Overview
- On Pi day (3/14/2023), OpenAI unveiled their latest GPT model, GPT-4, which boasts a multimodal interface that takes in images and texts and emits out a text response.
- GPT-4 was trained on a large dataset of text from the internet and fine-tuned using RLHF.
- The GPT-4 Technical Report gives us a glimpse of how GPT-4 works and it’s capabilities and that is what I have explained below.
Capabilities of GPT-4
- Let’s do a quick refresher on GPT:
- During pre-training, the model is trained to predict the next word in a sequence of text given the previous words.
- Once the model is pre-trained, it can be fine-tuned on a specific task by adding a few task-specific layers on top of the pre-trained model and training it on a smaller dataset that is specific to the task.
- While the paper is lacking on technical details about GPT-4, we can still fill in the gaps with information we do know.
- As the paper states, “GPT-4 is a Transformer-style model pre-trained to predict the next token in a document, using both publicly available data (such as internet data) and data licensed from third-party providers.” (source)
- Like it’s previous models, it was trained to predict the next word in a document or from publicly available data.
- Another piece of information we glean from this technical analysis is that GPT-4 uses Reinforcement Learning from Human Feedback (RLHF) much like InstructGPT has.
- GPT-4 uses RLHF to closely “align” the user’s intent for a given input and helps facilitate trust and safety in its responses.
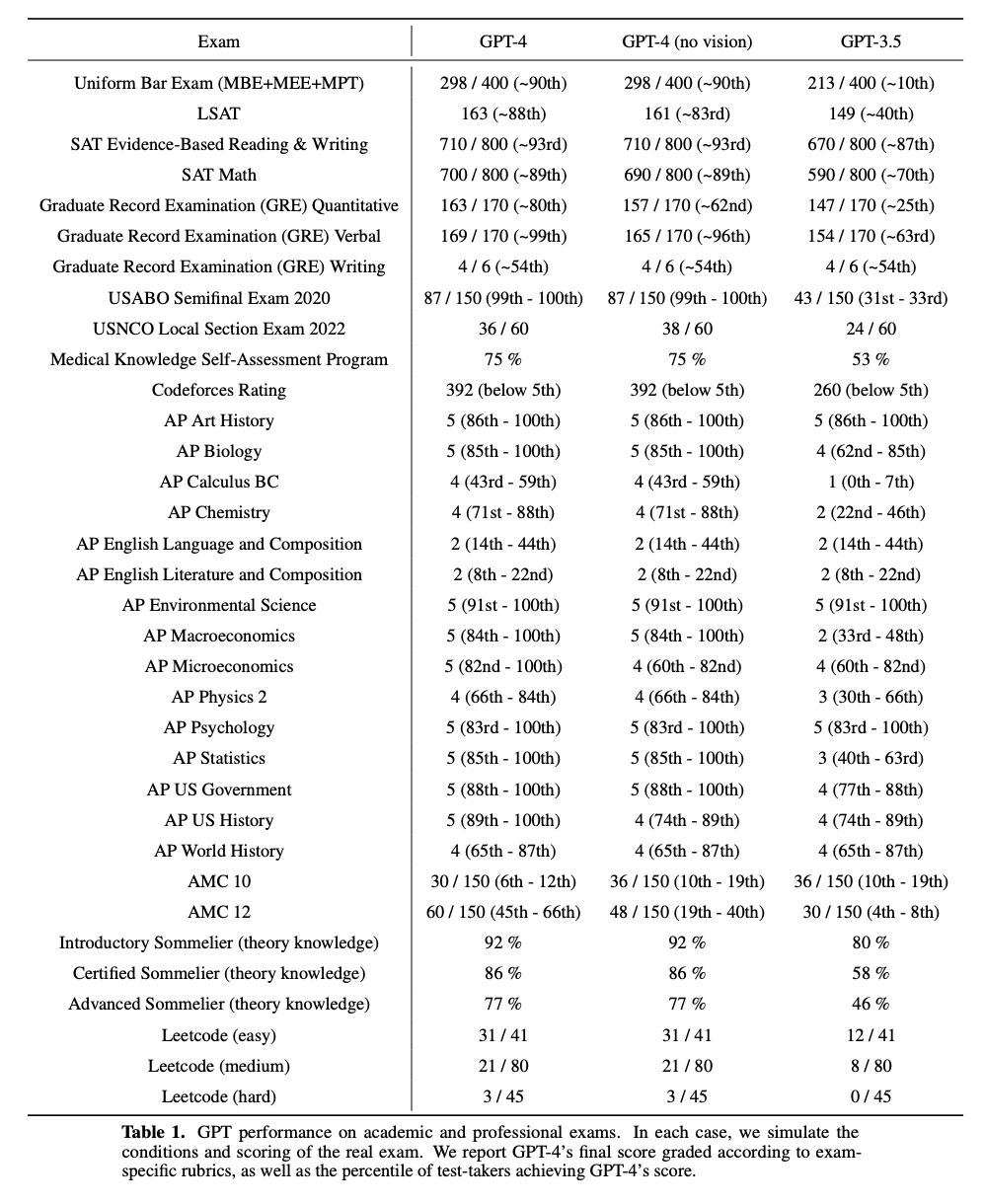
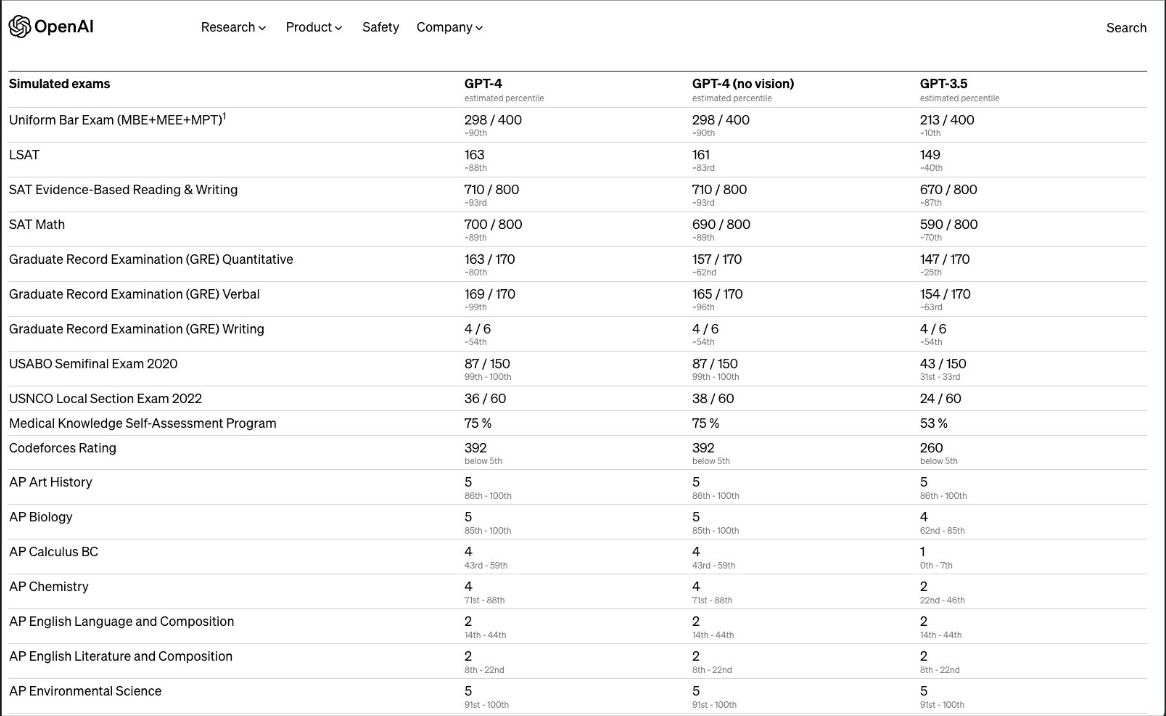
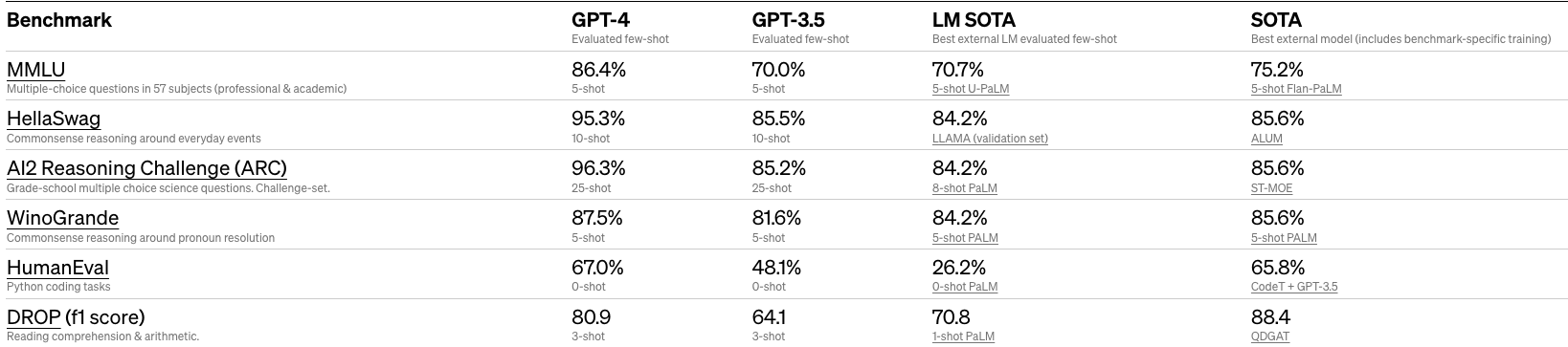
- The table below (sourced from the paper) depicts how GPT-4 performs on a variety of tests:
- Additionally, like its predecessors, GPT-4 is able to work with multiple languages and translate between them.
- As per the demo, it seems like GPT’s coding ability has been significantly bolstered compared to its predecessors.
- Now let’s look at some examples involving visual input (source):


- While we don’t have details on the visual architecture, we can see that it is able to take the image and run either of two tasks:
- If the image is a paper or contains text, it’s able to convert the image to text, proceed to understand the context, and finally return a response.
- Otherwise, if the image just contains objects and no text, it’s still able to glean information and return a response, likely still with the use of NLP and language contexting.
GPT-4 vs. GPT-3
- Let’s now explore the ways in which GPT-4 differs from GPT-3, including its ability to perform tasks that GPT-3 struggled with, as well as the technical features that make it more robust.
- In the demo given by Greg Brockman, President and Co-Founder of OpenAI, the first task that GPT-4 outperformed its predecessor on was summarization.
- Specifically, GPT-4 is able to summarize a corpus with more complex requirements, for example, “Summarize this article but with all words starting with a letter ‘G’”.
- In terms of using the model as a coding assistant, you are now able to not only ask it to write code for a specific task, but just copy and paste any errors that code may cause without any context and the model is able to understand and make the code fixes.
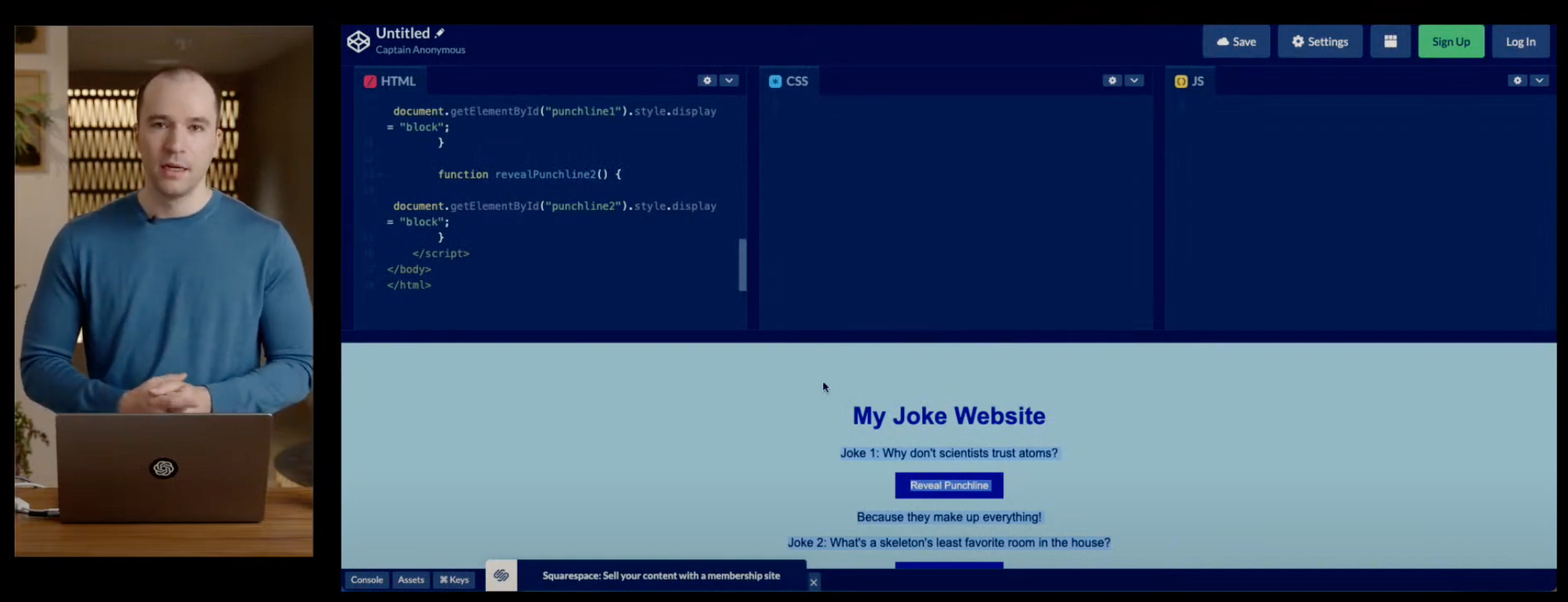
- One of the coolest tasks that GPT-4 was able to perform was taking a blueprint of a website, hand-drawn in a notebook, and was able to build the entire website in a matter of minutes as the images below show (source):

- Additionally, the model is now able to perform really well on academic exams. This shows how much language models have improved in general reasoning capabilities.
- “For example, it passes a simulated bar exam with a score around the top 10% of test takers; in contrast, GPT-3.5’s score was around the bottom 10%.” (source)
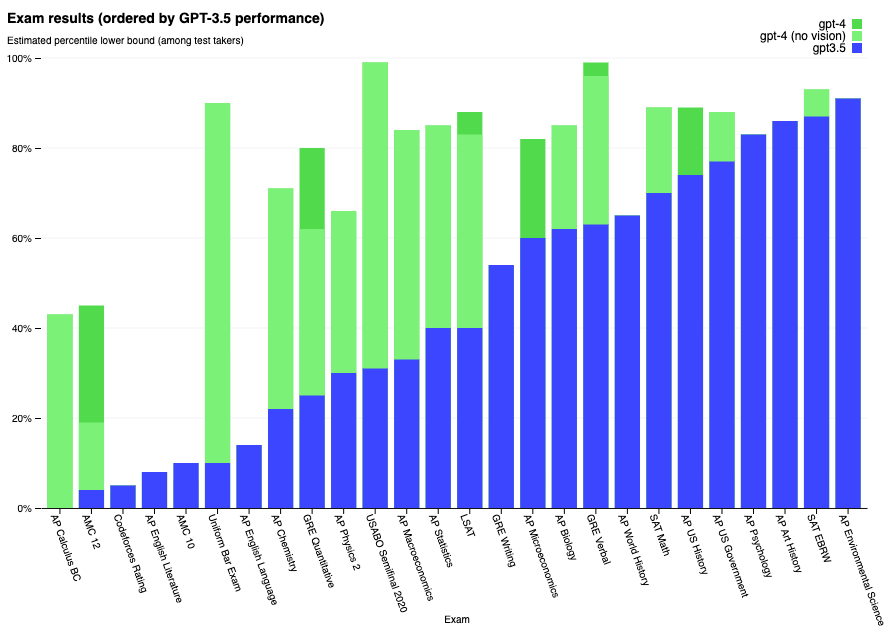
- GPT outperforms the previous state-of-the-art models on other standardized exams as well such as: GRE, SAT, BAR, APs as well as other research benchmarks such as: MMLU, HellaSWAG and TextQA (source).
- Now, lets look at the technical details of how GPT-4 has outperformed its predecessors.
- GPT-4 is capable of handling input context consisting of 8,192 to 32,000 words of text, which means it allows for a longer range of context (~50 pages max).
- The image below (source) shows GPT-4 on traditional benchmarks for machine learning models and it is able to outperform existing models as well as most of the SOTA models on most benchmarks.
Limitations
- GPT-4, like its predecessors, still hallucinates facts and make errors in terms of reasoning, thus, the output needs to be verified before it is used from these models.
- Much like ChatGPT, GPT-4 lacks knowledge of events that have occurred past the date of its data cut-off, which is September 2021.
Use-case: multimodal search engine
- Unlike prior GPT family models, we have far less technical details on GPT-4 possibly because it is what powers Bing as confirmed below.
- It’ll be fascinating moving forward to see how a multimodal powered search engine can help improve our lives!