Distilled - Google Docs and Drive
- Design
- Google Drive
- Step 1 - Understand the problem and establish design scope**
- Step 2 - Propose high-level design and get buy-in**
- Step 3: Design deep dive
- Step 4: Wrap up
- Further Reading
Design
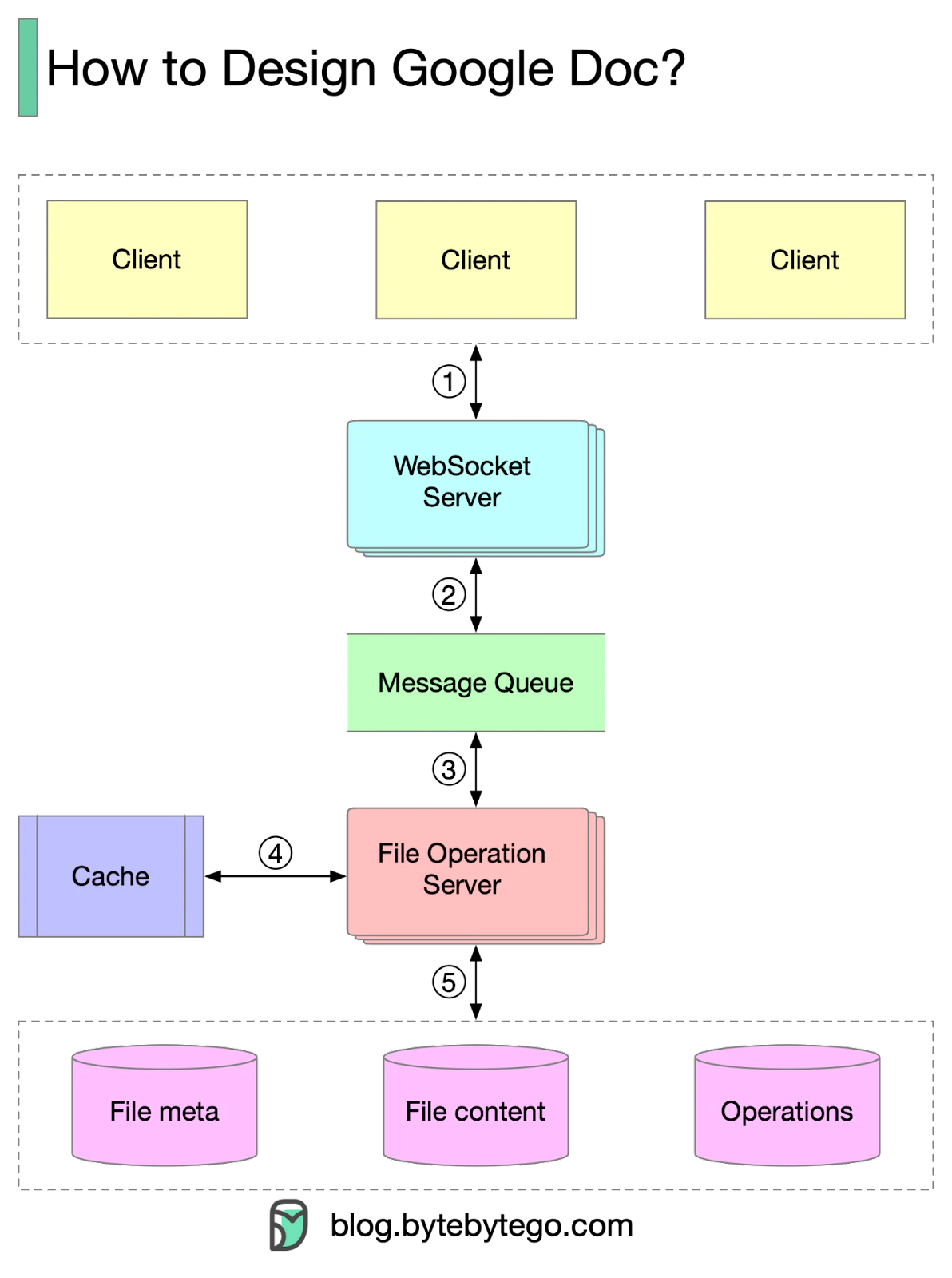
-
Clients send document editing operations to the WebSocket Server.
-
The real-time communication is handled by the WebSocket Server.
-
Documents operations are persisted in the Message Queue.
-
The File Operation Server consumes operations produced by clients and generates transformed operations using collaboration algorithms.
-
Three types of data are stored: file metadata, file content, and operations.
-
One of the biggest challenges is real-time conflict resolution. Common algorithms include:
-
Operational transformation (OT)
-
Differential Synchronization (DS)
-
Conflict-free replicated data type (CRDT)
-
-
Google Doc uses OT according to its Wikipedia page and CRDT is an active area of research for real-time concurrent editing.
Google Drive
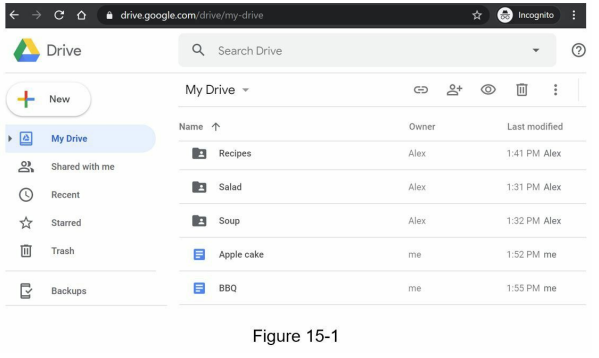
- Google Drive is a popular file storage and synchronization service.
- It allows users to store documents, photos, videos, and other files in the cloud.
- Files stored in Google Drive can be accessed from any computer, smartphone, or tablet.
- Google Drive provides the ability to easily share files with others, including friends, family, and coworkers.
- The service is available through a web browser interface (shown in Figure 15-1) and a mobile application interface (shown in Figure 15-2).
- Google Drive is integrated with other Google services, providing a seamless user experience across different platforms.
- Users can organize their files into folders and subfolders for efficient file management.
- Features such as search functionality and file versioning enhance the usability of Google Drive.
- Google Drive offers different storage plans, including free storage and paid storage options with larger storage capacities.
- The service ensures data security and privacy by implementing encryption and access controls.
Step 1 - Understand the problem and establish design scope**
Designing a Google Drive is a big project, so it is important to ask questions to narrow down the scope.
- Candidate: What are the most important features?
- Interviewer: Upload and download files, file sync, and notifications.
- Candidate: Is this a mobile app, a web app, or both?
- Interviewer: Both.
- Candidate: What are the supported file formats?
- Interviewer: Any file type.
- Candidate: Do files need to be encrypted?
- Interviewer: Yes, files in the storage must be encrypted.
- Candidate: Is there a file size limit?
- Interviewer: Yes, files must be 10 GB or smaller.
- Candidate: How many users does the product have?
- Interviewer: 10M DAU.
In this chapter, we focus on the following features:
- Add files: The easiest way to add a file is to drag and drop a file into Google Drive.
- Download files.
- Sync files across multiple devices: When a file is added to one device, it is automatically synced to other devices.
- See file revisions.
- Share files with your friends, family, and coworkers.
- Send a notification when a file is edited, deleted, or shared with you.
Features not discussed in this chapter include:
- Google doc editing and collaboration: Google Docs allows multiple people to edit the same document simultaneously. This is out of our design scope.
Other than clarifying requirements, it is important to understand non-functional requirements:
- Reliability: Reliability is extremely important for a storage system. Data loss is unacceptable.
- Fast sync speed: If file sync takes too much time, users will become impatient and abandon the product.
- Bandwidth usage: If a product takes a lot of unnecessary network bandwidth, users will be unhappy, especially when they are on a mobile data plan.
- Scalability: The system should be able to handle high volumes of traffic.
- High availability: Users should still be able to use the system when some servers are offline, slowed down, or have unexpected network errors.
Back of the envelope estimation
- Assume the application has 50 million signed up users and 10 million DAU.
- Users get 10 GB free space.
- Assume users upload 2 files per day. The average file size is 500 KB.
- 1:1 read to write ratio.
- Total space allocated: 50 million * 10 GB = 500 Petabyte
- QPS for upload API: 10 million * 2 uploads / 24 hours / 3600 seconds = ~ 240
- Peak QPS = QPS * 2 = 480
Step 2 - Propose high-level design and get buy-in**
- Instead of showing the high-level design diagram from the beginning, we will use a slightly different approach. We will start with something simple: build everything in a single server. Then, gradually scale it up to support millions of users. By doing this exercise, it will refresh your memory about some important topics covered in the book.
Let us start with a single server setup as listed below:
- A web server to upload and download files.
- A database to keep track of metadata like user data, login info, files info, etc.
-
A storage system to store files. We allocate 1TB of storage space to store files.
- We spend a few hours setting up an Apache web server, a MySQL database, and a directory called “drive/” as the root directory to store uploaded files. Under the “drive/” directory, there is a list of directories, known as namespaces. Each namespace contains all the uploaded files for that user. The filename on the server is kept the same as the original file name. Each file or folder can be uniquely identified by joining the namespace and the relative path.


- You pull an all-nighter to set up database sharding and monitor it closely. Everything works smoothly again.
- You have stopped the fire, but you are still worried about potential data losses in case of storage server outage.
- Your backend guru friend Frank suggests that leading companies like Netflix and Airbnb use Amazon S3 for storage.
- Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance.
- After researching, you decide to store files in S3.
- Amazon S3 supports same-region and cross-region replication.
- A region is a geographic area where Amazon Web Services (AWS) has data centers.
- Data can be replicated within the same region or across regions to ensure redundancy and availability.
- A bucket is like a folder in file systems.
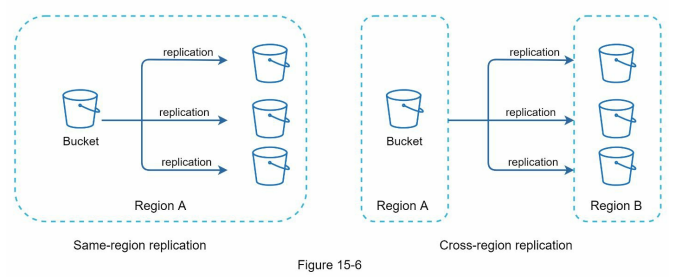
- After putting files in S3, you can finally have a good night’s sleep without worrying about data losses.
- To prevent similar problems in the future, you decide to research areas for improvement.
- Here are a few areas you find:
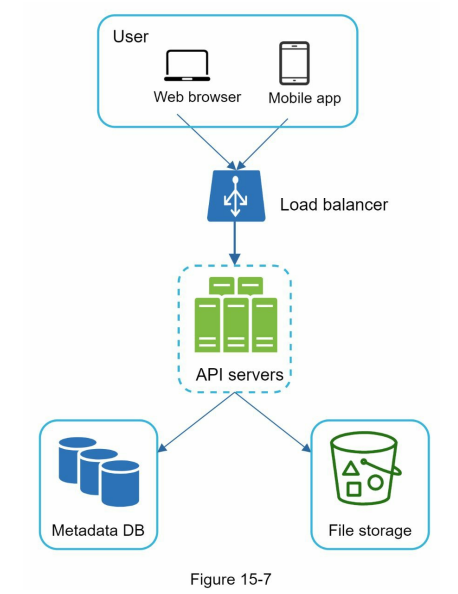
- Load balancer: Add a load balancer to distribute network traffic and ensure even distribution. It can also redirect traffic if a web server goes down.
- Web servers: With the load balancer in place, easily add or remove web servers based on traffic load.
- Metadata database: Move the database out of the server to avoid a single point of failure. Set up data replication and sharding for availability and scalability.
- File storage: Use Amazon S3 for file storage. Replicate files in two separate geographical regions for availability and durability.
- After implementing these improvements, you have successfully decoupled web servers, metadata database, and file storage from a single server. The updated design is shown in Figure 15-7.
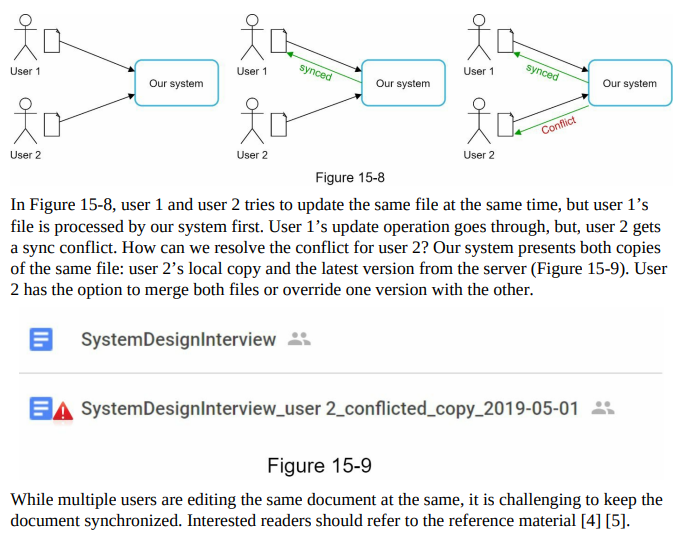
Sync conflicts
- For a large storage system like Google Drive, sync conflicts happen from time to time.
- When two users modify the same file or folder at the same time, a conflict happens.
- How can we resolve the conflict? Here is our strategy: the first version that gets processed wins, and the version that gets processed later receives a conflict. Figure 15-8 shows an example of a sync conflict.
High level design
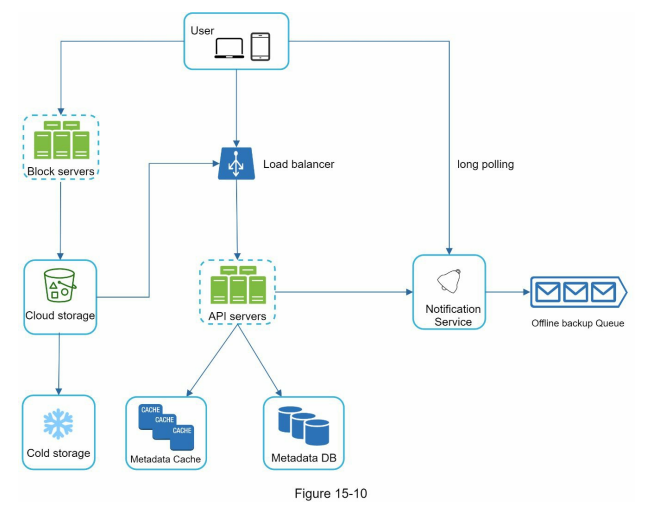
- User: Users access the application via browser or mobile app.
- Block servers: Upload blocks to cloud storage. Block storage splits files into blocks with unique hash values stored in the metadata database. Blocks are treated as independent objects and stored in the storage system (S3). Blocks are joined to reconstruct files.
- Cloud storage: Files are split into smaller blocks and stored in cloud storage.
- Cold storage: Designed for storing inactive data that is not accessed for a long time.
- Load balancer: Distributes requests evenly among API servers.
- API servers: Responsible for user authentication, managing user profiles, updating file metadata, etc.
- Metadata database: Stores metadata of users, files, blocks, versions, etc. Does not contain actual file data.
- Metadata cache: Caches some metadata for fast retrieval.
- Notification service: Publisher/subscriber system that notifies clients of file additions, edits, and removals. Clients can pull the latest changes.
- Offline backup queue: Stores file change information for offline clients to sync when they come online.
- Deep dive: Detailed examination of complex components will be discussed separately.
Step 3: Design deep dive
- Block servers:
- Delta sync: Only modified blocks are synced instead of the whole file, reducing network traffic.
- Compression: Blocks are compressed using appropriate algorithms based on file types to minimize data size.
-
Upload flow: Block servers receive files from clients, split them into blocks, compress and encrypt the blocks, and transfer only modified blocks to the storage system.
-
Download flow: Clients request files from the storage system, which retrieves the necessary blocks and sends them to the clients for reconstruction.
-
Notification service: Notifies relevant clients when files are added, edited, or removed elsewhere.
-
Save storage space: Compression algorithms are used to reduce the size of blocks, saving storage space.
- Failure handling: The system should be resilient to failures, ensuring data integrity and availability during server outages or errors.
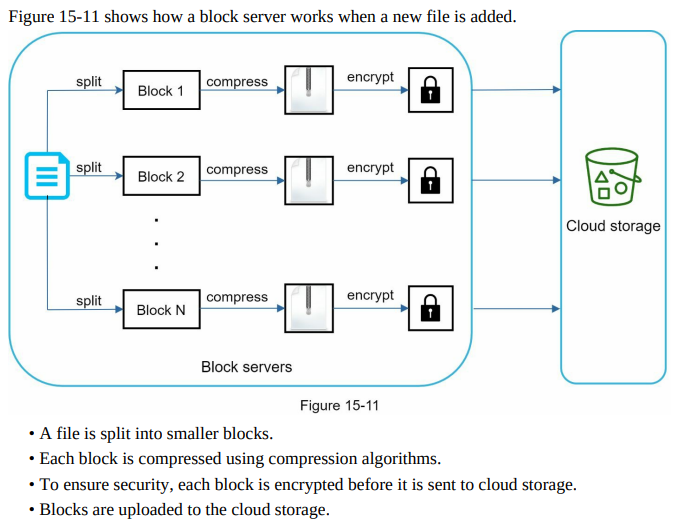
- A file is split into smaller blocks.
- Each block is compressed using compression algorithms.
- To ensure security, each block is encrypted before it is sent to cloud storage.
-
Blocks are uploaded to the cloud storage.
- Figure 15-12 illustrates delta sync, meaning only modified blocks are transferred to cloud storage. Highlighted blocks “block 2” and “block 5” represent changed blocks. Using delta sync, only those two blocks are uploaded to the cloud storage.
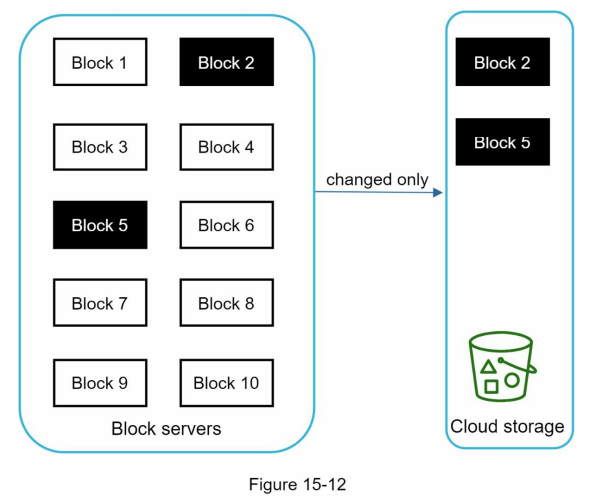
Certainly! Here’s the reformatted version:
- High consistency requirement:
- Strong consistency is required by default to ensure files are shown consistently across different clients.
- Strong consistency is needed for metadata cache and database layers.
- Memory caches:
- By default, memory caches adopt an eventual consistency model, where different replicas may have different data.
- To achieve strong consistency, the following steps are taken:
- Ensure data consistency between cache replicas and the master.
- Invalidate caches on database write to synchronize cache and database values.
- Achieving strong consistency:
- Relational databases are chosen in the design because they natively support the ACID (Atomicity, Consistency, Isolation, Durability) properties.
- NoSQL databases, which do not support ACID properties by default, require programmatically incorporating ACID properties in synchronization logic.
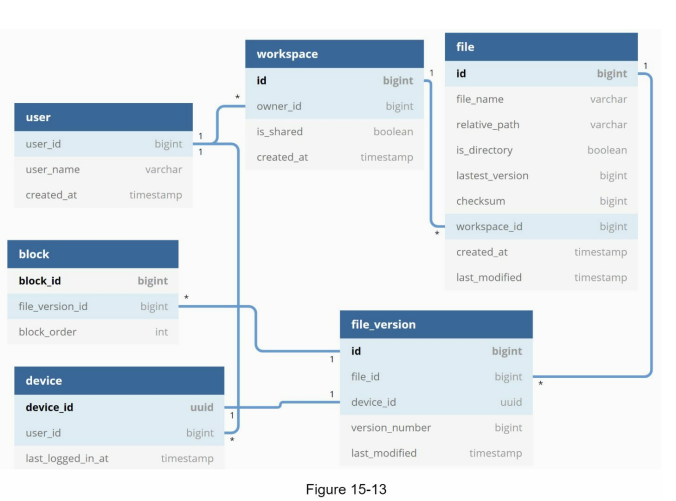
- Metadata database:
- User: Contains basic user information (username, email, profile photo, etc.).
- Device: Stores device information, with push_id used for mobile push notifications. A user can have multiple devices.
- Namespace: Represents the root directory of a user.
- File: Stores information related to the latest file.
- File_version: Maintains the version history of a file. Existing rows are read-only to preserve file revision integrity.
- Block: Stores information related to a file block. Blocks are joined in the correct order to reconstruct a file of any version.
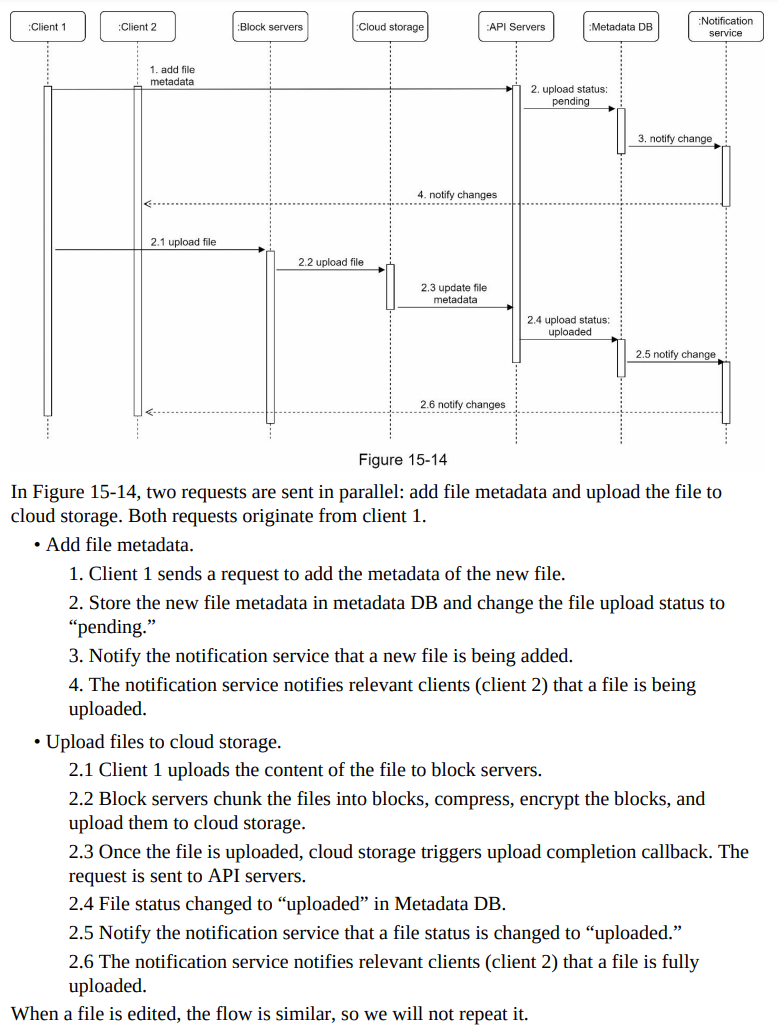
- Upload flow
- Let us discuss what happens when a client uploads a file. To better understand the flow, we draw the sequence diagram as shown in Figure 15-14.
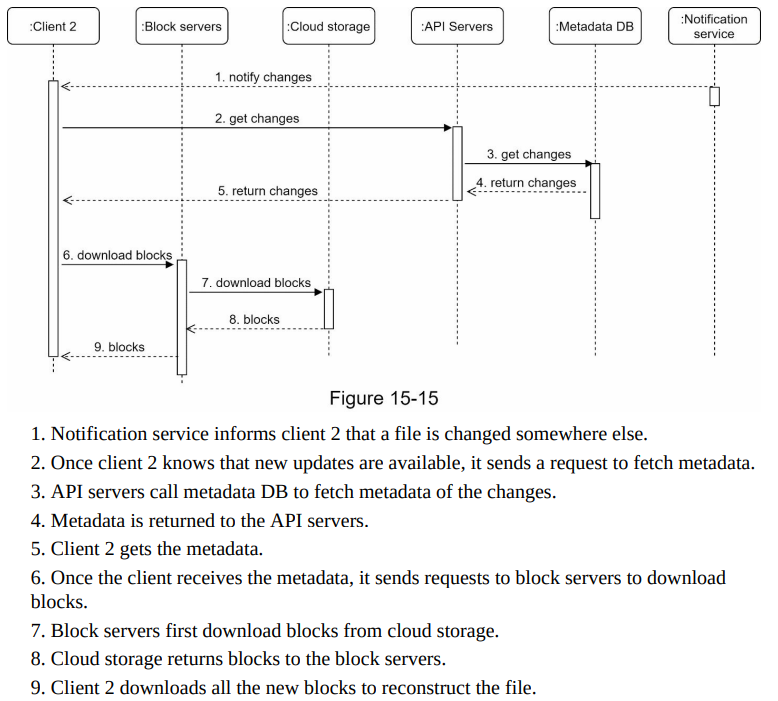
- Download flow:
- Triggered when a file is added or edited elsewhere.
- Client awareness:
- Online client: Notification service informs the client about changes made elsewhere, prompting it to pull the latest data.
- Offline client: Changes are saved to the cache. When the client reconnects, it pulls the latest changes.
- Steps:
- Client requests metadata from API servers.
- Client downloads blocks to construct the file.
- Diagram: Figure 15-15 provides a detailed flow, with only the most important components shown due to space constraints.
- Notification service:
- Purpose: Inform clients of local file mutations to maintain file consistency.
- Options for data transfer:
- Long polling: Dropbox uses this method.
- WebSocket: Provides a persistent bi-directional connection between client and server.
- Choice: Long polling selected for Google Drive due to:
- Unidirectional communication: Server sends file change information to clients, no need for bidirectional communication.
- Infrequent notifications: Notifications are sent sporadically, not requiring real-time, burst data transfer.
- Long polling process:
- Each client establishes a long poll connection to the notification service.
- If file changes are detected, the client closes the long poll connection.
- Closing the connection triggers the client to connect to the metadata server for downloading the latest changes.
- After receiving a response or reaching the connection timeout, the client sends a new request to maintain an open connection.
Save storage space:
- Techniques to reduce storage costs:
- De-duplicate data blocks:
- Eliminate redundant blocks at the account level by comparing hash values.
- Intelligent data backup strategy:
- Set a limit on the number of versions to store.
- Keep valuable versions only, giving more weight to recent versions.
- Experiment to find the optimal number of versions to save.
- Move infrequently used data to cold storage:
- Use cold storage options like Amazon S3 Glacier, which is cheaper than S3.
- De-duplicate data blocks:
Failure Handling:
- Load balancer failure:
- Secondary load balancer becomes active and takes over the traffic.
- Block server failure:
- Other servers handle unfinished or pending jobs.
- Cloud storage failure:
- Fetch files from replicated copies in different regions.
- API server failure:
- Load balancer redirects traffic to other API servers.
- Metadata cache failure:
- Replicated cache servers ensure data availability.
- Metadata DB failure:
- Promote a slave to act as the new master and bring up a new slave node.
- Master down:
- Promote a slave to act as the new master and bring up a new slave node.
- Slave down:
- Use another slave for read operations and replace the failed one.
- Notification service failure:
- Clients must reconnect to a different server due to long poll connection loss.
- Reconnecting with all lost clients is a relatively slow process.
- Offline backup queue failure:
- Replicated queues require consumers to re-subscribe if a queue fails.
Step 4: Wrap up
- Proposed system design for Google Drive:
- Supports strong consistency, low network bandwidth, and fast sync.
- Includes file metadata management and file sync flows.
- Notification service keeps clients updated with file changes using long polling.
- No perfect solution:
- Design must fit unique constraints of each company.
- Understanding tradeoffs in design and technology choices is crucial.
- Different design choices:
- Direct upload to cloud storage from the client:
- Faster file upload, transferring file only once.
- Implementation challenges on different platforms.
- Security concerns with client-side encryption.
- Direct upload to cloud storage from the client:
- Evolution of the system:
- Separate presence service for online/offline logic.
- Allows easy integration of online/offline functionality by other services.