25 M
- 1M users per hour
- .1M users creating boards (write)
- .9M users seeing boards (read)
- Read heavy service
- requests / user / day = 60
- rps / machine 10,000 (c10k problem)
- Horizontally scalable
- decoupled into microservices
- Horizontal scaling involves adding more machines to increase capacity, offering flexibility and distributed processing but with added complexity and potential consistency challenges.
- Vertical scaling focuses on enhancing a single machine with more power, leading to simplicity and consistency but with limitations in growth, potential downtime, and a single point of failure.
Storage - DB
DB design
- Boards
- id (UUID)
- name (100 char)
- description (1088 char) crested at (datetine)
- updated at (catetine)
- Links
- id (UUID)
- originaL_urt (char 1080)
- hash urt (char 50)metadata (¡son)
- title ogidetall (ison)
- Board Links
- board. ld
-
link id
-
undque - board_id + link_id
- Share
- board id
- shared_with.user_1d
- created_at
High level design
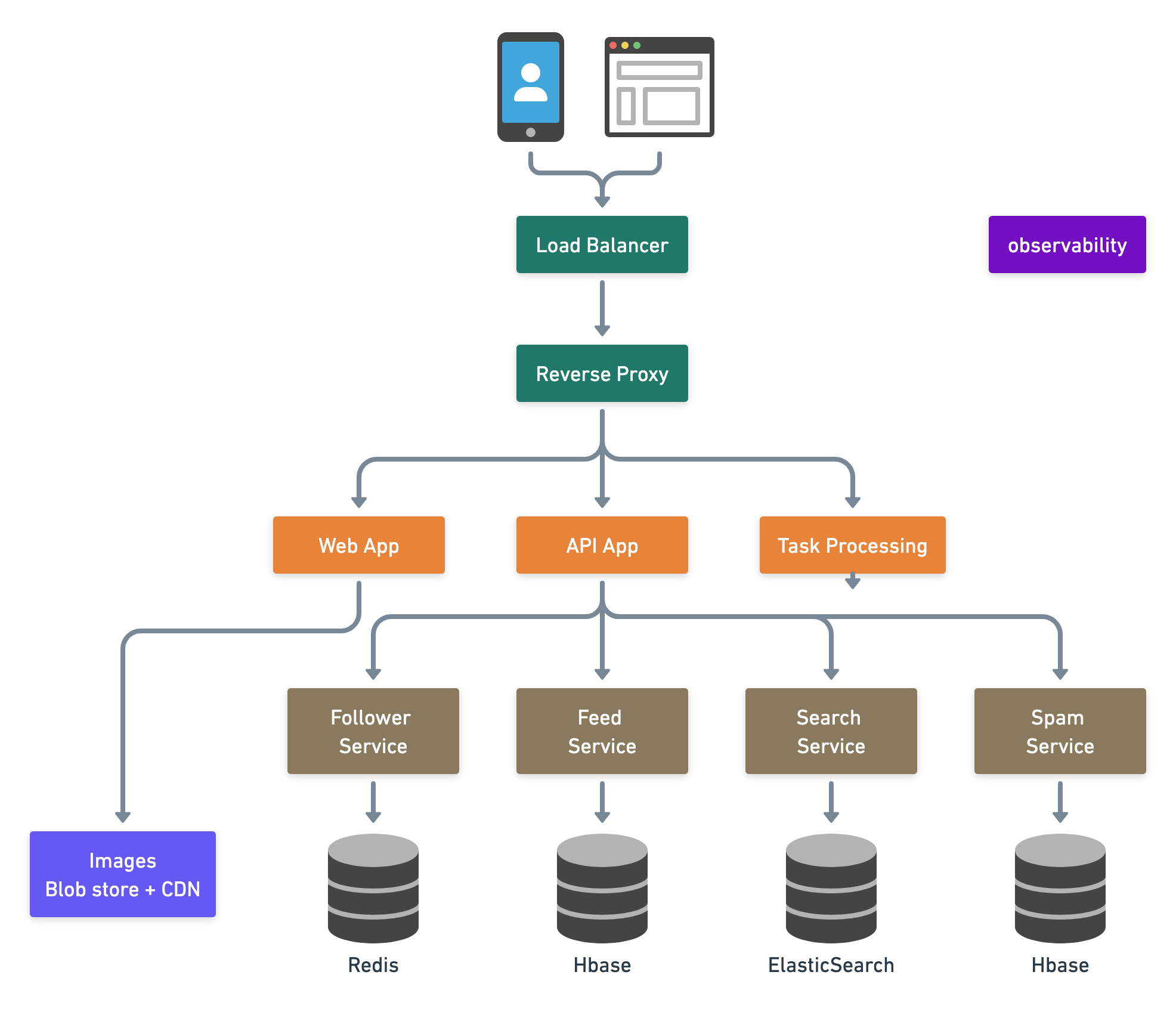
- Load balancer: Nginx (Engine-X), Google Cloud Load Balancing
- Reverse proxy, Nginx can also act as a reverse proxy here with Load balancing, SSL termination, caching, HTTP/2 support.
Load Balancer
- Load balancers distribute incoming network traffic to a group of backend servers. They fall into three categories:
- DNS Round Robin (rarely used): clients get a randomly-ordered list of IP addresses.
- pros: easy to implement and usually free.
- cons: hard to control and not quite responsive because DNS cache takes time to expire.
- L3/L4 Network-layer Load Balancer: traffic is routed by IP address and port. L3 is the network layer (IP). L4 is the transport layer (TCP).
- pros: better granularity, simple, responsive. e.g. forward traffic based on the ports.
- cons: content-agnostic: cannot route traffic by the content of the data.
- L7 Application-layer Load Balancer: traffic is routed by what is inside the HTTP protocol. L7 is the application layer (HTTP). In case the interviewer wants more, we can suggest exact algorithms like round robin, weighted round robin, least loaded, least loaded with slow start, utilization limit, latency, cascade, etc.
Reverse Proxy
- Reverse Proxy Definition: Unlike a “forward” proxy, which routes traffic from clients to an external network, a reverse proxy sits in front of servers, essentially acting in “reverse.” A load balancer can also be considered a type of reverse proxy.
- Routing: Centralizes traffic to internal services and provides unified interfaces to the public. Pages like www.example.com/index and www.example.com/sports may come from different servers but appear from the same domain through the reverse proxy.
- Filtering: Utilizes the reverse proxy to filter out requests lacking valid credentials for authentication or authorization.
- Caching: If certain resources are popular for HTTP requests, a reverse proxy can be configured with caching for those routes to conserve server resources.
Web App:
- Early Phase: Initially, web service often combines backend with page rendering (e.g., Django, Ruby on Rails).
- Decoupling: With growth, frontend (App rendering) and backend (serving APIs) often become separate projects.
Mobile App:
- Mobile Design: Most backend engineers may lack familiarity with mobile design patterns.
- Similar to Web Frontend: A dedicated frontend web project resembles a standalone mobile app; both are server clients.
- Holistic Frontend: Some engineers build user experiences on both platforms simultaneously (e.g., react for web and react-native for mobile).
API App:
- Communication: Clients talk to servers via public APIs, commonly served as RESTful or GraphQL APIs.
Stateless Web and API Tier:
- Bottlenecks: The major constraints are load (requests per second) and bandwidth.
- Solutions:
- More Efficient Software: Using frameworks with async and non-blocking reactor patterns.
- More Hardware: Either scaling up (vertical scaling with more powerful machines) or scaling out (horizontal scaling with more less-expensive machines).
- Preference for Scaling Out:
- Cost-Efficient: Utilizing a large number of commodity machines.
- Education and Recruitment: Facilitates learning programming on standard PCs.
- Service Statelessness: Keeping services stateless for easy management (e.g., unexpected termination, restarts).
- Scaling Considerations: Further information on scaling can be found in resources such as “how to scale a web service.”
Service Tier:
- Single Responsibility Principle: Advocates for small, autonomous services working together.
- Independence: Each service can “do one thing and do it well” and grow on its own.
- Small Teams: Ownership of small services enables aggressive planning for hyper-growth.
- Micro vs Monolithic: More about this topic can be learned in resources like “Designing Uber.”
Service Discovery: How services find each other?
- Zookeeper:
- Centralized Choice: Registers instances with name, address, port, etc.
- Querying: Services can query Zookeeper for the location of other services.
- CP System (CAP theorem): Zookeeper stays consistent during failures but may become unavailable for new registrations.
- Decentralized Methods:
- Example: Uber’s Hyperbahn (based on Ringpop consistent hash ring), although it was a failure.
- Understanding AP and Eventual Consistency: Read resources like Amazon’s Dynamo.
- In Kubernetes Context:
- Usage of service objects and Kube-proxy.
- Simplifies Targeting: Programmers can specify the address of the target service with internal DNS.
Follower Service
- The follower-and-followee relationship is all around these two straightforward data structures:
Map<Followee, List of Followers>
Map<Follower, List of Followees>
- A key-value store, like Redis, is very suitable here because the data structure is pretty simple, and this service should be mission-critical with high performance and low latency.
- The follower service serves functionalities for followers and followees. For an image to appear in the feed, there are two models to make it happen.
- Push. Once the image is uploaded, we push the image metadata into all the followers’ feeds. The follower will see its prepared feed directly.
- If the Map <Followee, List of Followers> fan-out is too large, then the push model will cost a lot of time and data duplicates.
- Pull. We don’t prepare the feed in advance; instead, when the follower checks its feed, it fetches the list of followees and gets their images.
- If the Map<Follower, List of Followees> fan-out is too large, then the pull model will spend a lot of time iterating the huge followee list.
- Push. Once the image is uploaded, we push the image metadata into all the followers’ feeds. The follower will see its prepared feed directly.
The system is composed of several key components:
Feed Service:
- This service handles the metadata of image posts, such as URL, name, and description, storing them in a database.
- Images are saved in Blob Storage like AWS S3 or Azure Blob store. The process involves generating a pre-signed URL for client uploads, storing the image, and triggering data pipelines to push posts to followers’ feeds.
- HBase/Cassandra’s timestamp index fits well for this use case.
Images Blob Store and CDN:
- Due to the high bandwidth consumption of transmitting blobs, caching with CDNs is common to bring the content closer to the customer.
- Popular combinations include AWS CloudFront CDN + S3, though others may use decentralized stores like IPFS and Arware.
Search Service:
- This service links to all possible data sources and indexes them for easy search across feeds, typically employing tools like ElasticSearch or Algolia.
Spam Service
- Utilizing machine learning techniques, the spam service identifies and eliminates profanity content and fake accounts, employing methods such as supervised and unsupervised learning.
- More insights can be gleaned from resources like “Fraud Detection with Semi-supervised Learning.”