Models • LLaMA
Introduction
- LLaMA: Open and Efficient Foundation Language Models is a collection of language models released by Meta AI (FAIR).
- LLaMA is open source, unlike ChatGPT or GPT-4, available to the public on this Github repository.
- It’s important to note however that while the code is available for the public, the weights are only available once you confirm your use case does not involve commercial use.
- LLaMA introduces a collection of smaller open-source models that were trained on public data and that outperform the most significant LLMs in recent history.
Methods LLaMA used
- Below are some methods LLaMA uses to improve performance and outpace recent LLMs; the smallest model is on par with GPT-3 on many language tasks.
- LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla70B and PaLM-540B. More on the
Pre-normalization
- “To improve the training stability, we normalize the input of each transformer sub-layer, instead of normalizing the output. We use the RMSNorm normalizing function” Source
- Pre-normalization is a technique that normalizes the input data before its fed into the neural network.
- The aim here is to improve the efficiency and stability of the trianing process by normalizing and reducing variation and correlation of the input features.
- Pre-normalization can take many forms, but the most common method is to subtract the mean and divide by the standard deviation of each feature across the training dataset.
- This ensures that the mean of each feature is zero and the standard deviation is one, which can make it easier for the neural network to learn the relationships between the features without being overly affected by their scales or magnitudes. -Pre-normalization can be especially important when dealing with features that have vastly different scales or magnitudes, as this can cause the neural network to overemphasize some features and underemphasize others.
- By pre-normalizing the data, these differences are accounted for, and the neural network can better learn the underlying patterns and relationships in the data
SwiGLU activation function (Swish-Gated Linear Unit)
- “We replace the ReLU non-linearity by the SwiGLU activation function, introduced by Shazeer (2020) to improve the performance. “Source
- SwiGLU is an activation function was introduced in research paper by Google researchers called “Swish-Gated Linear Units for Neural Network Function Approximation”.
-
The SwiGLU activation function is based on the Swish activation function, which is a smooth and non-monotonic function that has been shown to outperform other commonly used activation functions such as ReLU and sigmoid in certain neural network architectures.
- \[SwiGLU(x) = x * sigmoid(beta * x) + (1 - sigmoid(beta * x)) * x\]
- Experimental results have shown that SwiGLU can outperform other activation functions such as ReLU, Swish, and GELU (Gaussian Error Linear Units) on certain image classification and language modeling tasks.
- However, the effectiveness of SwiGLU can depend on the specific architecture and dataset used, so it may not always be the best choice for every application.
Rotary Embeddings
- “We remove the absolute positional embeddings, and instead, add rotary positional embeddings (RoPE), introduced by Su et al. (2021), at each layer of the network.”Source
- Rotary embeddings are used for processing sequential data introduced in a 2021 paper by Google researchers called “Rotary Position Embedding”.
- The basic idea behind rotary embeddings is to introduce additional structure into the position embeddings used in deep learning models. Position embeddings are used to encode the position of each element in a sequence (such as a word in a sentence) as a vector, which is then combined with the corresponding element embedding to form the input to the model.
- In traditional position embeddings, the vectors representing different positions are orthogonal to each other. However, this orthogonality can lead to certain symmetries in the model, which can limit its expressive power.
- Rotary embeddings address this issue by introducing a phase shift between the position embeddings for different dimensions. This phase shift is achieved using a matrix that has a special form based on the properties of rotations in high-dimensional space. The resulting embeddings are no longer orthogonal, but they preserve certain rotational symmetries that can make the model more expressive.
- Experimental results have shown that rotary embeddings can improve the performance of deep learning models on certain tasks, such as machine translation and language modeling.
Model Variants and Use-cases
- LLaMA is available at several sizes (7B, 13B, 33B, and 65B parameters).
- LLaMA is a more practical model to use compared to its predecessors for several reasons, it uses far less computing power and resources.
- Additionally, it is publicly available which is a big deal because these two aspects combined will further our understanding of language models inner workings.
Training Protocol
- LLaMA 65B and LLaMA 33B are trained on 1.4 trillion tokens while LLaMA 7B, is trained on 1 trillion tokens.
- LLaMA was trained like most language models, it took an input of a sequence of words and worked on predicting the next word.
- It was trained on 20 different languages with a focus on Latin and Cyrillic alphabets.
Results
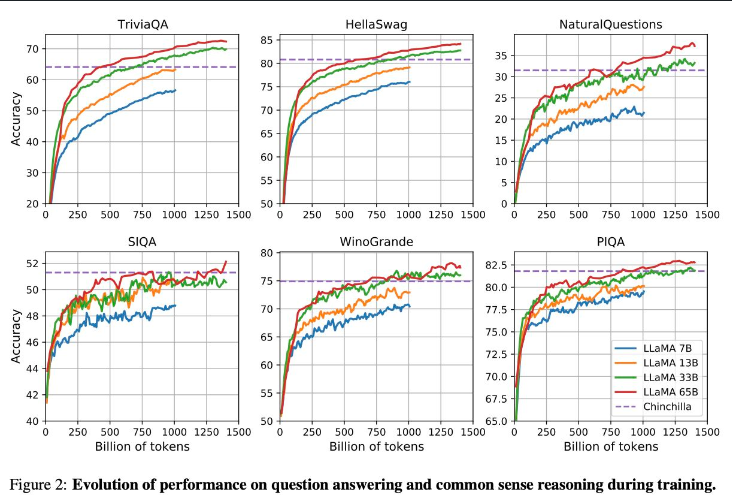
- LLaMA-13B outperforms GPT-3 (175B) on most benchmarks.
- LLaMA-65B is competitive with the best models, Chinchilla70B and PaLM-540B.” Yann LeCun
Llama 2
- Llama 2 has recently been released and is causing quite the ripple. They released not only a base model, that ranges from 7B to 70B parameters, but also a chat model.
- As seen below (source), Llama 2 starts with being pretrained on publicly available online sources.
- After this step, Llama2 chat is created through supervised finetuning and then refined through RLHF which specifically leverages rejection sampling and Proximal Policy Optimization.
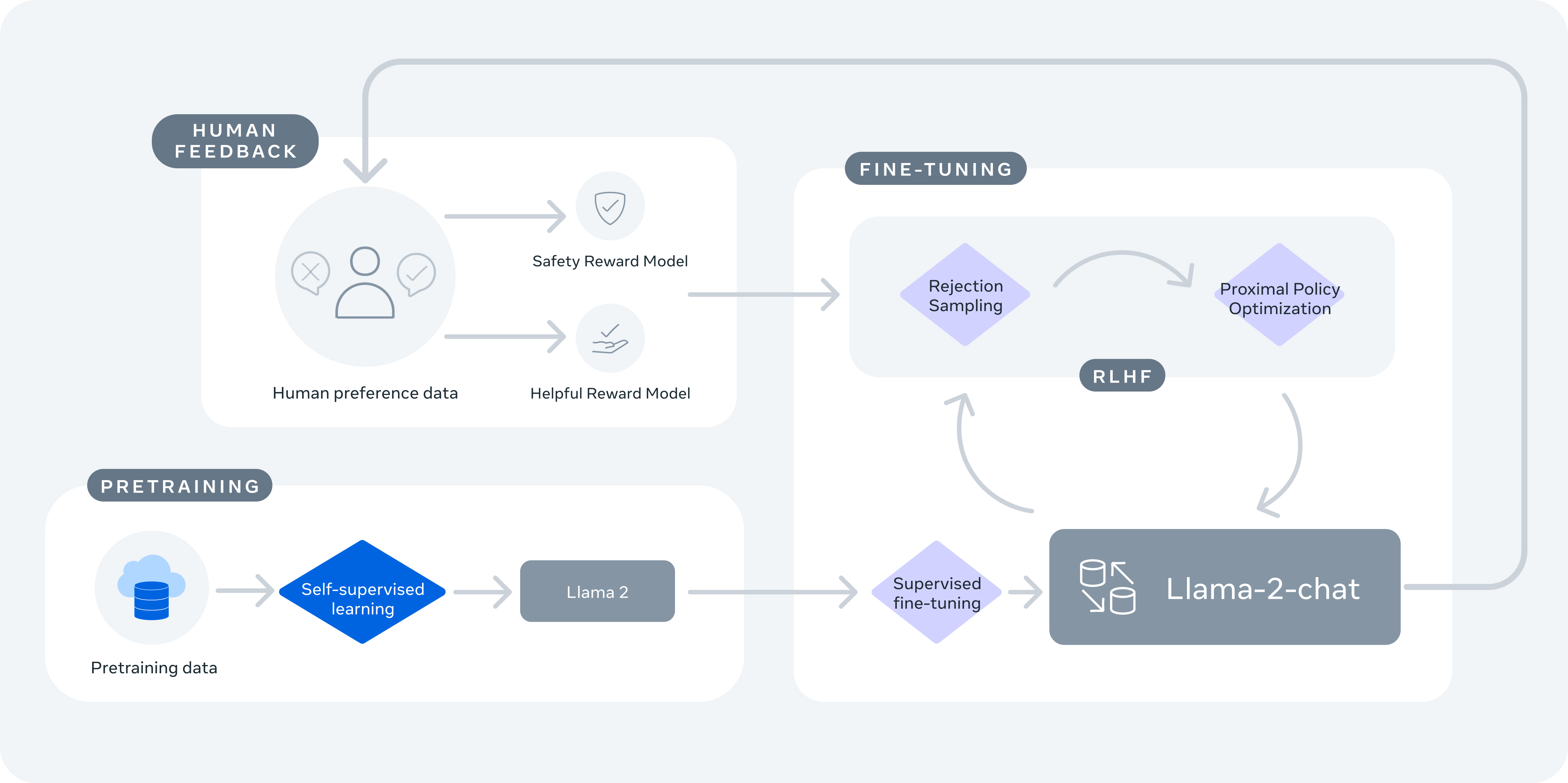
- The below image [(source)], captures a few key improvements of Llama 2 from its earlier version.