Pinterest Similar Products
Overview
- Design a system to detect similar products and provide more context to users.
- How to tell whether two products are similar
- Two shoes same size same color, different orientation
- What do you mean by better content
Function requirements
- Detect products that are too similar
- Provide non duplicate data/content to users
Key metrics/data
- num of users + estimated growth
- Database/storage size
- Reads vs Writes operation ratio
- Volume of request
System design
Background Pinterest Search
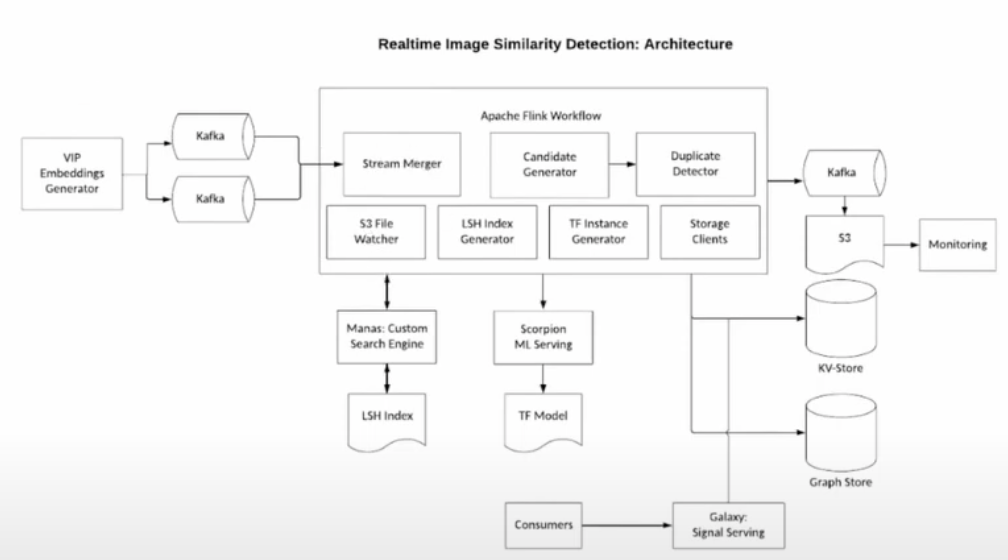
- VIP team handles media uploaded to pinterest, generate embeddings and send notification to kafka
- stream join, embeddings come a few seconds apart
- Embeddings are extracted and sent to manas- search engine
- If duplicate image, remove/ update it in storage
- once candidate generated, sent to ML hosting service scorpion and get a score b/w 0 and 1. this will form a cluster of items and we will pick the cluster of the highest score
- automated alerting, monitoring
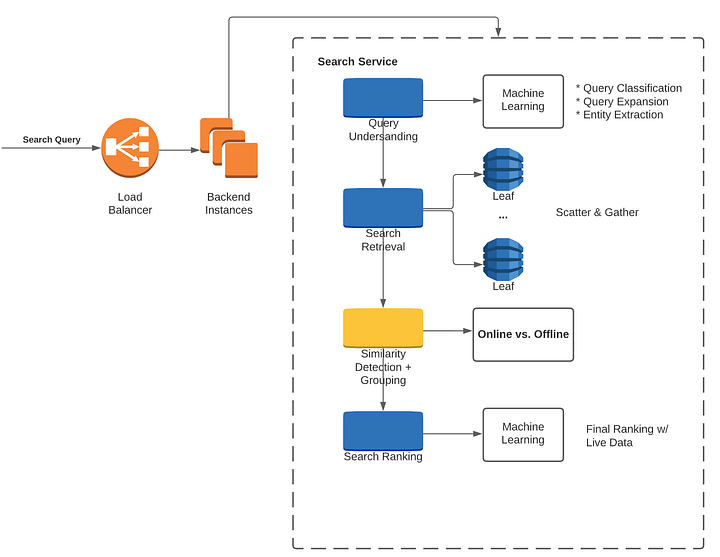
- Elastic search, weighted approach where you assign a weight to each category in the metadata: title, description, image, price
- calculate the confidence score
- Yes, the scatter-gather pattern can be applied to relational databases, particularly when working with distributed or sharded relational databases. Here’s how it might work:
Scatter:
- Query Breakdown: The original query is broken down into smaller parts, each of which can be executed on a different shard or partition of the database.
- Distribution: The smaller queries are “scattered” across the various nodes or shards, where each holds a portion of the overall data.
- Parallel Processing: These nodes or shards process the queries concurrently, working on the specific subset of data that they hold.
Gather:
- Collecting Results: The results from each node or shard are then “gathered” back together.
- Aggregation: Depending on the nature of the query, this might involve aggregating the results (e.g., summing, averaging), concatenating them, or otherwise combining them to form the final result set.
-
Final Result: The combined result is then returned to the client that requested the query.
- In a non-distributed relational database (i.e., a single instance), the scatter-gather pattern might not be directly applicable because there’s no distribution of data across different nodes or shards. However, some of the underlying principles, such as parallel processing of different parts of a query, can still be utilized in some databases that support parallel query execution.
- In distributed or sharded relational databases, the scatter-gather pattern can be very useful in efficiently querying large data sets. It leverages the distribution of data and parallel processing capabilities of the system to potentially deliver faster query results.
- Some distributed SQL databases and data warehousing solutions that are built to handle large-scale data across multiple nodes might inherently utilize a form of scatter-gather in their query execution, abstracting this complexity from the end-user.
Sure! ANN (Approximate Nearest Neighbors) and HNSW (Hierarchical Navigable Small World) both refer to algorithms used in similarity search, specifically for finding the nearest neighbors in a high-dimensional space. They are used in various machine learning and data mining applications where exact nearest neighbor search is computationally expensive.
ANN (Approximate Nearest Neighbors):
ANN aims to find the approximate nearest neighbors in a dataset. This is useful in many applications where exact matching isn’t necessary, and where an approximation can be found much more quickly.
- Indexing: ANN methods often use techniques like Locality-Sensitive Hashing (LSH) to index vectors, creating hash tables where similar items hash to the same “bucket.” Other tree-based methods can also be used.
- Distance Metric: Cosine similarity, Euclidean distance, and other metrics can be used to measure similarity between vectors.
- Search: During search, the method may only examine a subset of the dataset to find the approximate nearest neighbors quickly.
- Trade-off: There’s usually a trade-off between accuracy and speed. The more approximate the method, the faster it can perform searches, but the less accurate the results may be.
HNSW (Hierarchical Navigable Small World):
HNSW is a specific algorithm for approximate nearest neighbor search, and it is considered to be one of the most efficient algorithms for this task.
- Graph Structure: HNSW constructs a hierarchical graph where each layer of the graph is a subset of the previous layer. It forms connections between similar items, forming a “small world” network.
- Indexing: The indexing involves adding items to the graph and connecting them to their neighbors at various layers of the hierarchy. Neighbors in higher layers are more approximate, while neighbors in lower layers are more precise.
- Distance Metric: Similar to general ANN methods, HNSW can use various distance metrics including cosine similarity and Euclidean distance.
- Search: Searching involves starting at a higher, more approximate layer and navigating down to lower, more precise layers to find the nearest neighbors. By using this hierarchical structure, HNSW can quickly eliminate large portions of the search space.
Comparison:
- Methodology: While ANN refers to a broad category of algorithms for approximate nearest neighbor search, HNSW is a specific method within this category. HNSW’s hierarchical graph-based approach distinguishes it from other ANN methods that might use hashing or tree-based structures.
- Efficiency: HNSW is often considered more efficient in terms of both speed and memory compared to some other ANN methods, thanks to its hierarchical structure.
- Accuracy: Depending on the implementation and configuration, HNSW can achieve high accuracy while still being fast. The trade-off between speed and accuracy can be more finely controlled compared to some other ANN methods.
Conclusion:
Both ANN and HNSW are concerned with finding the nearest neighbors in a high-dimensional space, and both can use various distance metrics like cosine similarity. While ANN refers to a general category of algorithms, HNSW is a specific and highly efficient algorithm within this category, characterized by its hierarchical graph structure. The choice between different methods depends on the specific requirements of the application in terms of speed, accuracy, memory consumption, and other factors.