- System Design pages for Pinterest
- Ads Indexing at Pinterest
- 1. Ads Indexing as a Data Processing Pipeline:
- 2. Transformation from Raw to Servable Format:
- 3. Impact on Pinner (User) and Partner Experiences:
- 4. Challenges with Rapid Growth:
- 5. Limitations of Traditional Batch Index Builders:
- Conclusion:
- Ads Infra system design
- 1. Real-Time Incremental Pipeline:
- 2. Batch Pipeline:
- Conclusion:
- 1. Gateway:
- 2. Updater:
- 3. Storage Repo:
- 4. Argus:
- Resources
- Ads platform
- The new pipeline
- HNSW + Manas: customized search system
- What is TiDB?
- How TiDB is Used in Pinterest Ads:
- Conclusion:
- Real-Time Exactly-Once Ad Event Processing with Apache Flink, Kafka, and Pinot
- What is Apache Flink?
- Chat GPT example
- How Pinterest Engineering has developed a real-time user action counting system for ads. Let me break it down and explain the key components:
- How Pinterest’s engineering team used Kafka Streams API to develop a predictive budgeting system. This system was implemented to solve the problem of overdelivery in their advertising system. Let me break down the key aspects for you.
System Design pages for Pinterest
- System design fundamentals and glossary
- Pinterest follow pins and send notifications for updates/edits on pins
- Pinterest design a system to detect similar products
- Pinterest home page
- Tianpan’s blog on sys des, really good
Ads Indexing at Pinterest
- https://medium.com/pinterest-engineering/how-ads-indexing-works-at-pinterest-99b4796f289f
1. Ads Indexing as a Data Processing Pipeline:
- Ads indexing is a process of transforming raw ad campaign data into a format suitable for various stages of ad delivery such as targeting, retrieval, ranking, and auction. It is essentially a collection of algorithms and processes that analyze, process, and organize ad data so it can be quickly and efficiently served to users (Pinners).
2. Transformation from Raw to Servable Format:
The raw ad campaigns are provided in a format that is not directly suitable for serving. The indexing pipeline processes these campaigns, performs data joining with other relevant data, and converts them into a servable format. This is typically a computationally intensive process that might include:
- Joining Data: Combining information from different sources.
- Normalization: Making sure the data is consistent.
- Feature Extraction: Identifying and calculating variables that are relevant to the ad delivery system.
3. Impact on Pinner (User) and Partner Experiences:
- The quality and freshness of the indexed ad documents directly affect the relevance and timeliness of the ads served. If the indexed data is out-of-date or of low quality, users may see irrelevant ads, and partners may miss opportunities for conversion.
4. Challenges with Rapid Growth:
- With Pinterest’s rapid expansion in the ad business, the size of the ad index needs to grow, and the end-to-end (E2E) latency of indexing must be reduced. The challenge is twofold:
- Scaling the Index: The index must be able to accommodate a much larger number of ad documents without a loss in performance.
- Reducing Latency: The entire process of transforming raw data into servable format must be faster to ensure that the ads are as fresh and relevant as possible.
5. Limitations of Traditional Batch Index Builders:
- Traditional batch index builders process data in large chunks, usually at scheduled intervals. While this can be efficient, it often does not provide the flexibility and speed required to handle rapid scaling and the need for lower latency. This creates a need for a more real-time, scalable approach to indexing.
Conclusion:
-
The ads indexing pipeline at Pinterest plays a vital role in delivering targeted and relevant ads to users. The transformation of raw ad campaigns into a servable format is a complex process that has direct implications for user and partner experiences. As the business grows, traditional methods may fall short, requiring innovative solutions to scale up the index and reduce latency simultaneously. The emphasis on this part of the ad delivery stack underscores the importance of timely, relevant, and scalable ad serving in modern digital advertising ecosystems.
-
Thus, we built a scalable incremental indexing system inspired by Google’s web indexing system “Caffeine”, which achieves seconds-level indexing E2E latency with the scale up to 100M+ documents.
Ads Infra system design
- All the data processed by ads indexing pipeline falls into two categories: ads control and ads content data. Ads control data is the ads metadata set up by advertisers used in ads targeting, auction bidding, etc. Ads content data consists of various signals we use to understand the ads Pin for optimizing ads delivery performance.
- Ads control data
- Targeting specs
- Budget
- Bid
- Creative type
- Ads content data
- Image signature
- Pin interests(Coteries)
- Text annotation
- Pinvisual embedding
- Historical performance data
- For ads control data, we need low latency and absolute data correctness, because the data freshness directly impacts advertisers’ experience and data correctness is the key to have advertisers’ trusts. On the other hand, Ads content data has a relatively loose SLA ondata freshness, as many upstream data sources have a low data update frequency. However, they still require strong data correctness as low quality data can lead to severe ads delivery performance issues. To meet these requirements, we designed the ads indexing system as a combination of real-time incremental and batch pipelines.
- If the real-time pipeline is clogged, the serving index will fall back to the base index generated by the batch pipeline. If the batch pipeline fails one time, the real-time serving index can still cover all the delta updates since the previous batch index. As the trade off, there is additional merging logic between two indices at serving.
1. Real-Time Incremental Pipeline:
This part of the system is designed to handle rapid updates and maintain data consistency across large-scale concurrent processing. It’s broken down into several specific components:
- Distributed Transactions: By supporting distributed transactions in data processing, the system ensures that updates across multiple nodes are consistent. This is critical for maintaining accurate data in a large-scale, distributed environment.
- Distributed transactions refer to a method of managing and coordinating transactions over multiple distinct, interconnected systems or databases. Unlike a transaction on a single system where all the operations are under a unified control, a distributed transaction spans across various network nodes.
-
Push-Based Notifications: Implementing push-based notifications for changes in ads control data allows the system to update the ads index in seconds. This fast E2E latency ensures that changes in ad control data (like pausing or budget adjustments) are quickly reflected in what’s served to users.
- High and Medium Priorities: The real-time incremental pipeline has two logical priority levels, High and Medium, which may reflect different urgency or importance of the data being processed. This prioritization can help in efficiently handling diverse types of data updates.
2. Batch Pipeline:
The batch pipeline serves complementary roles to the real-time incremental pipeline, focusing on broader updates and robustness:
-
Periodical Refresh: The batch pipeline keeps the ads index up to date with Ads Content data by performing scheduled refreshes. This pull-based approach ensures that even if real-time updates miss some information, the index stays current through periodic comprehensive updates.
-
Eventual Consistency: Ensuring eventual consistency for both Ads control and content data means that even if there are temporary inconsistencies due to message loss or process failure in the real-time pipeline, the system will eventually reconcile these and achieve a consistent state.
-
Low Priority Pipeline: The batch pipeline is described as having a single logical pipeline with Low priority, contrasting with the incremental pipeline’s High and Medium priorities. This likely reflects the fact that while important, the batch updates are less time-sensitive than the real-time updates.
Conclusion:
The combination of real-time incremental and batch pipelines in the ads indexing system provides a nuanced, flexible approach to handling the complex requirements of modern ad serving. The real-time pipeline ensures rapid updates and data consistency, while the batch pipeline provides broader, regular updates and ensures robustness in the face of potential issues. Together, they enable the system to scale up and reduce latency, supporting the rapidly growing needs of the advertising business, while maintaining a balance between speed, consistency, and reliability.
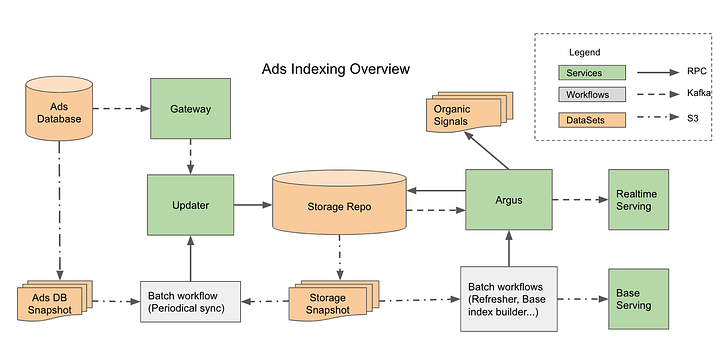
- Let’s break down each component of this architecture and the technologies that could be used for each:
1. Gateway:
- Purpose: Converts various update events from upstream sources into a format suitable for the ads indexing updater. It can send these updates to the Updater via Kafka or direct RPC (Remote Procedure Call).
- Potential Technologies:
- Stream Processing: Apache Kafka Streams, Apache Flink
- Messaging System: Apache Kafka for asynchronous communication
- RPC Framework: gRPC, Apache Thrift
2. Updater:
- Purpose: Acts as the data ingestion component that takes updates from the Gateway and writes them into the Storage Repo.
- Potential Technologies:
- Data Processing: Apache Storm, Apache Flink
- Data Ingestion Tools: Apache NiFi, Flume
3. Storage Repo:
- Purpose: Stores all data throughout the ad document process life cycle, from raw updates to final servable documents. It needs to support cross-rows and tables transactions and column-level change notification to Argus.
- Potential Technologies:
- Database Systems: Supporting transactions and column-level notifications could be done through RDBMS like PostgreSQL, MySQL, or distributed databases like TiDB.
- Change Data Capture (CDC) Tools: Debezium for capturing column-level changes
4. Argus:
- Purpose: Notification-triggered data process services. An Argus worker is notified of a data change event from the Repo, reads all dependent data from the data repo, conducts heavy computation, generates final servable documents, writes back to the Repo, and publishes them for real-time serving.
- Potential Technologies:
- Processing Frameworks: Apache Spark for computational heavy processes
- Workflow Management: Apache Airflow for orchestrating the complex data workflow
- Real-time Serving Technologies: Apache Druid, Redis
-
The architecture described is a multi-tiered system with distinct responsibilities for handling various aspects of ads indexing and serving. By carefully selecting appropriate technologies for each layer, you can achieve a balanced system capable of handling the complexities of real-time incremental updates, heavy computational processing, and robust storage and retrieval of ad documents. The choices should be aligned with the specific requirements of latency, scalability, and consistency for the ads infrastructure.
- Gateway
-
We built this lightweight stateless streamer service based on Kafka Stream, as it provides good support on “at least once process”. The major upstream is the mysql binlog from the ads database. As the mysql binlog contains only the delta change per transaction per table, we need to materialize it by querying ads database again. It also provides a short-cut path from ads database to serving by skipping the following heavy indexing process for some light-weighted serving documents, such as budget updates. For example, if a campaign budget is updated, Gateway will directly push this change to real-time budget control service via Kafka.
- Updater
-
Updater is a lightweight data ingestion service built on Kafka stream. It basically tails Kafka topics, extracts structured data from messages and writes them into Storage Repo with transaction protection. For versioned data, it also does the version check before updating to keep data update sequence while dealing with unordered upstream events. Besides updates from the Kafka, Updater also takes updates from RPC from batch processes for the backfill purpose.
- Storage Repo
-
Storage Repo is a columnar Key-Value storage that provides cross-table transactional operations for Updater and Argus. It also pushes the column level change notification to Argus. Because ads indexing pipeline needs to support full batch index building, Storage Repo also needs to integrate well with common big data workflows, such as snapshot dump, MapReduce jobs, and etc. Thus, we chose Apache Omid & HBase as the transactional nosql database for the Storage Repo. Omid is the transaction management service on top of HBase, which is inspired by Google’s Percolator. In Percolator, the change notifications are stored in a bigtable column and workers constantly scan partitioned range to pull change notifications. Because HBase can’t afford heavily scanning operations, we built the change notification service as HBase proxy, which converts HBase WAL to change notifications and publishes them to Kafka for data processing.
- Argus
-
Argus is the service that monitors the changes in Storage Repo to further process changed data. It is built on Kafka consumer with data APIs to Storage Repo. It tails the change notification from Storage Repo, and runs various handlers according to event type. Each handler reads multiple columns across different rows and tables in Storage, generates derived data objects via data joinings or enrichments, writes them back to Storage Repo within a single transaction. We built ads handlers inside Argus to do the following work:
- Ads handlers contain all the ads business logic of generating final servable Ads documents.
- Ads handlers pull some of Ads content data from external data sources for data enrichments. There is an in-memory cache layer inside handlers to improve the efficiency
- Ads handlers have options to publish the final servable documents to serving services via Kafka
- Batch process workflows
-
There are a few batch process workflows running in this system to ensure the data integrity. Because we already have the real-time incremental process pipelines, the batch workflows are used mainly to compensate the incremental pipeline and they share the same execution binary on the data process. Here are the list of workflows running in system
- Base index builder workflows: they run every few hours to generate the base index
- Data sync workflows: 1) the data sync between Ads Database and Storage Repo ensures the data consistency of ads control data. 2) the data sync among different tables in Storage Repo to check the data consistency within Storage Repo.
- Refresh workflows: they run periodically to mark all ads documents as newly updated to trigger the reprocessing for refreshing all pull type signals.
- GC workflows: they run infrequently to remove very old inactive ad documents so that Storage Repo won’t grow infinitely to hurt its performance.
- Downstream Services
-
The major downstream consumers are Ads Manas cluster(inverted index) and key-value store for Ads Scorpion(forward index). Both of them use delta architecture serving, taking base index and real-time per document update. The base index is published through S3 while the real-time document update is via Kafka broadcasting.
- System Visibility
-
The final ad servable document contains more than 100 ads control and content fields, and many engineers actively contribute to ads indexing by adding new fields or modifying existing fields. It is necessary for the platform to provide a good E2E visibility for engineers to improve their developing velocity. Therefore, we provide the following features in the ads indexing system:
- Integration test and Dev run: Gateway, Updater and Argus all provide the same RPC interfaces corresponding to their Kafka message ingestion interfaces. This setting simplifies the dev run for integration test on these components. Each component has its dev run with before/after comparison report for developers to understand the impact of their code changes to ads index
- Code Release: Each service has its own release cycle. But we set an E2E staging pipeline for continuous deployment.
- Presubmit integration test: Argus handlers have most complicated application logic and many more engineers work in its code base, thus we set the presubmit integration test on Argus handlers
- Debugging UI: Storage Repo keeps all intermediate data and additional debugging information. We built a web-based UI for developers to easily access these information
- Historical records: In addition to HBase versioning, we periodically snapshot HBase tables to the data warehouse for the historical records
-
In practice, ads indexing team is often involved in various ads delivery debugging tickets, such as why my ads campaign not spending. Having the above visibility features can allow engineers to quickly locate the root cause.
- System monitoring
-
Ads indexing system is one of the most critical components in the ads delivery service, thus we build a comprehensive monitoring for its system health in two major areas: 1) data freshness, 2) data coverage. The followings are the key metrics in our dashboard.
- Incremental pipeline health: E2E latency per document, latency breakdown by stages, process throughputs, daily report on the number of dropped messages in ads incremental pipeline and etc.
- Base pipeline health: Base index staleness, index data volume change, the coverage of critical fields in base index and etc.
- Data consistency: Number of unsynced documents reported by various sync workflows.
- Production Results
-
Ads indexing system has been running smoothly in production for more than one year. The hybrid system does not only provide seconds level E2E latency at most of the time, but also ensures the system high availability and data integrity. Here we select a few highlights from the production results
- Ads control data update-to-serve p90 latency < 60 seconds in 99.9% time
- Ads control data update-to-serve max latency < 24 hours in 100% time
- Single-digit daily number of dropped messages in incremental pipeline
-
Ads indexing system is highly resilient to handling various anomalies in production. With simple manual operations, it can recover very quickly from incidents to ensure data freshness and integrity. Here are some common production issues.
- Ads real-time pipeline clogging: This type of problem is usually caused by a huge spike in upstream updates. In this case, we can choose to shut down the data publishing from incremental pipeline to realtime serving so that it won’t be overwhelmed. The pipeline relies on the sync workflow to keep base index update to date. The Gateway and Update are both set to drop stale messages to quickly clear up the message buffed in Kafka, so that the ads real-time pipeline can catch up very fast after the spike passes.
- Incorrect data introduced by release: This is usually caught in staging vs prod monitoring, data coverage check in base index workflow, or performance degradation in prod. We can temporarily shut down the realtime serving and roll back base index to a good version. To clean up the polluted data in Storage Repo, we can trigger the refresh workflow to reprocess all documents. If we know only partial data is polluted, we can refresh the selective documents to shorten the recovery time.
- Data quality/coverage drop: This often starts in the external pull-type data sources and get caught in the coverage check in the base index workflow. We can rollback external data sources and backfill the data through refresh workflow. Because the backfill goes through the low priority pipeline, it won’t impact the high and medium priority pipelines to slow down the processing of updates from critical data sources.
- Brief technical discussions
-
Throughout the process of building the ads indexing system from scratch to fully meet all business requirements with production maturity, we made a few design decisions to balance between system flexibility, scalability, stability as well as implementation difficulty.
-
Data joining via remote Storage Vs multi-stream joining with local storage: Ads indexing involves many data joining operations upon update notifications as the ads document enrichment needs data joined on several keys such as adID, pinID, imageSignatureID, advertiserID, etc. We chose to do the data joining via fetching them from remote Storage with transactions instead of doing multi-streaming joining from local state. By doing so, the system provides more flexibility for distributed data processing applications as they don’t need to choose data partition key to avoid racing conditions. As the tradeoff, it pays an extra roundtrip for data fetching. But since the ads indexing processor is computational heavy so that this roundtrip cost is a tiny proportion of the total infra cost.
-
Decoupled services Vs merged services: During the design phase, we did consider merging services to have fewer components in ads indexing system, which is a tradeoff between system isolation and simplicity. Gateway and Updater could be merged to save one message hop. However, we chose to separate them as Gateway is a streaming process service while Updater is more on the data ingestion service. Now Gateway and Updater have quite different paths for evolving. Gateway became a popular lightweight streamer framework for a few other use cases, while Updater starts to ingest Ads content updates as they don’t need signal materialization as ads control data. Updater and Argus could be merged as they are both built on Kafka consumers with interactions to Storage Repo. We chose to have them as separate services, because they have quite different directions for performance optimizations; Updater is a very light weighted data extractor and sinker, while Argus is a heavy lifting computational component.
-
System scalability: there is one scalability bottleneck in ads indexing system as Omid relies on a centralized transaction manager for timestamp allocation and conflict resolution. To address this scalability limitation, we customized Omid at Pinterest to improve its throughout for better scalability, but its implementation details are beyond the scope of this tech blog.
- What’s next
-
The ads indexing system has evolved since its initial launch. We’ve been focusing on improving system stability and visibility. In addition, some of the core components are adapted by other application as they are designed to be running independently from the beginning. For example, Gateway is widely used as the lightweight streaming framework in ads retargeting and advertiser experiences. Moving forward, we plan to focus on improving system usability to further improve developer velocity in the following areas:
- Build a centralized config-based component for developers to manage data flows through ads indexing system in one single place. Right now the developers have to config in multiple places to cherry pick signals/fields among different data schemas. We also plan to build an assistant visualization tool based on configs for developers to easily browse the existing signals and their dependencies for data explorations.
- Enhance the pipeline health monitoring by integrating with the probing type test framework, as the current data health are mostly relying on the aggregation data view. Vertical feature developers have hard times to leverage aggregated metrics for monitoring, and they have to run ad hoc offline integration tests or data analysis reports to monitor the health of narrowed data segments. The probing framework can allow developers to launch their real-time validation tests on particular type of documents in production.
Resources
- https://github.com/donnemartin/system-design-primer
- https://github.com/khangich/machine-learning-interview
- https://igotanoffer.com/blogs/tech/system-design-interview-prep
- designing a machine learning pipeline that extract various signals from the contents and making it available to others.
- It was consisted of batch and real-time processing consideration. *
Ads platform
- In May 2020, Pinterest launched a partnership with Shopify that allowed merchants to easily upload their catalogs to the Pinterest platform and create Product Pins and shopping ads. This vastly increased the number of shopping ads in our corpus available for our recommendation engine to choose from, when serving an ad on Pinterest. In order to continue to support this rapid growth, we leveraged a key-value (KV) store and some memory optimizations in Go to scale the size of our ad corpus by 60x. We had three main goals:
- Simplify scaling our ads business without a linear increase in infrastructure costs
- Improve system performance
- Minimize maintenance costs to boost developer productivity
- Solution: Deprecate In-Memory Index
- Rather than horizontally or vertically scaling the existing service, we decided to move the in-memory index to an external data store. This removed the need for shards entirely, allowing us to merge all nine shards into a single, stateless, ads-mixer service. This vastly simplified the system as well, bringing us down from 10 clusters to just one.
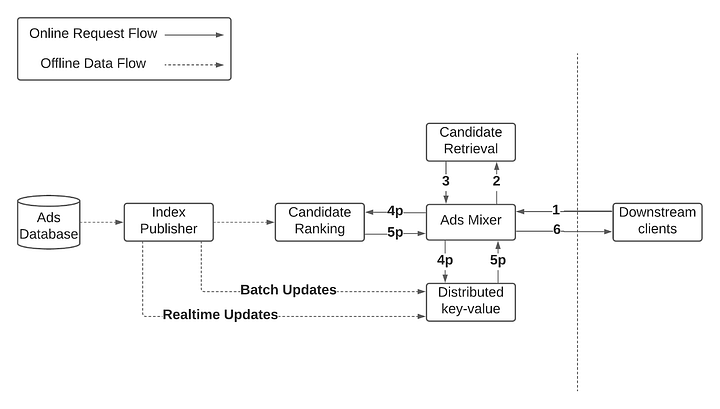
- Another benefit of removing the in-memory index was that it significantly reduced startup time from 10 minutes to <2 minutes (since we no longer needed to parse and load this index into memory). This allowed us to move from time-based cluster auto scaling to CPU-based cluster auto scaling, which makes our infra cost more reflective of actual traffic as opposed to dependent on hard coded capacity numbers that are not tuned frequently enough. It also makes our cluster more resilient to growth in traffic, since a larger cluster is automatically provisioned, without the need for manual intervention.
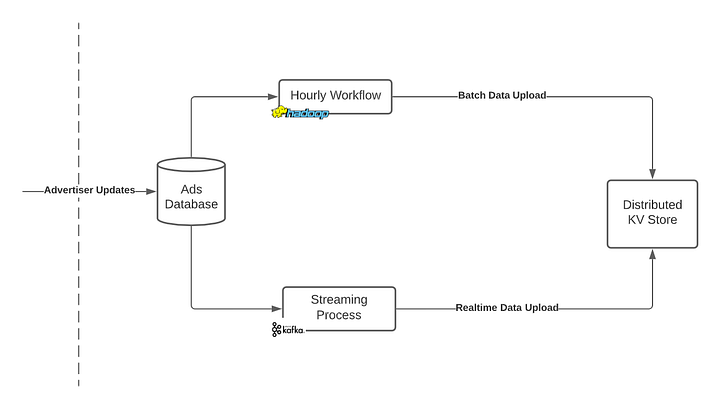
- Deprecating In-Memory Index: Moving the in-memory index to an external data store simplified the system, merging nine shards into a single stateless service, and reduced startup time.
- Garbage Collection (GC) Optimization: The GC in Go was causing CPU usage spikes. By reducing the number of objects on the heap and optimizing GC behavior, CPU usage was stabilized, and performance improved.
- Parallelization and Caching: Introducing parallel processes for fetching index data and ranking minimized latency, while local caching reduced the queries to the key-value store, saving infrastructure cost.
- Real-Time Data Updates: To handle missing or stale data in the KV store, real-time updates were enabled, reducing the number of missing candidates and improving data freshness.
- Key Achievements
- Simplified Scaling: By utilizing an external KV store and optimizing memory usage, the system could handle a 60x larger ad corpus without linearly increasing infrastructure costs.
- Improved Performance: Through parallel processing, caching, and garbage collection optimizations, system latency was reduced, and reliability increased.
- Minimized Maintenance Costs: By simplifying the architecture, maintenance became more straightforward, boosting developer productivity.
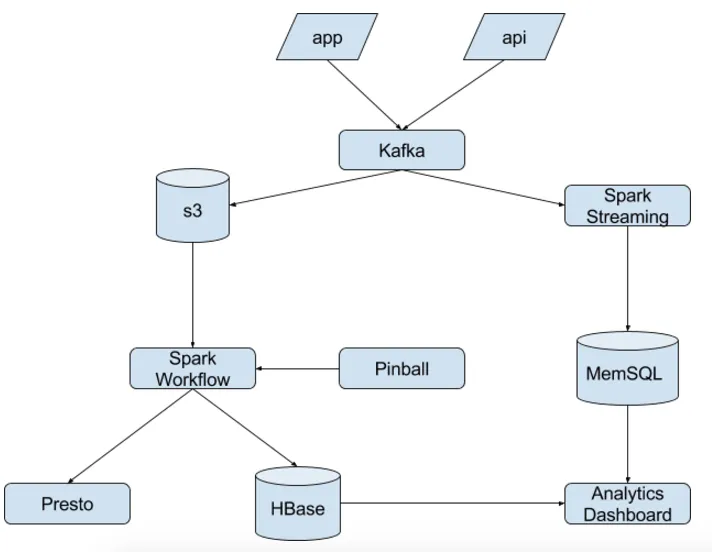
The new pipeline
- As we designed the new pipeline, we wanted to not only address the previously mentioned challenges, but also look forward to supporting Pinterest’s growth in years to comes. Specifically, we wanted to simplify the logic, reduce our storage footprint and easily support our users’ requests.
- To that end, we embraced Spark as our solution. (Check out this post which describes the components of our experiment framework.) A Spark workflow fits nicely in our framework. The figure below shows:
- Kafka for the log transport layer
- Pinball for orchestrating our Spark workflow
- Spark Streaming for real-time experiment group validation
- HBase and MemSQL to power the dashboard backend
- Presto for interactive analysis
HNSW + Manas: customized search system
- The Manas index includes an inverted index and a forward index.
- Same as a common inverted index, Manas inverted index stores the mapping from term to list of postings. Each posting records the internal doc ID and a payload. To optimize the index size and serving latency, we implemented dense posting list and split posting list, which are two ways to encode the posting list based on the distribution of key terms among all documents. The inverted index is used for candidate generating and lightweight scoring.
- On the other hand, Manas’ forward index stores the mapping from internal doc ID to the actual document. To optimize data locality, the forward index supports column family, similar to HFile. The forward index is used for full scoring.
- provides Approximate Nearest Neighbor (ANN) search as a service, primarily using Hierarchical Navigable Small World graphs (HNSW).
- ANN search retrieves based on embedding similarity. Oftentimes we’d like to do a hybrid search query that combines the two. For example, “find similar products to this pair of shoes that are less than $100, rated 4 stars or more, and ship to the UK.” This is a common problem, and it’s not entirely unsolved, but the solutions each have their own caveats and trade-offs.
What is TiDB?
TiDB (Ti stands for Titanium) is an open-source, distributed, Hybrid Transactional and Analytical Processing (HTAP) database. It is designed to provide strong consistency and horizontal scalability, allowing it to handle both OLTP (Online Transaction Processing) and OLAP (Online Analytical Processing) workloads. Key features include:
- Horizontal Scalability: You can easily scale TiDB horizontally by adding new nodes, which helps in handling larger amounts of data.
- Strong Consistency: TiDB provides strong consistency across all replicas, ensuring accurate and reliable data.
- MySQL Compatibility: TiDB speaks the MySQL protocol and can be used as a drop-in replacement for MySQL in many scenarios, easing migration.
How TiDB is Used in Pinterest Ads:
The integration of TiDB within Pinterest Ads for the Unified Storage Service was a significant project involving extensive evaluation, testing, and migration. Here’s how it works:
- Evaluation and Selection:
- Benchmarking: Pinterest evaluated multiple storage backends and benchmarked them with shadow traffic to assess performance.
- Final Candidate: TiDB was chosen as the best fit due to its compatibility, scalability, and other relevant features.
- Data Migration:
- From HBase to TiDB: The data residing in HBase needed to be migrated to TiDB. This required careful planning and execution to ensure that data integrity was maintained.
- Unified Storage Service Design and Implementation:
- Leveraging TiDB: TiDB powers the Unified Storage Service, handling the diverse data needs of the Pinterest Ads system.
- API Migration: Existing APIs from other systems like Ixia/Zen/UMS were migrated to Unified Storage Service, again leveraging TiDB’s MySQL compatibility.
- Offline Jobs Migration:
- TiSpark Ecosystem: The migration also included moving offline jobs from the HBase/Hadoop ecosystem to the TiSpark ecosystem, further integrating with TiDB.
- Meeting SLAs:
- Availability and Latency: Throughout this project, careful attention was paid to maintain the required availability and latency Service Level Agreements (SLAs), ensuring uninterrupted and high-quality service.
Conclusion:
TiDB’s role in the Pinterest Ads infrastructure is central to the Unified Storage Service, serving as the chosen storage backend after rigorous testing and evaluation. Its scalability, consistency, and compatibility made it a suitable choice for this complex migration and integration project, resulting in a robust and flexible storage solution for the diverse needs of the advertising system. The implementation process spanned multiple quarters and included not only migration from HBase to TiDB but also an overhaul of APIs and offline jobs, all while maintaining critical service standards.
Real-Time Exactly-Once Ad Event Processing with Apache Flink, Kafka, and Pinot
- Speed:Downstream ad systems (pacing of ads, budget updates) require the real-time context of user-generated ad events in order to perform their responsibilities.
- Customers will get to see their performance metrics with the least amount of delay.
- Reliability: The system must be reliable in terms of data integrity. Ad events represent actual money paid to Uber. If events are lost, then Uber loses on potential revenue.
- We must be able to accurately represent the performance of ads to our customers. Data loss would lead to underreporting the success of ads, resulting in a poor customer experience.
- Accuracy: We can’t afford to overcount events. Double counting clicks, results in overcharging advertisers and overreporting the success of ads. Both being poor customer experiences, this requires processing events exactly-once.
-
Uber is the marketplace in which ads are being served, therefore our ad attribution must be 100% accurate.
- Stream Processing with Apache Flink
-
The core building block of the system uses Apache Flink, a stream processing framework for processing unbounded data in near real-time. It has a rich feature set that’s well suited for ads, such as exactly-once guarantees, connectors to Kafka (Uber’s choice messaging queue), windowing functions for aggregation, and is well integrated and supported at Uber.
- Message Queues with Apache Kafka
-
Kafka is a cornerstone of Uber’s technology stack: we have one of the largest deployments of Kafka in the world and plenty of interesting work has gone into making sure it’s performant and reliable. Kafka can also provide exactly-once guarantees, and scales well with the ads use case.
- Real-Time Analytics with Apache Pinot
-
One of the main goals of the ads events processing system is to provide performance analytics to our customers, quickly: in comes Apache Pinot. Pinot is a distributed, scalable, OnLine Analytical Processing (OLAP) datastore. It’s designed for low-latency delivery of analytical queries and supports near-real-time data ingestion through Kafka.
- Data Warehousing with Apache Hive
-
Apache Hive is a data warehouse that facilitates reading, writing, and managing large datasets with rich tooling that allows the data to be queried via SQL. Uber has automated data ingestion flows through Kafka, and internal tooling that makes Hive a great solution to store data to be leveraged by data scientists for reporting and data analysis.
- First, we rely on the exactly-once configuration in Flink and Kafka to ensure that any messages processed through Flink and sunk to Kafka are done so transactionally. Flink uses a KafkaConsumer with “read_committed” mode enabled, where it will only read transactional messages. This feature was enabled at Uber as a direct result of the work discussed in this blog. Secondly, we generate unique identifiers for every record produced by the Aggregation job which will be detailed below. The identifiers are used for idempotency and deduplication purposes in the downstream consumers.
- The first Flink job, Aggregation, consumes raw events from Kafka and aggregates them into buckets by minute. This is done by truncating a timestamp field of the message to a minute and using it as a part of the composite key along with the ad identifier. At this step, we also generate a random unique identifier (record UUID) for every aggregated result.
- Every minute the tumbling window triggers sending aggregated results to a Kafka sink in an “uncommitted” state until the next Flink checkpoint triggers. When the next checkpointing triggers (every 2 minutes), the messages are converted to the “committed” state using the two-phase commit protocol. This ensures that Kafka read-offsets stored in the checkpoint are always in line with the committed messages.
- Consumers of the Kafka topic (e.g., Ad Budget Service and Union & Load Job) are configured to read committed events only. This means that all uncommitted events that could be caused by Flink failures are ignored. So when Flink recovers, it re-processes them again, generates new aggregation results, commits them to Kafka, and then they become available to the consumers for processing.
- A record UUID is used as an idempotency key in ad-budget service. For Hive it is used as an identifier for deduplication purposes. In Pinot, we leverage the upsert feature to ensure that we never duplicate records with the same identifier.
What is Apache Flink?
-
Apache Flink is an open-source, distributed stream processing engine. It’s designed for stateful computation over data streams, allowing for processing of unbounded datasets in real-time. Key features of Flink that are particularly relevant for ads and other real-time applications include:
-
Streaming APIs: Flink provides rich streaming APIs that enable developers to describe complex data transformations and analytics using a straightforward programming model.
-
Exact-Once Support: It ensures that each record in the data stream is processed exactly once, even in the face of failures, ensuring accuracy and consistency in calculations like ad spend.
-
State Checkpointing: Flink’s ability to periodically checkpoint its state allows for recovery from failures without loss of information, ensuring that streaming applications can resume from where they left off.
Overview of end to end once processing in flink with kafka
- Exactly-once semantics in Apache Flink ensure that each incoming event affects the final results only once, without duplicates or omissions, even in the case of a failure. This is achieved through Flink’s checkpointing system, a core feature that takes consistent snapshots of the application’s current state and the position in the input stream. Checkpoints are generated at regular intervals and saved to persistent storage, allowing Flink applications to continue processing data during this process.
- If a failure occurs, the system can resume from the most recent successful checkpoint, as though the failure never happened. This mechanism was limited to the scope of a Flink application before version 1.4.0 and did not extend to external systems where Flink sends data.
- With the introduction of the two-phase commit protocol and Flink’s TwoPhaseCommitSinkFunction, Flink now coordinates commits and rollbacks in distributed systems. This allows developers to maintain exactly-once semantics not only within a Flink application but also in conjunction with external systems, providing true end-to-end exactly-once processing.
How Flink Works for Ads at Pinterest:
- Within Pinterest’s Xenon platform, Flink is utilized to power several mission-critical functionalities:
- Once the data is ingested, Flink can take over to process this stream of data. In the case of ads, this might include tasks like:
- Calculating spending against budget limits in real-time
- Generating timely reporting results for advertisers
- Analyzing user interactions with ads for targeting or optimization
- Output: The results of Flink’s real-time processing can then be used in various ways, such as updating advertiser dashboards with spending information, adjusting ad delivery in response to budget constraints, or feeding into machine learning models to improve ad targeting.
So while Flink doesn’t ingest the ads themselves, it plays a crucial role in processing and analyzing the data associated with ads in real-time. This enables more responsive and data-driven decision-making within the advertising system.
- Ads Real-Time Ingestion, Spending, and Reporting:
- Real-time Calculation: By utilizing Flink’s stream processing capabilities, Pinterest can calculate ad spending against budget limits in real-time.
- Budget Pacing: This allows quick adjustments to budget pacing, ensuring that spending is aligned with advertiser targets.
- Timely Reporting: Advertisers receive more up-to-date reporting results, enabling more responsive decision-making.
- Platform Aspects:
- Reliability and Efficiency: Flink’s robustness and efficient processing capabilities contribute to platform reliability.
- Development Velocity: With Flink’s intuitive APIs, development speed for stream application development can be enhanced.
- Security & Compliance: The integration of Flink within the platform contributes to maintaining security and compliance standards.
- Other Use Cases:
- Fast Signals & Customized Experience: Flink’s real-time processing enables immediate availability of content signals, feeding into ML pipelines for personalized user experiences.
- Realtime Trust & Safety: Quickly identifying and reducing unsafe content.
- Content Activation & Shopping: Distributing fresh content and updating product metadata in near real-time.
- Experimentation: Supporting faster experiment setup, verification, and evaluation by accurately delivering metrics.
Conclusion:
Flink’s capabilities in stream processing, combined with its features like exact-once processing and state checkpointing, make it a versatile and powerful tool for real-time applications like ads. In Pinterest’s context, it’s integrated within the Xenon platform to enable real-time ad processing, along with various other critical use cases, ensuring timely and accurate data-driven decision-making.
Chat GPT example
- Below is the design of a machine learning pipeline for extracting various signals from contents and making it available to others. This pipeline will consider both batch and real-time processing, as required. Here’s a high-level overview of such a system:
- Data Collection and Preparation:
- Data can be collected from multiple sources such as databases, files, APIs, streaming data, etc.
- Ensure that you have the appropriate permissions and licenses to use and distribute the data.
- Clean the data to remove duplicates, handle missing values, etc.
- Input sources (Databases, Files, APIs, Streaming data)
- Data Cleaning
- Feature Extraction:
- This is the step where you will extract various signals from your content.
- Use Natural Language Processing (NLP) techniques like TF-IDF, Bag-of-words, Word2Vec, etc., for textual content.
- For image content, consider using Convolutional Neural Networks (CNNs) for feature extraction.
- NLP Techniques (if text)
- CNN (if images)
- Data Transformation and Storage:
- Normalize or standardize data, if necessary.
- Store transformed features in a suitable format, like parquet or feather, for efficient access.
- Consider using distributed storage systems like Hadoop HDFS or Cloud Storage solutions for large-scale data.
- Normalization
- Distributed Storage (Hadoop HDFS, Cloud)
- Model Training:
- Split the data into training and test sets.
- Choose an appropriate machine learning model based on the problem at hand.
- Train the model on the training set. Use cross-validation to tune hyperparameters.
- Split Data
- Train Model
- Hyperparameter Tuning
- Model Evaluation:
- Evaluate the model on the test set.
- Use appropriate metrics for evaluation based on the problem type (classification, regression, etc.)
- Test Split
- Metrics
- Model Deployment:
- Deploy the model for real-time predictions using technologies like Docker, Kubernetes, or cloud-based solutions like Google Cloud ML Engine.
- Ensure that the model can scale to handle multiple requests in parallel.
- Real-time Predictions
- Scalability
- Batch and Real-time Processing:
- For batch processing, consider using technologies like Apache Spark, which can handle large-scale data processing in a distributed manner.
- For real-time processing, consider using Kafka or Apache Flink, which can handle real-time data streams.
- Apache Spark (Batch)
- Kafka/Flink (Real-time)
- Data Distribution:
- Ensure secure and authorized access to data.
- Expose data through APIs, web services, or database queries.
- Use caching and load balancing to handle high demand.
- APIs, Web Services
- Caching & Load Balancing
- Monitoring and Maintenance:
- Continuously monitor the system for any anomalies or failures.
- Regularly update the model with new data.
- Anomaly Detection
- Regular Updates
How Pinterest Engineering has developed a real-time user action counting system for ads. Let me break it down and explain the key components:
1. The Problem: User Action Counting
- Frequency Control: Ensuring that users don’t see the same ad too frequently (or infrequently) to maximize engagement and brand awareness.
- Fatigue Model: Avoiding over-exposure to the same ads, which can negatively impact click-through rates (CTR).
- Query Pattern: Determining how user interactions with ads are counted, based on various dimensions (e.g., action, view type, time range).
2. User Action Counts Request Flow
- Ad Insertion: As a user interacts with Pinterest, an ad request is sent to fill designated ad spots.
- Action Tracking: User interactions with promoted Pins are tracked and logged.
- Event Writing: A Kafka consumer writes the action events to Aperture, a specialized data store developed by Pinterest.
3. Two Approaches to Counting
- Approach 1: Client-side Events Counting: Ads servers fetch raw events and run ad-hoc logic to compute counts.
- Approach 2: Independent Counting Service: A dedicated service uses a counting layer to serve counts and exposes generic counting APIs.
- Pinterest chose the second approach for its efficiency and suitability for their needs.
4. Other Challenges
- Deduplication: Ensuring that events are counted only once.
- Flexibility & Performance: The service must have a flexible query interface and meet stringent performance targets (e.g., <8ms P99 latency at peak times).
5. Aperture as the Counting Service
- Specialized Design: Aperture was built specifically for time series data storage and online events tracking and serving.
- Storage Schema Optimization: To boost query performance, Aperture breaks user events into separate records, categorized by time buckets.
- Query Language & Event Schema: Aperture uses a SQL-like query language and represents events as byte arrays. The client must define the event schema.
6. Client Request Handling
- The client-side ensures that counts for all use cases are fetched in a single place, reducing the number of requests to Aperture.
7. Conclusion
- The system enables Pinterest to deliver relevant and useful ads, leveraging Aperture’s specialized abilities for user action counting. The technology may be shared with the open-source community in the future.
How Pinterest’s engineering team used Kafka Streams API to develop a predictive budgeting system. This system was implemented to solve the problem of overdelivery in their advertising system. Let me break down the key aspects for you.
Overdelivery Problem
Overdelivery occurs when ads are shown for advertisers who have exceeded their budget, resulting in lost opportunities for other advertisers. The challenge is to predict and prevent this in real-time. Two major issues make this complex:
- Real-time spend data: Needing to feed information about ad impressions into the system within seconds to stop out-of-budget campaigns.
- Predictive spend: The system must predict future spend and slow down campaigns nearing their budget limit, accounting for natural delays in tracking ad impressions.
Solution Using Kafka Streams
Building a Prediction System
The spend prediction system had specific goals, such as:
- Handling different ad types and tens of thousands of events per second.
- Fanning out updates to many consumer machines.
- Ensuring low delay (less than 10 seconds) and 100% uptime.
- Being lightweight and maintainable for engineers.
Why Kafka Streams
Kafka Streams was chosen for the following advantages:
- Millisecond delay guarantee: Better than other technologies like Spark and Flink.
- Lightweight: No heavy external dependencies or dedicated clusters, thus reducing maintenance costs.
Concrete Plan
The architecture includes three main components:
- Ads serving: Distributes ads and communicates with inflight spend service.
- Spend system: Aggregates ad events and updates ads serving system.
- Inflight spend: Calculates and aggregates spends based on ad group using Kafka Streams.
Predicting Spend
The system proved to be highly accurate in practice, significantly reducing overdelivery.
Key Learnings
- Window design: Using tumbling windows instead of hopping windows increased performance by 18x.
- Compression strategies: By using delta encoding and lookuptable encoding, they reduced the message size by 4x.
Conclusion
Utilizing Apache Kafka Streams’ API allowed Pinterest to create a fast, stable, fault-tolerant, and scalable predictive spend pipeline. This approach proved to be an effective solution to a challenging industry problem and opened up further exploration into Kafka’s features.
Overall, the case study illustrates how a combination of real-time data processing, predictive modeling, and thoughtful system design can help address intricate problems in the advertising domain, providing near-instantaneous updates on ad spend and ensuring that advertising budgets are respected.
Overall, the article describes a complex and customized solution to a problem that many advertising platforms face. It offers insights into the technical decisions made by the Pinterest engineering team to track user interaction with ads in real time, allowing for more precise targeting and better user experience.
- Given a scenario where you are batch processing and each entry takes more than 30 seconds to process, design a system to process large volume of such data.
- New design where users can follow pins or users for updates: https://blog.devgenius.io/2020-pinterest-system-design-interview-1-37f3a721f3e
- 2.a.) what is the calibration and how to use the calibration in ML? The resulting score does not obey the distribution of the label of your data, you need to re-map model output to the proper distribution.
- 2.b.) what would you do if the training loss variate a lot? See the specific training process, In fact, it is normal to have variance at the beginning, the key is to see if the average loss is declining and trainin