Distilled • Top N Trending Topics/Songs
- Overview
- Design Goals/Requirements
- Scale Estimation and Performance/Capacity Requirements
- System APIs
- High Level System Design
- Detailed Component Design
Overview
- This question is very similar to designing the system for top N trending topics.
Design Goals/Requirements
- Functional requirements:
- Get the top N songs for a user over the past X days.
- Assume that the popularity of a song can be determined by the frequency of the song being listened to in the past.
- Non-functional requirements:
- Minimum latency: The suggestions should appear in real-time. The user should be able to see the suggestions within 200ms.
- High availability: The final design should be highly available.
- Eventual consistency (due to CAP theorem): As we know from the CAP theorem, that we can have either high availability or high consistency, thus we will aim for an eventually consistent system.
- Write-heavy service: Our system will be write heavy in nature as more users will be listening to songs rather than fetching the top-N songs that they have heard so far, thus the number of write requests will be far greater than read requests.
Scale Estimation and Performance/Capacity Requirements
- Some back-of-the-envelope calculations based on average numbers.
Traffic estimates
- Monthly Active Users (MAUs): 250M.
- Number of songs listened to daily: 1B.
- Read requests for the top N songs: 200.
System APIs
- Once we have finalized the requirements, it’s always a good idea to define the system APIs. This should explicitly state what is expected from the system. These would be running as microservices on our application servers.
- We can have SOAP or REST APIs to expose the functionality of our service.
-
The following could be the definition of the read API to fetch the top N songs over the past X days:
getTopSongs(user_id, maximum_results_to_return, timestamp)- Parameters:
user_id (number):The ID of the user for whom the system will generate the top-N songs list.maximum_results_to_return (number): Number of posts to return.timestamp (number):The current timestamp to send places with timestamps associated greater than the current time – can also optionally send the ID (if the ID is encoded based on the timestamp) of the latest comment to fetch places greater than this ID).
- Returns: (JSON) Returns a JSON object containing a list of top-N songs.
- Parameters:
- The following could be the definition of the write API to record when the user listens to a song:
addSong(user_id, song_id, timestamp)
- Parameters:
user_id (number):The ID of the user for whom the system will generate the top-N songs list.song_id (number): ID of the song played.timestamp (number):The current timestamp to send places with timestamps associated greater than the current time – can also optionally send the ID (if the ID is encoded based on the timestamp) of the latest comment to fetch places greater than this ID).
- Returns: (Bool) Success
High Level System Design
- Steps Involved:
- Whenever the user listens to a song, we will log it on the application server.
- A background async process will read the data from these logs, do some initial aggregation, and send the data for further processing.
- The aggregated data will be sent to a distributed messaging system like Apache Kafka.
- Then, we can divide our system into two paths, Fast Path or Slow Path.
Fast Path
- A data structure called Count-Min Sketch will be used.
- Count-Min Sketch is a probabilistic data structure used for approximate counting and frequency estimation in streaming data. It is particularly useful in scenarios where memory usage is limited or when it is impractical to store the entire dataset.
- The Count-Min Sketch data structure consists of an array of counters and a set of hash functions. The sketch is initialized with all counters set to zero. When an item is encountered in the stream, it is hashed using the set of hash functions, and the corresponding counters are incremented.
- Key characteristics of the Count-Min Sketch include:
- Approximate counting: The sketch provides an estimate of the frequency of an item in the stream. However, due to the limited number of counters, collisions may occur, resulting in overestimation.
- Hash functions: The hash functions are used to determine the indices of the counters to increment. Multiple hash functions are employed to minimize collisions and improve accuracy.
- Minimum operation: To estimate the frequency of an item, the sketch takes the minimum value among the counters corresponding to the hashed indices. This operation ensures that the estimate is not inflated by collisions.
- Trade-off between accuracy and memory: The accuracy of the Count-Min Sketch improves with more counters, but this also increases the memory requirements.
- It will calculate the top $N$ songs approximately, and the results will be available within seconds.
Slow Path
- A MapReduce pipeline will be run to calculate the top $N$ songs precisely.
- This may take minutes or hours for the results to be made available.
- A MapReduce pipeline refers to a data processing approach and framework for distributed computing. It is commonly used for large-scale data processing tasks, such as batch processing, data transformation, and analytics, across clusters or distributed systems.
- In a MapReduce pipeline, the data processing is divided into two main phases: the Map phase and the Reduce phase.
- Map Phase: In this phase, the input data is divided into smaller chunks and processed in parallel across multiple nodes in the cluster. Each node applies a “map” function to the input data, which transforms it into a set of key-value pairs. The map function can perform filtering, sorting, extraction, or any other required data transformations.
- Reduce Phase: Once the Map phase is complete, the intermediate key-value pairs generated by the map functions are shuffled and grouped based on their keys. The grouped data is then processed in parallel across nodes using a “reduce” function. The reduce function aggregates and combines the values associated with each key, producing the final output of the pipeline.
Choose the right approach
- Choose either path depending upon the system constraints that whether we will need near real-time results or if some delay is acceptable to achieve accuracy.
Detailed Component Design
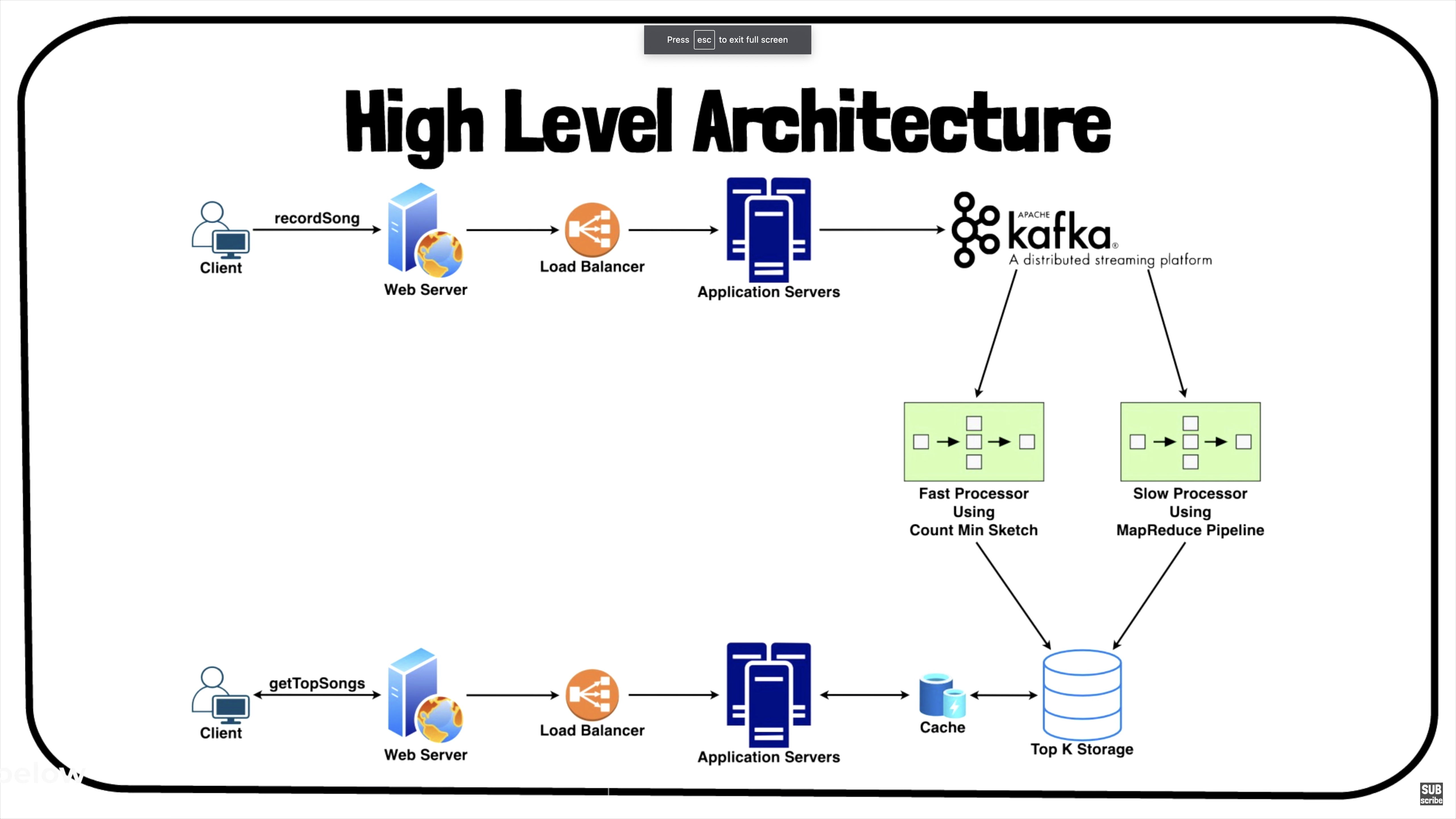
- It includes various components, such as:
- Fast path and slow patch
- Apache Kakfa for distributed messaging.
- Application servers to run system APIs as microservices.
- Suggestions ranking service.
- Caches for fast retrieval.
- Load balancers to distribute load as evenly as possible, and ensure crashed servers are taken out of the load distribution loop.