Ad End to End
- Overview
- Functional Requirements
- Non-functional, numbers
- Architecture components
- High level
- Distributed key value store
- Candidate Ranking
- Batch vs Realtime upload
- Ads Indexing Overview
- Ads database
- 1. Gateway:
- 2. Updater:
- 3. Storage Repo:
- 4. Argus:
- Ads Mixer
- Solution: Index Publisher
- Ads Manager
- HNSW + Manas: customized search system
- APIs
- Additional Considerations
- Ads Index Publisher
- The Challenge
- Solution: Index Publisher
- Pacing:
- Auction
- Ranking
- Forecasting
- Targeting
- Ad Server
- Metrics
Overview
- Let’s take a holistic look at the ads platform
Functional Requirements
- actual ad clicks and redirect should be pretty fast (low latency)
- high availability for the ad click events
- eventual consistency is good enough
- we should capture ad click events
- we should be able to query the ad click events, as a marketing analyst
- Minimum latency: The suggestions should appear in real-time. The user should be able to see the suggestions within 200ms.
- High availability: The final design should be highly available.
- Eventual consistency (due to CAP theorem): As we know from the CAP theorem, that we can have either high availability or high consistency, thus we will aim for an eventually consistent system.
Non-functional, numbers
- Scalability:
- Daily Active Users (DAUs): 200 million
- Ad Requests Per Second: 300,000 at peak times
- Latency:
- Ad Retrieval Latency: Less than 100 milliseconds (ms)
- Availability:
- System Uptime: 99.99%
- Data Storage and Throughput:
- Ad Corpus Size: 10 TB
- User Behavior Data: 50 TB per month
- Ad Performance Metrics: 5 TB per day
- Write Throughput: 10,000 writes per second
- Read Throughput: 50,000 reads per second
Architecture components
High level
- We had three main goals:
- Simplify scaling our ads business without a linear increase in infrastructure costs
- Improve system performance
- Minimize maintenance costs to boost developer productivity
- Solution: Deprecate In-Memory Index
- Rather than horizontally or vertically scaling the existing service, we decided to move to an external data store.
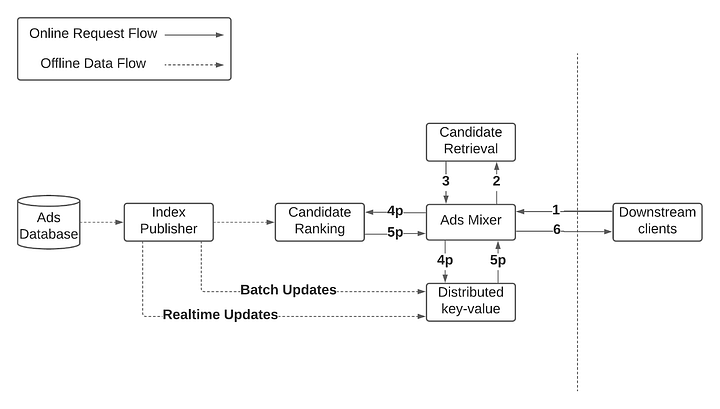
- Significantly reduced startup time from 10 minutes to <2 minutes (since we no longer needed to parse and load this index into memory).
- Cost: CPU-based cluster auto scaling, which makes our infra cost more reflective of actual traffic. as opposed to dependent on hard coded capacity numbers that are not tuned frequently enough.
- It also makes our cluster more resilient to growth in traffic, since a larger cluster is automatically provisioned, without the need for manual intervention.
-
Client Request: The client sends a request to the Ads Mixer, which could include details about the user’s context, preferences, and browsing history.
-
Query Vectorization: The Ads Mixer processes the client request to form a query vector that represents the information in a form that can be understood by the candidate retrieval system.
-
Candidate Retrieval: The Ads Mixer calls the candidate retrieval service (using HNSW or other algorithms) with the query vector to get a set of closest ad vectors. This may include an identifier for each vector, such as an ad ID.
-
Fetching Ad Details: The Ads Mixer uses the retrieved ad IDs to look up the full ad details from a distributed key-value store. This store would maintain a mapping between ad IDs and the actual content, metadata, images, and any other information necessary to serve the ad.
-
Response Formation: With the full ad details retrieved, the Ads Mixer constructs a response to send back to the client, including the selected ads in the appropriate format for display.
-
Real-time/Batch Update (Optional): The Ads Mixer might also update real-time statistics or log the event for later batch processing.
- Key Achievements
- Simplified Scaling: By utilizing an external KV store and optimizing memory usage, the system could handle a 60x larger ad corpus without linearly increasing infrastructure costs.
- Improved Performance: Through parallel processing, caching, and garbage collection optimizations, system latency was reduced, and reliability increased.
- Minimized Maintenance Costs: By simplifying the architecture, maintenance became more straightforward, boosting developer productivity.
Distributed key value store
- Amazon DynamoDB: A fully-managed key-value and document database that delivers single-digit millisecond performance at any scale.
- Apache Cassandra: A distributed key-value store that is designed to handle large amounts of data across many commodity servers, without any single point of failure.
- Google Cloud Bigtable: A scalable, fully-managed NoSQL database used for large analytical and operational workloads.
- Key: The key could be a unique identifier representing an ad, such as an ad ID or a unique hash corresponding to specific attributes of an ad. For instance, if using vectors to represent ads, the key might correspond to a specific vector identifier within the candidate retrieval system.
- Value: The value would be the actual data associated with that ad. This could include information such as the ad’s content, metadata (like title, description, image URL, etc.), targeting information, bidding details, and other properties that are relevant for serving the ad to users.
Candidate Ranking
- LTR - learn to rank algorithm
- Listwise Approaches: These consider the entire list of items and aim to optimize the order of the entire list. One popular listwise approach is ListNet, which models the problem of ranking as a probabilistic problem.
- Pairwise Approaches: These models try to learn the optimal ordering of pairs of items. RankNet is a popular algorithm in this category.
- Pointwise Approaches: These models predict a score or relevance label for each item independently. Algorithms like logistic regression or simple decision trees can be used for pointwise ranking
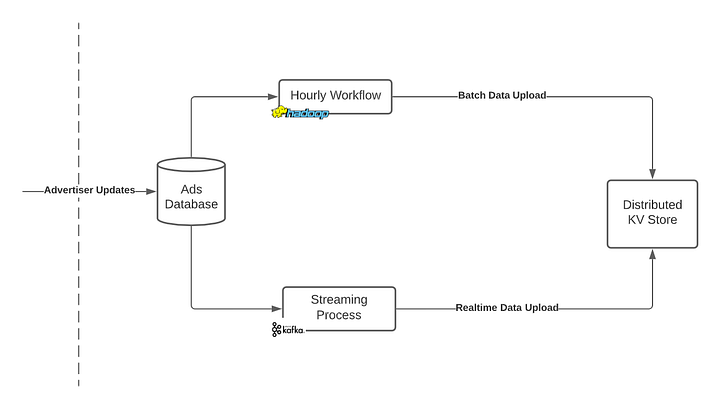
Batch vs Realtime upload
- Batch Processing - Hadoop:
- Hadoop is typically used for batch processing, where a large volume of data is processed at once in a scheduled, periodic manner. In the case of the index publisher, an hourly workflow using Hadoop might involve:
- Large-scale processing: Analyzing and processing a significant volume of accumulated data.
- Complex Computations: Performing more complex transformations or aggregations that aren’t time-sensitive.
- Resource Optimization: Running these tasks in a batch mode allows for better utilization of resources as tasks can be optimized to run together.
- Fault Tolerance: Hadoop provides robust fault tolerance, ensuring that if a part of the process fails, it can be restarted or recovered without losing all the work.
- Real-Time Streaming - Kafka:
-
For the real-time streaming process, Kafka is used to handle data that requires immediate processing. This can include:
- Continuous Ingestion: Kafka can consume and process streams of data in real time, making it suitable for handling continuous updates.
- Low Latency: Real-time processing demands quick response times, and Kafka is designed for low-latency processing.
- Scalability: Kafka can handle a large number of producers and consumers, enabling it to scale as the amount of real-time data grows.
- Durability: Kafka’s distributed architecture ensures that data is reliably stored and processed.
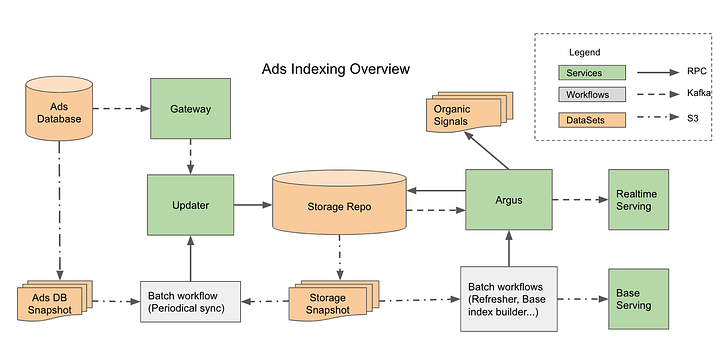
Ads Indexing Overview
- Let’s break down each component of this architecture and the technologies that could be used for each:
Ads database
When advertisers update the database, they might send a variety of information to create new ads or modify existing ones. Here’s a breakdown of typical data they might send:
- New Ad Creation:
- Ad Content: Text, images, videos, or other multimedia elements.
- Targeting Information: Specifications for the target audience, such as demographics, interests, location, etc.
- Bidding Information: Details on the bidding strategy and price for the ad placement.
- Scheduling Information: Timeframes for when the ad should be displayed.
- Campaign Information: Information about the overall ad campaign, like objectives, budget, etc.
- Tracking Information: Any specific tracking parameters or tags.
- Ad Modification:
- Content Updates: Changes to any of the multimedia content or text.
- Targeting Adjustments: Modifications to the target audience specifications.
- Bidding Adjustments: Changes to the bidding strategy or price.
- Scheduling Adjustments: Alterations to the ad’s scheduled display times.
- Status Changes: Enabling, pausing, or disabling specific ads or campaigns.
- Ad Performance Feedback:
- Performance Metrics: Information on how the ad is performing, like click-through rates, conversions, etc. (Though this might also be gathered by the ad platform itself).
- Bulk Operations:
- Advertisers might send bulk updates for managing multiple ads at once, such as pausing all ads for a particular campaign or updating the bidding strategy across a set of ads.
- Amazon DynamoDB: Structured Data: You can store text, integers, floats, booleans, and arrays in DynamoDB tables. Unstructured Data: Binary data like images or videos can be encoded and stored directly in DynamoDB. Alternatively, you could still store larger files in Amazon S3 and keep references (URLs or keys) in the DynamoDB records.
1. Gateway:
- The Gateway’s main job is to take update events from various upstream sources (like changes to ads, user interactions, etc.) and convert them into a standardized format that the ads indexing updater can understand.
- is a light-weighted stream process framework.
- “at least once process”
- Purpose: Converts various update events from upstream sources into a format suitable for the ads indexing updater.
- It can send these updates to the Updater via Kafka or direct RPC (Remote Procedure Call).
- Potential Technologies:
- Stream Processing: Apache Kafka Streams, Apache Flink
- Messaging System: Apache Kafka for asynchronous communication
- RPC Framework: gRPC, Apache Thrift
2. Updater:
- Purpose: Acts as the data ingestion component that takes updates from the Gateway and writes them into the Storage Repo.
- It basically tails Kafka topics, extracts structured data from messages and writes them into Storage Repo with transaction protection.
- Potential Technologies:
- Data Processing: Apache Storm, Apache Flink
- Data Ingestion Tools: Apache NiFi, Flume
3. Storage Repo:
- Purpose: Stores all data throughout the ad document process life cycle, from raw updates to final servable documents. It needs to support cross-rows and tables transactions and column-level change notification to Argus.
- Potential Technologies:
- Database Systems: Supporting transactions and column-level notifications could be done through RDBMS like PostgreSQL, MySQL, or distributed databases like TiDB.
- Change Data Capture (CDC) Tools: Debezium for capturing column-level changes
4. Argus:
- Purpose: Notification-triggered data process services. An Argus worker is notified of a data change event from the Repo, reads all dependent data from the data repo, conducts heavy computation, generates final servable documents, writes back to the Repo, and publishes them for real-time serving.
- Potential Technologies:
- Processing Frameworks: Apache Spark for computational heavy processes
- Workflow Management: Apache Airflow for orchestrating the complex data workflow
- Real-time Serving Technologies: Apache Druid, Redis
Ads Mixer
- The ads mixer is a microservice designed to manage the interaction between the retrieval and handling of advertisement data. As a stateless service, it communicates with an external key-value store that maintains the advertisement index. This approach allows the ads mixer to simplify the overall architecture by replacing a previously sharded in-memory index system.
- Identifying Active Ads: The primary challenge is to identify active ads at a given moment. Querying the database could be time-consuming due to the need to filter by status and join multiple tables (e.g., Campaign, Ad Set, Ad, and Creative).
- Read vs Write Optimization: While the database might be optimized for writes (e.g., updates to specific entities), reading to serve ads requires complex querying across multiple tables. This can be slow and inefficient.
Solution: Index Publisher
To overcome these challenges, the system requires an index publisher to pre-calculate various useful indices for efficient ad serving.
- Functions:
- Retrieval: Fetching relevant advertisement data from the external key-value store.
- Processing: Handling the necessary logic to serve the appropriate advertisements based on various factors such as user preferences, targeting rules, etc.
- Scaling: Facilitating the scalable management of large advertisement data without the need for complex sharding, by leveraging the external key-value store.
- Integration: Acting as an intermediary between different parts of the advertising system, such as candidate retrieval and updates (either batch or real-time).
-
By serving as a central hub for these functions, the ads mixer microservice enables streamlined scaling and improved performance for the advertising system. Its stateless nature ensures that the system can grow without a linear increase in infrastructure costs, minimizing maintenance challenges and boosting developer productivity.
- Parallelization and Caching:
- Introducing parallel processes for fetching index data and ranking minimized latency, while local caching reduced the queries to the key-value store, saving infrastructure cost.
- Real-Time Data Updates:
- To handle missing or stale data in the KV store, real-time updates were enabled, reducing the number of missing candidates and improving data freshness.
- Process Client Request for Ads:
def process_client_request(client_request: ClientRequest) -> ProcessedRequest: ... - Fetch Candidates from Retrieval Service:
def fetch_candidates(processed_request: ProcessedRequest, limit: int) -> List[CandidateAd]: ... - Retrieve Ad Details from Distributed Key-Value Store:
def get_ad_details(candidate_ads: List[CandidateAd]) -> List[Ad]: ... - Serve Ads to Client:
def serve_ads_to_client(client_id: str, ads: List[Ad]) -> ServeAdsResponse: ... - Update Ad Statistics in Distributed Key-Value Store (Real-Time/Batch):
def update_ad_statistics_in_kv_store(ad_statistics_update: AdStatisticsUpdate) -> bool: ... - Search Ads with Query (interacts with Candidate Retrieval and Key-Value Store):
def search_ads(query: str, filters: SearchFilters, limit: int) -> List[Ad]: ... - Manage Ad Campaign (possibly communicating with other services or databases):
def manage_campaign(campaign_request: CampaignRequest) -> CampaignResponse: ...
Web Interface for Ads client
- Usually, we could set up a web interface to help people manage their advertising campaigns.
- This web interface is usually a single page Javascript application that can handle complicated form input, large tables, and rich multimedia content.
Ads Manager
-
Campaign: This represents an overall marketing initiative or a specific marketing goal. A campaign may include various advertisements and target different segments of the audience.
-
Ad: An Ad is the single unit of advertising content that will be delivered to the audience. It could be a banner, video, or any form of media intended to communicate a specific message or promote a product.
-
Ad Set or Line Item: These are intermediate layers between a Campaign and an Ad. An Ad Set or Line Item is used to group similar Ads together, providing more refined control over targeting and delivery. This helps in organizing and managing different aspects of the campaign such as targeting criteria, budget, or scheduling.
-
Creative or Media: This refers to the actual content of an Ad. It could be an image, video, or text that communicates the advertisement’s message. The notion of “Creative” or “Media” allows the content of an Ad to be switched or changed without altering the overall structure of the advertising initiative.
-
Other Auxiliary Entities: These can include various supporting aspects like Account information, Payment Source, Predefined Audience (targeting criteria), etc. These elements are necessary for the functioning of the advertising platform but are not directly part of the Ad content itself.
- Home Tables: Where all the entities like Campaign, Ad are shown. Further editing could be made from here too.
- Creation Flow: A wizard form that helps advertiser (or internal ad ops) to place an order step by step.
- Stats and Reporting: Where advertisers can track the ad performance like impression counts, and also export the data for reference
- Asset Library: A place to manage all the multimedia content that a user has uploaded. Most of the time, there’re dedicated creative studios which help advertisers to make the asset. But, we can also offer some basic media editing web tools to help smaller business that don’t have budget for professional creative service.
- Billing and Payment: To manage the payment source and view the billing information. This part is usually integrated with Braintree APIs to support more funding source.
- Account: To manage role hierarchy and access control of multiple users. Usually, a big organization would have multiple ad accounts. Also, different roles would have different access.
- Audience Manager: This might not be necessary at the beginning. However, it could be convenient for frequent ad buyer to be able to define some reusable audience group so that they don’t need to apply complex targeting logic every time.
- Onboarding: This may be the most critical part of the system at an early stage. A good onboarding experience could increase sign-up significantly.
HNSW + Manas: customized search system
- The Manas index includes an inverted index and a forward index.
- Same as a common inverted index, Manas inverted index stores the mapping from term to list of postings. Each posting records the internal doc ID and a payload.
- To optimize the index size and serving latency, we implemented dense posting list and split posting list, which are two ways to encode the posting list based on the distribution of key terms among all documents. The inverted index is used for candidate generating and lightweight scoring.
- On the other hand, Manas’ forward index stores the mapping from internal doc ID to the actual document. To optimize data locality, the forward index supports column family, similar to HFile. The forward index is used for full scoring.
- provides Approximate Nearest Neighbor (ANN) search as a service, primarily using Hierarchical Navigable Small World graphs (HNSW).
- ANN search retrieves based on embedding similarity. Oftentimes we’d like to do a hybrid search query that combines the two. For example, “find similar products to this pair of shoes that are less than $100, rated 4 stars or more, and ship to the UK.” This is a common problem, and it’s not entirely unsolved, but the solutions each have their own caveats and trade-offs.
APIs
- Definition: Ads APIs are a set of protocols that enable interaction with advertising platforms. While a web interface may allow clients to manage their orders, APIs are needed to persist these changes and to provide data for the UI.
- Use with Agencies: In addition to the in-house use, Ads APIs are meant for advertising agencies that have their own software for tracking campaigns. This allows compatibility with external advertising platforms.
- Design Approach: RESTful APIs are preferred for communication between unfamiliar parties, as they guarantee compatibility and ease of documentation. Other solutions like gRPC and GraphQL are available but may lack wide acceptance.
Additional Considerations
- Budget Control: Managing advertising budgets within the system.
- Content Review Pipeline: Ensuring compliance and quality of content.
- Machine Learning Models: Potential use for auto-tagging and review process acceleration.
- In a digital advertising system, Ads APIs play a crucial role in enabling sophisticated campaign management, access control, billing, and reporting functionality.
- They provide a standardized way for advertisers and agencies to interact with the platform, ensuring compatibility and flexibility.
- Various design patterns, state machines, authentication protocols, and data handling strategies are employed to create a robust and scalable system that meets diverse business needs.
- Whether dealing with internal operations or integrating with third-party services, the considerations laid out in these pillars form the foundation for a successful Ads APIs system.
Ads Index Publisher
- Advertisers can create a campaign and throw in their own image or video ads in our system now. This is great. From now on, we are stepping into the user’s side of the system.
- The text describes the process of delivering ads to users and the challenges in determining which ads are currently active. Here’s the summary along with an explanation of key components:
The Challenge
- Identifying Active Ads: The primary challenge is to identify active ads at a given moment. Querying the database could be time-consuming due to the need to filter by status and join multiple tables (e.g., Campaign, Ad Set, Ad, and Creative).
- Read vs Write Optimization: While the database might be optimized for writes (e.g., updates to specific entities), reading to serve ads requires complex querying across multiple tables. This can be slow and inefficient.
Solution: Index Publisher
To overcome these challenges, the system requires an index publisher to pre-calculate various useful indices for efficient ad serving.
- Index Publisher:
- Functionality: The index publisher pre-calculates indices that save time during ad serving. These indices might include information about active campaigns, creatives, spend limits, ad scheduling, and more.
- Output: It publishes these indices to a storage service, and the ad server loads them into memory periodically.
- Advantages: This allows for quick access to the necessary data without complex, time-consuming queries.
- Managing Dependencies & Complex Validation:
- Use of Spark or Dataflow: The relationships between tables and complex business rule validations require a robust system to manage dependencies. Tools like Spark or Dataflow can be introduced to create multi-stage data pipelines.
- Data Pipeline Stages: These might include stages for filtering active campaigns, validating spend limits, scheduling ads, and more. Each stage processes the data further to refine the set of ads to be served.

- Live Index:
- Purpose: Identifies all live ads in the system.
- Contents: Contains all the essential information required to form an ad response, such as resource location and ad metadata.
- Secondary Indices: May include secondary indices based on targeting rules to filter out irrelevant ads.
- Use: Helps in the auction and filtering process in the ad server.
- Pacing Index:
- Purpose: Deals with pacing status and factors.
- Separation: Kept separate from the live index due to more complex calculations and to make the system more resilient (e.g., live ads can still be served if there’s a pacing issue).
- Feature Index:
- Purpose: Contains ad features for later use by rankers.
- Alternative Storage Options: Can be replaced with a low-latency datastore like Cassandra or an in-memory database like Redis.
Pacing:
- Goal: To distribute the delivery of ads over the lifetime of a campaign evenly, avoiding exhausting all impressions early on or overwhelming the user with the same ad repeatedly (ad fatigue).
- Importance: Acts as a guiding principle for ad delivery, ensuring ads are served in a controlled and consistent manner.
- Simple Approach: Splitting the budget into hourly or minute chunks, filtering out an ad if its budget for that period is exhausted. This method, however, lacks flexibility and can still result in uneven delivery.
- Traditional Approach: Using a PID (Proportional-Integral-Derivative) controller to have more refined control over the pacing. Let’s looke at PID below:
- The text explains the role of a PID (Proportional-Integral-Derivative) controller in managing the pacing of ad delivery:
- Function: The PID controller analyzes the difference between the desired state and current state to determine how much input should be given to the delivery system. If pacing is lagging, it suggests a higher input, resulting in a higher bid and increased chance of winning the ad opportunity.
- Current State: Easily determined by examining current metrics like total impressions and clicks.
- Desired State: Initially, a linear projection from 0 to the total desired impressions or clicks over time can be used. The rate of delivered impressions per minute is then used to reflect the desired state.
- Adjustments: The PID controller might start slowly, or its fluctuations may be significant. To remedy this, additional multipliers can be added to the formula.
- Pacing Factor: This derived value ensures the smooth delivery of ads, with adjustments made as needed to keep the delivery rate in line with the desired rate.
- Advanced Techniques: Specialized pacing factors and techniques can be used for specific challenges, like ensuring even distribution across different ad server machines in a distributed system, or satisfying specific frequency requirements.
Auction
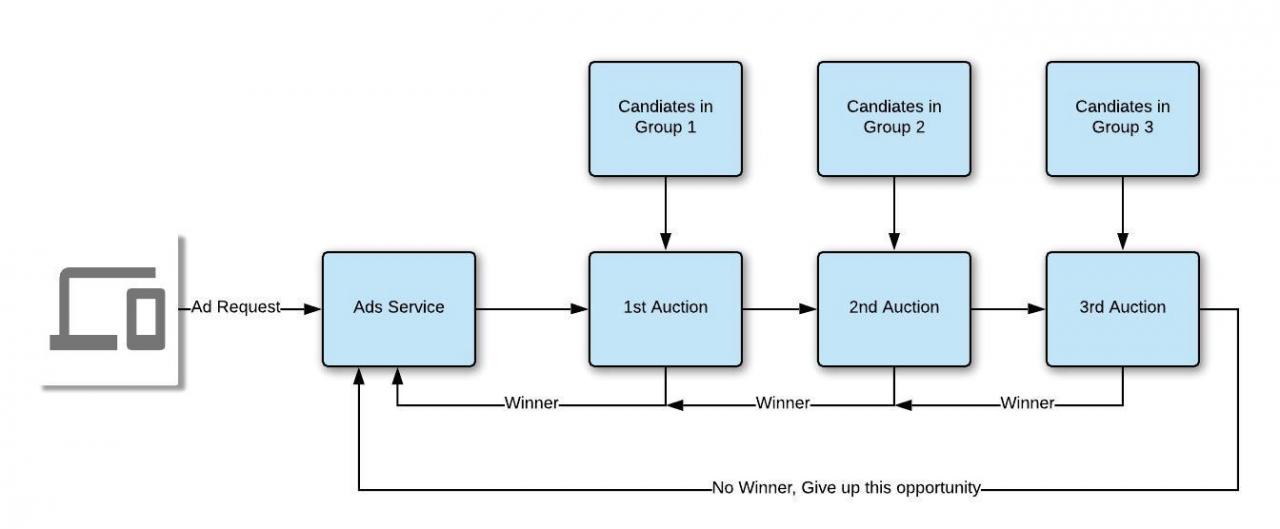
- Auction in Ad Systems: Auction is at the core of the ad engine. Different ads are put up for bid, and the one with the highest bid is displayed to the user.
- Pacing Factor: The bid value is multiplied by a pacing factor. The more urgent an ad is, the higher the pacing factor, leading to a higher bid.
- Second-Price Auctions: This common strategy allows the winning bidder to pay slightly less than their original offer, paying the second-highest bidder’s price plus a small increment.
- Total Bid Calculation: The total bid is calculated using the formula
Total Bid = k * EAV + EOV, wherekis the pacing factor,EAVis the estimated advertiser value, andEOVis the estimated organic value.- Advertiser Value (EAV): This depends on the advertising goal and is calculated differently for different metrics like clicks.
- Organic Value (EOV): This represents the benefit to the platform or user experience, possibly including negative weights for undesirable events like ad skipping.
- Complex Systems: More intricate formulas can be developed to suit different business priorities. The mathematics chosen shapes the essence of the ad engine.
- Actual Auction Engine: When a request arrives, candidate ads are sorted to find the highest bidder. Candidates may be grouped into priority levels, leading to a waterfall-like system where the request cascades through groups. A minimum bid price may be set to consider delivery costs.
-
Layered Auctions and Generalized Second Price Auction (GSP): For auctioning multiple related items simultaneously, GSP can be implemented. It’s a non-truthful mechanism where each winning bidder pays the price bid by the next highest bidder.
- In conclusion, the auction section details how ads are selected to be displayed to users. It involves complex mechanisms, bid calculations, and considerations for various advertising goals and platform benefits. Different strategies and systems, including second-price and generalized second-price auctions, allow for intricate control over ad selection and pricing.
Ranking
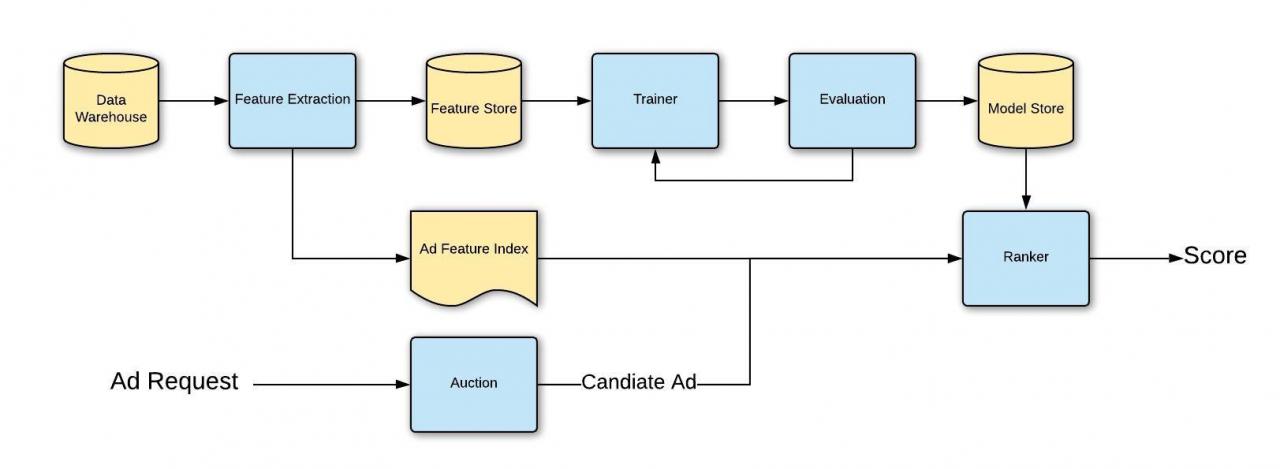
-
Purpose of Ads Ranking System: It selects the most suitable ad for a user considering their past behavior, interests, and the ad’s historical performance. The system’s calculation takes into account the maximum bid price, event probability, and the weight of organic values.
- Extension into Machine Learning (ML): Instead of simply using hardcoded scores, the system can be extended into an ML pipeline to improve performance and profit. This involves several key steps:
- Feature Engineering: Data cleaning and aggregation are carried out to extract useful information (features) such as context, demographics, engagement, ad specifics, fatigue factors, and content details.
- Batch Transformation: Tools like Dataflow, Spark, or Flint can transform these features, placing them into a feature store.
- Model Training: Techniques like Sparse Logistic Regression and Gradient Boosting Decision Tree are used. Frameworks like TensorFlow, XGBoost, or scikit-learn can be utilized for building a generic trainer.
- Model Deployment: Once validated, the model is published to a remote repository, and a subset of the production fleet picks up the new model to verify performance.
- Real-time Data Handling: A feature index is created from real-time data. The ranker refers to this index during runtime for metrics like ad stats and user engagement.
- Central Scheduling System: This orchestrates all tasks in the production machine learning pipeline. It keeps track of job information and manages the workflow DAG. While this service can be built from scratch, using container operations in tools like Airflow or Kubeflow is also a viable option.
- In summary, the ads ranking system uses both hard-coded algorithms and a machine learning pipeline to identify the best ad to show a user. By incorporating data on user behavior, context, and ad performance, and employing a sophisticated ML process, the system aims to maximize ROI for advertisers.
Forecasting
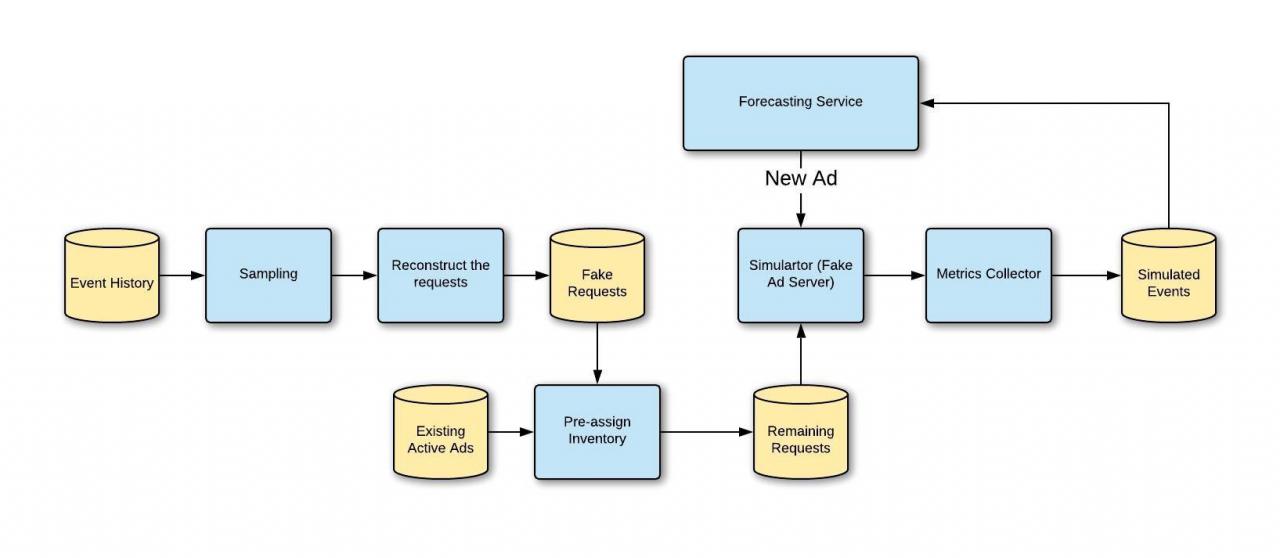
-
Forecasting, specifically Inventory Forecasting, in the context of an ad system, is a predictive mechanism to estimate the number of impressions for specific targeting at a given time. Here’s a summary:
-
Purpose: Inventory Forecasting assists in determining how much future inventory can be booked, improves the pacing system by adjusting to actual and predicted traffic, and aids in new feature testing and debugging.
-
Naive Implementation: The simple approach involves counting potential future inventory by analyzing historical data and categorizing them into buckets. While straightforward, this method may be unscalable as it requires separate maintenance from the production logic.
-
Robust Solution via Simulation: A more accurate method involves simulating the production serving path. This entails taking a new ad, pretending it’s live, and using historical impressions to “serve” it. This reflects future behavior accurately but might be time-consuming if the traffic is vast.
- Improving Simulation Performance: If a full simulation is too slow, several techniques can enhance performance:
- Downsampling Historical Requests: By taking only a fraction of the impressions per user, the process can be made faster.
- Turning Off Unnecessary Server Functionalities: Disabling certain features that aren’t needed in the simulation can reduce runtime.
- Separate Inventory Assignment for Existing Ads: Reusing recent forecasting data and preparing separate assignments can streamline the process.
- Parallel Simulation: By handling only one new ad at a time without interference from others, the simulation can run on multiple machines in parallel.
- Other Benefits of Simulation: Besides helping to understand inventory for a new ad, simulation provides other advantages:
- Event Estimation: Simulated events can predict the potential clicks or app installs for a given ad.
- Reach and Frequency Booking System Development: Simulations can help build systems to guarantee reaching a specific number of users a certain number of times, and ensure that future simulations account for booked impressions to avoid overbooking.
- In essence, Inventory Forecasting offers critical insights into future ad inventory, pacing, and performance. Though there’s a simple way to implement it, utilizing simulation provides a more precise and scalable solution, with opportunities for fine-tuning and parallel processing to enhance efficiency.
Targeting
-
Targeting in advertising is the process of defining rules for where an ad should be delivered, and this can range from very broad audiences (e.g., for brand awareness) to small niche markets (e.g., specific zip codes or hobbies). Here’s a summary of the concept:
-
Importance: Advertisers often have specific opinions about who should see their ads, and the targeting audience can vary widely depending on the advertising goals.
-
Structural Definition: Targeting rules may involve complex AND/OR logic, and INCLUDE/EXCLUDE conditions. An example might include targeting teachers in the U.S.
-
Human vs. Machine Reading: While the structure may be easy for humans to understand, it can be challenging for the ad server to determine a match.
- Solutions:
- Flattening JSON: One way to deal with this is to flatten the nested JSON into a list, making it easier to loop through and find matches during candidate filtering.
- Boolean Expression Matching Algorithm: This approach leverages algorithms like K-Index, Interval Matching, and BE-Tree to perform high throughput, low latency matching, and is used in various fields including e-commerce and digital advertising.
-
User Profile Connection: Understanding the target audience is only part of the equation. The targeting must be associated with the end user. This requires a user profile compiled from historical data like purchase and browsing history.
-
Privacy Concerns: This profiling process, often seen in platforms like Facebook, can raise privacy issues, as it uses personal data to generate profits without always informing the user.
- Third-Party Integration: If sufficient data isn’t available to create a detailed end-user profile, integration with third-party data companies can provide more insights.
- In summary, targeting is a vital aspect of ad delivery, necessitating clear rules and robust algorithms for effective matching. The process can be complex, involving both logical operations and user profiling, and may also raise ethical considerations related to privacy.
Ad Server
- The ad server is the culmination of various components that move an ad from the advertiser to the end user. Here’s a summary of its functionality and key considerations:
Request Anatomy
- User Initialization: The client (web or mobile) starts by notifying the ad server of a new active user, allowing time to load the user profile into a memory database for quick access later.
- Ad Request: The client sends an ad request, asking where to load the ad content, whether text or static file (via CDN location).
- Ad Filtering: Context information and the live ad index are used to filter ads that don’t match targeting criteria, and other filters like frequency or budget caps are applied.
- Auction: The ad candidates are sent to auction, and the winner is recorded in the metrics table, with information sent back to the client to prepare the ad.
- Ad Display and Tracking: The ad is displayed, and a tracking event is sent back to the metrics collector.
Reliability
- Critical Importance: Since the ad server is at the forefront of the ad business, even a small problem can lead to failure in ad delivery and a loss of revenue.
- Fallback Plans: If a non-core module fails (e.g., the ranking system), a backup plan or default model must be in place.
- Quick Rollback and Redeployment: A quick response to total system failure is crucial, potentially involving canary deployment or warm backup servers.
Latency
- Speed Requirements: To serve ads quickly, the index is loaded into memory. However, memory size is usually limited due to various factors like cost-efficiency or physical limitations.
-
Index Splitting: If the index grows too large, it might need to be split into groups, either by region (with potential hard region limitations) or via a dispatcher querying multiple machines with different shards of the index.
- The ad server is a complex system that orchestrates the delivery of ads to end users. It must handle requests with efficiency, ensure high reliability, and manage latency concerns, all while taking into consideration the various limitations and requirements of the system. The design of the ad server must carefully balance these factors to provide a seamless and effective advertising experience.
Metrics
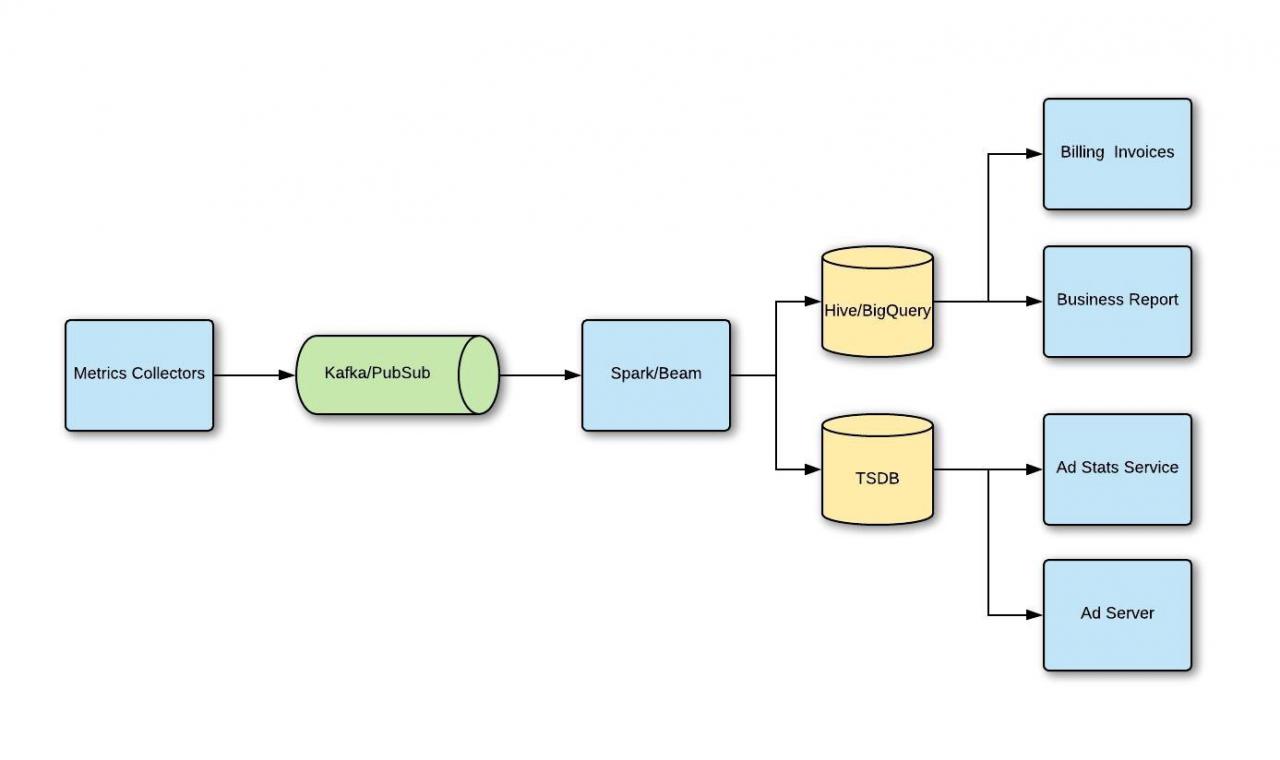
-
The metrics and stats service is a critical component in the advertising system, monitoring the performance of ads and aiding in business analysis. Here’s a summary of its core elements:
- Two Types of Workloads
- Business Analytics: This involves pulling large amounts of historical data to find patterns, create reports, and generate invoices and bills. It usually requires storing raw data in an OLAP database or cloud analytics software like BigQuery.
- Real-Time Stats: Advertisers are keen to know the real-time performance of their ads. This requires storing data in a Time Series Database (TSDB), such as OpenTSDB, InfluxDB, Graphite, or a custom-built engine. The main concern is the granularity and retention period, aiming for small granularity and low latency.
- Infrastructure Design
- Unified Data Pipeline: Storing metrics in different places doesn’t mean two separate pipelines are needed. A typical design includes generic metrics collectors to receive all data, a message queue system like Kafka to stream events, and a processing application like Spark to transform and aggregate the data.
-
Dual Routing: The final data is routed to both TSDB and OLAP DB to serve different needs.
- Ad Stats Considerations
- Avoiding Design Flaws: Inconsistent or bad design in the data pipeline can lead to severe issues downstream. Although it’s hard to foresee all future requirements, the system should be designed with flexibility in mind.
-
Long-Term Aggregation: Some statistical tasks may require data spanning several days or weeks or from different stages of transformation. This should be considered during the design process.
- Metrics and stats service in an advertising system serve dual purposes, catering to business analysts and advertisers with different needs. A flexible and efficient design that allows for both historical analysis and real-time performance tracking is essential. By carefully considering the design, granularity, latency, and future extensibility, an effective metrics system can be built to provide valuable insights and support decision-making within the advertising ecosystem.